지니 계수(Gini Coefficient)를 활용한 에지 용량(Edge Capacity) 계획 수립
요약
Fastly는 경제학의 지니 계수를 활용하여 에지(Edge) 인프라의 용량 계획을 수립합니다. 트래픽 불평등도를 핵심 신호로 사용하여 대규모 이벤트나 급격한 워크로드 변화에 대응하는 효율적인 용량 모델을 구축했습니다.
핵심 포인트
- 지니 계수를 통해 트래픽 불평등도를 측정하고 용량 계획에 활용
- 복잡한 ML 모델보다 해석 가능하고 빠른 단순 모델이 실제 운영에 효과적
- 트래픽 불평등 -> 캐시 동작 -> CPU 사용률 -> 여유 용량의 상관관계 파악
- 다양한 워크로드(API, 비디오, 보안 등)가 혼합된 에지 환경의 특성 반영
Fastly의 용량 모델(capacity model)의 핵심이 되는 통계치는 보통 경제학 논문에서 등장합니다. 지니 계수(Gini coefficient)는 인구 내 불평등을 설명하는 데 사용되는 거시 경제 지표입니다. Fastly의 용량 문제는 겉보기에 훨씬 더 구체적입니다. 우리는 특정 POP(Point of Presence)가 대규모 게임 출시를 감당할 수 있는지, 라이브 스포츠 이벤트 동안 대륙 전체에 어느 정도의 여유 용량(headroom)이 존재하는지, AI 및 보안 워크로드(workload)가 지속적으로 급성장함에 따라 어떤 일이 발생하는지, 그리고 몇 달 또는 몇 년 후의 인프라 투자를 어디에 해야 하는지를 알아야 합니다.
하지만 지니 계수가 우리의 용량 계획(capacity planning)의 핵심이라는 사실이 밝혀졌습니다.
주요 이벤트는 우리가 서비스하는 트래픽의 형태를 변화시킵니다. Fastly의 일반적인 하루는 고객 워크로드의 엄청난 다양성, 서비스 변경, 그리고 객체 인기도(object popularity)의 변화를 포함합니다. 대규모 게임 출시, 소프트웨어 업데이트, 라이브 이벤트, 또는 다른 제공업체로부터의 전환이 발생하는 동안, 소수의 워크로드가 갑자기 트래픽의 큰 비중을 차지할 수 있습니다.
이러한 관찰은 오늘날 Fastly가 사용하는 용량 모델의 핵심이 되었습니다:
트래픽 불평등(traffic inequality) -> 캐시 동작(cache behavior) -> CPU 사용률(CPU utilization) -> 여유 용량(headroom)
놀라운 점은 이 단 하나의 신호가 얼마나 많은 것을 설명해 주었는가 하는 점이었습니다. 저는 처음에 AutoML 시스템, 신경망(neural nets), 트리 모델(tree models), 앙상블(ensembles), 회귀(regressions), 특화된 시계열 예측 모델(time-series prediction models), 그리고 심지어 LLM까지 긴 목록의 머신러닝(machine learning) 및 예측 접근 방식을 시도했습니다. 많은 방식이 일반적인 트래픽에는 잘 작동했지만, 용량 계획에서 가장 중요한 희귀 사례(rare cases)에서는 어려움을 겪었습니다.
최종적으로 승리한 모델은 작고, 해석 가능하며(interpretable), 대화형 시나리오 분석(interactive scenario analysis)을 수행할 수 있을 만큼 충분히 빠릅니다. 이 모델은 현재 1년 이상 운영 환경(production)에서 사용되고 있습니다.
핵심은 트래픽 불평등을 일급 신호(first-class signal)로 취급한 것이었습니다.
에지의 용량은 워크로드의 문제입니다
Fastly POP는 용량(capacity)이라고 불리는 단 하나의 단순한 수치를 가지고 있지 않습니다. Fastly POP는 Fastly의 복잡하고 고성능인 소프트웨어 스택 위에서 혼합된 워크로드(mixed workload)를 실행하는 베어메탈(bare-metal) 서버들로 구성됩니다. 트래픽의 혼합 양상은 지역, 고객, 시간대 및 이벤트에 따라 달라집니다. POP는 라이브 비디오, API 트래픽, 보안 워크로드, 소프트웨어 다운로드, 혼합 웹 트래픽, 그리고 Wasm 기반의 Compute 워크로드를 동시에 처리합니다. 추가되는 각각의 요청, Gbps 단위의 트래픽, 또는 컴퓨팅 작업은 그 종류에 따라 매우 다를 수 있습니다. POP는 시간이 흐르며 구축되므로, 하드웨어 구성 또한 인프라가 언제 어디에 배포되었는지를 반영합니다.
이러한 특성 때문에 계획 수립은 깔끔하거나 추상적인 자원 할당(resource-allocation) 문제라기보다 실질적인 시스템 문제에 가깝습니다. 어느 날에는 여유 공간(headroom)이 충분했던 POP가, 워크로드가 표면적으로는 비슷해 보일지라도 다른 날에는 숨이 가쁠 정도로 한계에 부딪힐 수 있습니다.
우리는 일반적인 사례를 위해 계획을 세우는 동시에, 예외적인 사례도 처리할 수 있어야 합니다. 즉, 다음과 같은 질문들을 던져야 합니다:
- 이 POP가 다음 주에 예정된 알려진 이벤트를 감당할 수 있는가?
- 이 지역은 얼마나 많은 추가 벌크 다운로드(bulk-download) 트래픽을 흡수할 수 있는가?
- 만약 Compute와 보안 트래픽이 콘텐츠 전송(delivery) 트래픽보다 두 배 빠르게 성장한다면 어떻게 되는가?
- 어떤 프로세스 그룹이 가장 먼저 CPU 제한(CPU limiting) 상태가 되는가?
- 일반적인 계절적 트래픽(seasonal traffic) 위로 어느 정도의 여유 공간(headroom)이 남아 있는가?
- 어디에 더 많은 용량을 구축해야 하는가?
- 다른 제공업체로부터 장애 조치(failover)가 발생하여 고객 트래픽이 Fastly로 이동할 때 어떤 일이 발생하는가?
트래픽은 고객의 라우팅 결정, 계획된 이벤트, 트래픽 마이그레이션, 유지보수, 또는 인터넷상의 다른 곳에서 발생한 장애 등 다양한 이유로 Fastly로 이동할 수 있습니다. 용량 모델은 이러한 변화를 일반적인 계획 시나리오로서 처리할 수 있어야 합니다.
유용한 모델은 반사실적(counterfactuals) 상황을 지원할 수 있어야 합니다. 우리는 예상치 못한 일이 발생할 것을 기대하기 때문에, 다음에 무슨 일이 일어날지 예측하려고 애쓰기보다는 다양한 시나리오에서 어떤 일이 발생할지에 더 관심을 가집니다.
기성 AI 및 ML로는 충분하지 않았습니다
처음에는 이것이 전통적인 AI / ML 문제처럼 보였습니다. 우리는 트래픽, 요청률 (request rates), 컴퓨팅 작업 (compute tasks), 인터넷 상태 (internet weather), 캐시 동작 (cache behavior), CPU 사용률 (CPU utilization) 등 수천 개의 지표를 보유하고 있어, AI / ML 관점에서는 마치 사탕 가게에 온 아이처럼 풍부한 텔레메트리 (telemetry) 데이터를 가지고 있었습니다. 따라서 인기 있는 오픈 소스 패키지나 다양한 벤더의 독점 제품에서 제공하는 표준 AI 및 ML 기술 도구 상자를 사용해 보려는 시도는 자연스러웠습니다.
이러한 표준 기술 중 상당수는 평균적인 경우(average case)에 좋은 오차를 보여주었습니다. 이들은 일반적인 트래픽을 잘 학습했기에, 평범한 날에는 예측 결과가 상당히 좋아 보일 수 있었습니다. 하지만 용량 계획 (capacity planning)은 특이한 날(unusual days)에 의해 정의됩니다.
일반적인 모델들은 종종 다음과 같은 광범위한 관계를 학습하곤 했습니다:
바이트 증가 -> CPU 증가
요청 증가 -> CPU 증가
wasm 컴퓨팅 증가 -> CPU 증가
이는 데이터로부터 학습했어야 하는 내용이 맞습니다. 문제는 이러한 관계의 강도가 워크로드 (workload)의 세부 사항에 따라 달라진다는 점이며, 아무리 정교한 일반 모델이라 할지라도 이러한 세부 사항을 포착해내지 못했다는 것입니다.
불평등의 에지(edge) 버전
지니 계수 (Gini coefficient)는 소득과 같은 값의 집합 사이의 불평등을 측정합니다. 하지만 우리의 에지 인프라 (edge infrastructure)에서 핵심적인 불평등은 고객 워크로드 사이의 불평등, 즉 특정 시간에 지배적인 트래픽의 형태입니다.
핵심적인 관찰 결과는 우리의 알고리즘들이 특정 유형의 트래픽이 지배적인 상황에 암묵적으로 맞춰져 있다는 점입니다. 프로세서부터 POP (Point of Presence)에 이르기까지 모든 계층의 캐싱 (Caching)은 인기도 (popularity)로부터 이득을 얻습니다. 캐시는 핫 데이터 (hot data)를 서비스하는 것이 다른 곳에서 콜드 데이터 (cold data)를 가져와 제공하는 것보다 연산 집약도가 낮게 만듭니다. 결과적으로 인기도는 불평등의 한 형태이며, 지니 계수는 그 불평등을 측정하기에 적합한 지표라는 사실이 밝혀졌습니다. 지니 계수는 모델이 게임의 명칭, 이벤트, 고객 또는 출시 일정을 알 필요 없이 해당 인기도 신호에 대한 수치를 제공해 주었습니다.
이러한 현상이 가장 명확하게 나타나는 지점은 캐시 히트율 (cache hit ratio)입니다. 분산된 워크로드 (diffuse workload)는 수천 명의 고객이 트래픽의 작은 비중을 나누어 기여할 수 있습니다. 반면, 주요 출시(major release)나 라이브 이벤트(live event)는 단 몇 명의 고객이 특정 POP의 트래픽 대부분을 차지할 수 있습니다. 이 두 사례는 총 트래픽 양은 동일할 수 있지만, 캐시 동작 방식은 매우 다를 수 있습니다. 저는 트래픽 불평등을 지니 계수 (Gini coefficient) 형태로 확인했으며, 이를 재조정 (rescaled)했을 때 우리가 계획 수립 시 자주 고려하는 가장 극단적인 상황에서의 에지 캐시 (edge cache) 동작을 추적할 수 있음을 발견했습니다. 또한 이러한 이벤트들은 일반적인 AI 및 ML 기술이 가장 낮은 성능을 보였던 이벤트들과 정확히 일치한다는 사실도 밝혀졌는데, 이는 해당 이벤트들이 극단적이고 예측 불가능한 이상치 (outliers)였기 때문입니다.
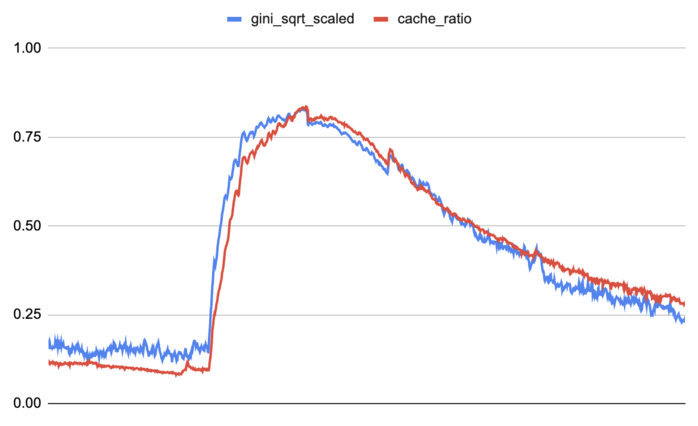
주요 게임 출시 전, 중, 후에 발생한 EWR POP의 재조정된 지니 계수의 제곱근 대 프론트엔드 캐시 히트율 (front-end cache hit ratio) 비교.
이러한 관찰을 통해 POP CPU 사용률 (CPU utilization)과는 별개인 캐시 모델을 도출했습니다:
gini = 상위 고객 트래픽 비율에 대한 지니 계수
top_N_ratio = 상위 N개 고객의 트래픽 비율
predicted_cache_hit_ratio = a * sqrt(gini)
...
이 모델의 계수들은 최근 이력에 대한 로버스트 회귀 (robust regression)를 통해 산출됩니다. 지니 계수 외에도 상위 N개 고객을 포함하는 것은 유사한 직관을 포착하며, 트래픽의 다양성이 현저히 낮은 POP의 경우에도 중요하게 작용합니다. 예측값은 합리적인 범위 내로 클리핑 (clipped)됩니다. 또한 우리는 텔레메트리 (telemetry)를 사용하여 구조적으로 캐싱이 덜 용이한 고객들을 고려하며, 이를 통해 캐싱할 수 없는 워크로드의 집중이 유용한 캐시 지역성 (cache locality)으로 오인되지 않도록 합니다.
제곱근을 취한 것은 작지만 중요한 재스케일링 (rescaling) 이었습니다. 캐시 동작은 트래픽 불평등 (traffic inequality)과 선형적으로 개선되는 것처럼 보이지 않았습니다. 집중의 초기 징후는 매우 중요했습니다. 이는 트래픽이 캐시가 활용할 수 있을 만큼 충분히 인기를 얻고 있음을 의미했습니다. 트래픽이 이미 고도로 집중된 이후에는 추가적인 불평등이 가져오는 수익이 체감되었습니다. 제곱근을 취함으로써 지니 계수 (Gini coefficient)의 낮고 중간인 범위를 확장하고 높은 범위를 압축하여, 두 영역을 정렬했습니다.
CPU 사용률에 불평등 반영하기
다시 CPU 사용률 (CPU utilization)로 돌아가 보겠습니다. 다양한 표준 AI/ML 기술을 사용하여 제가 처음 구축했던 모델들은 트래픽으로부터 CPU 사용률을 예측하기 위한 것이었습니다:
트래픽 믹스 (traffic mix) -> 예측된 CPU -> POP 용량/헤드룸 (POP capacity/headroom)
예측된 CPU를 알게 되면, 다양한 트래픽 믹스로 시나리오를 실행하여 어떤 CPU 수준에 도달하는지 확인할 수 있습니다. 점점 더 높은 트래픽 볼륨을 시뮬레이션하면 CPU 천장 (CPU ceiling)에 도달하게 되며, 이를 통해 POP의 용량과 헤드룸을 알 수 있습니다.
POP 용량의 정확한 모델링을 가능하게 하는 핵심 요소가 캐시 동작임이 밝혀지면서, 복잡한 AI/ML 기술은 더 이상 필요하지 않게 되었습니다. 현재 프로덕션 모델은 놀라울 정도로 단순합니다.
첫째, 위에서 언급한 접근 방식을 사용하여 트래픽 집중도(traffic concentration)로부터 프런트엔드 캐시 히트율 (front-end cache hit ratio)을 예측합니다. 프런트엔드 캐시 히트율은 CPU 효율성의 핵심인데, 이는 객체를 클러스터 프라이머리 (cluster primary)에 요청하지 않고도 서비스할 수 있는지 여부를 알려주기 때문입니다. 반면, (훨씬 더 높은 수치를 보이는) 클러스터 및 POP 전체 캐시 히트율은 오리진 오프로드 (origin offload)에 대해 더 많은 정보를 제공합니다.
둘째, 트래픽, 요청률 (request rate), 컴퓨팅 작업 볼륨 (compute task volume), 그리고 캐시 예측치를 사용하여 다음과 같이 CPU를 예측합니다:
트래픽 믹스 (traffic mix) -> 예측된 캐시 비율 (predicted cache ratio) -> 예측된 CPU -> POP 용량/헤드룸 (POP capacity/headroom)
| |
--------------------------
우리는 POP별로 학습합니다. 모델은 서버의 관련 CPU 그룹별로 별도로 학습됩니다. 이 모델의 피처 (features)는 의도적으로 좁고 운영 중심적입니다:
초당 비트 수 (bits per second)
초당 요청 수 (requests per second)
컴퓨팅 작업 볼륨 (compute task volume)
CPU 사용률 (CPU utilization) 모델은 1분 단위의 정밀도(granularity)로 이러한 특징(features)들에 대해 로버스트 회귀 (robust regression)를 사용합니다. 우리는 피팅 (fitting) 전에 CPU 사용량이 낮은 행들을 필터링하는데, 매우 조용한 기간은 용량 계획 (capacity planning)에 있어 정보 가치가 낮기 때문입니다. 또한 캐시 승수 (cache multiplier)를 피팅할 때 CPU 사용량이 높은 샘플에 더 높은 가중치를 부여하는데, 이는 상한 범위 (upper range)가 계획 결정이 이루어지는 구간이기 때문입니다.
학습 (training) 과정에서는 실제 프런트엔드 캐시 적중률 (cache hit ratio) 데이터를 사용하며, 추론 (inference) 과정에서는 먼저 지니 계수 (Gini-based) 기반의 캐시 적중률 모델을 실행하고 그 출력을 전달합니다. 가상의 이벤트의 경우, 우리는 캐시 적중률을 알 수 없습니다. 모델은 해당 트래픽 믹스 (traffic mix)가 만들어낼 캐시 동작을 예측해야 하며, 그 뒤를 따르는 CPU 사용량을 예측해야 합니다. 캐시 승수는 더 나은 캐시 동작이 CPU 비용을 줄이는 방식을 포착하며, 컷오프 (cutoff)와 거듭제곱 상수 (power constants)는 간단한 그리드 서치 (grid search)를 통해 결정됩니다:
downshifted = max(cache_hit_ratio - cutoff, 0)
multiplier = 1 - downshifted ^ power
predicted_cpu_utilization = base_cpu_utilization * multiplier
이 모델은 거의 즉각적인 추론이 가능합니다. 계획가와 엔지니어들은 POP, 베이스라인 (baseline), 고객, 워크로드 유형 (workload type), 그리고 성장 시나리오 (growth scenario)를 빠르게 변경할 수 있습니다. 출력값에는 트래픽 집중도 (traffic concentration), 예측된 캐시 비율 (predicted cache ratio), 캐시 승수 (cache multiplier), 기본 CPU 예측값 (base CPU prediction), 최종 CPU 예측값 (final CPU prediction), 그리고 제한 CPU 그룹 (limiting CPU group)과 같은 유용한 중간값들도 포함됩니다. 모델의 단순함은 해석 가능성 (interpretability)을 높여줍니다.
Fastly가 실제 환경에서 마주하는 광범위한 트래픽 형태에도 불구하고, 우리는 이 단순한 모델이 실제 CPU 사용률의 5% 이내 오차를 유지하는 반면, 더 정교한 모델들은 종종 25% 이상의 오차를 보인다는 것을 확인했습니다.
헤드룸 (Headroom)은 시나리오에 따라 달라집니다
하나의 POP는 균등한 성장 (uniform growth)을 위한 헤드룸, 컴퓨팅 집약적 성장 (compute-heavy growth)을 위한 헤드룸, 대량 다운로드 (bulk download)를 위한 헤드룸, 그리고 라이브 이벤트 (live event)를 위한 헤드룸이 각각 다를 수 있습니다. 모델은 이러한 가정들을 가시화해야 합니다.
헤드룸 루프 (headroom loop)는 대표적인 베이스라인에서 시작됩니다. 그런 다음 시나리오에 따라 트래픽을 확장하며, CPU 임계값 (threshold)에 도달할 때까지 예측 체인 (prediction chain)을 실행합니다.
시나리오와 기준 타임스탬프 (baseline timestamp)를 선택합니다.
이진 탐색 (binary search)을 사용하여 CPU 그룹의 최대 임계값 (max threshold) 바로 아래에 있는 트래픽 레벨을 찾습니다:
확장된 트래픽 믹스 (traffic mix)에 대한 캐시 동작 (cache behavior)을 예측합니다.
...
출력값에는 제한 요소가 되는 CPU 그룹, 임계값에서의 예측 CPU, 추가적인 Gbps 또는 RPS, 관련이 있는 경우 컴퓨팅 작업 헤드룸 (Compute task headroom), 그리고 서버당 용량 (per-server capacity)이 포함됩니다. 최종 계획 답변은 NIC, 피어링 (peering), 트랜짓 용량 (transit capacity)과 같은 네트워크 제약 조건도 고려합니다.
이러한 프레임워크 (framing)는 이벤트 계획 시 동일한 질문을 다양한 방식으로 던질 수 있게 해주므로 유용했습니다. 계획자는 피크(peak)에 근접한 기준점과 비피크 (off-peak) 기준점을 비교하거나, 균등 성장 가정과 고객 특정 대량 이벤트 (customer-specific bulk event)를 비교할 수 있으며, 전송 중심 고객의 램프업 (ramp-up)과 컴퓨팅 중심 고객의 램프업을 비교할 수도 있습니다.
정상 기준점 (Normal Baseline) 찾기
우리는 POP의 정상적인 트래픽을 나타내는 기준점 (baseline)이 필요합니다. 기준점은 알 수 없는 이벤트, 장애, 또는 예상치 못한 트래픽 동작을 피해야 합니다. 그렇지 않으면 헤드룸 (headroom) 계산이 해석 불가능한 기준점에서 시작되게 됩니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기