완전한 로컬 음성 비서 구축하기
요약
Raspberry Pi와 Platypush를 활용하여 클라우드 의존성을 최소화한 완전한 로컬 음성 비서를 구축하는 방법을 소개합니다. OpenWakeWord, Vosk, Piper를 통해 호출어 탐지부터 음성 합성까지 온디바이스로 처리하는 파이프라인을 제안합니다.
핵심 포인트
- OpenWakeWord를 이용한 로컬 웨이크 워드 감지
- Vosk를 활용한 온디바이스 음성-텍스트 변환(STT)
- Piper를 통한 로컬 텍스트 음성 변환(TTS) 구현
- OpenAI API를 의도 파악 및 일반 질문 답변용으로만 제한적 사용
- 개인정보 보호와 저지연을 위한 로컬 중심 아키텍처 설계
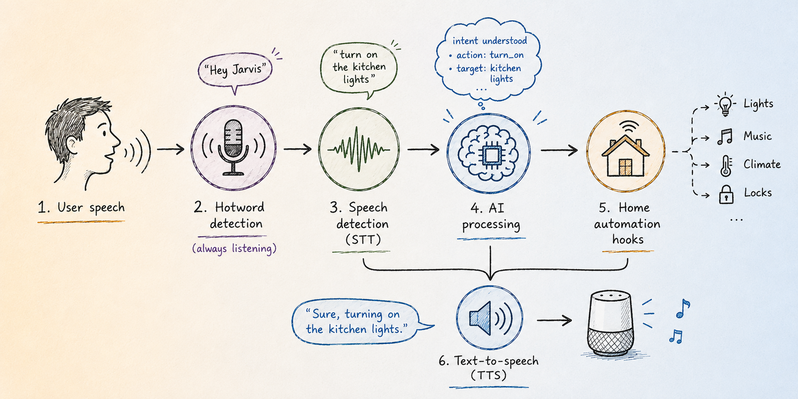
2026년에 완전한 로컬 음성 비서 구축하기
Platypush를 기반으로 한 Raspberry Pi 친화적인 실용적인 음성 비서 설정.
저를 오랫동안 팔로우해 오신 분들은 제가 직접 만드는 음성 비서에 얼마나 집착해 왔는지 알고 계실 것입니다.
지난 몇 년간의 제 실험은 다음과 같이 요약할 수 있습니다:
2007년: 은닉 마르코프 모델 (Hidden Markov models)을 사용하여 원시적인 음성 비서를 구축하려 했던 저의 첫 번째 시도인 Voxifera. 범용적인 용도로는 확실히 좋지 않았지만, 2007년 당시에는 수십 개의 간단한 음성 명령을 구분하기에 충분했습니다. -
2019년: Platypush를 기반으로 구축한 첫 번째 음성 비서. 마이크와 스피커가 장착된 Raspberry Pi 위에서 현재는 지원 중단된 Google Assistant Library를 사용했으며, 이벤트 훅 (event hooks)을 통해 모든 자동화 루틴과 사용자 정의 명령을 연결할 수 있었습니다. -
2020년: #platypush의 두 번째 반복 버전으로, 이번에는 다른 비서 플러그인들도 지원했습니다 - Alexa (현재 통합 기능 제거), Snowboy (프로젝트 중단으로 인해 제거됨), Mozilla DeepSpeech (Mozilla가 중단함에 따라 현재 제거됨), PicoVoice, 그리고 mimic3 (Mycroft를 기반으로 구축되었으나 현재 파산한 텍스트 음성 변환 (text-to-speech) 엔진). -
2024년: Platypush의 세 번째 반복 버전으로, 이번에는 강화된 PicoVoice 통합과 OpenAI API를 기반으로 한 새로운 음성 인식 (speech-to-text) 및 텍스트 음성 변환 (text-to-speech) 플러그인을 포함했습니다.
하지만 이제 2026년이며, 아마도 하드웨어와 소프트웨어 모두 한동안 지속될 가능성이 높은 완전한 오픈 솔루션에 기반한 완전한 온디바이스 (on-device) 음성 비서를 구축하기에 충분히 성숙했을 것입니다.
이 글에서 우리는 Platypush를 통해 그 간극을 메워보겠습니다:
assistant.openwakeword
웨이크 워드 (wake word)를 로컬에서 감지합니다.
assistant.vosk
명령을 로컬에서 전사 (transcribe) 합니다.
tts.piper
답변을 로컬에서 말합니다.
openai
언어 모델이 유용한 곳, 즉 지저분한 음성을 의도 (intent)로 변환하거나 일반적인 질문에 답하는 용도로만 사용됩니다.
- 기존의 홈 자동화 플러그인인
light.hue,music.mpd또는weather.openweathermap을 사용하여 동작을 수행합니다.
그 결과는 단순히 겉모습만 바꾼 또 다른 클라우드 비서가 아닙니다. 호출어 엔진 (Hotword engine), 음성 인식 (Speech recognition), 명령 디스패치 (Command dispatch) 및 음성 합성 (Speech synthesis)은 모두 온디바이스 (On-device)에서 실행될 수 있습니다. 만약 openai 단계가 로컬의 OpenAI 호환 서버를 가리킨다면, 전체 파이프라인 (Pipeline) 역시 여러분의 LAN 내에 머무를 수 있습니다.
파이프라인 (The pipeline)
아키텍처는 다음과 같이 요약할 수 있습니다:
호출어 탐지 (Hotword detection) ("OK Google", "Alexa" 등)는 지속적이고 낮은 지연 시간 (Low-latency)을 요구하는 작업이며, 네트워크를 필요로 해서는 안 됩니다.
음성-텍스트 변환 (Speech-to-text) 또한 로컬 추론 (Local inference)에 적합합니다. Vosk 모델은 Raspberry Pi를 포함한 겸손한 사양의 하드웨어에서도 실행될 수 있을 만큼 충분히 작으며, 짧은 홈 오토메이션 (Home automation) 명령을 처리하기에는 완벽하게 충분합니다.
텍스트-음성 변환 (Text-to-speech) 역시 오늘날 로컬 모델이 충분히 제 역할을 할 수 있는 분야입니다. Piper 음성은 빠르고 가벼우며, 과거의 로봇 같은 espeak 스타일의 폴백 (Fallback) 방식보다 훨씬 더 자연스럽습니다.
유일하게 선택적으로 네트워크가 필요한 부분은 **언어 모델 (Language model)**입니다.
하지만 이는 정책적인 선택일 뿐, 음성 스택 (Voice stack)의 필수 요구 사항은 아닙니다.
설정 (Setup)
어시스턴트 샘플 저장소 (Repository)를 클론 (Clone) 하세요:
git clone https://git.platypush.tech/platypush/assistant-sample
cd assistant-sample
모델 (Models)
다음 단계는 음성 스택에서 사용되는 음성 모델들을 다운로드하는 것입니다.
호출어 탐지 (Hotword Detection)
서비스가 처음 시작될 때, 사용 가능한 모든 모델을 자동으로 다운로드합니다.
서비스가 실행 중인 상태에서 다음 명령어를 사용하여 사용 가능한 모델 목록을 확인할 수 있습니다:
curl -s -XPOST \
-H 'Content-type: application/json' \
-H "Authorization: Bearer $PLATYPUSH_TOKEN" \
...
여기서 $PLATYPUSH_TOKEN은 서비스를 실행 중인 사용자의 토큰입니다.
서비스가 처음 시작될 때 http://localhost:8008에 접속하여 토큰을 가져올 수 있습니다. 자격 증명 (Credentials)을 생성한 후, Settings -> Tokens -> Generate API Token을 선택하세요.
음성-텍스트 변환 (Speech-to-text)
Vosk 음성 모델의 전체 목록은 여기에서 확인할 수 있습니다.
영어 모델의 품질에 대한 몇 가지 피드백은 다음과 같습니다:
| 모델 (Model) | 크기 (Size) | 비고 (Notes) |
|---|---|---|
vosk-model-small-en-us-0.15 | 40 MB | 매우 빠르고 가벼운 모델로 오래된 Raspberry Pi에서도 실행 가능하지만, 정확도는 낮을 수 있습니다. |
vosk-model-en-us-0.22-lgraph | 128 MB | 명확한 발음과 원어민의 경우 상당히 정확하지만, Raspberry Pi에서도 원활하게 실행될 만큼 충분히 작습니다. |
vosk-model-en-us-0.22 | 1.8 GB | 정확한 범용 미국 영어 (US English) 모델입니다. 노트북이나 x86 프로세서에서는 빠르지만, Raspberry Pi에서는 다소 무거울 수 있습니다. |
선택한 모델을 Docker 볼륨 작업 디렉토리로 다운로드하세요:
mkdir -p ./workdir/assistant.vosk/models
cd ./workdir/assistant.vosk/models
wget "https://alphacephei.com/vosk/models/vosk-model-en-us-0.22-lgraph.zip"
...
텍스트 음성 변환 (Text-to-speech)
여기에서 음성 합성 (speech synthesis) 모델을 다운로드하세요.
다운로드하기 전에 음성의 유형을 파악할 수 있도록 오디오 샘플도 제공됩니다.
모델은 보통 *.onnx 파일과 *.onnx.json 파일로 구성됩니다.
두 파일 모두를 Docker 볼륨 작업 디렉토리로 다운로드하세요:
mkdir -p ./workdir/piper_tts
cd ./workdir/piper_tts
wget "https://huggingface.co/rhasspy/piper-voices/resolve/main/en/en_US/hfc_female/medium/en_US-hfc_female-medium.onnx"
...
설정 (Configuration)
예시 설정 파일을 복사하여 편집하세요.
cp config/config.example.yaml config/config.yaml
홈 오토메이션 플러그인 (Home automation plugins)
인식된 음성이 집안의 나머지 부분에 전달될 수 있게 되면 어시스턴트는 유용해집니다.
예를 들어, Hue 조명:
light.hue:
bridge: hue
groups:
...
그리고 음악을 위한 MPD/Mopidy:
music.mopidy:
host: localhost
music.mpd:
...
이것들은 일반적인 Platypush 플러그인일 뿐입니다.
어시스턴트는 Hue, MPD, Chromecast, Zigbee, MQTT 등에 대한 특별한 지식이 필요하지 않습니다.
어시스턴트는 오직 이벤트를 발생시키기만 하면 되며, 여러분의 훅 (hooks)이 해당 이벤트로 무엇을 할지 결정합니다.
빌드 (Build)
어시스턴트 서비스를 위한 컨테이너 이미지를 빌드하세요:
docker build -t platypush-voice .
실행 (Run)
어시스턴트는 호스트의 마이크와 스피커에 접근할 수 있어야 합니다. 컨테이너는 ALSA를 PulseAudio를 통해 라우팅하므로, 아래 예시들은 호스트에서 실행 중인 PulseAudio 서버에 연결하는 방법을 설명합니다.
Linux
PulseAudio 또는 pipewire-pulseaudio가 설치된 경우:
docker run --rm \
-e PULSE_SERVER=unix:/run/pulse/native \
-v /run/user/$(id -u)/pulse/native:/run/pulse/native \
...
macOS
호스트에 PulseAudio를 설치하고 시작하세요:
brew install pulseaudio
pulseaudio --daemonize=yes --exit-idle-time=-1
pactl load-module module-native-protocol-tcp \
...
그 다음 컨테이너를 시작합니다:
docker run --rm \
-e PULSE_SERVER=tcp:host.docker.internal:4713 \
--name voice-assistant \
...
만약 pactl load-module 명령이 해당 모듈이 이미 로드되었다고 보고하면, 기존의 PulseAudio 데몬을 그대로 계속 사용하면 됩니다.
Windows
Windows용 PulseAudio를 설치한 다음, pulseaudio.exe와 동일한 디렉토리에 default.pa 파일을 생성하세요:
load-module module-waveout sink_name=output source_name=input record=1
load-module module-native-protocol-tcp auth-anonymous=1 listen=0.0.0.0 port=4713
set-default-sink output
...
PowerShell에서 PulseAudio를 시작하세요:
.\pulseaudio.exe -F .\default.pa --exit-idle-time=-1
그 다음 저장소(repository) 디렉토리에서 컨테이너를 시작합니다:
docker run --rm `
-e PULSE_SERVER=tcp:host.docker.internal:4713 `
--name voice-assistant `
...
Windows 개인 정보 설정에서 데스크톱 앱에 대한 마이크 액세스가 활성화되어 있는지 확인하고, 프롬프트가 나타나면 방화벽을 통해 PulseAudio를 허용하세요.
사용법 (Usage)
서비스가 실행되면 음성 명령(기본 호출어는 "Alexa")으로 상호작용을 시작할 수 있습니다.
날씨에 관한 모든 질문은 날씨 플러그인(weather plugin)이 활성화되어 있다면 해당 플러그인을 통해 해결됩니다.
음악(music) 또는 조명(lights) 플러그인이 활성화되어 있다면, 음성 명령("음악 중지", "불 켜줘" 등)으로 제어할 수 있습니다.
그렇지 않은 경우, 어시스턴트는 openai를 사용합니다.
질문에 답하기 위한 플러그인이며, OpenAI의 응답이 질문인 경우 후속 대화(follow-up turns)를 진행합니다.
어시스턴트 확장하기 (Extending the Assistant)
어시스턴트 로직은 config/scripts 아래의 간단한 Platypush 훅(hooks)을 통해 모델링됩니다.
자신만의 훅을 정의하거나 기존 훅을 수정함으로써 원하는 대로 확장할 수 있습니다.
대화 시작하기
대화는 HotwordDetectedEvent에 훅을 연결함으로써 시작됩니다.
import logging
from platypush import run, when
from platypush.events.assistant import HotwordDetectedEvent
...
결정론적 명령 (Deterministic commands)
일반적인 홈 오토메이션 명령의 경우, 일반적인 이벤트 훅(event hooks)이 여전히 가장 좋은 도구입니다. 이들은 빠르고, 검사 가능하며, 환각(hallucinate)을 일으키지 않습니다.
from platypush import run, when
from platypush.events.assistant import SpeechRecognizedEvent
@when(SpeechRecognizedEvent, phrase="turn on (the)? lights")
...
AI 명령 (AI Commands)
openai 플러그인이 활성화되어 있다면, 질문에 답하는 데 도움을 받기 위해 이를 사용할 수 있습니다.
AI 플러그인이 유익한 음성 비서의 두 가지 일반적인 사용 사례는 다음과 같습니다:
음성-의도 변환 (Speech to Intent)
응답 폴백 (Response fallback)
음성-의도 변환 (Speech to Intent)
일반적인 질문, 깔끔한 정규 표현식(regular expression)에 맞지 않는 명령, 또는 다음과 같은 가공되지 않은 문장을 변환하기 위해 이 기능이 필요할 수 있습니다:
"조금 더 어둡게 해주고 음악 볼륨을 줄여줘"
이를 다음과 같은 구조화된 실행 계획(structured action plan)으로 변환합니다:
[
{
"action": "light.hue.set_lights",
...
어시스턴트 샘플에서 제공되는 예시는 일기 예보입니다.
특히, 다음과 같은 자연어 요청을:
"내일 샌프란시스코 날씨가 어때요?"
다음과 같이 변환하는 잘 짜여진 시스템 프롬프트(system prompt)와 함께 openai.get_response를 사용하는 점에 주목하세요:
{
"type": "weather",
"delta_days": 1,
...
def parse_weather_request(request: str) -> WeatherRequest | None:
request_dict = (
run(
...
또한 직접적인 답변 대신 중간 변환(intermediate transformation)을 위해 모델을 사용할 수도 있습니다. 예를 들어, action과 args를 포함하는 아주 작은 JSON 객체를 반환하도록 요청할 수 있습니다.
, 그런 다음 명시적으로 허용한 액션(action)만 실행하세요:
ALLOWED_ACTIONS = {
"lights.on": "light.hue.on",
"lights.off": "light.hue.off",
...
마지막 검증 단계는 매우 중요합니다. 모델은 해석(interpretation)에는 유용할 수 있지만, run()에 임의로 접근할 수 있어서는 안 됩니다.
응답 폴백 (Response fallback)
요청이 정의된 명령 중 어느 것과도 일치하지 않는 경우, 일반적인 SpeechRecognizedEvent 훅(hook)을 사용하여 요청을 AI 플러그인으로 전달하고, 텍스트 음성 변환 (Text-to-Speech, TTS) 플러그인을 통해 응답을 음성으로 렌더링할 수 있습니다.
import logging
from platypush import run, when
from platypush.events.assistant import SpeechRecognizedEvent
...
LLM의 응답이 물음표로 끝나면, 어시스턴트는 자동으로 후속 명령을 대기하며 새로운 SpeechRecognizedEvent를 발생시킵니다.
듣는 동안 음악 일시 정지하기
대화가 시작될 때 음악을 일시 정지하고, 어시스턴트가 작업을 마친 후 다시 재생하는 것은 아주 좋은 디테일입니다.
from platypush import run, when
from platypush.events.assistant import (
ConversationEndEvent,
...
이렇게 하면 상호작용이 훨씬 덜 어색하게 느껴집니다. 웨이크 워드(wake word)가 호출되면, 음악 볼륨이 줄어들거나 일시 정지되고, 명령이 인식되어 답변이 출력된 후, 몇 초 뒤에 음악이 다시 재생됩니다.
완전히 로컬로 전환하기
위의 설정만으로도 핫워드 감지 (hotword detection), 음성-텍스트 변환 (Speech-to-Text, STT), 자동화 및 텍스트-음성 변환 (Text-to-Speech, TTS)은 이미 로컬에서 작동합니다. 유일한 비로컬(non-local) 구성 요소는 openai 플러그인이 OpenAI의 서버를 가리키고 있는 경우입니다.
마지막 단계까지 로컬로 만들려면, OpenAI 호환 API를 제공하는 모델 서버를 실행하세요. Ollama, llama.cpp server, vLLM, LocalAI 모두 /v1/chat/completions의 특정 버전을 제공할 수 있습니다.
예를 들어, Ollama를 사용하는 경우:
ollama pull llama3.1:8b
ollama serve
그러면 OpenAI 호환 엔드포인트는 보통 다음에서 사용할 수 있습니다:
만약 사용 중인 Platypush openai 플러그인 버전이 커스텀 API 기본 URL (base URL)을 지원한다면, 설정만 변경하면 됩니다:
openai:
model: llama3.1:8b
base_url: http://127.0.0.1:11434/v1
만약 그렇지 않다면, 어시스턴트의 나머지 부분은 정확히 동일하게 유지하고 폴백 액션 (fallback action)만 아주 작은 로컬 요청으로 교체하면 됩니다:
openai:
model: llama3.1:8b
base_url: http://127.0.0.1:11434/v1
이것만으로도 어시스턴트를 완전히 로컬 스택 (local stack)으로 전환하기에 충분합니다:
Raspberry Pi를 사용한다면 여전히 현실적인 기대치를 유지해야 합니다. 호트워드 감지 (Hotword detection), Vosk 및 Piper는 소형 기기에서도 잘 작동합니다. 로컬 LLM (Local LLMs)이 가장 무거운 부분입니다. 충분한 RAM을 갖춘 Pi 5는 작은 양자화 모델 (quantized models)을 실행할 수 있지만, 지연 시간 (latency)이 클라우드 모델이나 GPU 기반 워크스테이션처럼 느껴지지는 않을 것입니다. 많은 홈 오토메이션 (home automation) 워크플로우의 경우, LLM은 폴백 (fallback) 역할만 수행하고 빈번한 명령들은 결정론적 (deterministic)으로 유지되기 때문에 이는 수용 가능한 수준입니다.
이 아키텍처가 시간이 지나도 유효한 이유
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기