
로컬 LLM 벤치마크가 모든 모델에서 만점을 기록했다. 그것이 이 프로젝트에서 가장 유용했던 실패였다
요약
로컬 LLM 선정을 위한 벤치마크 테스트 중 모든 모델이 만점에 가까운 점수를 기록하며 변별력이 상실된 사례를 분석합니다. 벤치마크가 모델 간의 차이를 해상하지 못할 때 발생하는 오류를 지적하며, 유효한 평가를 위한 프로토콜의 중요성을 강조합니다.
핵심 포인트
- 모든 모델이 만점을 받는 벤치마크는 모델 품질이 아닌 문제 난이도를 측정할 뿐임
- 모델 간 파라미터 크기 차이에도 점수가 수렴한다면 테스트의 해상도를 의심해야 함
- 변별력 있는 벤치마크를 위해 다단계 추론과 언어적 뉘앙스를 포함한 고난도 설계 필요
- 실패한 실험 데이터와 그 원인을 기록하는 것이 방법론적으로 더 가치 있음
좁혀진 실무적인 질문에서 시작했습니다. 일본 기업이 온프레미스(On-premise)로 실제로 구동해야 할 로컬 LLM은 무엇인가. 후보 4개, 참여하지 않는 독립적인 저지(Judge), 3가지 축 — 품질·레이턴시(Latency)·VRAM.
첫 번째 실행에서는 모든 모델이 거의 만점에 가까운 점수를 반환했습니다. Faithfulness는 모든 모델이 1.0000. Hit rate는 0.90~1.00. 저지 일치율 κ = 1.0.
깔끔한 결과로 보였습니다. 실제로는 망가진 벤치마크였습니다 — 그리고 그 이유를 밝혀낸 것이 그 어떤 리더보드(Leaderboard)의 숫자보다 더 많은 것을 가르쳐 주었습니다.
너무 좋아서 믿기 힘든 숫자
이것이 v1, 20문항, 4개 모델입니다.
| 모델 | 파라미터 | Faithfulness | Hit rate |
|---|---|---|---|
| elyza-jp-8b | 8.0B | 1.0000 | 0.90 |
| ... |
8B 모델과 31B 모델이 동일한 점수를 냈다면 경보가 울려야 합니다. 이 정도로 용량 차이가 큰 모델들이 동일한 점수로 수렴한다는 것은, 거의 항상 테스트가 차이를 해상(Resolution)하지 못하고 있음을 의미합니다 — 차이가 사라진 것이 아니라 말입니다.
변별력(Discrimination)의 내역이 결정적이었습니다. 90%의 문제는 모든 모델이 정답, 10%는 일부 정답, 0%는 어떤 모델도 오답을 내지 못했다. 10문제 중 9문제를 후보군 사이에서 구분할 수 없는 벤치마크는 후보를 측정하고 있는 것이 아닙니다. 문제가 쉬운지 여부를 측정하고 있을 뿐입니다. 실제로 쉬웠습니다.
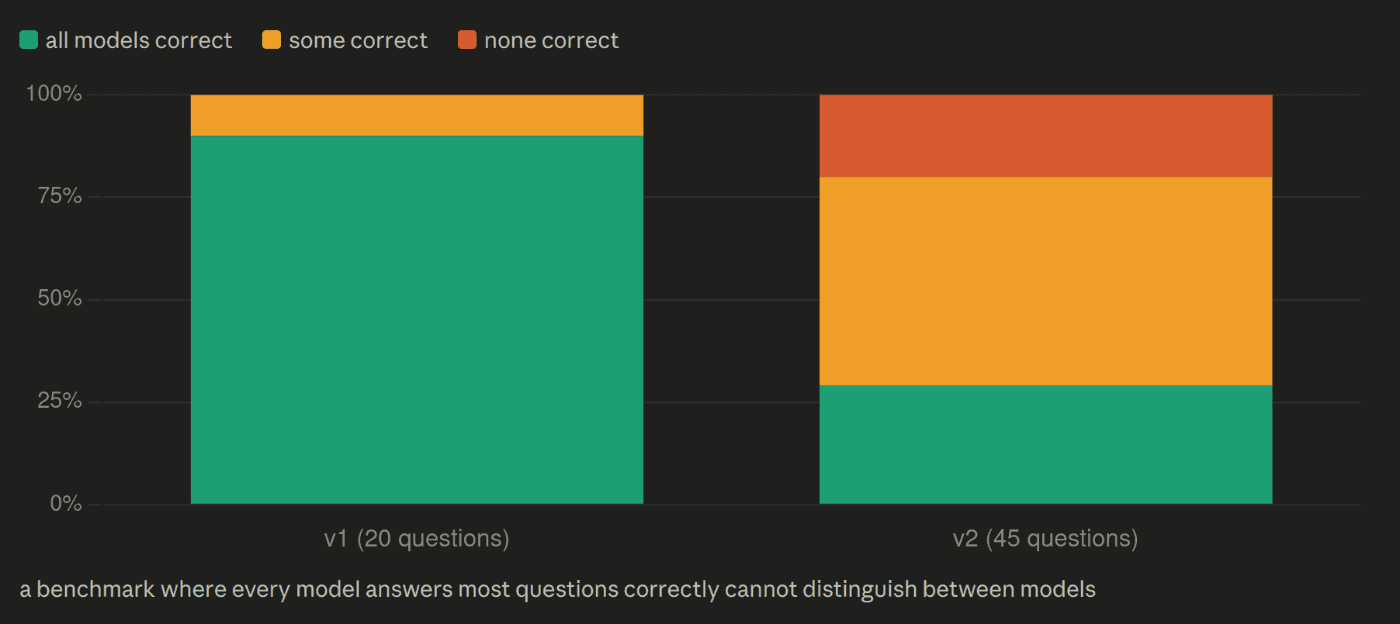
그리고 안심시켜 줄 것처럼 보였던 κ = 1.0의 저지 일치율은요? 두 명의 저지가 거의 모든 문제에 만점을 줄 때, 완전 일치는 자명한 해답일 뿐 강력한 신호가 아닙니다. 분산(Variance)이 제로라면 통계량 자체가 무의미해집니다. 여기서의 κ = 1.0은 "저지가 일치했다"가 아니라 "일치할 것도 없이 의견의 차이가 발생할 여지가 없었다"였습니다.
모두에게 만점을 주는 벤치마크는 정보 측면에서 벤치마크가 없는 것과 같습니다. 어떤 모델을 선택해야 할지에 대한 신호를 포함하고 있지 않으므로, 선정 판단을 할 수 없습니다.
왜 이것이 부끄러운 부분이 아니라 흥미로운 부분인가
유혹은 문제를 조용히 수정하여 깔끔한 v2 표만 공개하는 것입니다. 저는 반대로 하고 있습니다 — v1을 리포지토리(Repository)에 남겨두고, 실패를 기록한 ADR(Architecture Decision Record)을 첨부합니다. 실패야말로 방법론의 콘텐츠이기 때문입니다.
4개 모델을 문제 세트에 통과시켜 표를 내놓는 것은 누구나 할 수 있습니다. 정말 어렵고 정말 드문 일은, 숫자가 훌륭해 보일 때 자신의 측정이 망가져 있다는 것을 깨닫는 것입니다. 공개되어 있는 "로컬 LLM 비교"의 대부분은 변별력을 한 번도 체크하지 않습니다. 높은 점수의 표를 보여주며 그것을 벤치마크라고 부릅니다. 그 표의 모든 모델이 90% 이상이라면, 보고 있는 것은 모델의 품질이 아니라 문제의 난이도입니다.
따라서 진짜 성과물은 "모델 X가 이겼다"가 아닙니다. 프로토콜입니다. 모델 선정 벤치마크는 비교하는 모델을 해상할 수 있을 때에만 유효하며 — 그 사실을 어떤 점수를 믿기 전에도 명시적으로 테스트해야 한다.
변별력을 다시 만들기
v2에서는 문제 세트를 후보를 분리할 수 있도록 의도적으로 어렵게 설계한 45문항으로 교체했습니다.
- 단일 사실 검색이 아닌
다단계 추론 (Multi-step reasoning) -
일본어의 뉘앙스 — 경어, 전문 용어, 의도적으로 모호한 표현 -
경계선상의 사실 — 환각 (Hallucination)을 일으키기 쉬운 구체적인 날짜나 수치
목표는 "어려움을 위한 어려움"이 아닙니다. 특정 분포를 만드는 것입니다. 최강의 모델이라도 몇 개는 틀려야 합니다. v1은 형태가 잘못되었습니다 (90/10/0). v2는 **전체 정답 29%, 일부 정답 51%, 전체 오답 20%**에 안착했습니다. 아무도 풀지 못하는 20%가 상위권에서 해상도를 제공하는 부분입니다.
이것이 v2입니다.
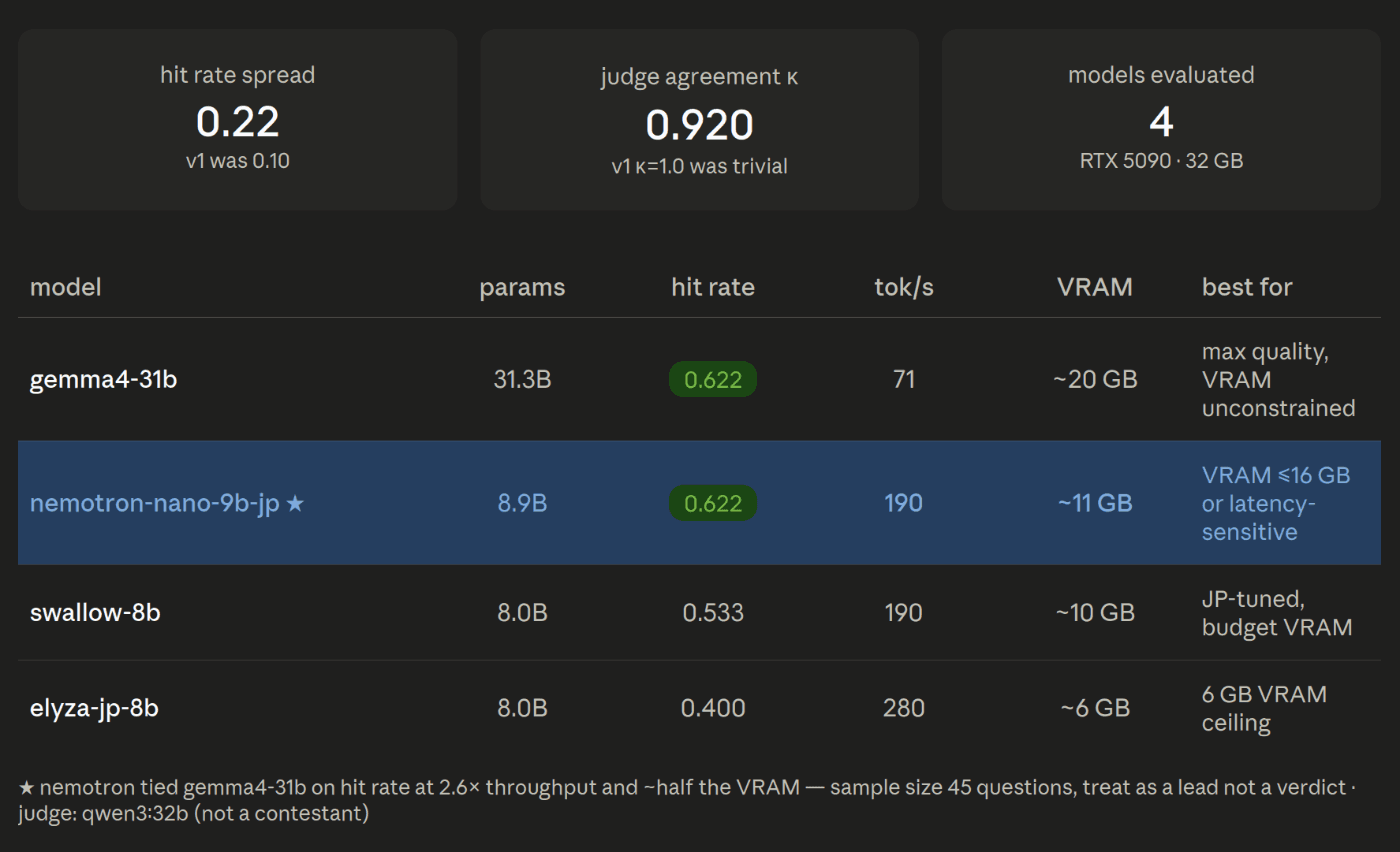
Hit rate의 편차는 0.10 (v1)에서 0.22 (v2)로 늘어났습니다. 모델이 실제로 분리되기 시작했습니다. 그리고 중요한 저지 일치율은, κ 가 1.0에서 0.920으로 낮아졌습니다.
이 하락은 개선입니다. v1의 κ = 1.0은 분산 제로의 아티팩트(Artifact)였습니다. v2의 κ = 0.920은 실제 불일치 위에서 계산된 진짜 일치 수치 — 저지 신뢰성의 통계량이 처음으로 의미를 갖는 버전입니다. 완전한 저지 일치를 보고하는 벤치마크를 본다면, 저지가 일치하기 위한 분산이 애초에 존재했는지를 물어야 합니다.
주목할 만한 발견 (주의사항 포함)
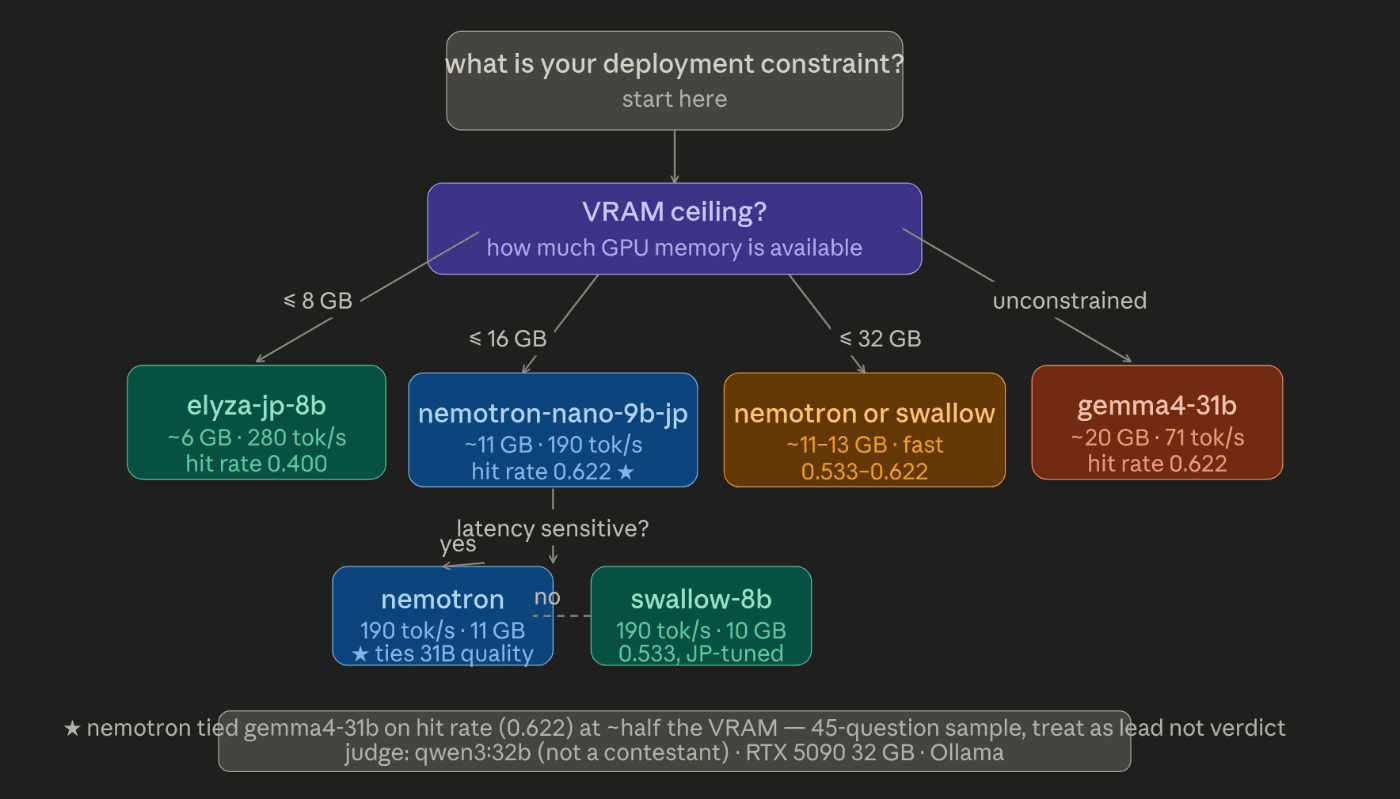
두 번 확인한 점. nemotron-nano-9b-jp(8.9B)가 hit rate(적중률)에서 gemma4-31b(31.3B)와 나란히 기록했다 — 각각 0.622 — 심지어 VRAM은 약 절반 수준(약 11GB 대 약 20GB)이며, 속도는 약 2.6배(warm 상태에서 190 대 71 tokens/s) 더 빨랐습니다.
이것이 유지된다면, 이는 단순한 원시 능력(raw capability)이 아니라 *제약 조건(constraints)*에 따라 모델을 선정해야 하는 이유 그 자체입니다. 가장 큰 모델이 자동으로 올바른 배포(deployment) 선택이 되는 것은 아닙니다. VRAM 상한, 레이턴시(latency) 목표, 처리량(throughput) 요구 사항 하에서는, 31B 모델과 대등한 성능을 내는 9B 규모의 일본어 특화 모델이 더 나은 판단일 수 있습니다. 그리고 이는 "어떤 모델이 가장 강력한가"라는 프레임워크 안에서는 결코 보이지 않는 부분입니다.
솔직한 주의사항을 먼저 말씀드립니다. 이것은 단 45개의 문항입니다. nemotron과 gemma4의 타이(tie) 기록은 이 세트에서의 관찰 결과일 뿐, 확정된 결과가 아닙니다. 더 큰 샘플을 통한 확인이 필요하며, 이는 행동해야 할 결론이 아니라 추적해야 할 단서로서 보고하는 것입니다. 프로토콜의 핵심은 바로 샘플이 뒷받침하지 못하는 결과를 주장하지 않는 데 있습니다.
저지(Judge) 구성 (회의적인 독자들을 위해)
주의 깊은 독자라면 가장 먼저 "누가 채점했는가, 그리고 무언가가 자기 자신을 채점했는가"를 물을 것입니다.
주 저지(Main Judge): qwen3:32b — 참가자가 아님. 중국 모델이며, 저의 배포/콘텐츠 분리 규칙에 따라 일본 온프레미스(on-premise) 기본 구성에 포함되지 않으므로, 경주에서 빠지는 대신 채점 역할을 수행합니다. 이를 통해 자기 선호 편향(self-preference bias)을 회피합니다. 어떤 참가자도 자신이나 동족의 답안을 채점하지 않습니다. -
교차 검증(Cross-validation): gemma4:31b가 20개 문항의 서브셋을 재채점하여 주 저지의 신뢰성을 확인합니다(위의 κ = 0.920). gemma4는 참가자이므로 저지 프로토콜의 검증 용도로만 사용하며, 자신의 채점에는 절대 사용하지 않습니다.
32GB 메모리에는 두 모델을 동시에 상주 시킬 수 없으므로(qwen3:32b 약 29GB, gemma4:31b 약 19GB), 전체 과정은 2-패스(2-pass) 구성으로 진행됩니다. 모든 답변을 생성하고 퇴피시킨 뒤, 저지를 로드하여 모든 답변을 채점합니다. 모델별로 캐싱되므로 재개가 가능합니다.
모델 선정을 위해 벤치마크를 수행하는 분들에게 전하고 싶은 것
어떤 점수를 믿기 전에 변별력(discrimination)을 확인하십시오. 대부분의 문제가 모든 후보 모델에 대해 정답으로 처리된다면, 측정하고 있는 것은 모델의 품질이 아니라 문제의 난이도입니다. -
만점은 녹색 신호가 아니라 적색 신호입니다. 특히 모델 크기 차이가 크게 날 때 더욱 그렇습니다. -
저분산(low variance) 세트에서의 완전한 저지 일치(κ=1.0)는 무의미합니다. 실제 불일치가 존재하는 상황에서의 약간 낮은 κ 값이 더 가치 있습니다. -
원시 능력이 아니라 제약 조건으로 선택하십시오. "가장 강력한 것"과 "이 배포 환경에 올바른 것"은 별개의 질문입니다. -
실패한 버전도 남겨두십시오. 망가진 벤치마크에서 작동하는 것으로 나아가는 과정이야말로 누구도 조작할 수 없는 부분입니다.
전체 프로토콜, v1의 실패, v2의 수정, 모든 원시 채점 출력물:
https://github.com/elvisyao007/eval-driven-llm/tree/main/reports/model-selection-v1
자매 도구 — 애초에 리트리벌(retrieval) 지표가 신뢰할 수 있는지 감사하는 의존성 제로(zero-dependency) 라이브러리 — 는 eval-sanity에 있습니다.
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기