
TSMC의 팹 확장 로드맵 분석 — 다중 팹 N2 램프업, CoWoS, SoIC 및 병목 현상 해소
요약
TSMC가 AI 프로세서 및 첨단 로직 칩 수요에 대응하기 위해 공격적인 팹 확장 로드맵을 발표했습니다. N2 공정 기술의 전례 없는 램프업과 대만, 미국, 일본, 독일을 아우르는 글로벌 생산 능력 확대를 통해 시장 지배력을 강화할 계획입니다.
핵심 포인트
- N2 공정 기술을 활용한 5개 시설 동시 양산 목표
- 연간 팹 건설 및 전환 속도를 기존 대비 2배로 가속화
- 대만, 미국, 일본, 독일 중심의 글로벌 생산 거점 확대
- 첨단 패키징 및 선단 노드 웨이퍼 생산 능력 극대화

불과 몇 년 전만 해도 우리가 TSMC를 언급할 때는 '세계 최대의 파운드리 (foundry)'라고 불렀으며, 이는 Intel이 여전히 세계 최대의 첨단 로직 칩 생산자임을 암시했습니다. 하지만 지난 10년 동안 용량 확장에 거의 2,400억 달러를 투자한 TSMC는 현재 수십 개의 300mm 팹 (fabs)을 보유한 9개의 사이트를 운영하고 있으며, 이 중 상당수는 Intel*보다 EUV (극자외선) 기반 공정 기술을 사용하여 수십 배 더 많은 웨이퍼를 처리할 수 있어, TSMC를 세계 최대의 첨단 로직 칩 제조사로 만들었습니다.
세계 최대의 첨단 AI 프로세서 제조사가 되기 위해서는 TSMC가 경쟁사인 Intel 및 Samsung Foundry를 상대로 공정 기술 측면에서, 그리고 아마도 훨씬 더 중요한 측면인 생산 용량 측면에서 앞서 나가야 합니다.
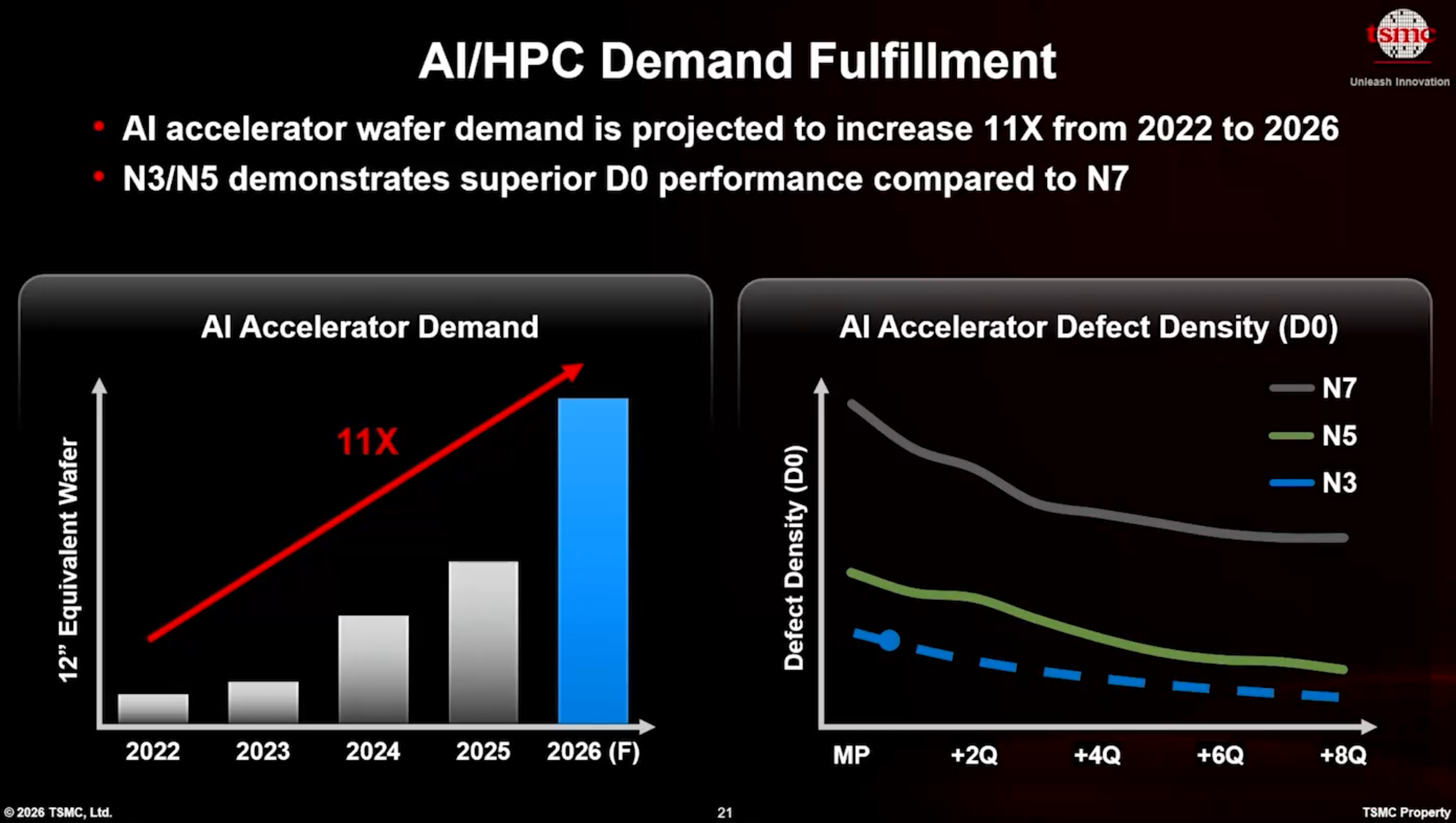
따라서 TSMC는 AI 프로세서, 최첨단 노드에서 제조되는 로직 칩, 그리고 첨단 패키징 (advanced packaging)에 대한 폭발적인 수요를 충족하기 위해 경쟁하며, 회사 역사상 가장 공격적인 제조 확장을 시작했습니다.
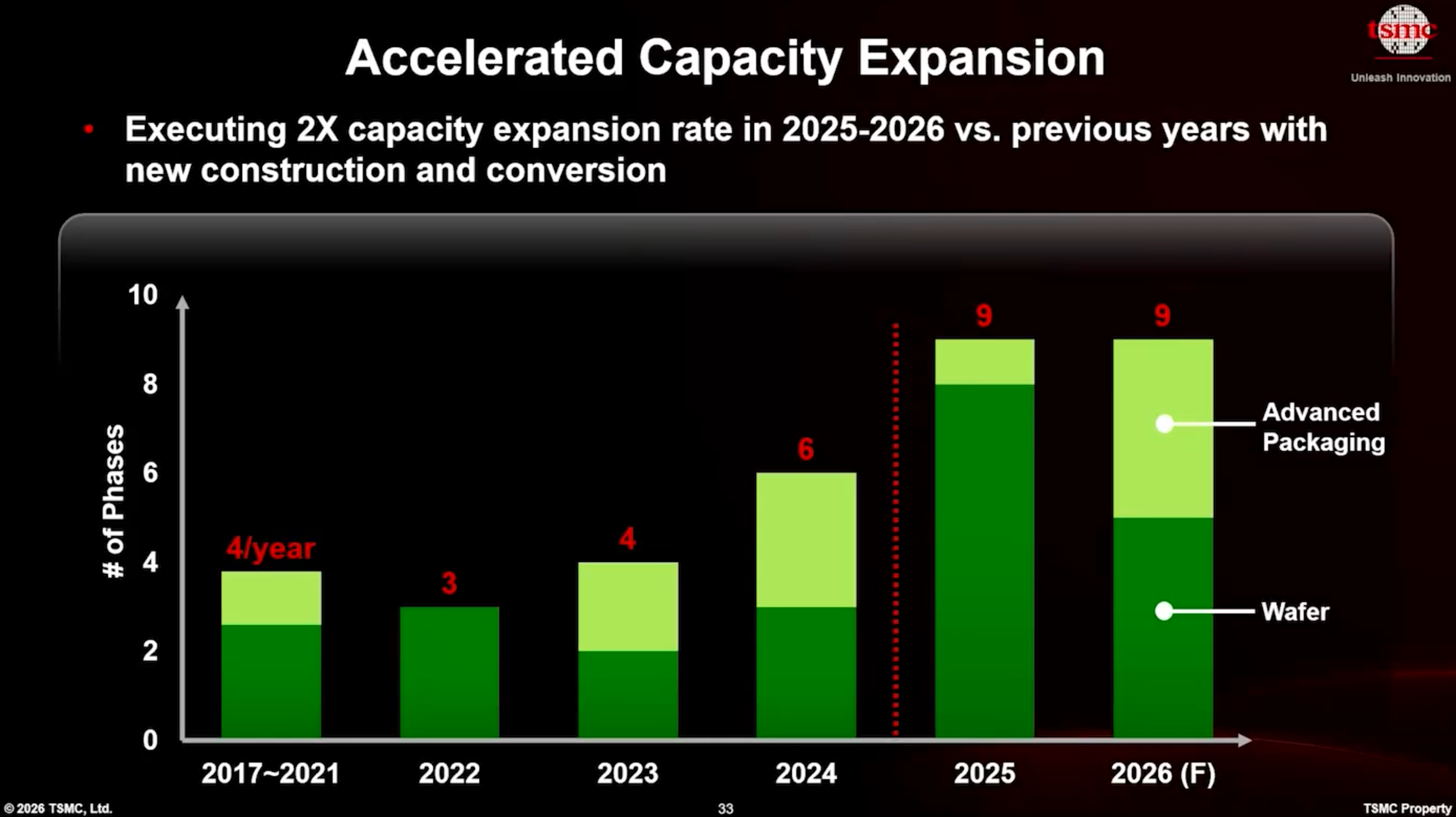
TSMC Tech Symposium 2026 제조 발표 기간 동안, 회사는 2025년~2026년에 연간 평균 4개 단계였던 건설 속도를 사실상 두 배로 높여 매년 9개의 팹 단계를 건설하거나 전환하고 있다고 밝혔습니다. 회사는 대만, 미국, 일본, 독일에서 동시에 새로운 팹을 건설하거나 가동률을 높이고(ramping) 있습니다. 또한, 기존 시설의 생산성을 향상시키기 위한 새로운 방법들을 도입하고 있습니다.
| 1, 2 |
| 2 |
| 3, 4 |
| ... |
N2 램프업 (ramp): 2029년까지 월간 수십만 장의 웨이퍼
TSMC 확장 계획의 핵심은 N2 공정 기술입니다. 현재 이 회사는 TSMC의 글로벌 R&D 센터 인근 신주(Hsinchu)에 위치한 Fab 20 1단계 및 2단계, 그리고 가오슝(Kaohsiung)의 Fab 22 1단계 등 두 곳에서 N2를 사용한 칩 생산을 램프업 (ramp-up)하고 있습니다. 세 곳의 시설에서 동시에 선단 노드 (leading-edge node)를 램프업하는 것은 파운드리 (foundry) 업계에서 매우 이례적인 일입니다. 또한 회사는 곧 Fab 22 2단계를, 올해 말까지는 Fab 22 3단계를 램프업할 계획입니다. 결과적으로 Fab 22 4단계도 가동될 예정입니다. 그 결과, TSMC는 첫해에 5개 시설에서 N2 공정 기술의 양산을 시작하는 것을 목표로 하고 있으며, 이는 전례 없는 규모입니다.
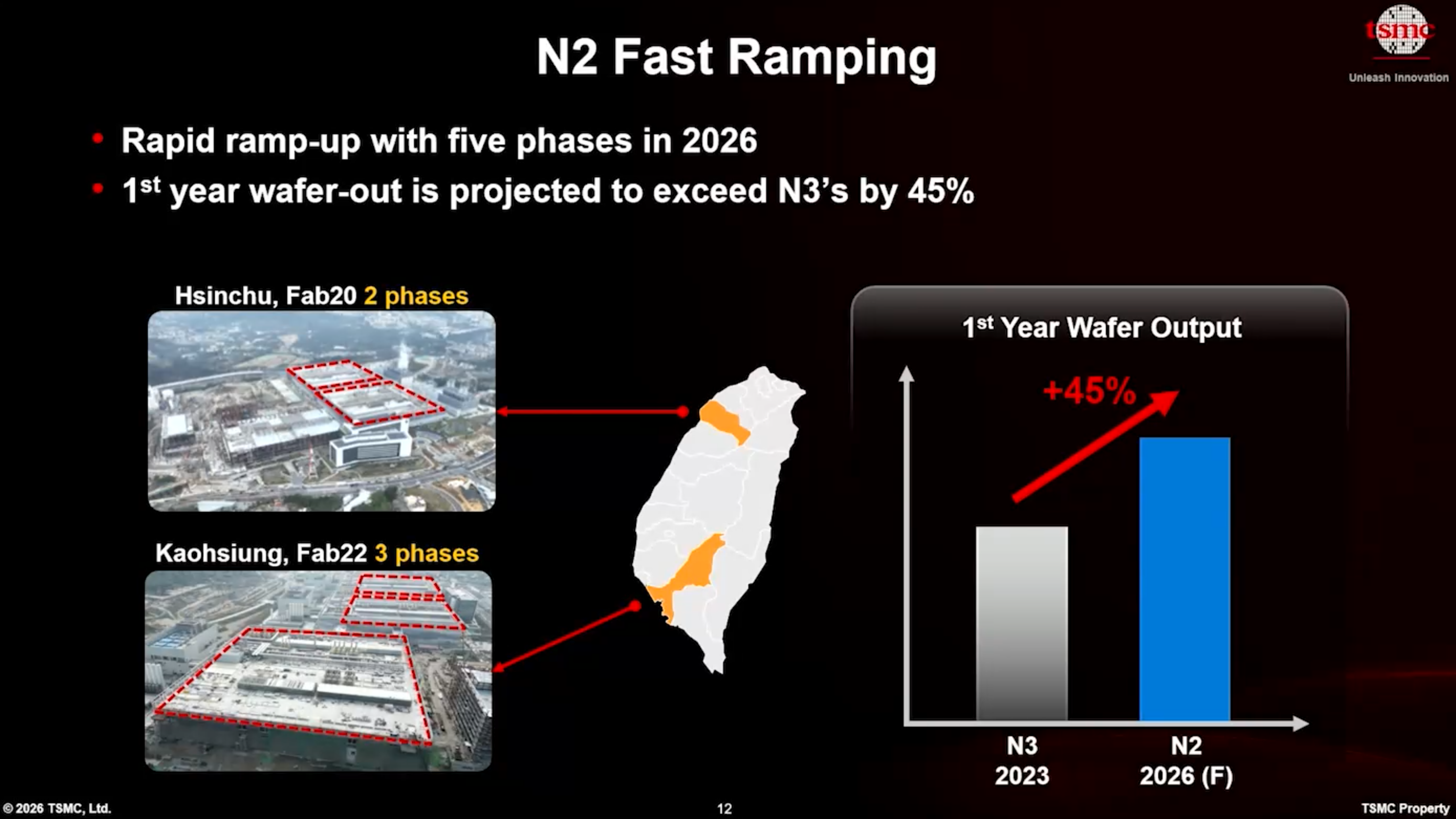
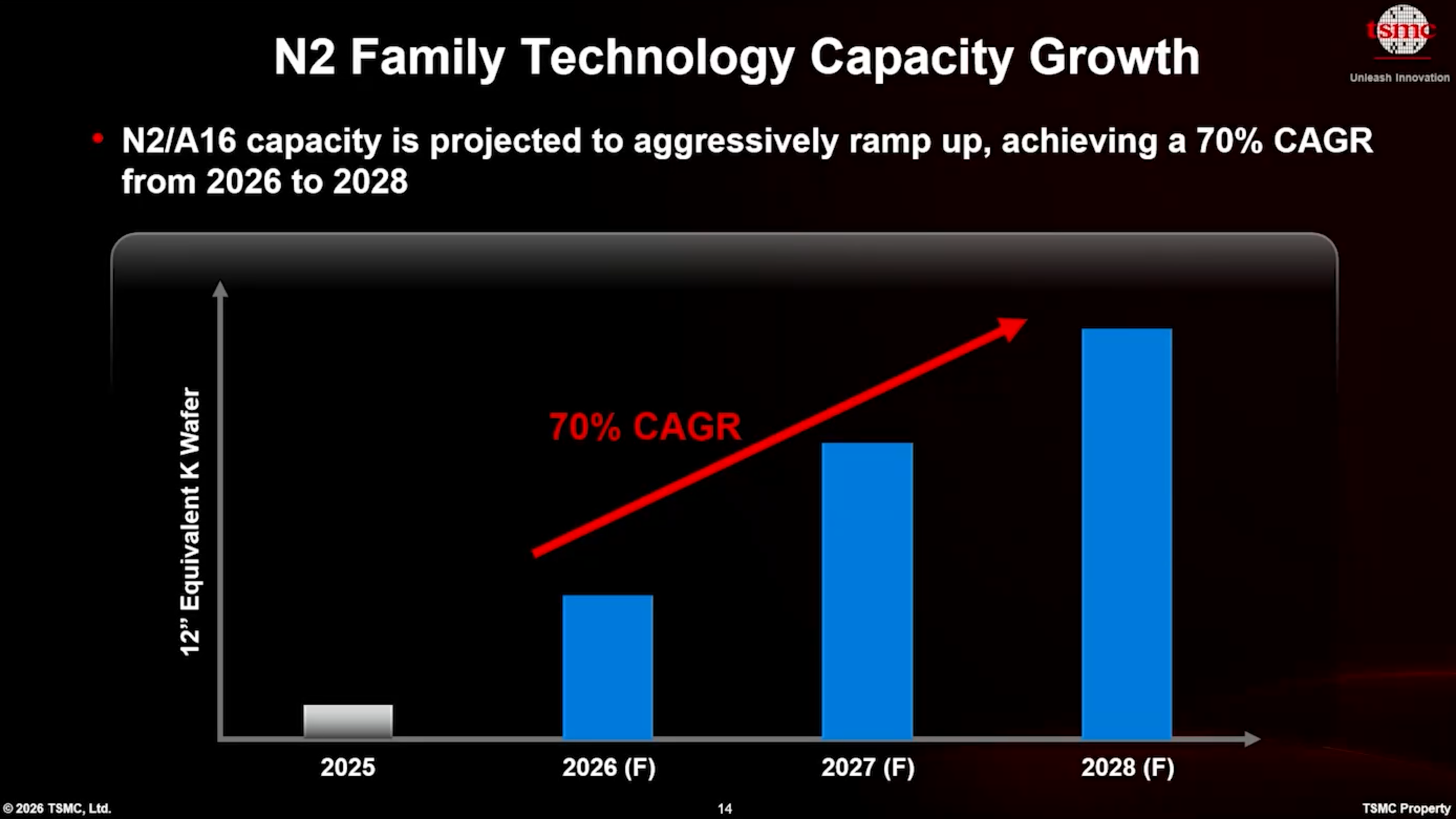
이러한 공격적인 램프업의 결과로, TSMC는 첫해 N2 웨이퍼 아웃 (wafer-out) 생산 능력이 N3B보다 45% 더 높을 것으로 예상하고 있습니다. 2023년~2024년의 보고서에 따르면, TSMC는 2023년에 Fab 18의 두 또는 세 단계를 통해 N3B 생산을 램프업했으며, 그해 말까지 월간 약 60,000장의 웨이퍼 투입량 (wafer starts)에 도달했습니다. 만약 이 보고서들이 정확하다면, TSMC는 올해 말까지 N2 생산 능력이 월간 약 90,000장의 웨이퍼 투입량 (WSPM)에 도달할 것으로 예상합니다. 이는 Intel의 18A 대응 가능 시설인 Fab 52의 완전 램프업된 생산 능력(약 40,000 WSPM으로 추정)을 상회하는 수치입니다.
더욱 인상적인 점은 TSMC가 2028년까지 N2/A16 대응 가능 생산 능력을 매년 70%씩 늘릴 계획이라는 것이며, 이는 2029년에 수십만 WSPM에 달함을 의미합니다.
방대한 생산 능력에 도달하는 것 외에도, 5개의 팹 단계(fab phases)를 동시에 램프업(ramp-up)함으로써 TSMC는 리스크를 완화할 수 있습니다. 만약 하나의 팹 단계에서 오염 문제, 장비 고장 또는 수율(yield) 문제가 발생하더라도, 전체 N2 공급망이 붕괴되지는 않을 것입니다. 이는 국가의 서로 다른 지역에 위치한 두 곳의 사이트에서 생산을 램프업하는 경우에도 동일하게 적용됩니다. 지진이나 유틸리티(utility) 장애가 발생하여 한 곳의 생산이 중단되거나 수율 손실이 발생할 수 있지만, 다른 곳에는 영향을 미치지 않을 것입니다. 이러한 리스크 완화는 지속적인 공급을 요구하는 Apple, AMD, Nvidia 또는 Qualcomm과 같은 고객사들에게 매우 중요합니다. 이러한 팹 단계들을 직렬(serial)이 아닌 병렬(parallel)로 램프업할 때 얻을 수 있는 잠재적인 또 다른 이점이 있으니, 계속해서 읽어보시기 바랍니다.
N2 램프업: One Team과 Super Manufacturing Platform
이러한 이례적인 램프업 전략은 TSMC의 두 가지 프로그램 덕분에 가능해진 것으로 보입니다. 바로 R&D와 팹 운영 간의 협업인 "One Team"과, 여러 팹(또는 팹 단계)이 하나처럼 작동할 수 있게 하는 Super Manufacturing Platform (SMP)입니다. 이는 Intel의 "Copy Exactly"와 유사할 가능성이 높습니다. TSMC는 One Team과 SMP에 대한 세부 사항을 많이 공유하지 않았지만, 우리는 몇 가지 합리적인 추측을 할 수 있습니다.


One Team은 기술 개발 및 램프업 과정에서 R&D, 공정 통합(process integration), 장비 관리 및 대량 제조(high-volume manufacturing) 전문 지식을 연결하는 글로벌 제조 지식 전수 시스템입니다. 피드백 루프(feedback loops)를 가속화하기 위해, TSMC는 노드(node) 개발 단계에서 비교적 일찍 제조 팀을 투입하여 R&D 팀이 팹에서 가능한 수준에 맞춰 작업을 조정하도록 할 가능성이 높습니다. 그 결과, 수율 학습(yield learning), 공정 최적화 및 장비 생산성 향상을 한 곳의 팹에서 빠르게 수행한 후 다른 팹으로 전수할 수 있습니다. TSMC는 한 팹에서 다른 팹으로 기술을 전수하는 데 통상적으로 소요되는 시간은 공개하지 않았으나, One Team을 통해 N3 대비 기술 전수 속도가 20% 빨라졌다고 밝혔습니다.
또한, TSMC의 모든 GigaFab 사이트는 이제 Super Manufacturing Platform (SMP)에 의존하고 있습니다. 이는 본질적으로 중앙 집중식 제조 제어 시스템으로, 표준 공정 레시피(process recipes), 장비 구성(tool configurations), 계측(metrology) 및 수율 관리 흐름(yield management flows)을 통해 여러 팹(fab)이 하나의 거대한 동기화된 팹처럼 작동하도록 만듭니다. 이를 통해 TSMC는 팹 간 생산 이전을 더 쉽게 수행하고, 새로운 노드(node)를 더 빠르게 램프업(ramp-up)하며, 수율 개선 사항을 국지적(local)인 수준이 아닌 전 세계적으로 도입할 수 있고, 칩 생산지가 한 팹에서 다른 팹으로 이동할 때 발생하는 고객의 재인증(requalification) 작업을 줄일 수 있을 것입니다.
게다가 모든 팹 단계는 각자의 장비 동작 데이터(tool behavior data), 결함 밀도 데이터(defect density data), 공정 윈도우 통계(process window statistics) 및 수율 학습 정보(yield learning information)를 생성하므로, SMP와 One Team이 구축되어 있다면 여러 단계의 동시 램프업이 실제로 수율/결함 학습을 가속화할 수 있습니다. 결과적으로 이는 팹 단계의 램프업 속도를 높일 수 있습니다.
향후 몇 년간 N2/A16 용량에서 70%의 연평균 성장률(CAGR)을 기록하는 것은 최첨단 제조 분야에서 매우 공격적인 램프업입니다. TSMC의 One Team 구조와 SMP 같은 체계가 없다면, Fab 22의 여러 단계, Fab 20, 그리고 궁극적으로 애리조나의 Fab 21 phase 3에 걸쳐 이 정도 규모의 확장을 조정하는 것은 조직적(운영 제어) 관점과 경제적(수율 학습, 공정 윈도우 등) 관점 모두에서 거의 불가능했을 것입니다.
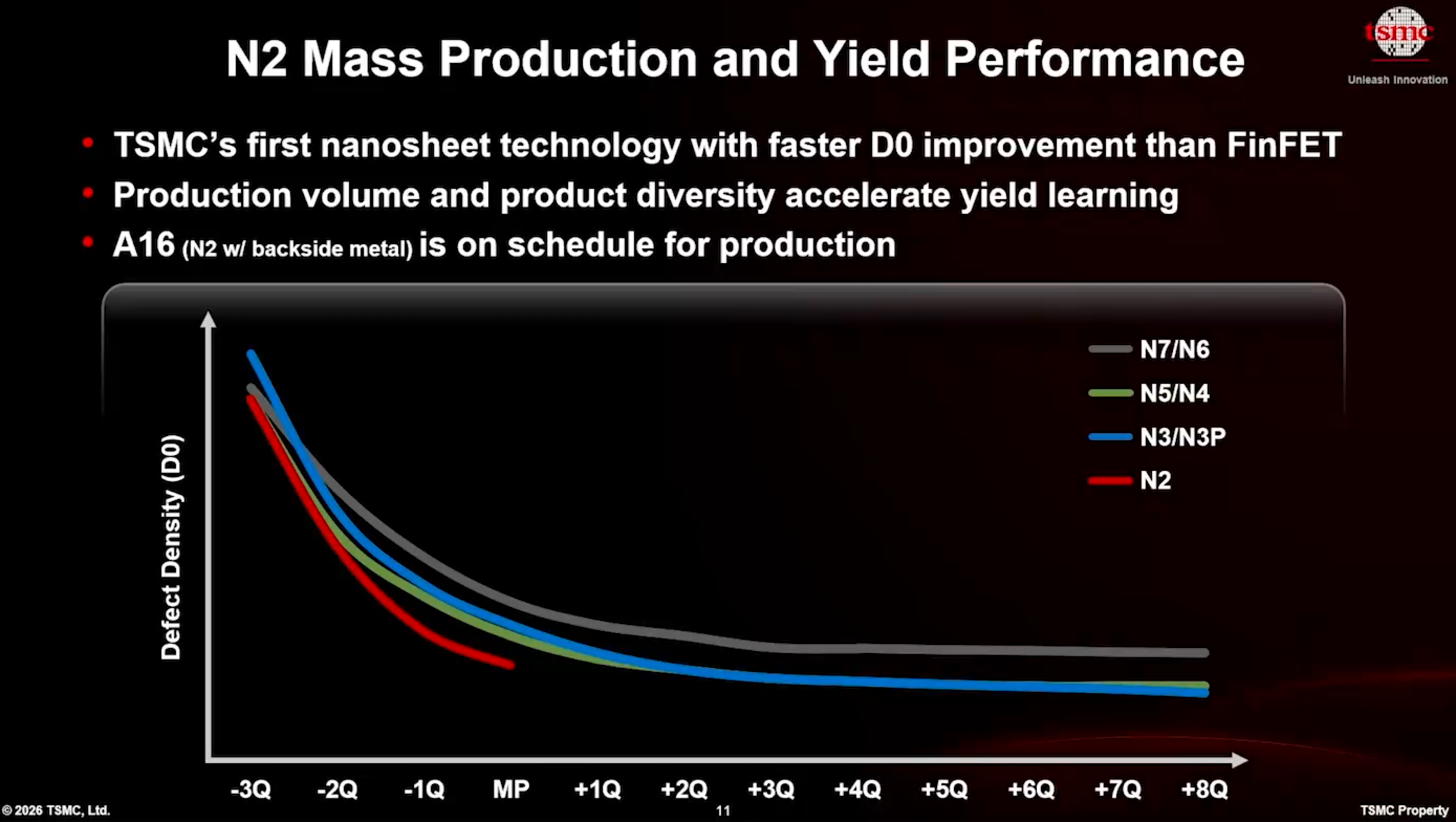
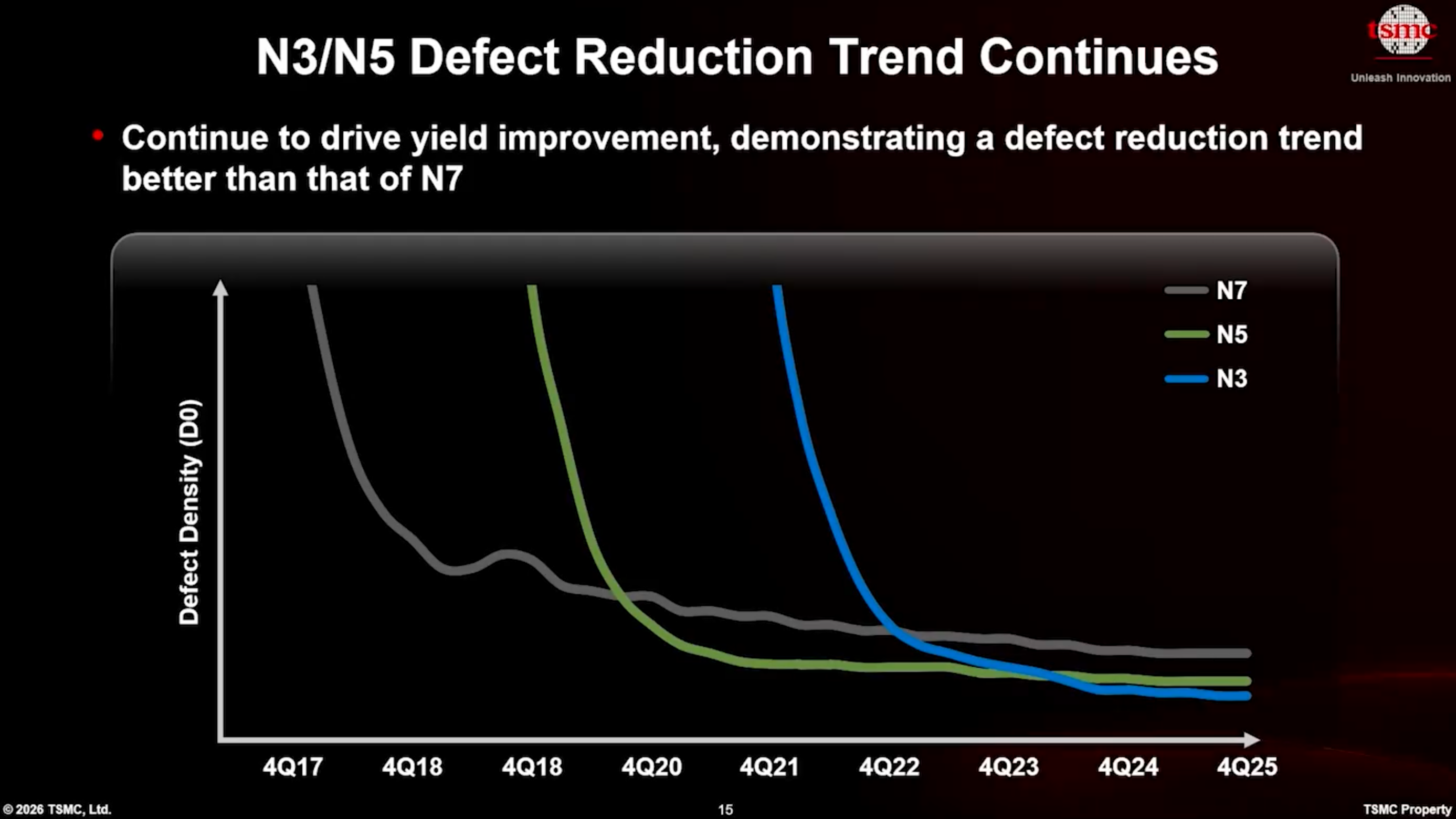
TSMC는 또한 Gate-all-around (GAA) 나노시트(nanosheet) 트랜지스터와 관련된 복잡성이 현저히 높음에도 불구하고, N2가 N3보다 더 나은 수율 학습 곡선(yield learning curve)을 달성하고 있다고 언급했으며, 이는 다시 회사가 사용하는 혁신적인 접근 방식 덕분이라고 밝혔습니다.
N2를 넘어: A14, A13, 그리고 A12
TSMC의 N2/N2P/N2X/N2U/A16 생산은 주로 Fab 20 phase 1 및 2, Fab 22 phase 1, 2, 3, 4, 그리고 어느 정도는 Fab 21 phase 3에 집중될 것입니다. 그러나 A14, A13, A12와 같이 2nm급을 넘어서는 노드(A16은 본질적으로 후면 전력 공급 네트워크(backside power delivery network)를 갖춘 N2P임)의 경우, TSMC는 Fab 21 phase 3을 건설한 후 대만 중부에 최소 4개의 단계를 갖춘 완전히 새로운 Fab 25 사이트를 건설할 예정입니다.

A14는 2028년 말에 대량 생산 (High-volume production)을 시작할 예정이므로, TSMC가 Fab 20 phase 3과 Fab 25 phase 1 모두에서 이를 램프업 (Ramp up)할 가능성이 높습니다. 하지만 용량 확장 (Capacity expansion)에 대한 회사의 공격적인 접근 방식을 고려할 때, TSMC는 다시 한번 우리를 놀라게 할 수도 있습니다. 또한, TSMC가 N2/A16 대응 팹 (Fabs)을 차세대 노드로 어떻게 업그레이드할 계획인지(만약 한다면)는 아직 알 수 없습니다.
N2를 넘어선 확장
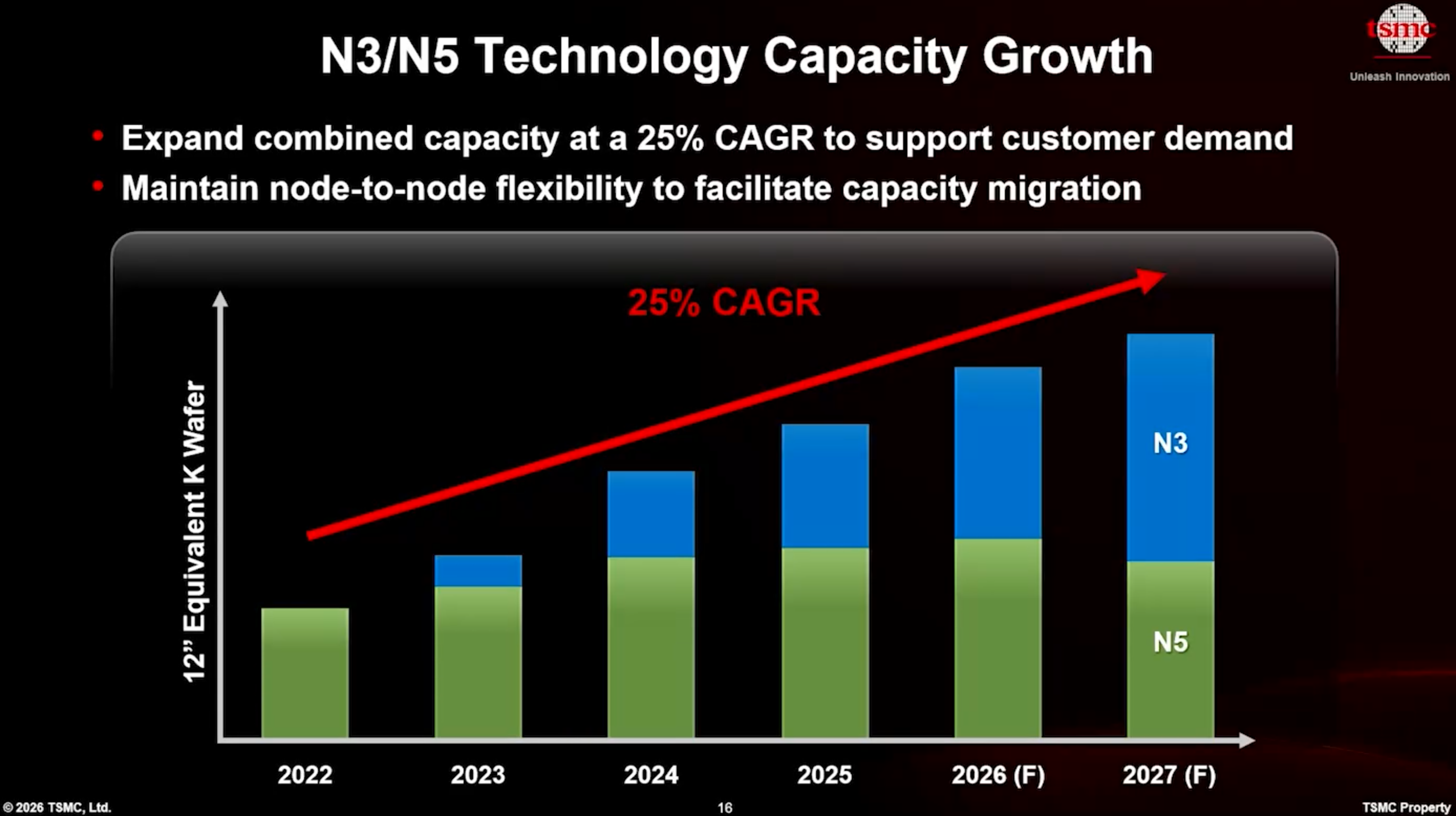
확장은 N2 생산 노드 및 후속 기술에만 국한되지 않습니다. TSMC는 2022년부터 2027년까지 N3와 N5의 합산 용량을 연평균 성장률 (CAGR) 25%로 지속적으로 성장시키고 있습니다. 즉각적인 수요에 대응하기 위해, 회사는 일부 N5 용량을 N3 생산으로 전환하고 있는데, 이는 N3가 N5에 사용된 장비의 85%~90%를 재사용하기 때문에 특별히 비용이 많이 들지 않습니다. 더욱이, TSMC의 N3 및 N5 용량 상당 부분이 Fab 18(N5 4단계, N3 4단계)에 집중되어 있기 때문에, 물류적 관점에서 일부 N5 용량을 N3로 전환하는 것은 상대적으로 쉽습니다.
AI는 도움을 주기 위해 존재합니다 (더 많은 AI 프로세서를 구축하기 위해)
N5를 N3 용량으로 전환하는 것과 병행하여, TSMC는 각 장비, 특히 팹 (Fab) 전체의 성능을 향상시키기 위해 AI를 적극적으로 활용하고 있습니다. 본질적으로 TSMC는 더 많은 AI 프로세서를 만들기 위해 AI를 사용하고 있는데, 이는 역설적으로 보일 수 있으나 AI가 워크플로우 (Workflows) 내에 내장됨에 따라 대중화되고 있습니다.

현대적 팹의 사이클 타임 (Cycle times)을 크게 늦추는 요인 중 하나는 약 5,000단계의 공정 중 불가피한 부분인 다양한 챔버 (Chambers)에서의 웨이퍼 배치 처리 (Batch processing)입니다. 본질적으로, 25장의 웨이퍼가 리소그래피 (Lithography) 장비가 개별적으로 처리할 때까지 (아마도 CVD 챔버 내에서) '대기'하게 됩니다.
Rapidus의 Atsuyoshi Koike는 다르게 생각하며, 모든 단계에서 단일 웨이퍼 처리 (Single-wafer processing)를 수행하면 장비 효율성 (Tool efficiency)을 희생하는 대신 사이클 타임 (Cycle time)을 크게 단축할 수 있다고 믿습니다. TSMC는 단일 웨이퍼 처리 방식을 사용할 계획은 없어 보이지만 (그들의 구매력을 고려할 때, 팹 장비 제조사들을 설득하여 적절한 장비를 생산하게 할 가능성이 높음에도 불구하고), 기존 팹의 생산성을 높이기 위해 기존 장비를 사용하는 방식을 확실히 최적화할 수 있습니다.
TSMC는 최근 기술 서밋 (Technology Summit)에서 장비 효율성을 최적화하기 위해 '최첨단 선형 계획법 (Linear programming) 및 휴리스틱 알고리즘 (Heuristic algorithms)'을 통합한 지능형 스케줄링 시스템을 사용한다고 밝혔으나, 정확히 무엇을 수행하고 무엇을 달성했는지는 밝히지 않았습니다. TSMC는 또한 웨이퍼 품질을 유지하면서 '장비의 물리적 한계에 도전하는' 최적의 파라미터 (Parameters)를 식별하기 위해 생성형 AI (Generative AI) 알고리즘을 사용한다고 밝혔습니다. 이와 병행하여, 회사는 빅데이터 분석 (Big-data analytics) 및 텍스트 마이닝 (Text-mining) 시스템을 사용하여 장비 로그 (Tool logs)를 분석함으로써 주요 파라미터를 동적으로 조정하고, 장비 유휴 시간 (Tool idle time)을 최소화하며, 산출량 (Output)을 극대화합니다.
AI 시스템은 또한 실시간 챔버 상태 분석 (Chamber condition analysis)에 사용되어 최적의 챔버 세정 (Chamber-cleaning) 타이밍을 결정하고, 장비 가동 시간 (Uptime)과 가용 용량 (Available capacity)을 감소시킬 수 있는 불필요한 유지보수를 방지합니다. 또한, TSMC는 대량의 장비 검증 파라미터에 대한 AI 지원 비교 및 미세 조정 (Fine-tuning)을 통해 새로운 장비를 검증하고 대량 생산 (High-volume manufacturing) 단계에 도달하는 데 필요한 시간을 20% 이상 단축했으며, 이는 새로운 팹 모듈을 더 빠르게 램프업 (Ramp up)하는 데 도움이 된다고 공개했습니다.
TSMC는 또한 장비 공통성 (Equipment commonality)을 높이고 '교차 기술 계획 (Cross-technologies planning)'을 통합함으로써 타이난 (Tainan)의 Fab 18에서 더 유연한 할당과 더 높은 N3 및 N5 결합 용량을 달성했다고 밝혔습니다. 이는 본질적으로 회사가 가능한 한 많은 장비를 재사용한다는 것을 의미합니다.
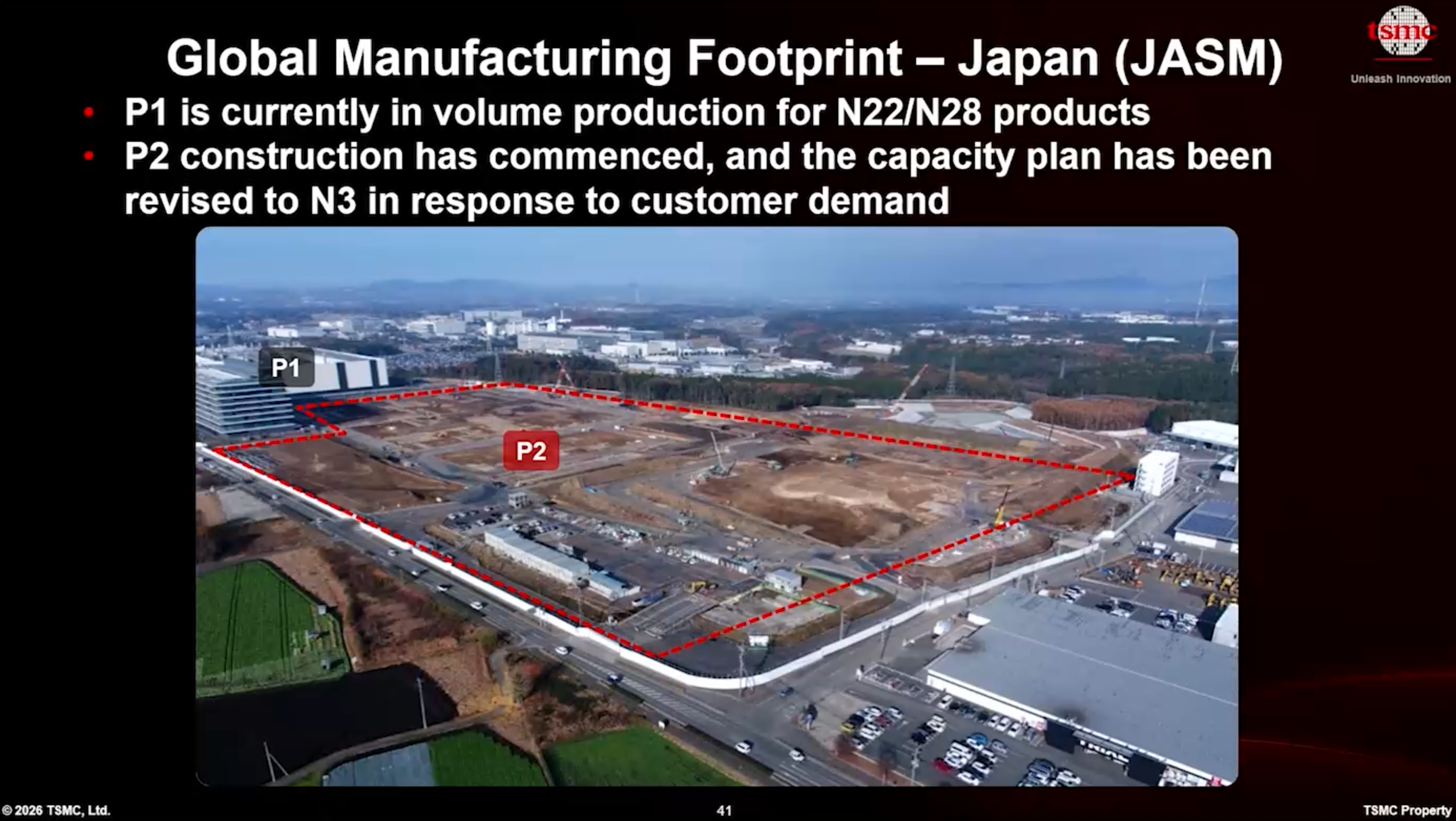
대만 이외 지역으로의 확장
대만 이외 지역으로의 확장
대만 이외 지역에서, TSMC는 지리적 거점을 지속적으로 확장하고 있습니다. 애리조나(Arizona)의 Fab 21 1단계는 이미 N4 기술을 사용하여 칩을 생산하고 있으며(올해에만 용량이 1.8배 증가), Fab 21 2단계는 2027년 3분기에 N3 생산을 시작할 예정입니다. Fab 21 3단계는 이번 십 년 내(this decade) 어느 시점에 N2를 목표로 하고 있으며, 회사는 3단계와 4단계를 위한 건물 외벽(shells) 건설을 계속 진행 중입니다. 또한 회사는 향후 확장을 지원하기 위한 첨단 패키징 시설(advanced packaging facility), R&D 센터, 그리고 추가적인 토지 매입 계획을 재확인했습니다.


AI 자동 생성 콘텐츠
본 콘텐츠는 Tom's Hardware의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기