TrOPD: LLM을 위한 안정적인 증류 (Stable distillation)
요약
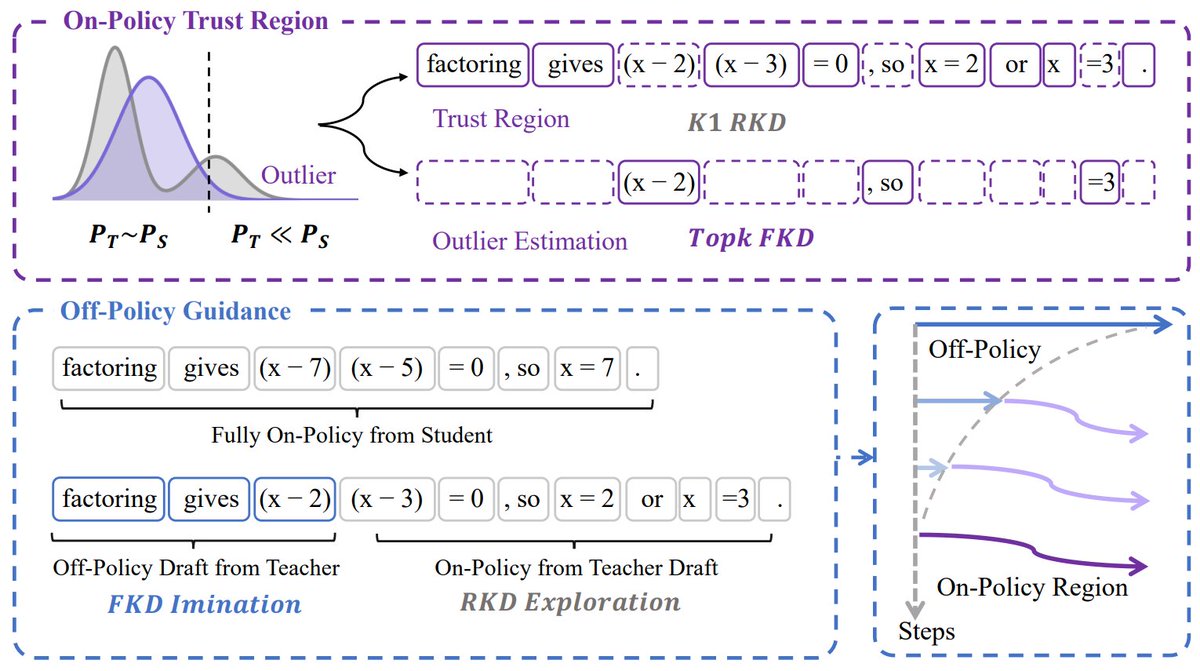
TrOPD는 온-폴리시 증류 과정의 불안정성을 해결하기 위해 신뢰 영역 내에서 교사 감독을 적용하는 새로운 방법론입니다. 이상치 추정과 오프-폴리시 가이드를 통해 탐색을 유지하며 수학적 추론 및 코드 생성 성능을 높였습니다.
핵심 포인트
- 신뢰 영역 기반의 안정적인 LLM 증류 방법론 제안
- 이상치 추정 및 오프-폴리시 가이드를 통한 불안정성 해소
- 수학적 추론 및 코드 생성 벤치마크에서 SOTA 달성
TrOPD: LLM을 위한 안정적인 증류 (Stable distillation)
신뢰 영역 (trust regions) 내에서만 교사 감독 (teacher supervision)을 적용하는 동시에, 탐색 (exploration)을 유지하기 위해 이상치 추정 (outlier estimation) 및 오프-폴리시 가이드 (off-policy guidance)를 사용하여 온-폴리시 증류 (on-policy distillation)의 불안정성을 해결하는 새로운 방법론입니다.
TrOPD는 수학적 추론 (math reasoning), 코드 생성 (code generation) 및 일반 벤치마크 (general benchmarks) 전반에서 최첨단 베이스라인 (state-of-the-art baselines)을 능가합니다.
논문 (Paper):
https://huggingface.co/papers/2606.01249
코드 (Code):
https://github.com/Xingrun-Xing2/TrOPD
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기0