Trellis에 RadixAttention 도입하기
요약
Trellis 시스템에서 LLM 추론의 prefill 단계를 최적화하기 위해 RadixAttention을 도입한 기술적 과정을 설명합니다. 라딕스 트리(Radix Tree) 구조를 활용한 접두사 캐싱(Prefix Caching)을 통해 중복되는 시스템 프롬프트와 토큰 임베딩의 저장 공간을 최소화하고 효율적인 KV 캐싱을 구현합니다.
핵심 포인트
- RadixAttention을 통한 LLM prefill 단계 최적화
- 라딕스 트리 구조를 활용한 효율적인 접두사 캐싱 구현
- 중복되는 시스템 프롬프트 및 토큰 임베딩 저장 공간 최소화
- 다양한 하드웨어 환경에서의 LLM 추론 민주화 및 성능 개선
우리는 사용자의 데이터 프라이버시를 타협하지 않으면서 LLM 추론 (LLM inference)을 민주화하기 위해 Trellis를 만들었습니다. 그 목표를 향해, 우리는 사용자가 이미 소유하고 운영 중인 하드웨어, 즉 노트북, 워크스테이션, 서버 등 어디에나 배포할 수 있는 시스템을 구축했습니다.
사용자가 처한 환경에 맞추기 위해, 우리는 성능이 다소 떨어지는 하드웨어까지 수용해야 하며, 따라서 가능한 한 최적화 기회를 포착해야 합니다.
이 포스트에서는 Trellis에서 LLM 추론의 prefill 단계를 어떻게 최적화했는지에 초점을 맞출 것입니다. 먼저 문제에 대한 간략한 배경을 설명하고, 채팅 기반 및 에이전트형 (agentic) LLM 세션에 유효한 캐싱 전략 (caching strategy) 구현에 대해 논의한 후, 벤치마크 결과(benchmark results)를 보여주며 마무리하겠습니다.
LLM prefill 및 KV 캐시 (KV cache)
Trellis 그리드의 컴퓨팅 노드들은 LLM 트랜스포머 블록 (transformer block)의 수치 연산 (attention, linear layers 등)을 수행합니다. 수치 연산이 결과를 평가하기 전(즉, 다음 토큰을 샘플링하기 전)에, 우리는 모든 피연산자(operands)를 계수(coefficients)로 채워야 합니다. 이것이 LLM 추론의 prefill phase이며, 이는 연산 제한적 (compute-bound)입니다.
구체적으로, 토큰 (t+1)을 생성하기 위해, 어텐션 (attention)은 모든 이전 토큰(토큰 (0 .. t))의 키(keys)와 값(values, 투영된 임베딩)이 필요합니다.
첫 번째 핵심 관찰 사항: 자기회귀 생성 (autoregressive generation)에서, 샘플링된 토큰은 이미 생성된 토큰 뒤에 추가되며, 결합된 시퀀스가 모델의 입력으로 다시 피드됩니다. 이 사실은 인과적 어텐션 마스크 (causal attention mask)와 결합되어, 위치 (i < j)에서의 임베딩(따라서 K 및 V 행렬)이 이후 위치 (k \geq j)의 임베딩에 의존하지 않음을 의미하며, 따라서 이후의 모든 토큰을 생성하는 동안 추가 전용(append-only) 방식으로 캐싱 (cached) 될 수 있습니다.
RadixAttention을 이용한 접두사 캐싱 (Prefix caching)
두 번째 핵심 관찰 사항은 LLM의 실제 사용 방식, 즉 시스템 프롬프트(system prompt)가 사용자 요청보다 앞서는 채팅 세션에서 비롯됩니다. 동일한 템플릿을 기반으로 반복되는 LLM 요청은 공통된 접두사 문자열(prefix string)로 모델을 프리필(prefill)해야 하며, 이는 시스템 프롬프트의 모든 토큰 임베딩(token embeddings)을 미리 계산하고 캐싱(cached)할 수 있음을 의미합니다. 그뿐만 아니라, 원칙적으로 요청들 사이에서 재사용될 것임을 알고 있다면 프롬프트의 모든 *접두사(prefixes)*를 캐싱할 수 있습니다. RadixAttention의 핵심 통찰은 문자열 접두사들이 전체 서브스트링(substrings)을 공유하는 일반적인 경우에 저장 공간을 최소화하는 특화된 데이터 구조(라딕스 트리 (radix tree))를 사용하는 것이었습니다 (예를 들어, "hello my name is Alice"와 "hello my name is Bob"이라는 문자열이 주어지면, 라딕스 트리는 "hello my name is ", "Alice", "Bob"이라는 3개의 항목만 저장합니다).
Trellis에서의 RadixAttention
Trellis 그리드 내에서는 여러 노드가 동시에 추론(inference) 요청을 보낼 수 있으며, 이는 다시 하나 이상의 트랜스포머 블록(transformer blocks)을 보유한 여러 노드에 의해 서비스됩니다. 따라서 KV 캐싱(KV caching) 메커니즘은 동시성 메커니즘(concurrency mechanism)의 역할도 수행합니다. 서로 관련 없는 요청이라도 접두사를 공유할 수 있기 때문입니다 (예: 팀이 동일한 시스템 프롬프트를 재사용하는 경우).
우리의 RadixAttention KV 캐시 구현은 블록 페이징 (block-paged) 방식입니다. K/V 활성화 값(activations)은 공유 *풀 (pool)*에서 가져온 고정된 크기의 토큰 임베딩 *블록 (blocks)*에 저장되며, 각 세션은 연속된 배열 대신 블록 ID의 정렬된 리스트를 보유합니다. 두 세션이 접두사를 공유할 때, 두 번째 세션은 새로운 블록을 **할당 (allocating)**하고 다시 계산하는 대신 기존의 접두사 블록을 **획득 (acquires)**합니다 (참조 횟수(refcount) 증가).
벤치마크 (Benchmarks)
설정 및 정의
아래의 모든 벤치마크는 단일 Mac M1에서 합성 프롬프트(synthetic prompts)를 사용하여 TinyLlama 1.1B Q4_0를 인프로세스(in-process) 방식으로 실행합니다. 반복되는 파라미터는 다음과 같습니다:
L— 토큰 단위의 프롬프트 길이 (prompt length).
D— 디코딩 예산 (decode budget): 세션당 생성되는 토큰 수.
N— 동시 디코딩 세션 수. 한 번 워밍업(warmed)된 하나의 공유 "시스템 프롬프트 (system prompt)"와, 세션당 하나씩 총 N개의 서로 다른 사용자 접미사(user suffixes)를 사용합니다.
φ (phi)— 공유 접두사 비율 (shared-prefix fraction): 각 프롬프트에서 공통 접두사가 차지하는 비율입니다. φ=0.5는 모든 호출에서 각 프롬프트의 앞부분 절반이 동일함을 의미합니다. φ는 블록 양자화 (block-quantized) 된다는 점에 유의하세요. 내부적으로 공유 영역은 32-토큰 블록 단위의 정수로 반올림됩니다 (prefixBlocks = round(φ·L/32)), 따라서 실제 구현된 φ는 32/L의 배수로 고정됩니다.
op— 하나의 전체 벤치마크 반복 (iteration): 새로운 추론 파이프라인(inference pipeline)을 구축하고, 공유 접두사를 워밍업하며, N개의 모든 세션을 완료할 때까지 실행하는 과정입니다. 따라서 "allocations/op"는 단일 토큰이 아니라 전체 반복 과정의 힙 트래픽 (heap traffic)을 의미합니다.
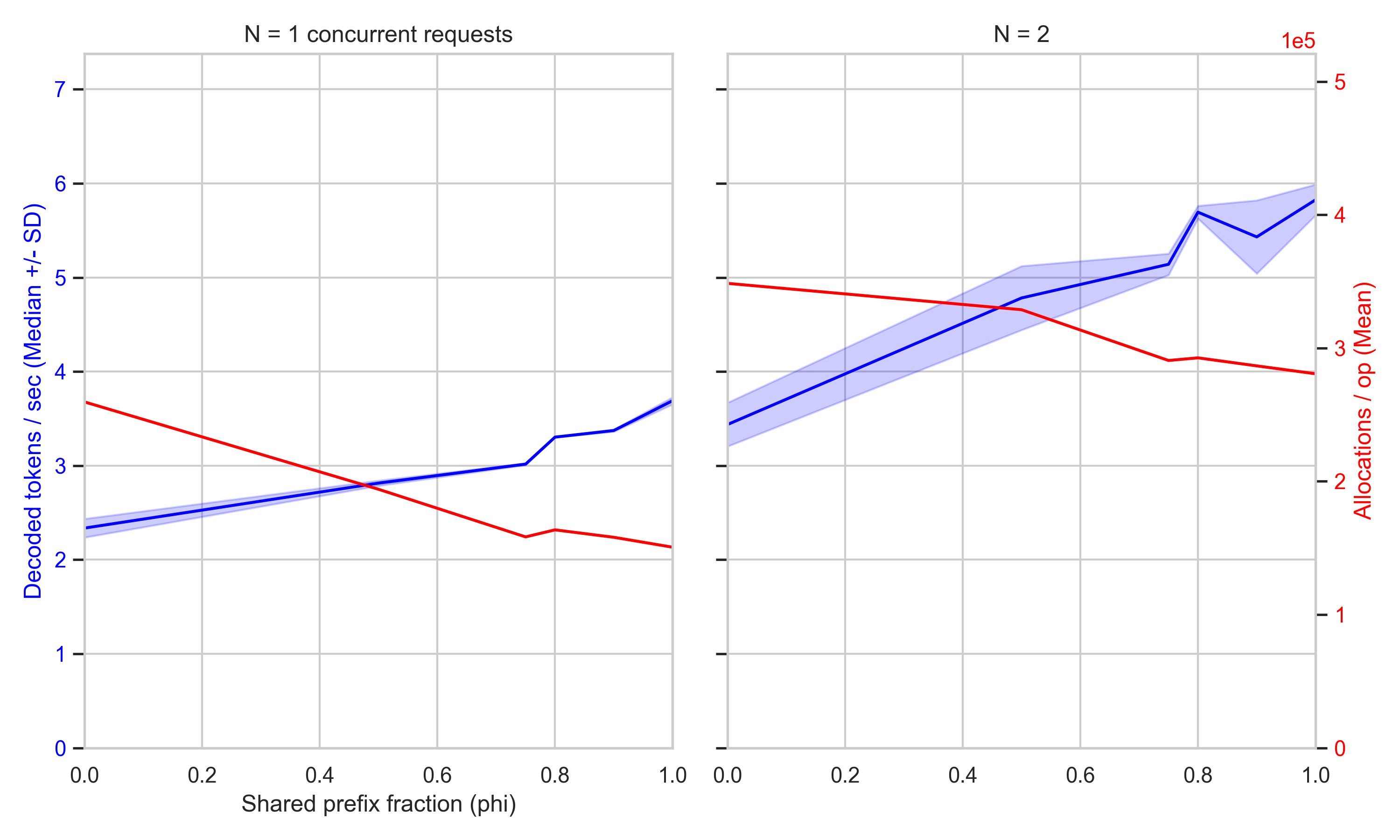
처리량 (Throughput) vs 공유 접두사 비율

프롬프트 길이 L : 512 토큰, 디코딩 예산 D : 세션당 64 토큰
공통 접두사를 공유하는 프롬프트에 RadixAttention을 사용함으로써 생성 처리량 (generation throughput)과 메모리 할당 (memory allocation) 측면에서 얼마나 이득을 얻을 수 있을까요? 결과는 상당히 큽니다.
할당 (allocations) 곡선(빨간색 선)을 보면 캐싱이 설계된 대로 작동함을 알 수 있습니다. φ가 증가함에 따라 반복당 힙 할당(heap allocations) 횟수는 단조 감소합니다. 이는 접두사 블록의 더 큰 비중이 새로 *할당 (allocated)*되는 대신 풀(pool)에서 *획득 (acquired)*되기 때문이며 (참조 횟수(refcount) 증가), 해당 블록들이 커버하는 프리필(prefill) 위치를 더 이상 다시 계산할 필요가 없기 때문입니다.
안심할 수 있는 점은, 처리량 (throughput) 곡선(파란색 선) 또한 φ가 증가함에 따라 선형적으로 개선된다는 것입니다. 캐싱된 KV 위치는 프리필(prefill)을 수행할 필요가 없기 때문입니다 (φ가 0.75와 0.9일 때의 변동은 벤치마킹 환경의 노이즈 때문일 가능성이 높습니다).
첫 번째 토큰 생성 시간 (Time-to-first-token)

여기서는 LLM 호출 간에 프롬프트 접두사가 공유될 때, RadixAttention이 중복 계산을 제거하는 데 얼마나 효과적인지 확인하고자 합니다.
TTFT (Time To First Token)는 하나의 프롬프트로 캐시를 예열(prewarming)한 다음, 단일 요청에 대해 하나의 토큰을 디코딩(decoding)함으로써 측정됩니다 (concurrency = 1). φ가 상승함에 따라 TTFT는 꾸준히 감소하는데, 이는 공유되는 접두사(shared prefix)가 커질수록 더 많은 위치가 캐시된 블록(cached blocks)에서 제공되고, 처음부터 채워넣어야 하는(prefilled) 위치가 줄어들기 때문입니다.
이 수치를 읽을 때 주의할 점 두 가지가 있습니다. 첫째, φ 값이 낮을 때 나타나는 큰 분산(variance)은 첫 번째 반복(first-iteration)에서 발생하는 현상입니다. 즉, 아주 첫 번째 반복에서는 일회성 콜드 스타트(cold-start) 비용이 발생합니다. 격자(grid)의 오른쪽 끝에서도 달성 가능한 최대 히트율(hit rate)은 1.0이 아니라 (L/32 − 1)/(L/32)라는 점에 유의하십시오. 조사용 프롬프트(probe prompt)는 항상 워밍 프롬프트(warm prompt)의 마지막 블록에서 달라지므로, 하나의 블록은 결코 공유되지 않습니다.
결론
이 포스트에서 우리는 RadixAttention이 어떻게 Trellis 노드를 30-40% 더 빠르게 실행하고 그만큼 메모리를 적게 사용하게 만드는지 보여주었습니다. 이러한 발전은 더 긴 LLM 세션이 지속되는 추세에 따라 복합적으로 작용할 가능성이 높습니다.
Trellis는 아직 초기 단계에 있으며, 분산형 동시 실행 LLM 런타임(distributed, concurrent LLM runtime)의 설계 공간은 매우 방대합니다. 만약 이와 같은 문제에 대해 이전에 생각해 본 적이 있고 피드백을 공유하고 싶으시다면, 여러분의 의견을 듣고 싶습니다!
부록: 캐시 블록 크기 선택하기
우리는 관리 비용(bookkeeping)과 지연 시간(latency) 사이의 균형을 맞추기 위해 휴리스틱(heuristically)하게 블록 크기를 선택합니다. 다음 그림은 우리가 기본 블록 크기 B = 32를 선택하는 데 도움이 되었습니다.

AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기