
Software 3.0 시대로의 진입
요약
Andrej Karpathy가 정의한 Software 1.0, 2.0, 3.0의 진화 과정을 통해 자연어 기반 프로그래밍 패러다임을 설명합니다. LLM의 한계를 극복하고 실제 작업에 활용하기 위한 'harness(도구 및 인프라)'의 중요성을 강조합니다.
핵심 포인트
- Software 3.0: 자연어로 '무엇'을 요구하는 프롬프트 기반 프로그래밍 시대
- LLM의 한계: 컨텍스트 제한, 환각, 외부 시스템 접근 불가 문제
- Harness의 역할: RAG, 메모리 관리, 도구(Tool)를 통한 LLM 활용 극대화
이 글은 이전에 게시된 기사의 영어 버전입니다.
Software 3.0이란 무엇인가?
2025년 6월, Andrej Karpathy는 Y Combinator AI Startup School에서 소프트웨어 진화의 세 단계를 설명하는 설득력 있는 강연을 진행했습니다.
Software 1.0은 우리가 수십 년 동안 의존해 온 방식입니다. Python, Java 또는 C++와 같은 언어로 명시적인 로직 (logic)을 코딩하고, if-else로 분기하며, for 루프로 반복하고, 함수를 통해 추상화합니다. 이는 코드에 "어떻게 (how)"에 대한 모든 세부 사항을 명시하는 것이었습니다.
Software 2.0은 2010년대 딥러닝 (deep learning)의 부상과 함께 등장했습니다. 더 이상 규칙을 수동으로 작성하지 않습니다. 대신 데이터를 수집하고 모델을 학습시키면, 신경망 가중치 (neural network weights)가 프로그램이 됩니다. 신경망이 방대한 양의 C++ 코드를 대체한 Tesla Autopilot을 생각해보세요.
Software 3.0은 우리가 현재 처한 단계입니다. 코드를 작성하는 대신, 자연어 (natural language)로 LLM에게 원하는 "무엇 (what)"을 말하면 프롬프트 (prompt)가 프로그램이 됩니다.
Karpathy가 말했듯, "Software 3.0이 1.0/2.0을 집어삼키고 있습니다." 새로운 패러다임이 장악하고 있습니다.
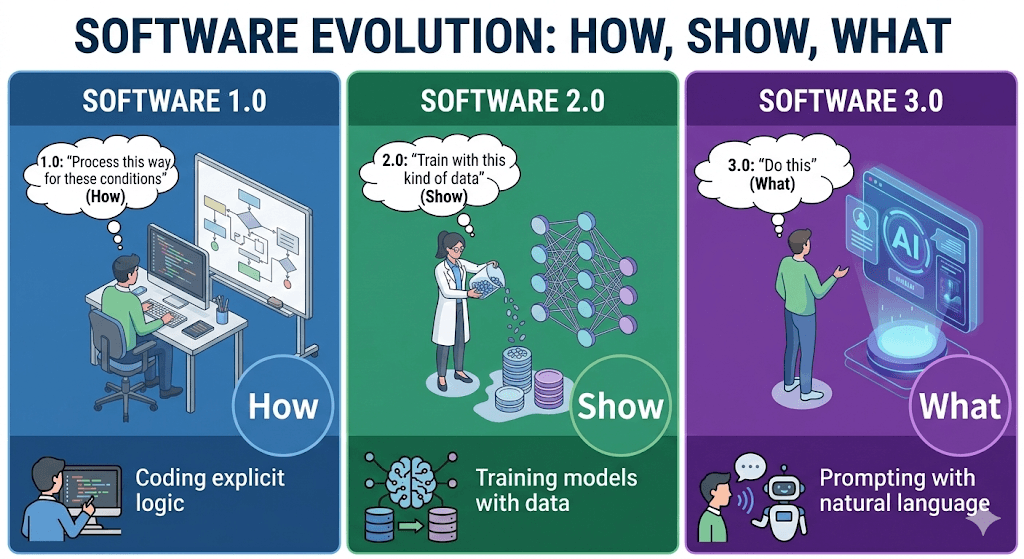
Karpathy의 표현을 빌리자면: "Software 3.0이 1.0/2.0을 집어삼키고 있습니다." 새로운 패러다임이 기존의 것들을 삼키고 있습니다.
📺
Harness: LLM을 유용하게 만드는 것
하지만 현실은 다른 이야기를 합니다.
단순히 ChatGPT에게 "우리 서비스의 버그를 수정해줘"라고 말한다고 해서 마법처럼 문제가 해결되지는 않습니다. LLM은 강력하지만, 스스로 파일을 읽거나, API를 호출하거나, 데이터베이스 (database)에 접근할 수는 없습니다.
여기에서 harness라는 개념이 등장합니다.
본래 harness는 인간이 말의 힘과 속도를 이용할 수 있도록 말에게 채우는 장구를 의미합니다. harness가 없는 말은 그저 말일 뿐입니다.
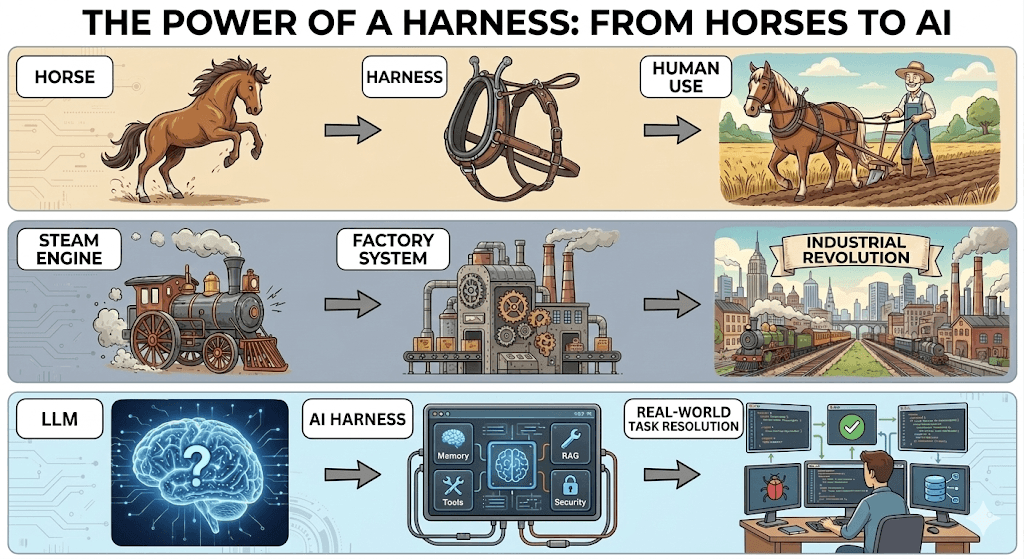
LLM도 마찬가지입니다. 그 자체만으로는 제어하거나 활용하기 어렵습니다. LLM의 한계를 극복하고 이를 실제 작업에 연결하기 위해서는 적절한 도구와 인프라 (infrastructure)가 필요합니다.
LLM Limitation
Harness의 역할
컨텍스트 윈도우 제한 (Context window limit)
메모리 관리 (Memory management)
환각 (Hallucination)
사실 근거 제시 (Fact grounding), RAG
도메인 지식 부족 (Lack of domain knowledge)
지식 베이스 (Knowledge base)
상태 관리 불가 (Unable to manage status)
세션 (Session), 오케스트레이션 (Orchestration)
외부 시스템 접근 불가 (Unable to access external system)
도구 (Tool), MCP
Claude Code: Claude를 위한 Harness
Claude Code는 Anthropic의 CLI 기반 코딩 에이전트 (coding agent)입니다. 본질적으로, 이는 Claude를 위한 harness (하네스)입니다.
Claude Code가 제공하는 기능은 다음과 같습니다:
| 기능 | 역할 |
|---|---|
| 파일 시스템 접근 (File system access) | LLM이 코드를 읽고 쓸 수 있게 함 |
| 터미널 실행 (Terminal execution) | LLM이 명령어를 실행할 수 있게 함 |
| MCP (Model Context Protocol) | 외부 시스템과 연결 |
| 서브 에이전트 (Sub-agent) | 복잡한 작업을 세분화 |
| 슬래시 명령어 (Slash command) | 사용자의 의도를 라우팅 |
| 스킬 (Skills) | 재사용 가능한 기능 단위 |
| 훅 (Hooks) | 이벤트 기반 자동화 |
이 기능들이 결합되어 Claude를 단순한 LLM 엔진에서 실제로 실무를 수행할 수 있는 에이전트로 변모시키는 harness 역할을 합니다. 익숙한 구조인가요?
Software 1.0을 통해 Claude Code 이해하기
MCP, Skills, Sub-agents, Slash command...
새로운 용어들이 빠르게 쌓이면서 인지 과부하 (cognitive overload)를 일으킵니다. 하지만 이러한 라벨 너머를 살펴보면, 그 구조는 우리가 수년 동안 사용해 온 계층형 아키텍처 (layered architecture)와 놀라울 정도로 유사합니다.
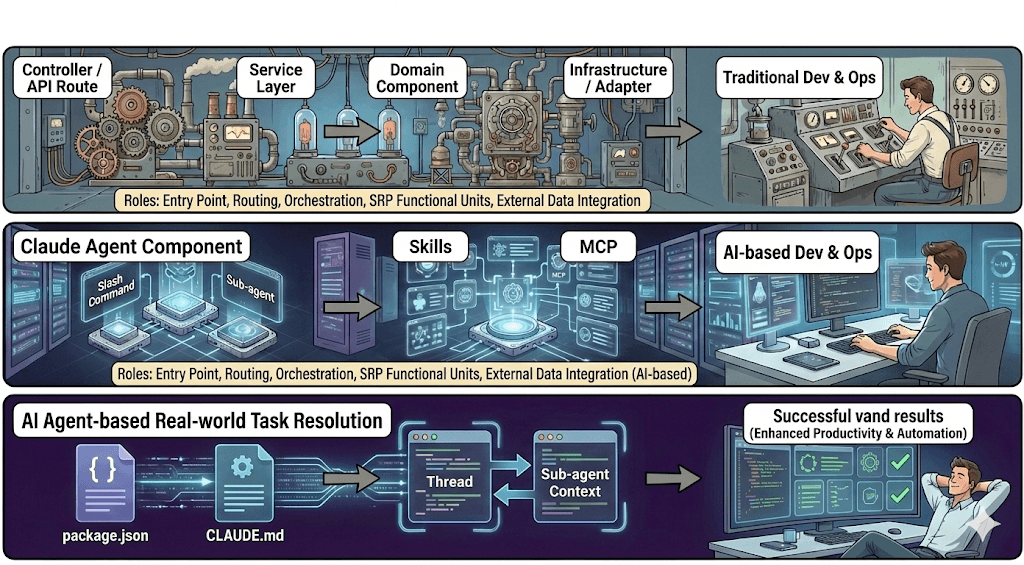
각 계층 상세 분석
슬래시 명령어 (Slash command) = 컨트롤러 (Controller)
슬래시 명령어는 Spring의 @RestController나 Express의 router.get()과 마찬가지로 사용자 요청의 진입점 (entry point)입니다. /review는 리뷰 워크플로를 트리거하고, /refactor는 리팩토링 워크플로를 트리거합니다.
서브 에이전트 (Sub-agent) = 서비스 계층 (Service Layer)
서브 에이전트를 서비스 계층처럼 생각하십시오. 이들은 리포지토리 (repository)와 도메인 객체 (domain object)를 조정하는 대신, 스킬 (skills)을 조정하고 이를 결합하여 워크플로를 완성합니다. 각 서브 에이전트는 자체적인 컨텍스트 (context)를 유지하므로, 별도의 스레드 (thread)처럼 독립적으로 작동할 수 있습니다.
스킬 (Skills) = 도메인 수준 컴포넌트 (Domain-level Component, SRP)
스킬은 단일 책임 원칙 (Single Responsibility Principle, SRP)을 따르며, 각 스킬은 정확히 한 가지 일만 수행합니다. "코드 리뷰", "테스트 생성", "문서 작성"과 같은 식입니다. 비대해진 클래스 (bloated classes)가 위험 신호인 것처럼, 너무 많은 일을 하려고 하는 스킬 또한 문제입니다.
MCP = 인프라스트럭처 (Infrastructure) / 어댑터 (Adapter)
MCP(Model Context Protocol)는 데이터베이스, API, 파일 시스템과 같은 외부 세계로 연결되는 가교 역할을 합니다. 저장소 (Repository) 패턴이나 어댑터 (Adapter) 패턴과 마찬가지로, 내부 로직이 외부 구현에 종속되지 않도록 추상화 계층 (Layer of abstraction)을 제공합니다.
CLAUDE.md = package.json
CLAUDE.md는 package.json 또는 pom.xml과 동일한 역할을 수행합니다. 이는 기술 스택 (Tech stack), 코딩 컨벤션 (Coding conventions), 빌드 명령 (Build commands)과 같이 거의 변하지 않는 요소들을 정의하는 데 사용됩니다.
참고: 만약
CLAUDE.md를 계속해서 수정하고 있다면, 해당 내용은 아마 그곳에 포함되어서는 안 되는 내용일 것입니다. 대신 대화나 서브 에이전트 컨텍스트 (Sub-agent context)를 통해 동적인 정보(현재 이슈, 오늘의 우선순위 등)를 전달하도록 시도해 보세요.
동일한 안티 패턴 (Anti-patterns)의 적용
계층형 아키텍처 (Layered architecture)에서 나타나는 것과 동일한 안티 패턴이 에이전트 설계에서도 나타납니다. 다음 이름들은 익숙하게 느껴질 것입니다.
| 전통적 개념 | 에이전트 개념 | 증상 |
|---|---|---|
| God Class (갓 클래스) | God skill (갓 스킬) | 하나의 스킬이 300줄에 달하는 모든 일을 처리함 |
| Spaghetti Code (스파게티 코드) | Spaghetti CLAUDE.md | 구조 없이 모든 지침이 뒤섞여 있음 |
| Tight Coupling (강한 결합) | MCP 없는 하드코딩 | 직접적인 curl 호출 사용, API 변경 시 모든 것이 깨짐 |
| Leaky Abstraction (누수된 추상화) | MCP 내부 구조를 아는 서브 에이전트 | 추상화 경계가 무너져 재사용이 불가능함 |
| Circular Dependency (순환 의존성) | 순환 스킬 호출 | A→B→C→A, 무한 루프의 위험이 있음 |
코드 스멜 (Code smells) 또한 마찬가지입니다.
- Feature Envy (기능 탐닉): 하나의 스킬이 다른 스킬의 데이터를 과도하게 참조함
- Duplication (중복): 유사한 프롬프트 (Prompts)가 여러 스킬에 흩어져 있음
- Long Method (긴 메서드): 하나의 서브 에이전트가 10개의 스킬 호출을 연속으로 체이닝 (Chaining) 함
핵심적인 차이점: 계층형 아키텍처가 설명하지 못하는 것
계층형 아키텍처를 사용하여 에이전트 설계를 대부분 이해할 수 있지만, 여전히 설명되지 않는 한 가지가 있습니다. 전통적인 서비스 계층 (Service layer)을 상상해 보세요. 주문 도중 재고가 소진되면 OutOfStockException을 던지거나 백오더 (Backorder) 정책을 적용합니다. 결제가 실패하면 재시도하거나 에러를 반환합니다.
모든 상황은 사전에 예측되어야만 합니다.
하지만 현실 세계의 개발은 다릅니다. 우리는 결국 다음과 같은 질문을 던지게 됩니다.
"잠시만요, 이 건에 대해서는 PM (Product Manager)을 참여시켜야겠어요." "이건 명세서(Spec)에 없던 내용인데, 이제 어떻게 하죠?"
전통적인 아키텍처 (Architecture)에서는 코드를 멈출 방법이 없습니다. 예외 (Exception)를 던지거나, 임의의 호출을 수행하거나, 로그를 남기고 다음 단계로 넘어가야만 합니다.
질문하는 에이전트 (Agents)
하지만 에이전트 (Agents)는 다릅니다. 이들은 Human-in-the-Loop (HITL)를 지원합니다.
UserAskQuestion과 같은 도구를 사용하여, 에이전트는 작업 중간에 단순히 멈춰서 질문을 던질 수 있습니다.
그렇게 예외 (Exceptions)는 질문이 됩니다.
| 구분 | 전통적 방식 (Traditional) | HITL 방식 |
| :--- | :--- | :|
| | 모든 케이스가 사전에 정의되어야 함 | 불확실할 때 질문함 |
| | 예외 → 에러 또는 기본값 반환 | 예외 → 사용자 입력 요청 |
| | 100% 또는 0% 자동화 | 부분적 자동화 |
| | 실수는 롤백 (Rollback)이 필요함 | 실수하기 전에 확인 |
언제 질문하고, 언제 실행할 것인가
HITL을 사용할 수 있다고 해서 에이전트가 매번 질문해야 한다는 뜻은 아닙니다. 그렇게 되면 짜증을 유발하는 도구가 될 것입니다.
질문해야 할 때:
- 실행 취소가 어려운 작업 (삭제, 배포, 외부 API 호출)
- 선택지는 여러 개지만 명확한 정답이 없는 경우
- 결정에 상당한 비용이나 리스크가 따르는 경우
실행해야 할 때:
- 작업이 안전하고 반복 가능한 경우
- 이미 확립된 컨벤션 (Convention)이 있는 경우
- 실행 취소가 쉬운 작업인 경우
좋은 에이전트는 언제 질문해야 할지를 압니다. 위대한 에이전트는 "언제 질문하지 말아야 할지"를 압니다.
1.0에서 3.0으로의 개발
태동하는 Software 3.0의 시대가 왔다고 해서 우리가 이전에 배운 모든 것이 쓸모없어지는 것은 아닙니다.
버려야 할 것
- "모든 로직을 명시적으로 설명해야 한다"는 강박
- 모든 엣지 케이스 (Edge Cases)를 사전에 정의하려는 시도
- LLM을 단지 "똑똑한 자동 완성" 도구로만 사용하는 것
가져가야 할 것
- 계층 분리 (Layer separation), 단일 책임 원칙 (Single responsibility principle), 추상화 (Abstraction)
- 의존성 관리 (Dependency management), 인터페이스 설계 (Interface design)
- 테스트 가능성 (Testability), 디버깅 전략 (Debugging strategy)
- 코드 리뷰 (Code review), 점진적 개선 (Incremental improvements)
도구는 변했지만, 좋은 설계를 위한 근본적인 원칙 (응집도, 결합도, 추상화)은 변하지 않았습니다.
MCP를 설계할 때 어댑터 패턴 (Adapter Patterns)을 떠올려 보세요. 스킬 (Skill)을 생성할 때 단일 책임 원칙 (SRP)을 떠올려 보세요. 서브 에이전트 (Sub-agent)를 설계할 때 서버 레이어 (Server Layers)를 떠올려 보세요.
여러분의 아키텍처 지식은 훌륭한 에이전트를 구축하기 위한 토대입니다.
하지만 모든 것이 그대로 전이되지는 않습니다
그렇긴 하지만, 계층형 아키텍처 (Layered Architecture)만으로는 완전히 설명할 수 없는 부분들이 있습니다. 다음은 유의해야 할 몇 가지 사항입니다.
토큰은 새로운 메모리입니다
전통적인 서버 개발에서는 RAM이 제약 사항이었습니다. 에이전트의 경우에는 토큰 (Tokens)이 제약 사항입니다.
컨텍스트 윈도우 (Context Window) = 작업 메모리 (Working Memory)
토큰 사용량 = 메모리 사용량
CLAUDE.md, 스킬 (Skills), 대화 기록 (Conversation History), 그리고 MCP 응답은 모두 컨텍스트 윈도우에 쌓입니다. 200K 토큰은 넉넉해 보일 수 있지만, 대규모 코드베이스에서 작업하다 보면 순식간에 사라집니다.
| 요소 | 토큰 비용 | 비고 |
|---|---|---|
| CLAUDE.md (잘 구조화된 경우) | 500–2,000 | 프로젝트당 |
| 스킬 하나 | 300–1,500 | 로드될 때마다 |
| 대화 기록 | 누적됨 | 세션을 통해 |
| MCP 응답 (DB 쿼리 등) | 가변적 | 대규모 응답 시 주의 |
OOM (Out of Memory)을 방지하려고 노력하는 것처럼, 토큰 팽창 (Token Bloat) 또한 예측 가능한 요소입니다. CLAUDE.md에 "모든 테스트 파일을 분석하라"라고 쓰기 전에, 그 명령이 50개의 테스트 파일에 걸쳐 어떻게 나타날지 그려보세요. 정확한 토큰 수를 계산할 필요는 없으며, 파일 수와 라인 양에 대한 대략적인 감각만 있으면 충분합니다.
지침을 작성한 후, Claude에게 직접 물어보세요: "내가 이 워크플로우를 실행하면 결국 어떤 파일들을 읽게 될까?" 만약 범위가 예상보다 크다면, 이는 지침을 더 엄격하게 제한하거나 작업을 단계별로 나누어야 한다는 신호입니다.
토큰을 절약하는 또 다른 방법은 결정론적 로직 (Deterministic Logic)을 스크립트로 오프로드 (Offload)하는 것입니다.
LLM은 단순히 스크립트를 실행하고 그 출력값과 함께 작업할 뿐입니다. 컨벤션을 파싱하거나, 스크립트가 밀리초 단위로 계산할 수 있는 내용을 토큰을 써가며 다시 유도할 필요가 없습니다. 만약 어떤 작업에 판단 (Judgment)이 필요하지 않다면, 이를 처리할 도구 (Tool)를 만드세요.
스킬 분리의 딜레마: 클래스 폭발과 데메테르의 법칙 (Law of Demeter)
전통적인 아키텍처에서 단일 책임 원칙 (SRP)을 맹목적으로 따르는 것은 클래스 폭발 (class explosion)로 이어집니다. 수백 개의 아주 작은 클래스들이 코드베이스 전반에 흩어져 있게 되며, 이들 사이의 관계를 매핑하는 것 자체가 인지적 부담 (cognitive burden)이 됩니다.
이는 스킬 (Skills)에도 동일하게 적용됩니다. 시작 시점에 Claude는 모든 스킬의 메타데이터 (이름 및 설명)를 시스템 프롬프트 (system prompt)에 로드합니다. 스킬이 20개라면, 20개의 설명이 컨텍스트 (context)를 영구적으로 점유하게 됩니다.
위의 상황은 다음과 같은 코드를 작성하는 것과 같습니다:
데메테르의 법칙 (Law of Demeter)을 생각해 보세요: "낯선 사람에게 말을 걸지 마세요." 객체는 오직 자신의 직계 이웃만을 알아야 합니다. 이를 스킬 설계에 적용하면, SKILL.md가 진입점 (entry point)을 제공하고, 상세한 지식은 references/로 위임되어야 함을 의미합니다.
이는 퍼사드 패턴 (facade pattern)과 유사합니다:
Claude도 이와 매우 유사한 방식으로 작동합니다. SKILL.md가 퍼사드 (facade) 역할을 수행하며, references/ 내부의 파일들은 Claude가 필요하다고 판단할 때만 컨텍스트에 로드됩니다.
균형 찾기:
| 상황 | 전통적인 아키텍처 | 스킬 설계 |
|---|---|---|
| 독립적인 워크플로우 (Independent workflow) | 별도의 서비스 클래스 (Separate service class) | 별도의 스킬 (Separate skill) |
| 도메인 특화 규칙 (Domain-specific rules) | 프라이빗 메서드 / 내부 클래스 (Private method / inner class) | references/ 파일 |
| 재사용 가능한 유틸리티 (Reusable utility) | 공통 모듈 (Common module) | scripts/ 또는 MCP |
실전 팁: 설정 및 구성 패턴 (Setup & Config Patterns)
하지만 이것이 실제로 어떻게 작동할까요?
슬래시 명령어 (Slash commands)를 사용하면 인간 참여형 (HITL, Human-In-The-Loop) 방식과 자동화를 쉽게 결합할 수 있습니다. 이미 알고 있는 CLI 패턴과 비교해 보세요:
HITL이 진정한 가치를 발휘하는 지점은 바로 설정 프로세스입니다:
에이전트 (agent)가 환경을 자동으로 감지하지만, 모호한 부분은 질문을 통해 표시합니다. 모든 것을 미리 정의할 필요는 없습니다. 명확한 케이스는 에이전트가 처리하게 두고, 불확실한 상황에서만 개입하세요.
오픈 소스 프로젝트인 claude-hud 플러그인은 이 패턴을 잘 보여줍니다:
/claude-hud:setup이 수행하는 작업:
- 현재 환경 감지 (터미널 유형, Claude Code 버전 등)
- 상태 표시줄 (statusline) 설정 자동 구성
- 필요한 훅 (hooks) 등록
에이전트는 수동 입력 (manual input)을 최소화하기 위해 꼭 필요한 경우에만 질문을 던져야 합니다.
맺음말
Software 3.0 시대의 개발은 코드를 직접 작성하는 것에서 코드를 조립하고 지시하는 것으로 변화하고 있습니다.
하지만 그 핵심에 있어, 코드 조립 (code assembly)의 원칙은 여전히 크게 변함이 없습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 RSS: Toss Tech Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기