
SmithDB의 전문 검색(Full-text search)을 위한 역색인(Inverted index) 구축 방법
요약
SmithDB에서 전문 검색을 지원하기 위한 역색인(Inverted index)의 구축, 압축, 쿼리 과정을 설명합니다. 특히 대규모 JSON 페이로드를 효율적으로 처리하기 위해 JSON 테이프 방식을 활용한 평탄화 기법과 토큰화 과정을 다룹니다.
핵심 포인트
- 데이터 수집 중 인라인으로 역색인을 구축하여 실시간 검색 지원
- JSON 파싱 성능 최적화를 위해 Apache Arrow 스타일의 JSON 테이프 구조 활용
- 중첩된 JSON을 (path, leaf_value) 쌍으로 평탄화하여 인덱싱
- FST(Finite State Transducers)를 활용한 효율적인 용어 레이아웃 구현
개요 (Overview)
SmithDB에서 전문 검색(Full-text search)을 지원하는 방법에 관한 이전 블로그 포스트에서는 객체 스토리지(Object-storage) 기반의 역색인(Inverted index) 구현을 어떻게 설계했는지 살펴보았습니다. 이번 블로그 포스트에서는 SmithDB에서 이 인덱스를 어떻게 구축(Construct), 압축(Compact), 그리고 쿼리(Query)하는지 다루겠습니다.
역색인 구축 및 병합 (Inverted index construction and merging)
인덱스 구축은 데이터 수집(Ingestion) 과정 중에 인라인(Inline)으로 발생합니다. 새로운 실행(Run) 데이터는 몇 초 이내에 검색 가능한 상태가 되며, 가장 최신 데이터는 이를 기록한 노드에 그대로 남아 있기 때문에, 최신 쿼리(Leading-edge queries)는 객체 스토리지를 거치는 왕복 시간(Round trip)을 들이는 대신 로컬 스토리지에서 인덱스와 핵심 데이터 파일(Core data files)을 직접 읽습니다. 압축(Compaction) 시에는 서로 다른 데이터 파일과 연결된 인덱스들을 병합합니다.
페이로드 파싱 (Payload parsing)
SmithDB가 실행 페이로드(Run payloads)에 포함된 대규모 inputs 및 outputs 필드(그 외 몇 가지 포함)를 인덱싱한다는 점을 기억하십시오. 깊게 중첩되고(Deeply nested) 거대한 페이로드의 경우, JSON 파싱(Parsing)이 구축 시간의 대부분을 차지합니다. 저희는 평탄화된 키 경로(Flattened key paths)와 리프 값(Leaf values)만 필요하기 때문에, simdjson의 테이프 형식(Tape format)에서 영감을 받은 Apache Arrow의 arrow-json 크레이트(Crate)를 변형하여 JSON 테이프(JSON tape)를 구축했습니다.
저희의 구현은 모든 문자열 바이트가 하나의 연속된 버퍼(Contiguous buffer)에 담긴 토큰들의 평탄한 순차 배열(Flat sequential array)로 구성됩니다. 즉, 필드별 할당(Per-field allocation)이나 숫자 변환(Numeric conversion)이 없습니다. 단일 패스 반복자(Single-pass iterator)는 각 문서를 (path, leaf_value) 쌍으로 평탄화합니다. 중첩된 객체는 점 표기법 경로(Dotted paths)가 되고, 배열 요소는 부모 키로 축약됩니다. 예를 들어 {"agent": "deep agents", "tags": ["langchain", "engine"]}는 (agent, "deep agents"), (tags, "langchain"), (tags, "engine")를 생성합니다.
아래에서 또 다른 예시를 확인하십시오.
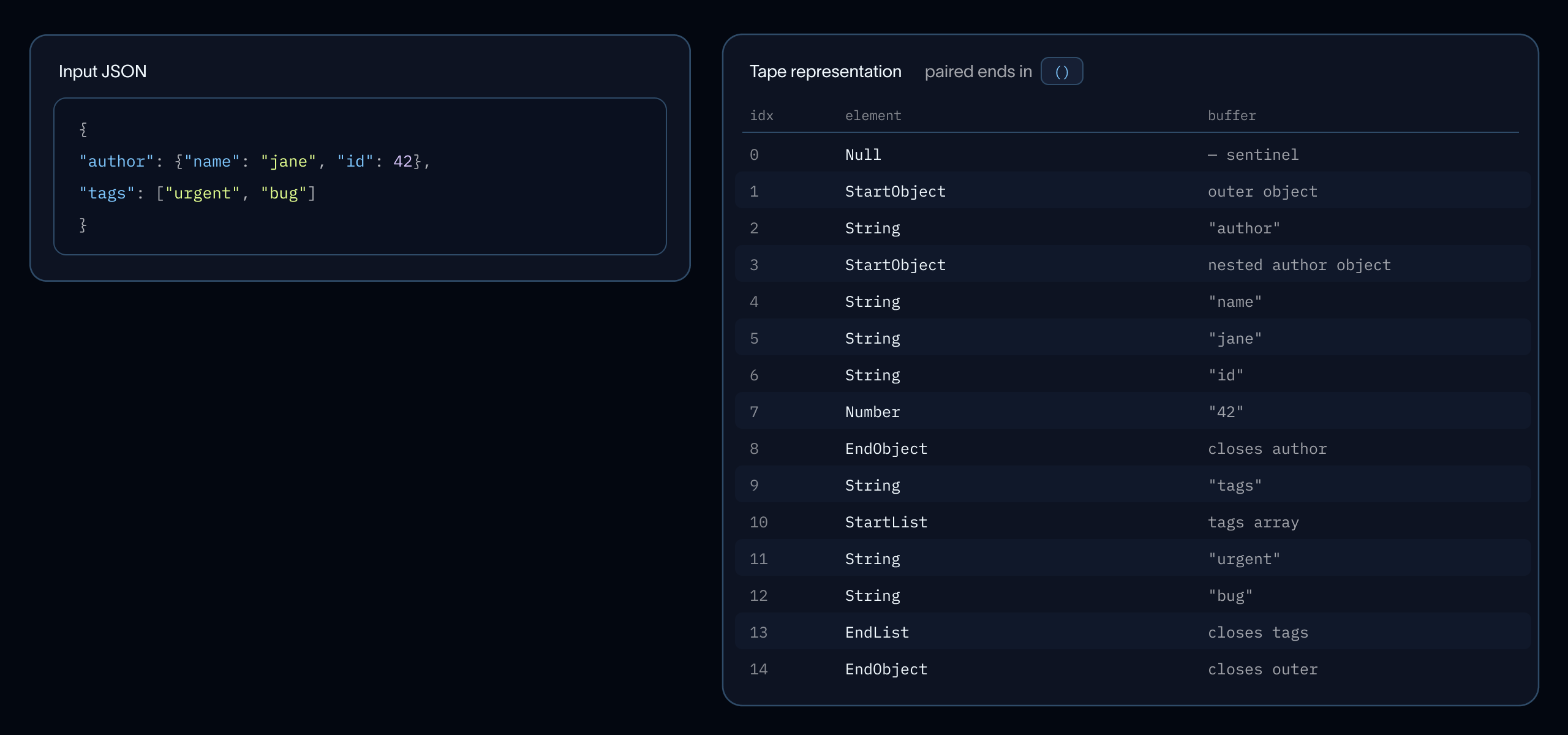
토큰화 (Tokenization)
값이 인덱스 용어(Index term)가 되기 전에 토큰화(Tokenized) 과정을 거칩니다. 즉, 비알파뉴메릭(Non-alphanumeric) 경계에서 분할되고, 소문자로 변환되며, 불용어(Stop words)가 제거되고, 최대 256자로 제한됩니다.
정렬 및 인터닝 (Sorting and interning)
우리의 역색인 (Inverted index) 구현에서 용어 레이아웃 (Term layout)을 위해 유한 상태 트랜스듀서 (Finite State Transducers, FSTs)를 사용한다는 점을 상기하십시오. 평면 포스팅 테이블 (Flat postings table)은 FST 라이터 (FST writer)에 전달되기 전에 반드시 용어(Term)별로 정렬되어야 합니다.
에이전트 트레이스 (Agent traces) 전반에 걸쳐, 특정 테넌트 (Tenant) 및 트레이싱 프로젝트 (Tracing project)의 거의 모든 문서에는 동일한 JSON 경로와 토큰 값이 반복됩니다. 이를 단순하게 구현하면, 이 정렬 과정은 문자열 비교 (String comparisons)에 의해 지배됩니다. 이를 해결하기 위해 우리는 문자열 인터닝 (String interning)을 활용합니다. 이는 각 고유 용어를 사전에 압축된 정수 ID로 매핑하는 기술입니다. 그 결과, 비교 비용은 발생 횟수가 아닌 **고유 용어 (Distinct terms)**의 수에 따라 확장되므로, 벤치마크에서 구축 시간을 약 2.2배 단축했습니다.
우리는 해싱 (Hashing)을 위해 ahash를 사용하며 (표준 라이브러리는 약 20% 느리고, Tantivy의 MurmurHash2는 약 30% 느림), 모든 바이트를 하나의 연속된 버퍼 (Contiguous buffer)에 저장하고, Hashbrown의 raw API를 사용하여 각 인터닝 호출당 각 문자열을 정확히 한 번만 해싱합니다. 그런 다음 각 발생 위치는 평면 테이블에 (doc_id, term_rank, position) 트리플 (Triple)로 기록됩니다. 우리는 정렬된 런 (Sorted run)이 FST 라이터에 전달되기 전, O(n) 시간 복잡도로 용어별 포스팅을 그룹화하기 위해 기수 정렬 (Radix sort)을 활용합니다.
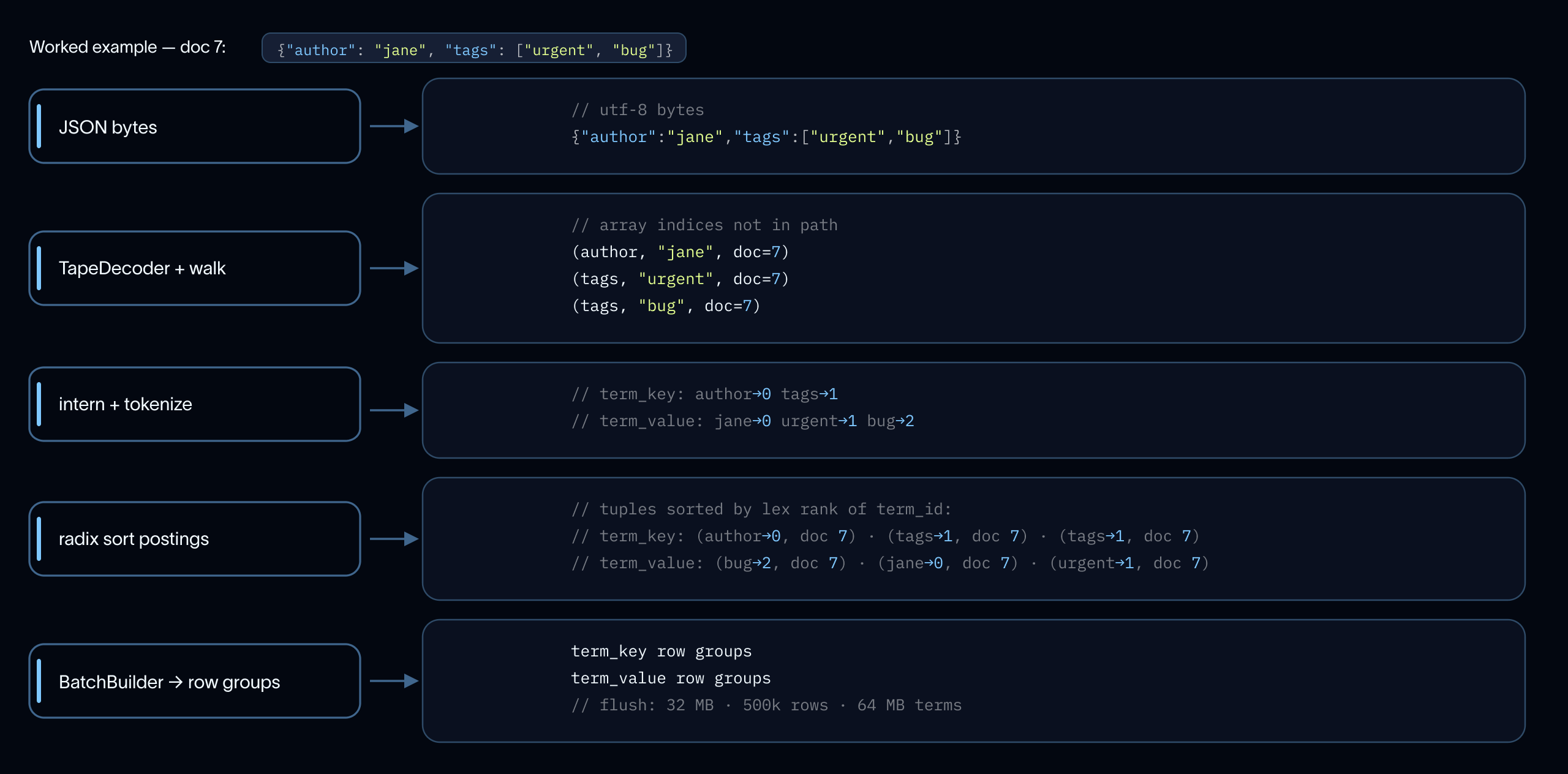
플러시 임계값 (Flush thresholds)
쓰기 전에 전체 배치를 모두 모으는 방식은 고빈도 용어(5, agent 또는 일반적인 JSON 키)가 무제한으로 커지게 만들 수 있습니다. 인덱스 쓰기 중에 우리는 세 가지 임계값에 대해 최적화된 플러시 경계 (Flush boundaries)를 가집니다:
- 로우 그룹 (Row group): 32 MB 포스팅 / 500 K 용어 / 64 MB 원시 용어 바이트. 이는 인메모리 FST 라이터를 주소 지정 가능한 메모리 (Addressable memory) 내에 유지하도록 크기가 조정되었습니다.
- 정렬된 청크 (Aligned chunk): 약 2 MB. 포스팅과 위치(Positions)가 일치하는 문서 경계에서 플러시되어, 두 정보를 모두 읽는 쿼리가 단일 GET 요청으로 연속된 바이트 범위 (Contiguous byte ranges)를 가져올 수 있게 합니다.
- 중간 용어 위치 스필 (Mid-term position spill): 8 MB.
5와 같이 Zipfian 분포의 꼬리 부분에 해당하는 용어들이 용어 처리가 끝나기 전에 수억 개의 위치 정보를 축적하는 것을 방지하기 위한 탈출구 (Escape hatch)입니다.
각 컬럼 내의 청크는 디스크 상에서 바이트 단위로 연속되어 있으므로, 모든 임계값은 최악의 경우의 GET 크기 및 최악의 경우의 메모리 사용량 (Memory footprint)과 직접적으로 매핑됩니다.
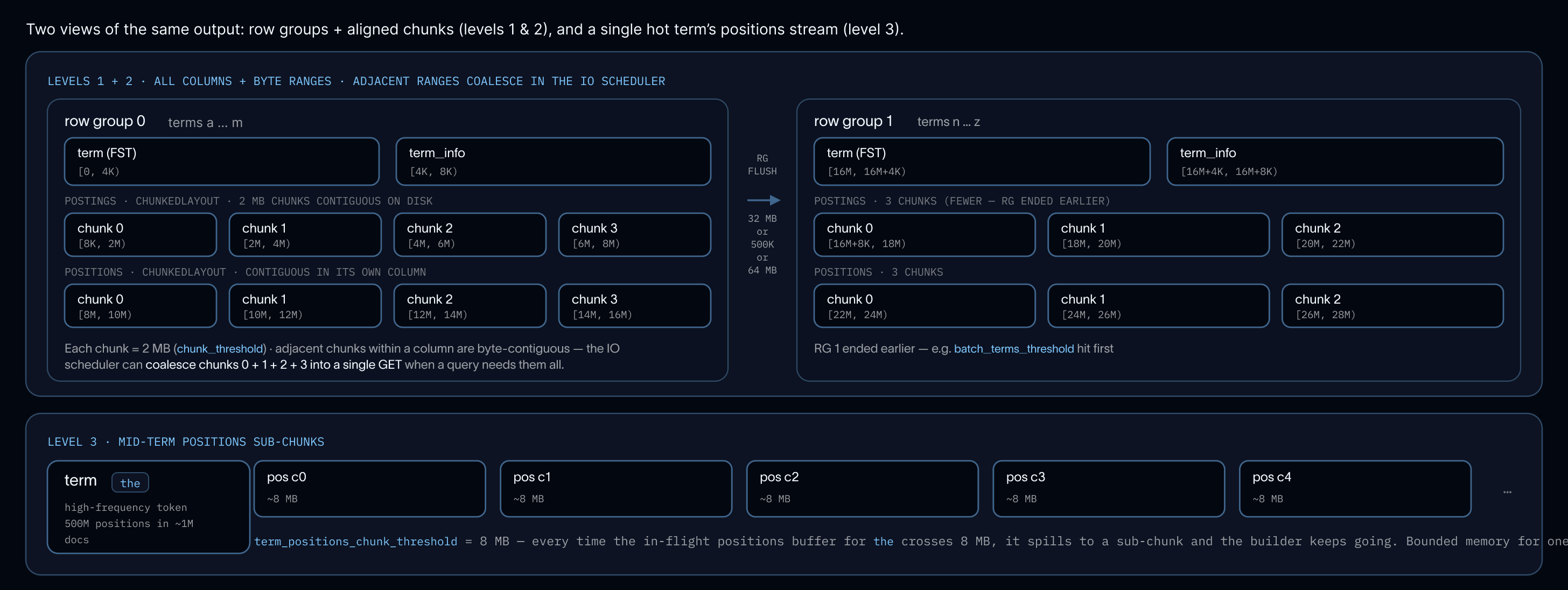
인덱스 병합 (Index merge)
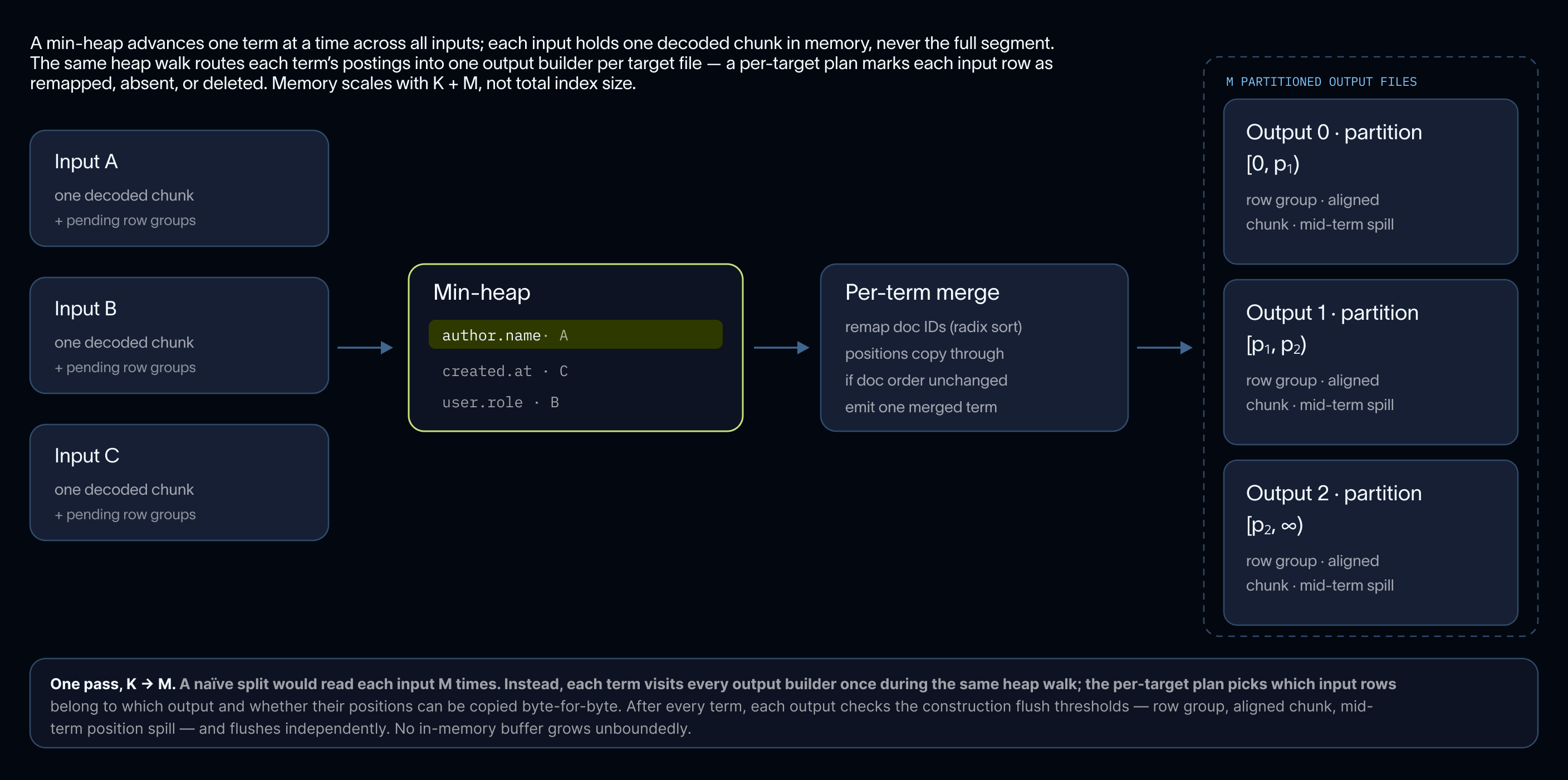
우리의 컴팩션 서비스 (compaction service)는 인제스션 (ingestion)에 의해 작성된 더 작은 파일들을 쿼리에 더 최적화된 더 큰 파일들로 병합합니다. 코어 파일 (core files)을 컴팩션하는 것과 동시에, 이 서비스는 각 코어 파일의 파일별 인덱스를 스트리밍 병합 (streaming merge) 방식으로 처리합니다.
최소 힙 (min-heap)이 모든 입력값에 대해 한 번에 하나의 용어 (term)를 전진시키며, 각 입력값은 한 번에 하나의 디코딩된 청크 (decoded chunk)만을 메모리에 유지하며 전체 세그먼트 (segment)를 유지하지는 않습니다. 병합된 용어들은 이미 정렬된 상태로 나타나며 (FST 작성에 필요함), 생성 시와 동일한 세 가지 플러시 임계값 (flush thresholds: 로우 그룹 (row group), 정렬된 청크 (aligned chunk), 중간 용어 위치 스필 (mid-term position spill))이 매 용어마다 출력 빌더 (output builder)를 제한합니다. 메모리는 참여하는 세그먼트의 수와 관계없이, 병합되는 입력값의 수에 따라 확장됩니다.
쿼리 시간 (Query time)
읽기 경로 (read path)는 SmithDB의 나머지 쿼리들이 이미 통과하고 있는 동일한 메커니즘 (DataFusion 및 Vortex의 LayoutReader 파이프라인)을 재사용하며, 역색인 (inverted index)을 플래너 (planner)가 술어 (predicate)를 밀어넣을 수 있는 또 다른 레이아웃 (layout)으로 끼워 넣습니다. SQL 인터페이스나 쿼리 플래너 (query planner) 측면에서 인덱스가 존재한다는 사실을 새로 학습할 필요는 없습니다. 이 모든 과정은 우리의 TableProvider 및 LayoutReader 구현체에 의해 내부적으로 처리됩니다.
특정 쿼리에 대해, 메타스토어 (metastore)로부터 후보 세그먼트들을 해결한 후, 플래너는 해당 세그먼트들 중 쿼리 중인 컬럼에 대해 실제로 구축된 인덱스가 있는지 확인합니다. 쿼리된 컬럼에 대한 인덱스가 없는 세그먼트는 조용히 컬럼 스캔 (column scan)으로 라우팅되는 대신 처리되며, 인덱스가 있는 세그먼트는 인덱스로 라우팅됩니다. 이 모든 과정은 객체 스토리지 (object-storage) 요청이 발생하기 전에 일어납니다.
하나의 세그먼트, 여러 파일
SmithDB에서 각 메타스토어 엔트리 (metastore entry)는 로우 데이터 (row data)를 보유한 하나의 코어 파일과, 인덱싱된 컬럼당 하나의 형제 파일 (sibling file)을 가리킵니다. 쿼리 시간에서의 과제는 이 파일 집합이 (상위의 DataFusion과 하위의 IO 스케줄러 모두에게) 하나의 주소 지정 가능한 엔티티 (addressable entity)처럼 동작하게 만들면서도, 동시에 각 술어 (predicate)가 실제로 열어야 할 파일을 선택할 수 있도록 하는 것입니다 (모든 술어가 인덱스 파일을 다운로드하고 열 필요는 없습니다).
**계획 시점 (plan time)**에는, 각 술어(predicate)가 세그먼트당 한 번씩 검사되어 다음 세 가지 결과 중 하나로 라우팅됩니다: 인덱스를 통해 읽기 (해당 세그먼트에 해당 컬럼이 인덱싱되어 있음), 코어 파일(core file)에 대한 컬럼 스캔으로 폴백 (사용 가능한 인덱스 없음), 또는 "일치 항목 없음"으로 단락 회로(short-circuit) 처리 (해당 컬럼이 전혀 투영(projected)되지 않음). 이 세 가지 결정은 모든 오브젝트 스토리지(object-storage) 요청이 발생하기 전에 이루어지므로, 쿼리된 컬럼에 대한 인덱스가 없는 세그먼트는 인덱스 파일을 절대 열지 않으며, 인덱스가 있는 세그먼트는 해당 술어에 대해 컬럼을 열지 않습니다.
**런타임 (runtime)**에는, 코어 파일과 각 인덱스 파일이 하나의 가상 레이아웃(virtual layout)으로 구성됩니다. DataFusion은 하나의 논리적 파일 세그먼트로 인식합니다. 투영 푸시다운 (projection pushdown), 술어 푸시다운 (predicate pushdown), 그리고 세그먼트의 로우 인덱스 공간 (row-index space)은 모두 코어 컬럼과 인덱스 컬럼 전체에 걸쳐 균일하게 작동합니다. 반면, IO 스케줄러 (IO scheduler)는 각 하위 파일의 실제 바이트 범위를 확인하므로, 동일한 파일 내의 읽기 작업은 인접한 경우 자연스럽게 병합(coalesce)되고, 그렇지 않은 경우 올바르게 분할된 상태를 유지합니다.
백 개의 컬럼 중 세 개의 컬럼을 사용하는 쿼리는 정확히 세 개의 인덱스 파일만 엽니다. 인덱스를 사용하지 않는 술어는 인덱스 파일을 전혀 열지 않습니다. 특정 컬럼에 대한 인덱스가 누락된 세그먼트는 쿼리의 나머지 부분에 대한 인덱싱을 비활성화하지 않고, 해당 컬럼에 대해서만 투명하게 스캔으로 폴백합니다.
SmithDB SQL 인터페이스 (json_key, json_key_search, search)는 플래너(planner)에 의해 Vortex 표현식으로 재작성됩니다. 시간 범위(time bounds), 투영(projections), 그리고 코어 파일에 대한 조인(joins)은 모두 변경되지 않은 DataFusion 플랜을 통해 실행됩니다. 이전 블로그 포스트에서 설명한 v1→v2 레이아웃 마이그레이션은 Vortex 레이어 상위에서 어떠한 변경도 필요하지 않았습니다. 즉, 표현식 인터페이스는 동일하지만 하단의 바이트 구조만 달라졌습니다.
레이아웃에서 GET 요청까지
이전 블로그 포스트에서는 역색인(inverted index) 데이터를 로우 그룹(row-groups)으로 어떻게 구성하는지 개괄했습니다. 각 로우 그룹 읽기는 두 단계로 이루어집니다: 범위 등록(range registration), 그 다음 디코딩(decode). 리더(reader)는 FST를 통해 용어(term)를 확인하고, 해당 term_info를 읽습니다.
포스팅(postings, 구절 쿼리(phrase queries)의 경우 위치(positions) 포함)의 오프셋(offsets)과 길이(lengths)를 얻기 위한 엔트리에 진입하며, 어떠한 오브젝트 스토어(object-store) 요청을 보내기 전에 필요한 모든 범위를 Vortex 세그먼트 스케줄러(segment scheduler)에 등록합니다. 스케줄러는 인접한 범위들을 병합하고, 최대 1MB 이하의 간격으로 떨어진 비인접 범위들을 결합하며, 병합된 윈도우(window)의 크기는 16MB로 제한합니다.
오브젝트 스토리지(object storage)에서는 각 GET 요청마다 고정된 요청당 지연 시간(latency)과 비용이 발생하며, 이는 작은 크기의 읽기 작업에서 지배적인 요소가 되므로 요청의 수가 중요합니다. 병합(Coalescing)은 약간의 낭비되는 전송량(1MB 미만의 간격)을 대가로 왕복 시간(round trips)을 줄이는 방식이며, 레이아웃이 특정 용어(term)의 범위들을 물리적으로 가깝게 유지하기 때문에 여기서 효과적입니다. 구체적으로, 로우 그룹(row groups)은 32MB의 포스팅 예산(postings budget)에 의해 제한되며, 포스팅(postings)과 위치(positions)는 공유된 문서 경계(document boundaries)에 맞춰 정렬된 약 2MB 크기의 청크(chunks) 단위로 플러시(flush)됩니다. 선택적인 용어에 대한 구절 조회(phrase lookup)는 term_info, postings, positions를 포함하는 하나의 GET으로 해결되며, 비구절 조회(non-phrase lookup)는 term_info와 postings를 포함하는 하나의 GET으로 해결됩니다. 단일 GET은 용어 빈도(term frequency)와 관계없이 로우 그룹 예산에 의해 상한선이 결정됩니다.
로우 그룹의 범위가 가져와지면, 추가적인 오브젝트 스토어 요청 없이 반환된 버퍼 내에서 디코딩(decode)이 완전히 수행됩니다. 탐색(seeking)조차도 로컬에서 이루어집니다. 블록 비트팩킹(block-bitpacked)된 델타(deltas)는 각 블록의 비트 너비(bit width)를 인라인(inline)으로 기록하므로, 블록을 건너뛸 때 디코딩을 하거나 GET을 요청하지 않고도 커서(cursor)를 일정한 오프셋만큼 전진시킬 수 있습니다. 따라서 쿼리가 생성하는 유일한 오브젝트 스토어 요청은 로우 그룹별 읽기 그 자체입니다. 그러므로 쿼리 지연 시간은 가지치기(pruning)를 거쳐 살아남은 로우 그룹의 수에 의해 제한되며, 각 GET은 로우 그룹 바이트 예산에 의해 제한됩니다. 100ms의 왕복 시간(round trip)은 정확히 그 횟수만큼 지연 시간 예산에 포함됩니다.

세 가지 쿼리 형태, 세 가지 조회 경로
라우팅(routing)이 술어(predicate)를 인덱스 레이아웃에 전달하고 나면, 세 가지 쿼리 형태 각각은 v2 컬럼(term, term_info, postings, positions)에 직접 매핑됩니다.
경로 전용(Path-only) (json_key) 방식은 term_key를 탐색합니다.
FST를 통해 포스팅 리스트(postings)를 반환합니다. 이는 구문 쿼리(phrase query)가 아니므로 위치(positions) 정보는 전혀 읽지 않습니다. 디코딩된 포스팅 리스트는 부모 레이아웃 리더(parent layout reader)가 필터링에 사용하는 행 인덱스 마스크(row-index mask)가 됩니다. 이 방식은 세 가지 형태 중 비용이 가장 저렴하며, 존 레벨 프루닝(zone-level pruning)의 효과가 가장 큽니다. 접두사 패턴 경로 쿼리(json_key(inputs, "author.%"))는 FST 작업이 시작되기 전에 대부분의 로우 그룹(row group)을 건너뜁니다(우리의 FST는 파티션되어 있습니다).

키 기반 검색 (Keyed-search) (json_key_search)는 v2 레이아웃에서 도입된 token\0path 키잉(keying)을 사용하여 term_value에 대해 하나 이상의 FST 조회를 수행합니다. 단일 토큰 조회는 단일 FST 완전 일치(exact-match)와 단일 포스팅 페치(postings fetch)로 이루어집니다. 다중 토큰 구문 변형은 먼저 포스팅 리스트를 교집합(intersect)한 다음, 인접성(adjacency) 확인을 위해 PhraseQuery로 넘어갑니다.

전체 텍스트 (Full-text) (search)는 두 가지 모드에서 동일한 term_value FST를 재사용합니다. 일반 텍스트 컬럼의 경우 완전 일치(exact lookup)를 수행합니다. JSON 값에 대한 자유 형식 텍스트(free-text)의 경우, token\0 접두사 스캔(prefix scan)이 해당 토큰이 나타나는 모든 경로를 탐색하고 그 포스팅 리스트들을 합집합(union)합니다. 즉, 하나의 FST가 키 기반 검색과 비키 기반 검색을 모두 처리하므로, 두 번째 사전(dictionary)이나 추가적인 IO가 필요하지 않습니다.
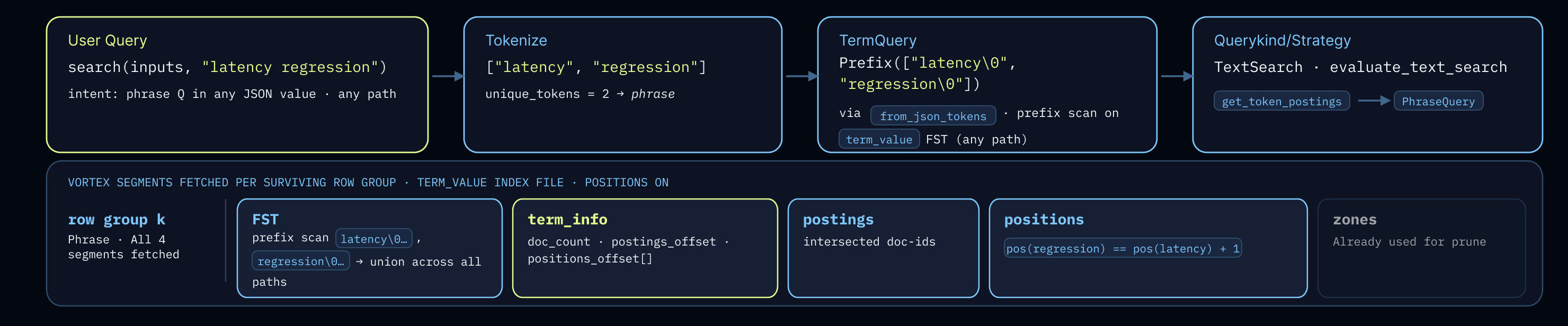
세 가지 형태 중 어느 것이든 다중 토큰 구문은 PhraseQuery를 거치며, 이는 두 단계로 작동합니다. 먼저 포스팅 리스트를 교집합하여 후보 문서(candidate documents)를 좁힌 다음, 해당 후보들에 대해서만 위치(positions)를 디코딩하여 인접성을 검증합니다. 위치 디코딩은 포스팅 교집합 단계 이후에 수행되므로, 일치하는 문서가 적은 구문 쿼리는 위치 정보에 대한 IO를 거의 발생시키지 않습니다. 이러한 비대칭성(asymmetry)이야말로 별도의 positions 컬럼이 설계된 정확한 목적입니다.
최근 수집된 데이터 처리
관측성(Observability) 쿼리는 최근 데이터에 크게 치우쳐 있으며, 고객은 디버깅을 위해 방금 수집한 트레이스(trace)가 몇 초 내에 검색 가능하기를 기대합니다. 이전 섹션에서 설명한 "수집 중에 인라인으로 구축되는 인덱스(indexes built inline during ingestion)" 구조 모델이 이를 가능하게 하지만, 이를 위해서는 읽기 경로(read path)가 두 개의 스토리지 티어(storage tiers)를 아울러야 합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기