RTX 5090와 M4 MacBook Air: 게임이 가능할까?
요약
M4 MacBook Air에 NVIDIA RTX 5090과 같은 데스크톱 GPU를 Thunderbolt eGPU로 연결하는 기술적 시도를 다룹니다. macOS의 드라이버 부재 문제를 해결하기 위해 tinygrad의 AI 스택과 Linux VM을 통한 PCI 패스스루(Passthrough) 방식을 검토하고 그 가능성을 분석합니다.
핵심 포인트
- Thunderbolt를 통해 PCIe 장치를 macOS 호스트에 연결하여 eGPU로 인식시킬 수 있음
- macOS는 Apple Silicon용 NVIDIA/AMD 드라이버를 기본 제공하지 않아 범용적인 사용이 어려움
- tinygrad의 eGPU 드라이버는 AI 추론용으로 개발되었으나, 네이티브 Metal 대비 성능이 매우 낮음
- Linux VM을 활용하여 macOS 호스트 상에서 NVIDIA GPU를 패스스루하는 엔지니어링적 접근법 제시
MacBook Air에 데스크톱용 GPU를 장착할 수 있다면 어떨까요? 알고 보니, 가능합니다.
FTC(연방거래위원회) 규정에 따른 공지: 제 링크를 통해 구매하시면 저에게 소정의 수수료가 지급될 수 있습니다.
확률을 말하지 마라
인정하기 싫지만, 이제 제 프로젝트의 첫 번째 단계는 대부분 AI에게 물어보는 것입니다. 어쩌면 제가 모르는 무언가를 알려줄지도 모르니까요.
다행히도, 거의 불가능에 가까운 일을 시도하는 것이 제 특기입니다.
Thunderbolt eGPU란 무엇인가?
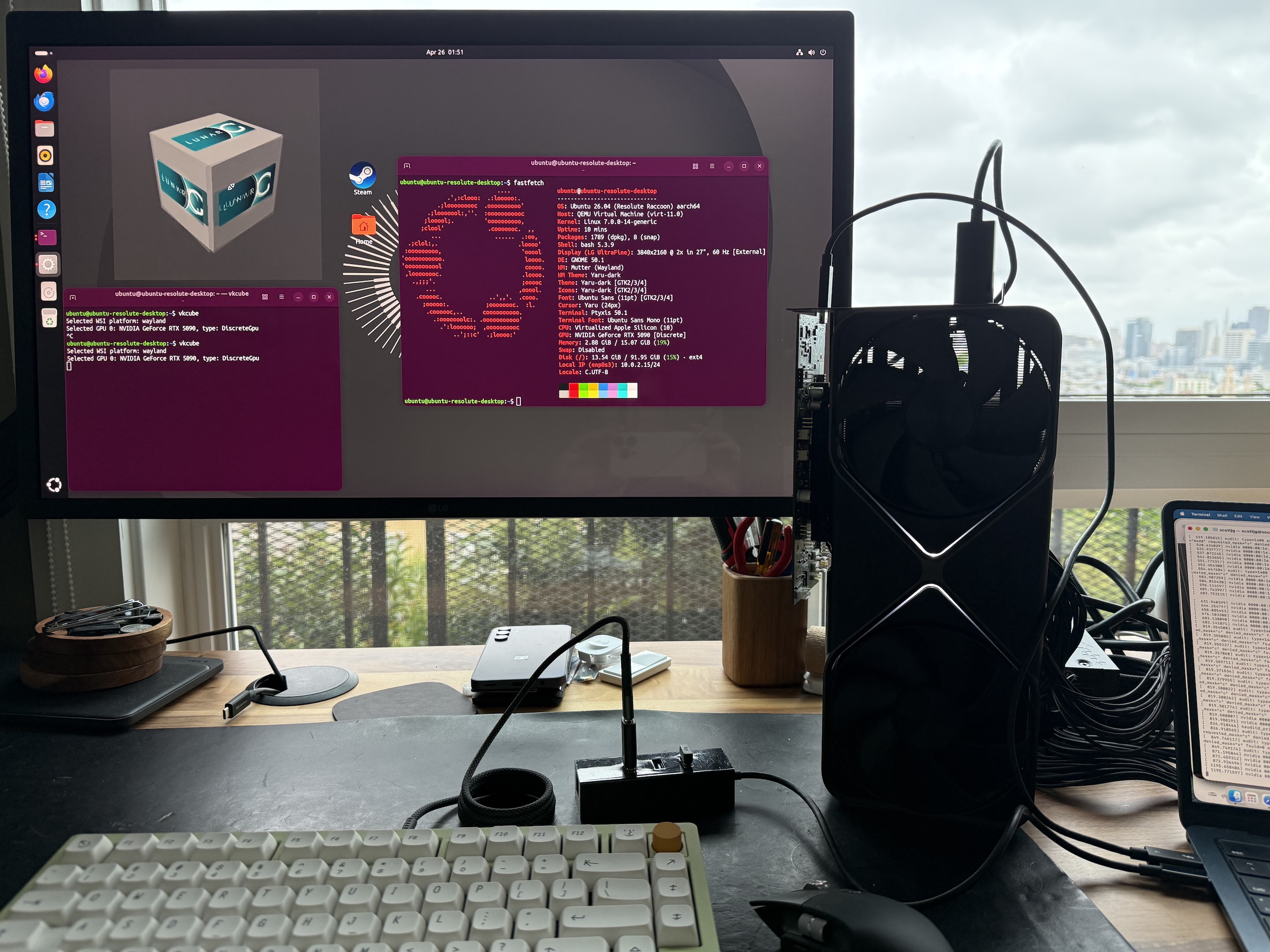
자, 계획은 NVIDIA RTX 5090이라는 거대한 PC 게이밍 GPU를 제 M4 MacBook Air에 연결하는 것입니다. 이를 위해 PCIe를 Thunderbolt로 변환해 주는 Thunderbolt 독(dock)에 GPU를 연결하고, 이를 USB-C 포트에 연결합니다.
Thunderbolt는 USB-C 케이블을 통해 PCIe를 터널링(tunneling)하므로, 컴퓨터 입장에서는 Thunderbolt 장치가 USB 장치가 아니라 실제로 PCIe 장치로 인식됩니다. Thunderbolt 4에서는 터널링으로 인한 약간의 성능 저하가 있지만, 최대 40Gbps 속도로 4개의 PCIe 레인(lane)을 사용할 수 있습니다. USB4 역시 선택적 기능으로 동일한 PCIe 터널링을 포함하고 있으므로, 일부 비-Thunderbolt USB4 포트에서도 이 작업이 가능합니다. 이를 이용해 호환 가능한 포트가 있는 노트북에 GPU를 연결할 수 있습니다.
컴퓨터 입장에서는 해당 장치가 다소 느린 PCIe 장치처럼 보일 뿐이므로, 보통 해당 장치들에 사용하는 것과 동일한 드라이버(driver)를 사용할 수 있습니다. eGPU는 Linux와 Windows에서 거의 즉시 작동합니다. Raspberry Pi에서도 (Thunderbolt가 아닌 Oculink를 사용해야 하지만) 사용하는 것이 가능합니다.
첫 번째 장애물은 macOS가 Apple Silicon용 NVIDIA 또는 AMD GPU 드라이버를 기본적으로 제공하지 않는다는 점입니다.
tinygrad는 어떤가?
tinygrad는 최근 자체적인 macOS eGPU 드라이버를 출시했습니다. 이는 NVIDIA 및 AMD 하드웨어를 위한 자체 오픈 소스 드라이버 파이프라인(driver pipeline)을 갖춘 완전히 새로운 AI 스택(stack)입니다.
안타깝게도, 주요 목적이 AI 추론 (inference)을 실행하거나 게임을 플레이하는 것이라면, tinygrad는 아마 여러분이 찾고 있는 해결책이 아닐 것입니다. 유튜버 Alex Ziskind의 이 영상에 따르면, tinygrad를 통해 eGPU를 사용하여 추론을 수행하는 것은 eGPU 없이 M4 Pro에서 직접 네이티브 Metal 추론을 실행하는 것보다 약 10배 더 느립니다. tinygrad eGPU 드라이버는 tinygrad 스택에서만 사용할 수 있으며, 그 외의 용도로는 사용할 수 없습니다. 또한 다양한 AI 모델에 대한 지원도 매우 제한적입니다.
GPU에서 NVIDIA PTX 코드를 실행하는 것과, 임의의 소프트웨어와 작동하는 완전한 범용 디스플레이 드라이버 (display driver)를 작성하는 것은 별개의 문제입니다. 후자는 훨씬 더 어려운 문제입니다. 따라서 현재로서는, eGPU와 Mac으로 실제로 무엇을 할 수 있을까요?
기존 Linux 드라이버
이제 Apple Silicon Mac에서 Linux를 실행할 수 있습니다. 유감스럽게도, 현재 Linux 커널은 Apple Silicon에서 Thunderbolt를 지원하지 않습니다 (내부 장치와 USB3만 지원). 하지만…
macOS 호스트 상의 64비트 ARM VM에서 Linux를 실행할 수 있습니다. macOS는 Thunderbolt 장치를 지원합니다. Linux는 NVIDIA GPU를 지원합니다. 이제 이 조각들을 모아서 Linux VM으로 GPU를 패스스루 (passthrough) 해보겠습니다.
높은 수준(high level)에서 보면, 우리는 단순히 GPU를 Linux VM에 넣으려는 것입니다. VM은 Mac 호스트와 동일한 아키텍처(arm64)이므로 성능은 비슷할 것입니다. 물론, 세부적인 사항에서 차이가 발생할 수 있습니다.
ARM64 Windows용 NVIDIA 카드 드라이버는 존재하지 않습니다. 이것이 우리가 Linux를 사용하는 이유입니다.
결과에 대한 빠른 영상 데모는 다음을 확인하세요:
포스트의 나머지 부분에서는 이것을 실제로 작동하게 만들기 위한 길고 험난한 과정을 살펴보겠습니다. 스크린샷과 벤치마크 (benchmark)만 보고 싶다면, 아마도 벤치마크 섹션으로 건너뛰어도 좋습니다.
macOS에서 PCI 패스스루 (Passthrough) 엔지니어링
PCI 장치 기초
VM이 PCI 장치와 통신하기 위해 작동해야 하는 두 가지 요소를 살펴보겠습니다:
PCI BAR (Base Address Registers)- 각 PCI 장치는 컴퓨터가 읽고 쓸 수 있는 메모리 청크(chunks of memory)를 통해 통신합니다. 기본적으로 각 장치를 위해 컴퓨터의 메모리에 예약된 영역이 존재합니다. PCI 패스스루 (Passthrough)가 작동하려면 이러한 메모리 영역이 VM으로 미러링(mirrored)되어야 합니다.
DMA (Direct Memory Access)- 이것은 장치가 컴퓨터의 메모리에 직접 정보를 읽고 쓸 수 있는 방식입니다. CPU가 장치로부터 데이터를 복사하기 위해 사이클을 소모하는 대신, 장치가 자동으로 메모리를 복사할 수 있습니다. GPU의 경우, 컴퓨터의 메모리에서 자신의 비디오 메모리(video memory)로 텍스처를 직접 복사하는 데 사용될 수 있습니다.
PCI BAR 매핑 (Mapping PCI BARs)
QEMU가 VM을 시작할 때, 게스트(guest)의 메모리 레이아웃을 설정합니다. 일반적인 RAM의 경우, 이는 QEMU에서 Hypervisor.framework를 사용하는 hvf_set_phys_mem() 호출로 요약됩니다:
hv_vm_map(mem, guest_physical_address, size, HV_MEMORY_READ | HV_MEMORY_WRITE | HV_MEMORY_EXEC);
다음으로, 호스트의 PCIDriverKit 드라이버에 연결하여 PCI 장치의 메모리를 우리 프로세스로 매핑하도록 요청합니다. (드라이버 측 코드는 일단 제외하겠지만, 매우 유사한 보일러플레이트(boilerplate) 코드입니다.)
// BAR0를 현재 프로세스로 매핑하고 `addr`을
// 매핑된 위치로 설정합니다
mach_vm_address_t addr = 0;
...
이제 우리에게 addr이 생겼으며, 이는 이제 우리 프로세스에서 직접 접근할 수 있는 BAR0 메모리를 가리킵니다. 이 시점부터는 다른 메모리 조각과 마찬가지로 단순히 읽고 쓸 수 있습니다.
volatile uint32_t *bar0 = (volatile uint32_t *)addr;
printf("BAR0[0] = %x\n", bar0[0]);
// 출력 결과: BAR0[0] = 0x1b2000a1
...
이제 QEMU가 우리 장치 메모리에 대해 hvf_set_phys_mem()을 호출하도록 만들기만 하면, 해당 메모리를 게스트로 매핑할 수 있습니다. 게스트 코드가 해당 매핑에 접근하면, 호스트의 오버헤드(overhead)를 최소화하면서 GPU와 직접 통신하게 됩니다. 이것이 성능 면에서 최상의 시나리오입니다. 적어도 이론상으로는 말이죠.
실제로는, VM이 PCI BAR 메모리에 접근하자마자 호스트 커널(kernel)이 충돌(crash)했습니다.
이런 경험이 한 번도 없었다면, 매우 당혹스러울 것입니다. 컴퓨터 전체가 멈춰버릴 것이고, 트랙패드 피드백은 소프트웨어에 의해 제어되기 때문에 갑자기 트랙패드가 더 이상 클릭되지 않을 것입니다. 동네의 개와 고양이들이 울부짖기 시작하고, 집 벽에서 사진들이 떨어집니다. 결국 컴퓨터는 재부팅될 것이며, 여러분은 다음과 같은 대화 상자를 마주하게 될 것입니다.
좋습니다, 장치 메모리(device memory)를 직접 매핑할 수는 없지만, 우리에게는 다른 속임수들이 있습니다. 메모리에 대한 모든 접근을 트랩(trap)하고, 게스트(guest)를 QEMU로 다시 종료(exit)시킨 뒤, QEMU가 각 읽기 또는 쓰기를 장치로 전달(forward)하게 할 수 있습니다. 이렇게 하면 동작의 정확성은 유지되지만, 매우 느려집니다. 많은 워크로드(workload)에서 고통은 다른 곳에서 발생합니다. 성능에 민감한 작업의 대부분은 DMA이지만, 일부 경로는 여전히 BAR를 통해 명령을 얼마나 빨리 밀어 넣을 수 있는지에 따라 달라집니다.
저는 Apple을 위한 버그 리포트(bug report)를 준비하기 시작했고, 이 문제를 증명하기 위해 작은 재현 코드(음, AI의 도움을 받은)를 작성했습니다:
#include <Hypervisor/Hypervisor.h>
#include <IOKit/IOMapTypes.h>
#include <libkern/OSCacheControl.h>
...
약 100줄의 C 코드로 VM을 구동하고, 장치 BAR를 게스트에 매핑하며, 이를 건드리는 코드를 실행할 수 있습니다. 이것이 더 좌절스러운 일이었는지 아니면 고무적인 일이었는지는 여전히 잘 모르겠지만, QEMU가 여전히 호스트를 패닉(panic) 상태로 만드는 동안 이 버전은 충돌 없이 실행되었습니다. 한동안 저는 막막했습니다. 게스트 페이지 테이블(guest page tables) 때문이었을까요? BAR가 어떤 미묘한 방식으로 게스트 RAM과 충돌하고 있었던 걸까요? 왜 개와 고양이들은 여전히 울부짖고 있었던 걸까요?
결국, 절박한 심정으로 AI 코딩 어시스턴트(AI coding assistant)에게 제 샘플과 QEMU를 비교해 달라고 요청했습니다. 그것은 즉시 제 매핑이 HV_MEMORY_READ | HV_MEMORY_WRITE를 사용하는 반면,
QEMU는 HV_MEMORY_READ | HV_MEMORY_WRITE | HV_MEMORY_EXEC를 사용한다는 점을 지적했습니다.
아아, 또다시 AI에게 패배했습니다. 이제는 유치한 블로그 프로젝트조차 안전하지 않습니다 (대부분 농담입니다).
QEMU에서의 해결책(workaround)은 작은 변경이었습니다:
diff --git a/accel/hvf/hvf-all.c b/accel/hvf/hvf-all.c
index 5f357c6d19..76cec4655b 100644
--- a/accel/hvf/hvf-all.c
...
작동은 하지만, 완벽하지는 않습니다. ARM에는 여러 종류의 디바이스 메모리 (Device-nGnRnE/nGnRE/nGRE/GRE 제품군)가 있으며, 쓰기 작업이 모아질 수 있는지(gathered), 재정렬될 수 있는지(reordered), 또는 조기에 확인(acknowledged early)될 수 있는지에 대해 서로 다른 규칙을 가집니다. 이는 가장 허용 범위가 넓은 쪽을 기준으로 보면 x86의 쓰기 결합 (Write-combining)과 대략적으로 유사합니다.
실제 하드웨어에서 제 GPU의 프리페치 가능 (prefetchable) BAR들은 모으기 (gathering)를 허용하도록 되어 있어, 대량 쓰기 시 BAR0보다 몇 배 더 빠릅니다. 하지만 hv_vm_map()에는 이를 설정할 수 있는 플래그가 없어서, 모든 디바이스 매핑이 결국 가장 엄격한 nGnRnE로 끝나게 됩니다. 우리가 할 수 있는 일은 없으며, 모든 액세스를 트랩 (trapping)하는 것보다는 여전히 약 30배 빠르지만, BAR 쓰기 속도를 정상적인 경우보다 약 10배 느리게 만듭니다.
DMA
이 부분은 프로젝트에서 단연코 가장 불안정한 부분이었습니다. 우선, VM PCI 패스스루 (PCI-passthrough)가 설정된 Linux 기반 PC에서 이것이 어떻게 작동하는지 살펴본 다음, macOS에서의 과제와 비교해 보겠습니다.
단순히 컴퓨터가 디바이스와 통신하는 경우 (VM이 관여하지 않는 경우), 둘은 직접 대화할 수 있습니다. PC는 디바이스에 "이 메모리 주소에 DMA 버퍼가 준비되었습니다"라고 알려주고, 디바이스는 해당 메모리에 직접 접근할 수 있습니다 (즉, DMA). 간단합니다.
VM이 관여하면 상황은 더 복잡해집니다. 게스트 물리 주소 (Guest physical addresses)는 호스트 물리 주소 (Host physical addresses)와 일치하지 않습니다. VM의 RAM은 호스트 메모리 중 사용 가능한 곳에 할당된 임의의 덩어리일 뿐입니다. 따라서 게스트가 디바이스에 "0x00000000으로 DMA 하세요"라고 말하면, 디바이스는 호스트의 해당 위치에 실제로 무엇이 있든 상관없이 그 위에 마음대로 덮어써 버릴 것입니다. 가장 간단한 해결책은 두 가지입니다:
- 디바이스가 접근하는 동안 게스트 메모리가 페이지 아웃 (paged out)되지 않도록 모든 게스트 메모리를 고정 (Pin)합니다.
- 디바이스와 호스트 메모리 사이에 IOMMU라고 불리는 하드웨어 유닛을 배치합니다. 하이퍼바이저 (Hypervisor)가 게스트 → 호스트 변환 정보를 IOMMU에 프로그래밍하면, 디바이스의 모든 DMA 요청은 실시간으로 재매핑 (remapped)됩니다.
읽기/쓰기 (Read/Write)
0x00000000
0x80000000
0xA0000000
0x20000000
0xA0000000
이것은 투박한 해결책입니다. 게스트 (Guest)는 특별한 조치를 취할 필요가 없지만, 호스트 (Host)는 모든 게스트 RAM을 고정 (Pinned) 상태로 유지해야 합니다. 더 발전된 접근 방식 (가상 IOMMU와 같은)도 있지만, 이는 이 포스트의 범위를 벗어납니다.
Apple Silicon의 DMA
Apple Silicon에는 IOMMU와 거의 동등한 DART라는 하드웨어 유닛이 있습니다. 이는 VM에만 국한된 것이 아니라, 장치가 임의의 호스트 메모리에 접근하는 것을 방지하는 보안 경계 (Security boundary) 역할도 수행합니다. 이상적으로는 위에서 언급한 간단한 사례에서 Linux가 IOMMU를 사용하는 것과 동일한 방식으로 DART를 사용하면 됩니다.
불행히도, DART는 (적어도 Thunderbolt 장치를 위한 PCIDriverKit를 통해서는) 몇 가지 엄격한 제약 사항이 있습니다:
~1.5GB 매핑 제한 (Mapping limit). 1.5GB RAM을 가진 VM은 기술적으로 부팅할 수 있지만, CUDA는 메모리 부족 현상을 겪게 되며 최신 게임은 8~16GB를 필요로 합니다.
~64k 매핑 상한 (Mapping cap). 많은 수의 작은 DMA 버퍼가 있으면 매핑 테이블이 가득 찹니다.
주소 또는 정렬 제어 불가 (No address or alignment control). PCIDriverKit은 매핑된 주소를 자동으로 할당합니다. 사용자가 주소를 선택하거나 정렬 제약 조건 (Alignment constraints)을 지정할 수 없습니다. 이로 인해 게스트가 자체적인 DMA 주소를 선택해야 하는 가상 IOMMU 방식은 배제됩니다.
1.5GB의 천장은 초기 단계에서 가장 큰 장애물이었습니다. 저는 몇 가지 우회 방법을 시도했습니다. DMA가 위치할 것으로 추측되는 범위를 미리 매핑하는 방식 (당연히 작동하지 않았습니다)과, restricted-dma-pool 디바이스 트리 속성을 사용하여 모든 DMA를 미리 할당된 영역을 통하도록 강제하는 방식을 시도했습니다. 제한된 풀 (Restricted pool) 접근 방식은 더 단순한 장치에는 실제로 작동하지만, GPU 드라이버는 그 모델에 맞추기에는 너무 특이합니다. (상세 내용이 궁금하시다면, 제가 이에 대해 논의한 qemu-devel 스레드가 있습니다.)
apple-dma-pci
결국 저는 QEMU에 apple-dma-pci라고 불리는 새로운 가상 PCI 장치를 설계하게 되었습니다. 이 장치는 패스스루 (Passed-through)된 GPU와 함께 VM에 삽입되며, 게스트의 보조 커널 드라이버가 NVIDIA 드라이버의 DMA 매핑 호출을 가로챕니다 (Intercept). 솔직히 말해서 이 해결책은 매우 화가 나는 해킹 (Hack)이지만, 작동은 합니다.
매핑(Mapping)은 DMA 요청당 필요할 때마다 생성되고 버퍼가 해제될 때 해제되기 때문에, 우리는 특정 시점에 필요한 매핑된 메모리의 양을 줄일 수 있습니다. 게스트 메모리 전체가 아니라, 어느 순간에도 활성(live) DMA 버퍼의 워킹 셋(Working set)만이 우리의 1.5GB 제한 내에 들어오면 됩니다.
게스트 드라이버는 초기에 (/etc/modules-load.d/ 설정을 통해) 로드되므로, 프로브(Probe) 시점에 GPU를 찾아 NVIDIA 드라이버가 건드리기 전에 커스텀 DMA 연산(Ops)을 교체(Swap in)할 수 있습니다:
static struct dma_map_ops apple_dma_ops = {
.map_page = apple_dma_map_page,
.unmap_page = apple_dma_unmap_page,
...
각 커스텀 연산은 얇은 래퍼(Wrapper)입니다. 이는 인자들을 작은 요청(Request)으로 마샬링(Marshal)하고, 이를 apple-dma-pci 가상 BAR(Base Address Register) 메모리에 기록한 뒤, 도어벨 레지스터(Doorbell register)를 트리거하고 응답을 기다립니다. 호스트 측에서는 QEMU가 이 요청을 수신하여 PCIDriverKit 드라이버로 전달하며, 이 드라이버가 실제 DART 매핑을 수행하면 결과로 나온 DMA 주소가 게스트 메모리에 다시 기록됩니다. NVIDIA 드라이버는 이 차이를 알아차리지 못할 것입니다.
NVIDIA 정렬 특이사항 (NVIDIA alignment quirk)
하지만 즉시 잘 작동한 것은 아니었습니다. 드라이버가 처음에는 카드를 로드하고 초기화했지만, CUDA 워크로드(Workload)를 실행하려고 시도하자마자 다음과 같은 재미있는 커널 로그 메시지를 마주하게 되었습니다:
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기