
RAG를 위한 이미지 인덱싱 방법
요약
RAG 파이프라인에서 이미지 데이터를 효율적으로 활용하기 위한 인덱싱 전략을 소개합니다. 쿼리 시점에 비전 모델을 사용하는 대신, 인덱싱 단계에서 저렴한 모델로 이미지를 텍스트로 설명하여 저장함으로써 비용을 절감하고 답변의 질을 높이는 방법을 다룹니다.
핵심 포인트
- 인덱싱 시점에 비전 모델로 이미지 설명을 생성하여 텍텍스트로 저장
- 쿼리 시점의 멀티모달 방식 대비 오버헤드를 1~6% 수준으로 절감
- 설명용 및 핵심 지지형 이미지 모두 답변의 실행 가능성을 높임
- 통계적으로 유의미한 답변 품질 향상 확인
RAG를 위한 이미지 인덱싱 방법
LLM을 위한 기술 문서 내 스크린샷, 다이어그램 및 표 읽기
작성자
Matteo Bortoletto
Kapa는 기술 문서로부터 질문에 답하는 AI 어시스턴트를 구축합니다. 우리가 처리하는 지식 베이스(Knowledge bases)에는 스크린샷, 아키텍처 다이어그램, 회로도, 주석이 달린 UI 워크스루(UI walkthroughs) 등 수백만 개의 이미지가 포함되어 있습니다. 우리는 이러한 이미지들을 우리의 RAG(Retrieval-Augmented Generation) 파이프라인에서 어떻게 유용하게 만들 수 있을지 고민하며 수개월을 보냈습니다.
요약하자면: 우리는 쿼리 시점(Query time)에 모델로 이미지를 보내지 않습니다. 대신 인덱싱 시점(Indexing time)에 저렴한 비전 모델(Vision model)을 사용하여 각 이미지를 한 번 설명하고, 그 설명을 텍스트로 저장한 뒤 일반 텍스트 청크(Text chunks)와 함께 검색합니다. 인덱싱은 일회성 비용입니다. 그 이후 쿼리당 오버헤드는 텍스트 전용 방식 대비 1%에서 6% 수준이며, 답변의 질은 통계적으로 유의미하게 더 좋아집니다. 이 포스트에서는 우리가 어떻게 이 단계에 도달했는지 설명합니다.
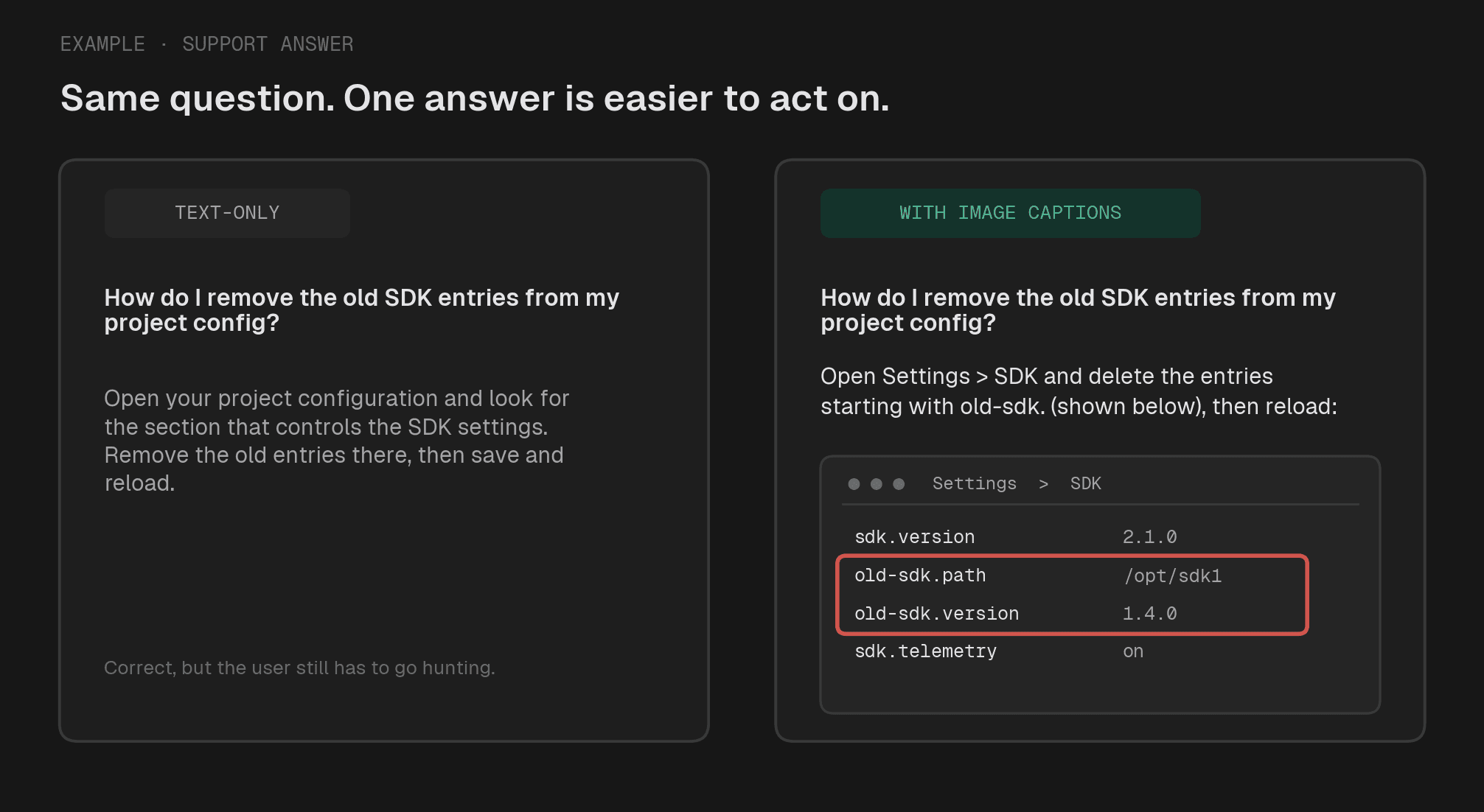
두 답변 모두 정답입니다. 스크린샷을 보여주는 답변은 사용자가 설정을 찾아 헤맬 필요 없이 바로 실행할 수 있는 답변입니다.
기술 문서에서 이미지가 실제로 하는 역할
우리는 하드웨어, 반도체, 개발자 도구 계정에 걸쳐 수천 개의 실제 고객 질문을 검토하여 이미지가 답변에서 어떻게 제 역할을 하는지 확인했습니다. 이미지는 두 가지 유형으로 나뉩니다.
대부분은 설명용(Illustrative)입니다. 텍스트가 이미 말하고 있는 내용을 더 명확하게 보여줍니다. 예를 들어 가이드에서 "설정 아이콘을 클릭하세요"라고 말하면, 옆에 있는 스크린샷은 어떤 아이콘인지, 어디에 있는지, 어떻게 생겼는지를 보여줍니다. 단어는 사실을 전달하고, 그림은 실행을 쉽게 만듭니다.
일부는 핵심 지지형(Load-bearing)입니다. 배선도, 사양 표(Spec table), 인증 또는 색상 가용성 매트릭스는 그림 안에만 존재하고 사실상 다른 곳에는 없는 값을 담고 있을 수 있습니다. 이 경우 그림은 편의를 위한 것이 아니라 답변의 원천(Source)입니다.
우리는 두 경우 모두 성능 향상을 확인했습니다. 이미지 컨텍스트(Image context)를 사용할 수 있을 때, LLM 판독기(LLM judge)는 세 개의 고객 프로젝트와 두 개의 모델에 걸쳐 통계적으로 유의미한 차이(McNemar's test, p < 0.05)로 해당 답변들을 선호했습니다.
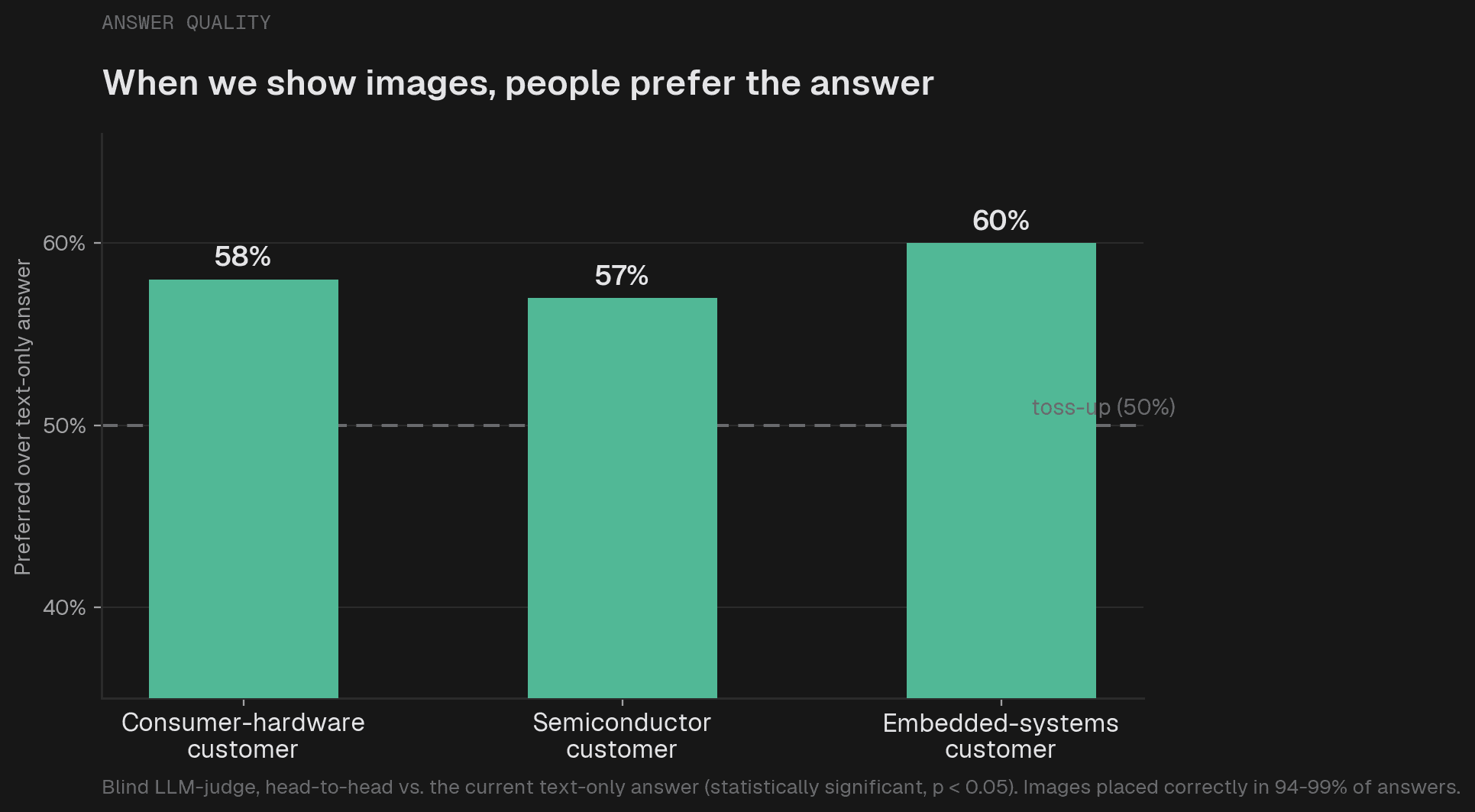
이러한 개선은 사용자가 직접 체감할 수 있는 종류의 것입니다. "설정을 제어하는 구성 섹션을 찾아보세요"라는 답변 대신, 구체적인 경로와 함께 정확히 어디를 클릭해야 하는지를 보여주는 스크린샷을 받게 됩니다. 사실 관계는 동일하지만, 실행하기는 훨씬 더 쉽습니다. 고객 지원 어시스턴트(Support assistant)에게 있어, 이는 사용자가 스스로 문제를 해결하느냐 아니면 지원 티켓(Ticket)을 생성하느냐를 결정짓는 차이입니다.
어떤 방식이든, 이미지는 답변의 질을 실질적으로 향상시킵니다. 엔지니어링 측면에서의 과제는 이 포스트의 나머지 부분에서 다룰 내용입니다. 즉, 모든 쿼리(Query)마다 비전 비용(Vision bill)을 지불하지 않고 이미지를 어떻게 사용할 것인가 하는 문제입니다.
쿼리 시점의 멀티모달 (Query-time multimodal) 방식이 대규모 환경에서 작동하지 않는 이유
대부분의 사람들이 가장 먼저 시도하는 접근 방식은 다음과 같습니다. 관련 청크(Chunk)를 검색하고, 해당 청크가 참조하는 이미지들을 수집하여 모든 정보를 비전 기능이 있는 모델(Vision-capable model)에 전달하는 것입니다.
우리는 수백 개의 실제 운영 질문(Production questions)을 대상으로 GPT 5.1 및 Claude 4.6 Sonnet을 사용하여 이를 테스트했습니다. 문제는 튜닝을 통해 해결할 수 있는 엔지니어링 세부 사항이 아니라 구조적인 문제였습니다.
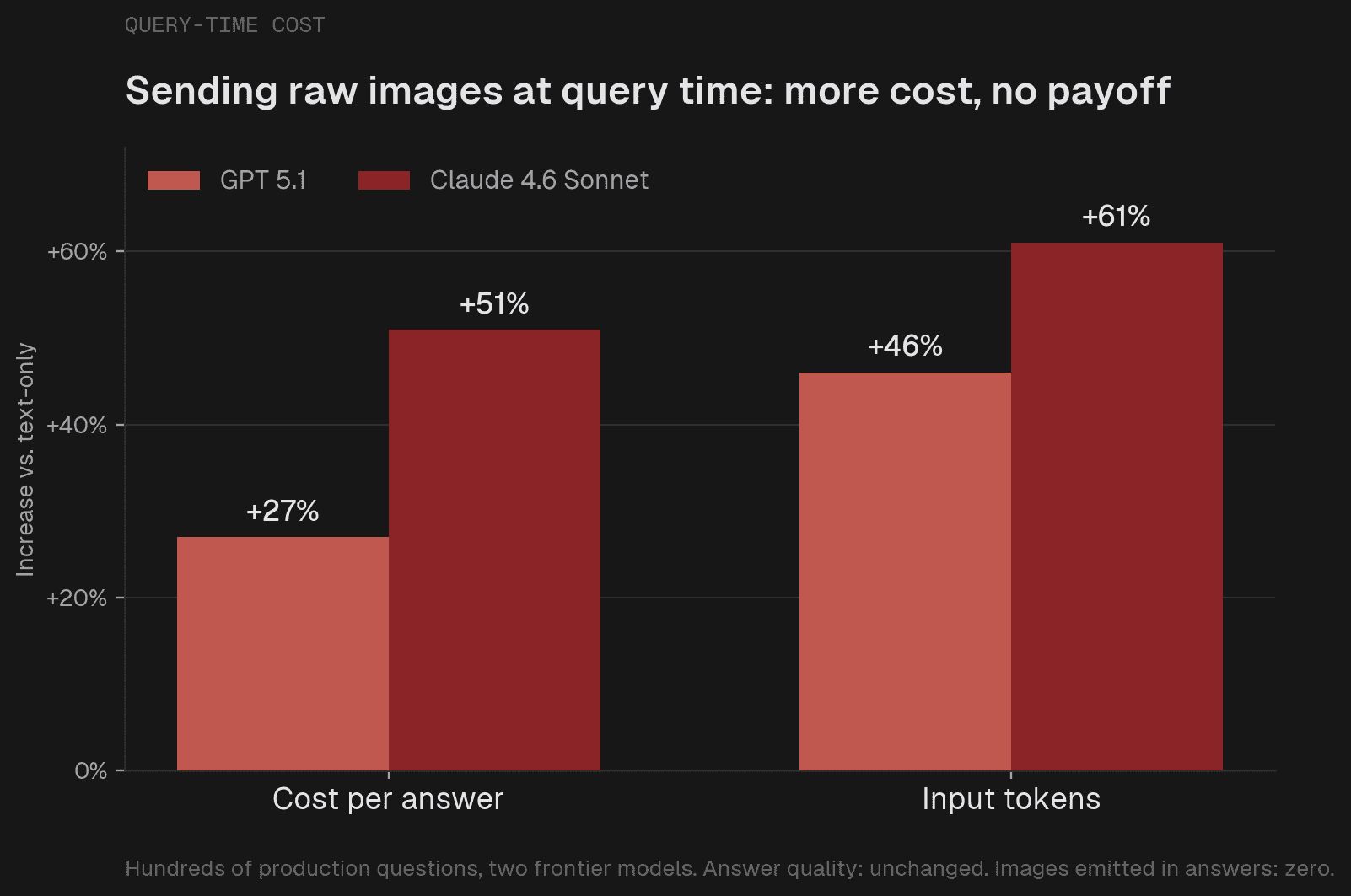
경제성이 맞지 않습니다. 원본 이미지를 추가했을 때 쿼리당 비용이 GPT에서는 27%, Claude에서는 51% 증가했습니다 (Claude는 이미지를 약 975 토큰으로 토큰화하는 반면, GPT는 716 토큰을 사용합니다). 우리는 수백만 개의 쿼리를 처리합니다. 대부분의 답변이 픽셀을 새로 살펴볼 필요가 없음에도 불구하고, 모든 쿼리에 대해 그만큼의 추가 비용을 지불하는 것은 우리가 감당할 수 있는 거래가 아닙니다.
이미지가 물리적으로 들어가지 않습니다. 전형적인 질문은 평균 2030개의 이미지를 참조하는 1030개의 청크를 검색하며, 130개를 넘어가는 경우도 많습니다. Claude의 페이로드 제한(Payload limit)은 30MB이고 OpenAI는 50MB입니다. 약 25장의 이미지만으로도 이미 Claude의 한계치에 도달합니다. 이미지를 공격적으로 제한해야 할 텐데, 이는 이미지 사용의 목적 자체를 무색하게 만듭니다.
멀티모달 검색 (Multimodal retrieval)은 이 도메인에 적합하지 않습니다. CLIP 스타일의 임베딩(Embeddings)은 차트, 표, 주석이 달린 스크린샷에서 중요한 미세한 디테일을 희석시키며, 짧은 기술적 질문("X를 어떻게 구성하나요")은 이미지 벡터와 매칭하기에 신호(Signal)가 너무 적습니다.
이것들은 수정해야 할 버그가 아니라 현재 생태계의 특성입니다. 이러한 특성들로 인해 우리는 쿼리 시점의 비전 방식을 완전히 배제하게 되었습니다.
인덱싱 시점에 한 번 설명하고, 텍스트로 검색하라
성공적인 접근 방식은 경제성을 역전시킵니다. 매 쿼리마다 이미지를 처리하는 비용을 지불하는 대신, 인덱싱 (Indexing) 시점에 한 번만 비용을 지불하여 각 이미지를 텍스트 설명으로 변환합니다. 그 이후의 검색 (Retrieval) 및 생성 (Generation) 과정은 전적으로 텍스트로 수행됩니다.
인덱싱 시점에 비전 언어 모델 (Vision Language Model)이 각 이미지에 대한 캡션 (Caption)을 작성합니다. 이 캡션들은 일반적인 텍스트 청크 (Text Chunks)와 함께 저장되고 검색됩니다. 쿼리 시점에 캡션이 관련이 있다면, 검색기 (Retriever)가 이를 가져옵니다. 모델은 캡션만을 보며 원본 이미지는 결코 보지 않지만, 원래의 URL을 통해 해당 이미지를 인용합니다.
이 방식이 작동하는 이유는 이미지를 실제로 살펴보는 무거운 작업이 매 쿼리마다 일어나는 대신, 데이터 수집 (Ingestion) 시점에 단 한 번만 발생하기 때문입니다. 예시용 스크린샷의 경우 캡션은 설명이 되며, 핵심적인 역할을 하는 도표 (Figure)의 경우 도표가 담고 있는 내용, 표의 값, 다이어그램의 라벨 등을 전사 (Transcription)한 것이 됩니다. 어떤 방식이든 콘텐츠는 텍스트가 되며, 나머지 파이프라인은 픽셀을 볼 필요가 없습니다. Microsoft의 연구 팀 또한 동일한 결론에 도달했습니다: 수집 시점에 설명하고, 별도의 청크로 저장하라.
이것이 핵심적인 사례를 작동하게 만드는 요소이며, 동시에 많은 어시스턴트들이 조용히 실패하는 지점이기도 합니다. 색상 가용성 매트릭스 (Color-availability matrix)는 체크 표시로 가득한 벽과 같고, 내화성 표 (Fire-resistance table)는 등급이 나열된 그리드 형태입니다. 일반적인 추출기 (Extractor)를 사용하여 이를 평문 텍스트로 펼쳐버리면 구조가 해체되며, 이로 인해 어시스턴트가 고객에게 존재하지 않는 색상의 패널이 있다고 자신 있게 말하는 상황이 발생합니다. 수집 시점에 전사된다면, 동일한 매트릭스는 검색 가능한 텍스트가 되며 답변은 도표가 실제로 보여주는 내용에 근거하게 됩니다.
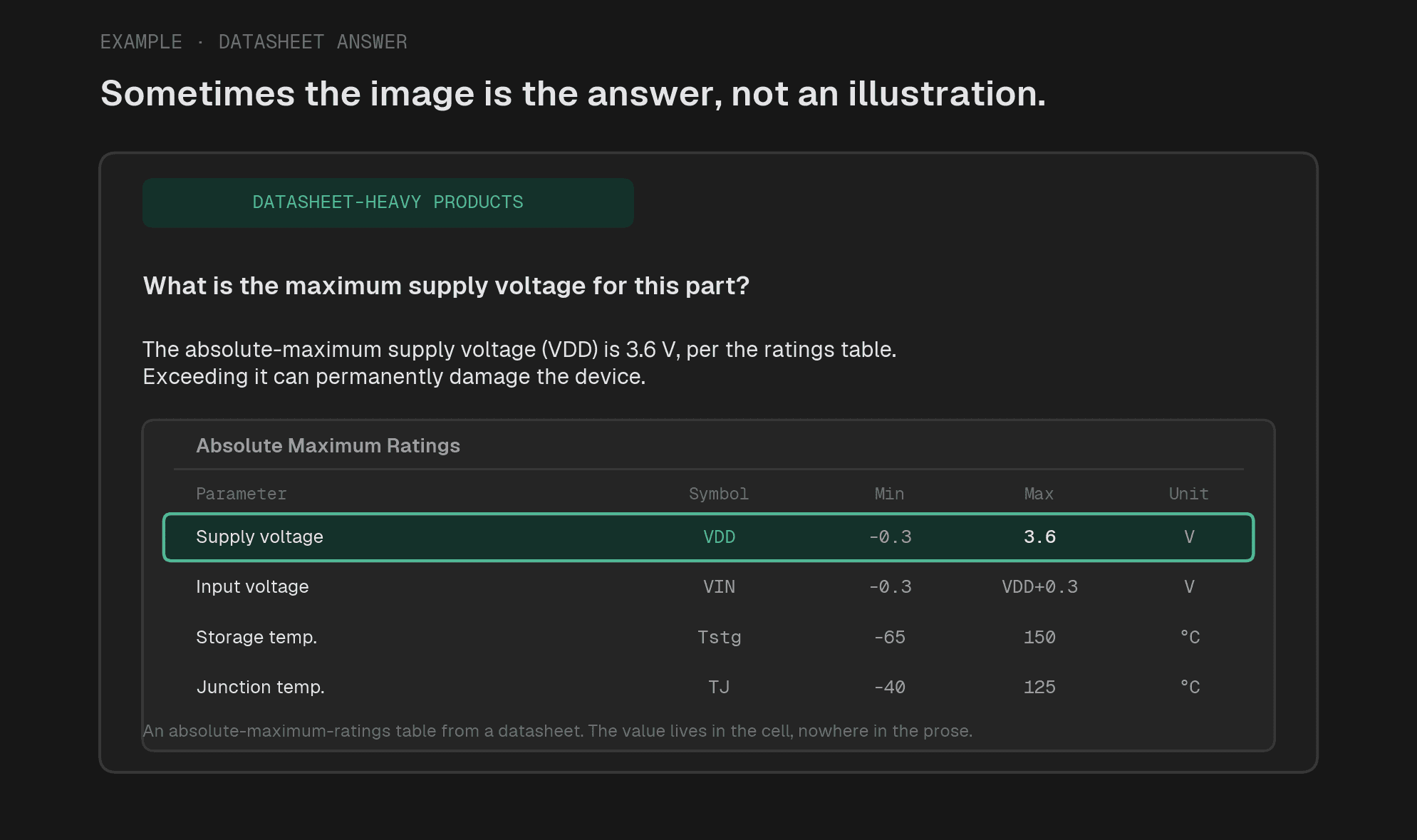
데이터시트 비중이 높은 제품의 경우, 도표 자체가 정답이 될 수 있습니다. 다만, 실제 운영 환경의 사용자 질문을 기반으로 했을 때 이러한 경우는 드뭅니다.
운영 환경에서 반드시 제대로 구현해야 할 것
필터링: 대부분의 이미지는 불필요하며, 일부는 분류할 수 없습니다
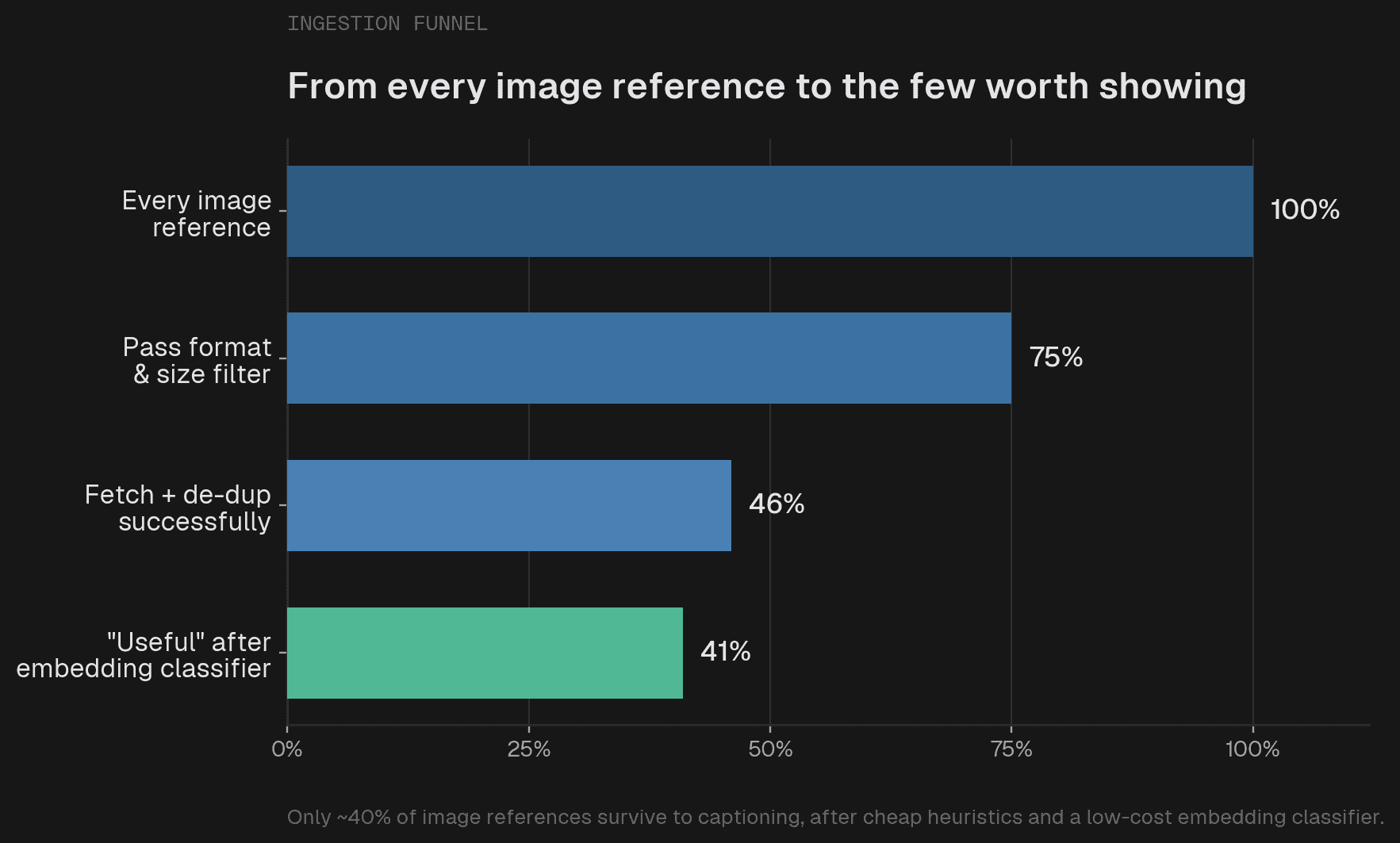
수백만 개의 이미지에 무분별하게 캡션(Caption)을 달 수는 없습니다. 대부분은 로고, 아바타, 소셜 프리뷰 카드, 장식용 배너와 같은 노이즈입니다. 휴리스틱(Heuristics)을 통해 1차 처리(지원되지 않는 형식, 너무 작은 이미지, 극단적인 종횡비 제거)를 수행합니다. 남은 이미지들에 대해서는 멀티모달 임베딩(Multimodal embeddings)을 기반으로 제로샷 분류기(Zero-shot classifier)를 구축했습니다. 이는 전체 코퍼스(Corpus)에 걸쳐 실행하기에 충분히 저렴합니다.
명확한 이미지의 경우 96.8%의 정확도(F1 0.974)를 기록합니다. 하지만 모호한 이미지의 경우 정확도가 59.8%로 급락하는데, 그 이유는 근본적입니다. 카운트다운 타이머의 스크린샷은 장식용 배너일 수도 있고, 타이머에 관한 튜토리얼의 3단계일 수도 있습니다. 픽셀은 동일합니다. 주변 텍스트가 없다면 결정하기 위한 정보가 충분하지 않으며, 어떤 임베딩 모델(Embedding model)도 이를 해결할 수 없습니다. 따라서 우리는 이를 수용합니다. 분류기는 명확한 쓰레기(휴리스틱을 통과한 것 중 약 13%)를 제거하고, 우리는 모호한 경계 사례를 감수합니다. 문맥 인식 분류(Context-aware classification)가 명백한 다음 단계입니다.
캡셔닝(Captioning): 모델 크기보다 문맥이 더 중요하다
캡션의 품질을 결정하는 두 가지 요소가 있습니다. 첫째는 주변 텍스트입니다. 이미지 전후의 단락을 모델에 입력하면 품질이 비약적으로 상승합니다. 문맥이 없다면 파일 업로드 대화 상자는
캡션(Caption)이 텍스트 바로 옆에 위치하기 때문에 인라인(Inline) 방식이 승리할 것으로 예상했습니다. 하지만 비용과 이미지 사용량 측면 모두에서 분리(Separate) 방식이 승리했습니다. 인라인 캡션은 해당 캡션이 포함된 모든 청크(Chunk)의 크기를 부풀리며, 이미지가 관련이 있는지 여부와 상관없이 모든 쿼리(Query)마다 해당 청크들이 전송됩니다. 반면 분리된 청크는 리트리버(Retriever)가 관련이 있다고 판단할 때만 컨텍스트(Context)에 포함되므로, 이미지가 중요할 때만 비용을 지불하면 됩니다. 이미지 비중이 높은 한 프로젝트에서는 GPT 사용 시 인라인 방식의 쿼리당 비용이 19% 상승한 반면, 분리 방식은 6% 상승에 그쳤습니다. Claude의 경우, 분리된 캡션은 텍스트 전용 방식에 비해 비용을 약간 낮추었습니다. 또한 성능 면에서도 가치가 입증되었습니다. 리랭커(Re-ranker)는 전체 순위가 안정적으로 유지되는 동안(Spearman ρ = 0.905), 51%의 쿼리에서 이들을 상위 15위 이내로 끌어올렸습니다.
결과
GPT 5.1 및 Claude 4.6 Sonnet을 사용한 세 가지 고객 프로젝트의 엔드 투 엔드(End-to-end) 결과입니다:
| 텍스트 전용 베이스라인(Baseline) | 이미지 캡션 포함 |
|---|---|
| 답변 내 이미지 인용 | 0% |
| 답변 품질 (LLM 판사) | 베이스라인 |
| 쿼리당 비용 | 베이스라인 |
| 지연 시간 (첫 번째 토큰 생성 시간) | 베이스라인 |
| 모델 불확실성 | 베이스라인 |
| 인덱싱 비용 | 해당 없음 |
모든 실험에서 이미지는 94%에서 99%의 확률로 정확한 위치에 배치되었습니다.
이는 "멀티모달(Multimodal) 모델을 사용하라"는 답변보다는 덜 화려하지만, 바로 그것이 핵심입니다. 이 방식이 효과적인 이유는 비전(Vision) 기능을 적재적소에 배치하기 때문입니다. 즉, 매 쿼리마다 픽셀을 재검토하는 비용을 지불하는 대신, 데이터 수집(Ingestion) 단계에서 단 한 번 이미지가 담고 있는 내용을 텍스트로 변환합니다. 이미지가 단어를 명확하게 해주든 혹은 답변 자체를 담고 있든, 한 번 읽는 것이 더 저렴하며 나머지 파이프라인(Pipeline)의 작동 방식에도 더 적합합니다. 우리가 마주한 제약 사항들은 우회해야 할 장애물이 아니라, 아키텍처(Architecture)가 나아가야 할 방향을 가리키고 있었습니다.
현재 프리뷰(Preview) 단계로 출시 중입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기