Podcast 및 음성 파일을 화자 분리하여 AI 분석하는 데스크톱 앱을 만들었습니다
요약
음성 파일을 업로드하면 화자 분리, 텍text 변환, 키워드 추출 및 웹 검색 기반 분석 리포트를 생성하는 데스크톱 앱 'AI Speak Trace'를 소개합니다. Claude API를 활용해 대화 내용 중 궁금한 점을 즉시 조사할 수 있는 원스톱 워크플로우를 제공합니다.
핵심 포인트
- 화자 분리(Diarization) 및 타임스탬프 기반 음성 재생 지원
- Claude API와 웹 검색을 결합한 심리스한 키워드 분석 리포트 생성
- Tauri v2를 사용하여 저작권 문제를 방지하는 로컬 데스크톱 환경 구축
- 장시간 음성 데이터(Podcast 등) 분석에 최적화된 기능 제공
서론
음성 파일을 업로드하는 것만으로, 화자 분리(Speaker Diarization)・텍스트 변환(Transcription)・키워드 추출・Web 검색이 포함된 분석 리포트까지 일괄적으로 처리할 수 있는 데스크톱 앱 AI Speak Trace를 개인 개발했습니다.
MIT 라이선스의 OSS(Open Source Software)로 공개하고 있습니다. 본 기사에서는 앱의 개요와 개발에 이르게 된 목적을 소개합니다.
개발 목적
누구를 위한 앱인가
음성 대화 내용을 스스로 깊이 파고들어 이해를 높이고 싶은 사람을 위한 앱입니다. 듣는 것으로 끝내지 않고, 대화 내용을 제대로 이해하는 단계까지 지원하는 도구입니다.
왜 Podcast 음성을 분석 대상으로 삼았는가
Podcast를 소재로 하고 있지만, "Podcast 전용인가?"라고 생각하신 분도 계실지 모릅니다. 답은 NO이며, 가지고 있는 음성 파일이라면 동일하게 텍스트 변환 및 분석이 가능합니다.
그렇다면 왜 개발 중인 소재로 Podcast를 선택했는가. 이유는 간단합니다. 장시간 음성 데이터의 샘플로서 가장 다루기 쉬웠기 때문입니다.
- 수십 분~1시간 이상의 장척(Long-form) 음성이 많아, 장시간 데이터에서의 정밀도 검증에 적합함
- macOS의 Podcast 앱에서 로컬로 저장할 수 있어, 시행착오를 위한 소재를 모으기 쉬움
- 2인 대담 형식이 많아, 화자 분리 기능의 검증이 용이함
Podcast는 "딱 적당한 테스트 데이터의 보물창고"였던 셈입니다. 그리고 Podcast에서 작동하는 메커니즘이 만들어지면, 가지고 있는 모든 음성 파일에 그대로 응용할 수 있습니다.
Podcast의 "흘려듣기"를 "학습"으로 바꾸고 싶었다
음성 콘텐츠를 들어도 궁금한 화제를 그 자리에서 깊이 파고들 수단이 없어, 그냥 흘려듣고 끝나는 경우가 많다고 느꼈습니다. 텍스트 변환 + 키워드 추출이 가능하다면, 궁금한 용어나 화제를 즉시 조사하여 대화 내용을 자신의 것으로 만들 수 있습니다.
텍스트 변환의 "그 너머"까지 원스톱으로
텍스트 변환 도구 단독으로는 세상에 많이 존재하지만, 변환된 텍스트에서 의문점을 파고드는 단계까지 일관되게 수행할 수 있는 도구가 필요했던 것이 가장 큰 동기입니다. Claude API의 Web 검색 기능과 조합하여, 텍스트 → 궁금한 용어 → 조사 리포트까지 심리스(Seamless)하게 연결했습니다.
주요 기능
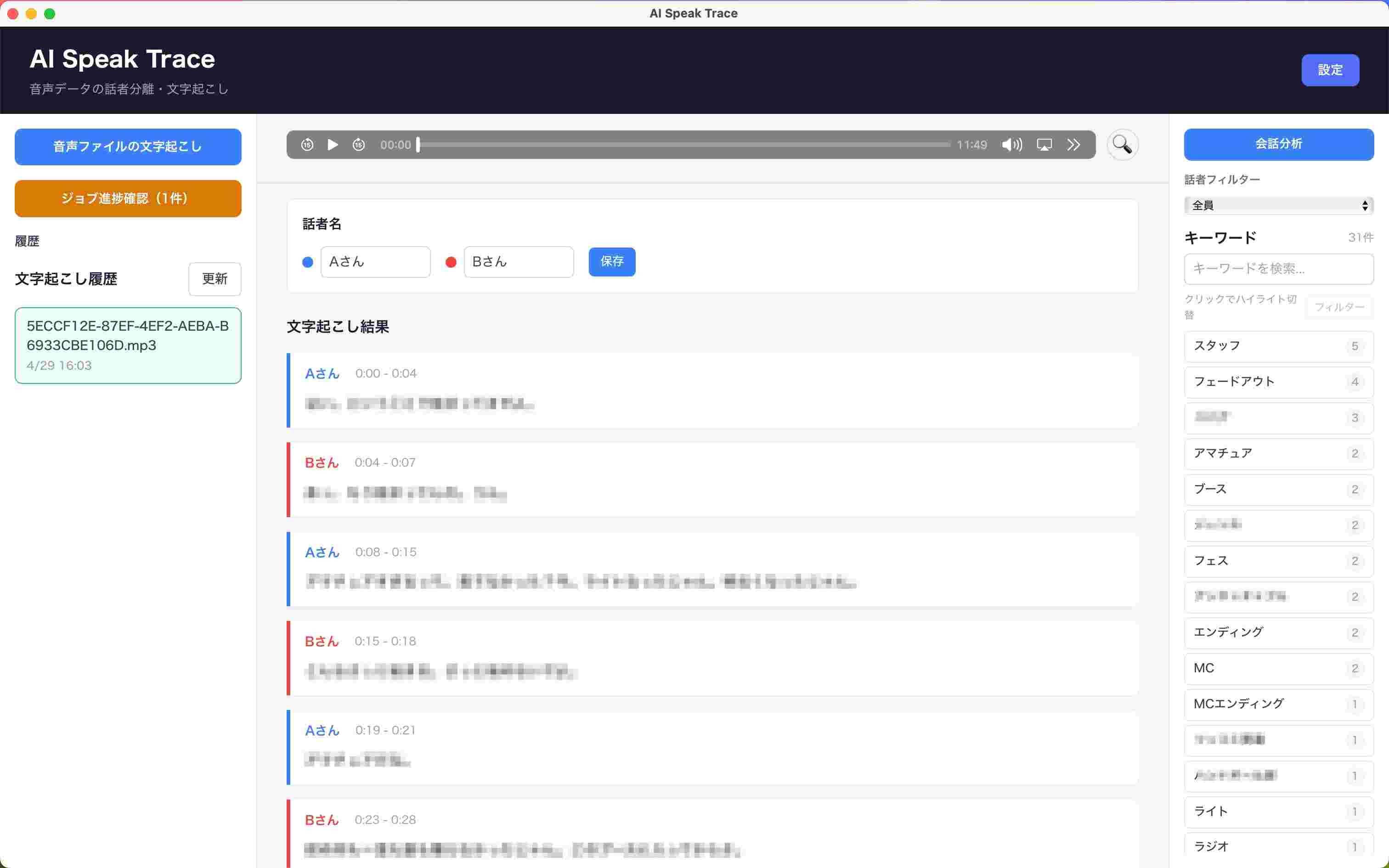
텍스트 변환・트랜스크립트(Transcript) 표시
- 음성 파일을 업로드하면 화자 분리와 함께 텍스트 변환 수행
- 화자별로 색상이 구분된 트랜스크립트 표시
- 화자 이름(기본값 "A씨", "B씨")은 나중에 자유롭게 변경 가능
- 발화의 타임스탬프를 클릭하면 해당 위치부터 음성 재생. 텍스트를 읽으면서 음성을 확인할 수 있음
화자 필터
- 특정 화자의 발화만 골라낼 수 있음
- 필터링 중 발화를 클릭하면 직전의 다른 화자 발화를 팝업으로 확인 가능
키워드 추출 & 대화 분석
- 키워드를 선택하면 해당 발화만 필터링
- 선택한 키워드로부터 Claude가 조사 질문을 자동 생성
- Web 검색이 포함된 분석 리포트 생성 (출처 URL 포함)
- 과거에 생성한 분석 리포트는 언제든 다시 볼 수 있음
기술 스택
| 레이어 | 기술 |
|---|---|
| 데스크톱 | Tauri v2 (Rust + WebView) |
| ... |
기술 선정 이유
Tauri (데스크톱 앱)
데스크톱 앱을 선택한 이유는 크게 3가지입니다.
- 저작권: Podcast 음성을 서버에 업로드하는 Web 서비스로 만들 경우 저작권 문제가 발생할 가능성이 있습니다. 로컬에서 완결되면 파일이 외부로 나가지 않으므로 해당 우려를 회피할 수 있습니다.
- 데이터의 안심감: 음성 파일 및 텍스트 변환 결과는 자신의 머신 내에 저장됩니다. (※ 텍스트 변환 및 분석 자체는 각 API를 이용합니다)
- 비용 관리: ElevenLabs와 Anthropic의 API 키는 사용자 스스로 관리하므로, 종량제 과금을 직접 컨트롤할 수 있습니다.
프레임워크로 Tauri를 선택한 것은 Web 프론트엔드를 그대로 데스크톱 UI로 사용할 수 있어, React + TypeScript 자산을 활용하면서 데스크톱 앱을 만들 수 있다는 점이 결정적이었습니다.
TypeScript (프론트엔드・백엔드 공통)
프론트엔드 (React)와 백엔드 (NestJS)를 모두 TypeScript로 통일했습니다. 본 앱은 Claude Code를 사용하여 개발하고 있으며, TypeScript는 타입 정보 (Type Information)가 있어 AI에 의한 코드 생성 품질이 안정되기 쉽고 궁합이 좋다는 점이 결정적인 이유였습니다.
ElevenLabs Scribe (음성 인식)
여러 음성 인식 API를 비교 검토한 결과, 일본어 받아쓰기 (Transcription) 정확도가 높았던 것이 ElevenLabs Scribe였습니다. 화자 분리 (Speaker Diarization) 정확도를 포함하여 실용적인 수준에 도달했기에 채택했습니다.
구현상의 노하우: 청크 (Chunk) 분할
ElevenLabs Scribe는 공식 문서상 큰 파일도 지원하지만, 실제로 큰 파일을 보내면 실패하는 경우가 있었습니다. 또한 이 API에는 실패 시 중간부터 재개하는 메커니즘이 없어, 실패하면 처음부터 다시 시작해야 합니다.
따라서 앱 측에서 ffmpeg를 사용하여 10분 단위의 청크 (Chunk)로 분할 $\rightarrow$ 순서대로 API에 전송 $\rightarrow$ 타임스탬프 (Timestamp)를 보정하여 병합하는 방식을 채택했습니다. 청크 단위로 처리함으로써, 실패하더라도 완료된 청크는 건너뛰고 중간부터 재개할 수 있습니다.
Claude API (AI 분석)
실제로 사용해 보니 기대한 대로의 출력을 얻을 때까지의 프롬프트 (Prompt) 조정이 쉽고, 개발 컨트롤을 하기 용이하다고 느낀 것이 채택 이유입니다.
사용해 보기
음성 데이터 입수 방법이나 설치 절차는 GitHub의 README를 참고해 주세요.
마치며
Podcast라는 '장시간 음성 데이터의 샘플'에서 시작된 앱이지만, 구조 자체는 모든 음성 콘텐츠에 응용할 수 있습니다.
개발에는 Claude Code를 활용하고 있으며, AI와 대화하며 코드를 써 내려가는 스타일로 개인 개발의 속도를 크게 끌어올릴 수 있었습니다. 'AI로 만든 앱을 AI로 분석한다'는 구조로 되어 있는 점도 개인적으로 마음에 드는 포인트입니다.
같은 고민을 하고 계신 분들께 참고가 된다면 기쁘겠습니다. 마음에 드셨다면 GitHub 리포지토리에 스타 (Star)를 눌러주시면 큰 힘이 됩니다.
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기