Pinecone Serverless를 활용한 RAG 애플리케이션 구축 및 배포
요약
본 기사는 프로덕션 환경에서 RAG(검색 증강 생성) 애플리케이션을 구축할 때 발생하는 관리 및 비용 문제를 해결하는 방법을 다룹니다. Pinecone Serverless를 통한 효율적인 벡터 데이터 관리, LangServe를 이용한 신속한 배포, 그리고 LangSmith를 통한 관찰 가능성 확보를 핵심 솔루션으로 제시합니다.
핵심 포인트
- RAG는 LLM의 환각 현상을 줄이고 최신 컨텍스트를 제공하는 핵심 기술임
- Pinecone Serverless는 인덱스 프로비저닝 부담을 줄이고 사용량 기반 과제로 비용 효율성을 극대화함
- LangServe를 활용하면 LCEL로 구성된 체인을 HTTP 엔드포인트로 빠르게 웹 서비스화할 수 있음
- 프로덕션 수준의 RAG 구축을 위해서는 벡터스토어 관리, 신속한 배포, 관찰 가능성(Observability)이 필수적임
주요 링크
컨텍스트 (Context)
LLM(대규모 언어 모델)은 생성형 AI 애플리케이션의 새로운 시대를 열고 있으며, 새로운 종류의 운영체제의 커널 프로세스가 되고 있습니다. 현대의 컴퓨터에 RAM과 파일 액세스가 있는 것처럼, LLM에는 데이터베이스나 벡터스토어(vectorstores)와 같은 외부 데이터 소스에서 검색된 정보로 채울 수 있는 컨텍스트 윈도우(context window)가 있습니다.
검색된 정보는 컨텍스트 윈도우에 로드되어 LLM 출력 생성에 사용될 수 있으며, 이 과정을 검색 증강 생성 (RAG, retrieval augmented generation)이라고 합니다. RAG는 출력을 근거에 기반하게 함으로써 환각 (hallucinations) 현상을 줄일 수 있고, 학습 데이터에 존재하지 않는 컨텍스트를 추가할 수 있기 때문에 LLM 애플리케이션 개발의 핵심 개념입니다.
프로덕션에서의 과제
이러한 점들을 염두에 두었을 때, 벡터스토어는 관련 컨텍스트를 저장하고 검색하는 좋은 방법을 제공하기 때문에 프로덕션 RAG 애플리케이션에서 상당한 인기를 얻었습니다. 특히, 사용자 제공 입력과 관련된 정보 조각(chunks)을 검색하기 위해 시맨틱 유사도 검색 (semantic similarity search)이 흔히 사용됩니다.
지난 몇 달 동안 Jupyter notebook 및 로컬 벡터스토어와 같은 도구를 사용하는 수많은 RAG 데모가 공유되었습니다. 하지만 몇 가지 페인 포인트 (pain points)로 인해 이러한 데모와 프로덕션 RAG 애플리케이션 사이에는 격차가 존재합니다. 아래에서는 이러한 격차를 극복하는 몇 가지 방법과, 처음부터 프로덕션 RAG 애플리케이션을 구축하는 리포지토리 (repo) 및 실습 영상을 모두 제공하겠습니다.
| 페인 포인트 (Pain Point) | 세부 사항 (Detail) | 솔루션 (Solutions) |
|---|---|---|
| 호스팅된 벡터스토어 관리 | 사용량 기반 요금제 및 무제한 확장성 | Pinecone serverless |
| 신속한 RAG 애플리케이션 배포 | 프로토타입 RAG 애플리케이션의 빠른 배포 | 호스팅된 LangServe |
| RAG 관찰 가능성 (observability) | RAG 애플리케이션의 원활한 관찰 가능성 | LangSmith |
프로덕션을 위한 지원
Pinecone Serverless
Pinecone은 가장 인기 있는 LangChain 벡터스토어 (vectorstore) 통합 파트너 중 하나이며, 호스팅 지원 덕분에 프로덕션 (production) 환경에서 널리 사용되어 왔습니다. 하지만 커뮤니티에서 들려온 최소 두 가지의 페인 포인트 (pain points)가 있었습니다: (1) 직접 Pinecone 인덱스 (index)를 프로비저닝 (provision)해야 한다는 점과 (2) 사용량에 관계없이 인덱스에 대해 고정된 월간 비용을 지불해야 한다는 점입니다. Pinecone serverless의 출시는 클라우드 객체 스토리지 (cloud object storage, 예: S3 또는 GCS)를 통해 "무제한" 인덱스 용량을 제공하고, 서비스 비용을 상당히 절감(사용자가 사용한 만큼만 지불 가능)함으로써 이 두 가지 과제를 모두 해결합니다.
LangServe
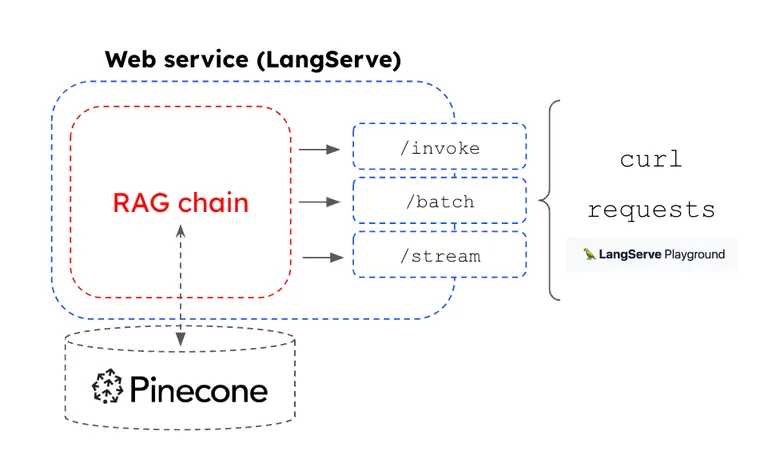
LangChain은 RAG 애플리케이션의 신속한 프로토타이핑 (prototyping)에 인기를 얻었지만, 우리는 모든 체인 (chain)을 프로덕션에 적합한 웹 서비스로 신속하게 배포할 수 있도록 지원할 기회를 보았습니다. 이것이 LangServe를 만든 동기가 되었습니다. LCEL을 사용하여 구성된 모든 체인은 공통된 호출 메서드 세트(예: batch, stream)를 가진 실행 가능한 인터페이스 (runnable interface)를 가집니다. LangServe를 사용하면 이러한 메서드들이 웹 서비스의 HTTP 엔드포인트 (endpoints)로 매핑되며, 이는 Hosted LangServe를 사용하여 관리할 수 있습니다.
LangSmith
LangSmith는 LangServe와 원활하게 통합되는 LLM 관찰 가능성 (observability) 플랫폼을 제공합니다. 우리는 LCEL을 사용하여 Pinecone Serverless에 연결되는 RAG 체인을 구성하고, LangServe로 이를 웹 서비스로 변환하며, Hosted LangServe를 사용하여 배포하고, LangSmith를 사용하여 입출력 (input / outputs)을 모니터링할 수 있습니다.
예제 애플리케이션
이 모든 요소가 어떻게 결합되는지 보여주기 위해 템플릿 리포지토리 (template repo)를 제공합니다.
- Pinecone Serverless 인덱스를 LangChain의 RAG 체인에 연결하는 방법을 보여줍니다. 여기에는 인덱스에 대한 유사도 검색 (similarity search)을 위한 Cohere 임베딩 (embeddings)과 검색된 청크 (chunks)를 기반으로 답변을 합성하기 위한 GPT-4가 포함됩니다.
- LangServe를 사용하여 RAG 체인을 웹 서비스로 변환하는 방법을 보여줍니다. LangServe를 통해 체인은 Hosted LangServe를 사용하여 배포될 수 있습니다.
결론
우리는 프로토타이핑 (Prototyping)과 프로덕션 (Production) 사이의 간극을 메우는 도구에 대한 수요를 확인했습니다. 사용량 기반 요금제 (Usage based pricing)와 무제한 확장성 (Unlimited scaling) 지원을 통해, Pinecone Serverless는 커뮤니티에서 목격해 온 벡터 스토어 (Vectorstore) 프로덕션화 (Productionization) 과정의 고충들을 해결하는 데 도움을 줍니다. Pinecone Serverless는 LCEL, Hosted LangServe, 그리고 LangSmith와 잘 결합되어 RAG 애플리케이션의 용이한 배포를 지원합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기