
Oracle GDAI로 실현하는 글로벌 분산 AI 데이터베이스 정리해 보기
요약
Oracle의 GDAI(Globally Distributed Autonomous AI Database) 솔루션의 특징과 기술적 요소를 정리합니다. 글로벌 분산 데이터베이스 기술과 자율 운영 기능, 그리고 AI 기능을 결합하여 미션 크리티컬한 애플리케이션을 지원하는 방식을 다룹니다.
핵심 포인트
- GDAI는 글로벌 분산, 자율 운영, AI 기능을 통합한 풀 매니지드 서비스임
- 데이터 샤딩을 통해 대규모 미션 크리티컬 애플리케이션 지원 가능
- 자기 관리, 보호, 복구, 최적화 기술로 운영 자동화 및 인적 오류 감소
- AI Vector Search, RAG, Agentic AI와의 조합을 통한 활용 가능성 제시
최근 글로벌 분산 데이터베이스나 분산 SQL에 관한 화제를 자주 접하게 되었습니다.
데이터 레지던시 (Data Residency), 고가용성 (High Availability), 저지연 (Low Latency), 멀티 리전 (Multi-region), 멀티 클라우드 (Multi-cloud), AI 활용 등 키워드만 봐도 상당히 강력해 보이는 세계입니다.
그러한 가운데, Oracle에도 Globally Distributed Autonomous AI Database, 약칭 GDAI라는 솔루션이 있습니다.
즉, 글로벌하게 분산될 수 있고, 자율적으로 운영되며, AI 기능도 갖춘 데이터베이스입니다.
Oracle Globally Distributed Autonomous AI Database (GDAI)는 Oracle Cloud Infrastructure (OCI)가 제공하는 풀 매니지드 (Fully Managed) 서비스이며, 단일 사용자 인터페이스 내에서 글로벌하게 분산된 통합 데이터베이스 간의 데이터 샤딩 (Sharding)을 가능하게 합니다. 대규모 미션 크리티컬 (Mission-critical) 애플리케이션을 지원하도록 설계되었으며, 높은 가용성, 내결함성 (Fault Tolerance), 확장성 (Scalability)을 갖춘 데이터베이스 서비스입니다. 이를 통해 조직은 방대한 양의 데이터를 높은 퍼포선스와 신뢰성으로 저장 및 처리할 수 있습니다.

GDAI는 Oracle Autonomous Database의 자율형 (Autonomous) 기술을 기반으로 구축되었으며, 자기 관리 (Self-management), 자기 보호 (Self-protection), 자기 복구 (Self-healing), 자기 최적화 (Self-optimization)의 개념을 도입한 분산 데이터베이스 서비스입니다.
이를 통해 패치 적용, 튜닝 (Tuning), 백업 및 복구 (Backup and Recovery) 등 데이터베이스 관리에 수반되는 많은 정형 업무를 자동화할 수 있어, 인적 오류 (Human Error)의 리스크를 줄이고 시스템 가동 시간을 향상시킬 수 있습니다.
글로벌 분산 DB, 액티브 글로벌 애플리케이션 구성, 멀티 리전 고가용성, 운영 자동화와 같은 테마는 클라우드 네이티브 (Cloud-native) 애플리케이션 설계에서 점점 더 중요해지고 있습니다.
이 기사에서는 다음과 같은 흐름으로 GDAI를 정리합니다.
- GDAI란 무엇인가
- 어떤 과제를 해결하는가
- 분산 데이터베이스로서의 기술 요소
- 분산 SQL / 글로벌 분산 DB로 볼 때의 관점
- @Hyperscaler에서의 이용 이미지
- 구축 방법의 큰 흐름
- AI Vector Search / Select AI / RAG / Agentic AI와의 조합
- 상정 유스케이스 (Use Case)
GDAI의 특징은 Oracle Database의 기능, Autonomous Database의 자동 운영, Oracle AI Database의 AI 기능, Exadata 기반, Oracle Multicloud를 조합할 수 있다는 점입니다.
특히 Oracle Database의 기존 자산을 가진 시스템에서는 Oracle Database의 기술, 데이터 모델, 애플리케이션 자산을 활용하면서 글로벌 분산, 데이터 레지던시, 고가용성, AI 활용을 검토할 수 있다는 것이 큰 포인트가 됩니다.
그래서 이번에는 아직 실제로 환경을 생성하여 확인하지는 못했지만, 공개된 정보를 바탕으로 GDAI의 개요와 기술 요소를 정리해 보겠습니다.
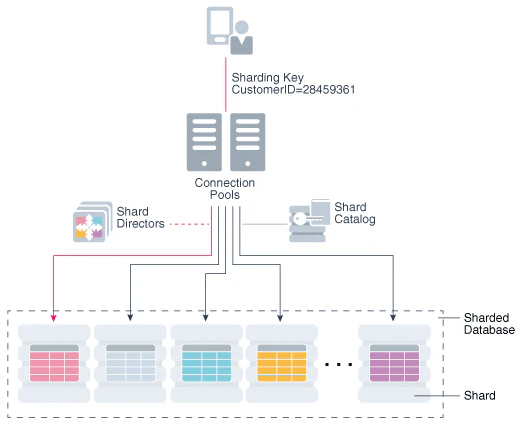
Oracle Globally Distributed Autonomous AI Database는 단일 사용자 인터페이스로부터 여러 database instance, 즉 shard에 걸친 데이터셋을 배포 및 관리할 수 있는, fully managed 형태의 OCI 분산 데이터베이스 서비스입니다.
애플리케이션에서는 하나의 논리적인 Oracle AI Database로 취급하면서, 내부적으로는 여러 Oracle AI Database shard에 데이터를 분산 배치합니다. 이를 통해 데이터 레지던시, 고가용성, 스케일 아웃 (Scale-out), 글로벌 저지연과 같은 요구사항에 대응하기 쉬워집니다.
GDAI는 single logical Oracle AI Database입니다. 내부적으로는 여러 Oracle AI Database shards로 분산되며, 각각의 shard는 논리 데이터베이스의 일부 데이터를 보유하는 독립된 Oracle AI Database 인스턴스입니다.1

GDAI는 다음과 같은 솔루션입니다.
- 애플리케이션에서는 하나의 논리적인 Oracle AI Database로 사용
- 내부적으로는 여러 개의 shard에 데이터를 분산 배치
- shard를 여러 Availability Domain, 리전(Region), 지리적 위치(Geographic Location)에 배치 가능
- Shard Catalog를 통해 분산 데이터베이스 전체의 구성 관리 및 multi-shard query 지원
- Shard Director를 통해 애플리케이션 연결을 적절한 shard로 라우팅
- Data Guard 및 Raft 기반의 복제(Replication)를 통해 고가용성 실현
- Autonomous Database의 자동화를 통해 운영 부하 감소
- Select AI 및 AI Vector Search 등 Oracle AI Database의 기능과 결합 가능
Application
|
| Single logical Oracle AI Database
...
GDAI의 핵심은 단순히 여러 개의 데이터베이스를 나열하는 것이 아닙니다.
데이터 분산, 연결 라우팅, 복제, 고가용성, 관리 자동화를 결합하여, 글로벌 분산 DB를 단일 논리 데이터베이스로 취급한다는 점에 있습니다.
GDAI가 목표로 하는 주요 과제는 다음과 같습니다.
글로벌하게 서비스를 전개하면 국가나 지역마다 데이터 보관 및 처리 장소에 대한 제약이 발생합니다.
예를 들어, 다음과 같은 요구사항이 있습니다.
- 일본 이용자 데이터는 일본 국내에 두고 싶음
- EU 데이터는 EU 내에서 보관 및 처리하고 싶음
- 금융, 공공, 의료 등 규제 요구사항이 강한 데이터를 지역별로 관리하고 싶음
- 글로벌 분석은 수행하되, 데이터의 소재지는 제어하고 싶음
Oracle 공식 페이지에서는 GDAI의 유스케이스(Use Case)로 분산 데이터 웨어하우스(Data Warehouse)나 데이터 레이크(Data Lake)에서의 데이터 레지던시(Data Residency) 요구사항 대응을 꼽고 있습니다. 데이터 분산 정책과 내장된 자동화를 결합함으로써, 데이터셋의 저장과 처리를 필요한 지리적 위치에 유지하면서도 집중 관리를 제공한다는 개념입니다.1
글로벌 애플리케이션에서는 모든 액세스를 단일 리전에 집중시키면 원격지 사용자의 레이턴시(Latency)가 커집니다.
GDAI에서는 데이터를 여러 지역에 분산 배치할 수 있습니다. 이용자와 가까운 곳에 데이터를 두고 애플리케이션이 적절한 shard에 접속할 수 있다면, 로컬 액세스에 가까운 경험을 제공하기 쉬워집니다.
User in Japan -> Japan / APAC side shard
User in US -> US side shard
User in EU -> EU side shard
미션 크리티컬(Mission-critical)한 애플리케이션에서는 리전 장애, 데이터 센터 장애, 노드 장애 등을 상정한 설계가 필요합니다.
shard를 OCI Availability Domain이나 리전에 분산함으로써 고가용성을 제공할 수 있습니다.
또한, 각 shard는 고가용성을 위해 Data Guard로 복제합니다.1
나아가 GDAI는 Raft 합의 프로토콜(Raft consensus protocol)을 통한 내장 복제 및 Oracle Data Guard와 같은 복제 기술을 이용할 수 있다고 설명되어 있습니다.2
GDAI는 shard를 통한 수평 분산 구성입니다.
데이터량이나 트랜잭션량이 증가할 경우 shard를 추가하여, 분산 데이터베이스 전체로서 처리 능력을 확장하는 방식입니다.
라이프사이클 관리로서 Add Shards (Scale Out), Remove Shards (Scale In), Monitor the Deployment 등의 항목이 마련되어 있습니다.3
분산 데이터베이스의 어려움은 분산된 DB 군을 애플리케이션이나 운영자가 어떻게 다루느냐에 있습니다.
GDAI에서는 Shard Catalog가 자동 shard deployment, 집중 관리, multi-shard query를 지원합니다. Shard Director는 분산 데이터베이스에 대한 고성능 연결 라우팅을 제공합니다.
애플리케이션의 요청은 Oracle drivers와 sharding key를 이용하여 대상 shard로 직접 라우팅됩니다.1
이 구성을 통해 애플리케이션은 분산 배치된 데이터를 단일 논리 DB로서 다루기 쉬워집니다.
지금부터 GDAI를 이해하는 데 중요한 기술 요소를 정리하겠습니다.
Shard는 논리 데이터베이스 전체 데이터의 일부를 보유하는 독립적인 Oracle AI Database 인스턴스입니다.
GDAI에서는 단일 논리 데이터베이스를 여러 shard로 분할합니다. 각 shard는 물리적으로 독립되어 있으며, 동일 리전, 여러 Availability Domain, 여러 리전, 또는 여러 지리적 위치(Geographic Location)에 배치할 수 있습니다.
Logical Database
|
+-- Shard A : Customer range A
...
설계 시에는 어떤 단위로 데이터를 분산할지가 중요합니다.
- 고객 ID
- 국가 / 지역
- 테넌트 ID (Tenant ID)
- 사업부
- 애플리케이션 영역
- 데이터 주권 요구사항 (Data Sovereignty Requirements)
글로벌 SaaS라면 테넌트 단위나 리전 단위의 분산이 후보가 됩니다. 금융, 공공, 의료 등의 분야에서는 국가나 규제 단위의 데이터 배치가 중요해질 수 있습니다.
Shard Catalog는 분산 데이터베이스 전체의 관리를 지원하는 컴포넌트입니다.
Shard Catalog는 다음을 지원합니다.1
- 자동화된 shard 배포 (automated shard deployment)
- 중앙 집중식 관리 (centralized management)
- 멀티 샤드 쿼리 (multi-shard queries)
- 자동화된 쿼리 코디네이터 (automated query coordinator)
즉, Shard Catalog는 분산 데이터베이스의 관리 평면 (Management Plane)으로서 중요합니다.
애플리케이션 관점에서는 하나의 논리 DB로 보이지만, 내부적으로는 여러 shard에 분산되어 있습니다. 그 배치와 상태를 파악하고 관리하며, 필요에 따라 여러 shard에 걸친 질의를 지원하는 것이 Shard Catalog의 역할입니다.
Shard Director는 애플리케이션 연결을 적절한 shard로 라우팅하는 컴포넌트입니다.
Shard Director는 분산 데이터베이스 데이터에 액세스하기 위한 고성능 연결 라우팅을 제공합니다. 또한, 애플리케이션 요청은 Oracle drivers와 샤딩 키 (sharding key)를 사용하여 shard로 직접 라우팅됩니다.1
Application
|
| sharding key = customer_id
...
이 부분이 GDAI 애플리케이션 설계에서 중요한 포인트입니다.
애플리케이션이 sharding key를 적절히 다룰 수 있으면, 요청이 대상 shard로 직접 향하기 쉬워집니다. 이를 통해 분산 DB에서 우려되는 불필요한 크로스 샤드 액세스 (cross-shard access)를 줄이고, 성능과 확장성 (Scalability)을 높이기 용이해집니다.
분산 DB에서는 데이터를 분산하는 것만으로는 불충분합니다.
장애 발생 시에도 데이터를 잃지 않고, 일관성 (Consistency)을 유지하며, 서비스를 지속할 수 있어야 합니다.
Oracle Database Insider의 GDAI 기사에서는 GDAI의 고가용성 (High Availability) 및 확장성 맥락에서, Raft 합의 프로토콜 (Raft consensus protocol)을 통한 내장 복제 (embedded replication)와 Oracle Data Guard에 대해 설명하고 있습니다. Raft는 분산 시스템에서 합의 형성을 수행하기 위한 대표적인 알고리즘입니다.2
GDAI에서의 Raft 기반 복제 (Raft-based replication)는 다음과 같은 관점에서 중요합니다.
- 레플리카 (Replica) 간의 일관성 유지
- 장애 발생 시 전환 속도 가속화
- 데이터 손실을 방지하는 설계 지원
- 활성 글로벌 분산 구성이나 고가용성 구성을 지원하는 중요한 기술 요소가 됨
분산 DB에서는 성능뿐만 아니라 일관성과 가용성의 균형이 중요합니다. Raft 기반 복제는 그 핵심에 있는 기술 요소 중 하나입니다.

GDAI에서는 여러 위치에 shard를 분산 배치하고, Shard Director와 Oracle drivers / sharding key를 통해 애플리케이션으로부터 적절한 shard로 연결을 라우팅할 수 있습니다.
이 덕분에 글로벌로 분산된 사용자나 애플리케이션으로부터 데이터 배치 위치와 가까운 shard로 액세스하는 설계를 검토할 수 있습니다.
글로벌 분산 DB에서는 여러 로케이션(Location)에서 애플리케이션을 가동하는 Active-Active형 애플리케이션 구성을 검토하는 경우가 있습니다. 그 경우, GDAI의 shard 배치, Shard Director를 통한 연결 라우팅(Routing), 복제(Replication), 페일오버(Failover) / 페일백(Failback) 설계를 조합하여 고려해야 합니다.
Region A / Cloud A
Application A
Shard / Replica A
...
액티브-액티브(Active-Active) 구성에서는 다음 사항을 설계해야 합니다.
- 어떤 사용자를 어느 로케이션으로 라우팅할 것인가
- 어떤 데이터를 어디에 배치할 것인가
- 쓰기(Write) 작업이 어느 shard로 향할 것인가
- 장애 시 어디로 전환할 것인가
- 복구 후 어떻게 페일백(Failback)할 것인가
- 애플리케이션의 재시도(Retry)나 연결 풀(Connection Pool)을 어떻게 설정할 것인가
GDAI는 분산 DB의 기반을 제공하지만, 애플리케이션 설계도 중요합니다.
client application request는 Oracle drivers와 sharding key를 사용하여 shard로 직접 라우팅됩니다.1
이를 애플리케이션 설계 관점에서 보면 다음이 중요합니다.
- sharding key를 명확하게 설계하기
- SQL이나 API가 sharding key를 포함하는 형태로 만들기
- 연결 풀이 shard-aware한 연결을 다룰 수 있도록 하기
- 단일 shard 내에서 완결되는 처리를 늘리기
- cross-shard query가 필요한 처리를 명확히 분리하기
분산 DB에서는 데이터의 위치를 의식하지 않고 무엇이든 실행할 수 있는 것처럼 보여도, 성능 면에서는 "어떤 데이터가 어디에 있는가"가 중요합니다.
GDAI에서는 Shard Director와 Oracle drivers를 통한 라우팅이 이 부분을 뒷받침합니다.
글로벌 분산 DB에서는 DB 측의 고가용성뿐만 아니라, 애플리케이션 측의 페일오버(Failover) 설계도 중요합니다.
고려해야 할 사항은 다음과 같습니다.
- 접속 대상이 이용 불가능해졌을 때, 어느 접속 대상으로 전환할 것인가
- 연결 풀이 장애를 어떻게 감지할 것인가
- 트랜잭션(Transaction) 도중의 실패를 어떻게 처리할 것인가
- 재시도(Retry) 가능한 처리와 재시도해서는 안 되는 처리를 어떻게 나눌 것인가
- 복구 후 원래의 로케이션으로 되돌릴 것인가, 되돌리지 않을 것인가
- 페일백(Failback) 시 애플리케이션 중단이 수반되는가
GDAI의 기술 요소인 Shard Director, Data Guard, Raft 기반 복제(Replication)는 고가용성의 기반이 됩니다. 애플리케이션 측에서는 연결 라우팅, 재시도 설계, 예외 처리, 운영 절차를 함께 설계해야 합니다.
GDAI를 분산 SQL / 글로벌 분산 DB로 볼 경우, 중요한 것은 "단일 논리 DB로 보이는 것"과 "실제 데이터 배치를 의식한 설계" 사이의 균형입니다.
sharding key를 포함하는 처리는 대상 shard로 직접 라우팅하기 쉬워 성능을 내기 유리한 반면, cross-shard query나 글로벌 집계는 Shard Catalog / query coordinator의 역할을 이해한 상태에서 설계해야 합니다.
■ Oracle Multicloud / @Hyperscaler에서의 이용을 고려
GDAI를 고려할 때 Oracle Multicloud / @Hyperscaler와의 관계도 중요합니다.
Oracle은 주요 클라우드 상에서 Oracle AI Database를 이용하기 위한 서비스로서 Oracle AI Database@Azure, Oracle AI Database@Google Cloud, Oracle AI Database@AWS를 제공하고 있습니다.
Oracle AI Database@Azure에서는 Azure data centers에 colocated된 Exadata infrastructure 상에서 Oracle workloads를 실행할 수 있으며, RAC, Oracle Data Guard, Maximum Availability Architecture를 통한 엔터프라이즈급 가용성이 설명되어 있습니다.
Oracle AI Database@Google Cloud에서는 OCI의 Oracle AI Database services가 Google Cloud에서 구동되며, Google Vertex AI와 같은 Google Cloud 서비스와 Oracle AI Database를 결합한 애플리케이션 개발에 대해 설명합니다.
Oracle AI Database@AWS에서는 Oracle Exadata Database Service on Dedicated Infrastructure 또는 Oracle Autonomous AI Database on Dedicated Exadata Infrastructure를 AWS 내에서 이용할 수 있으며, Amazon SageMaker 및 Amazon Bedrock 등과의 조합에 대해 설명합니다.
이와 같이 Oracle AI Database의 이용 장소는 OCI에만 국한되지 않습니다.
GDAI를 검토할 때도 Oracle AI Database의 멀티 클라우드 (Multi-cloud) 전개와 데이터 배치, 네트워크, 레이턴시 (Latency), 데이터 레지던시 (Data Residency), 보안을 어떻게 조합할지가 중요한 검토 포인트가 됩니다.
단, 실제로 GDAI를 어떤 클라우드, 어떤 리전, 어떤 서비스 형태로 이용할 수 있는지는 대상 리전, 서비스 제공 상태, Dedicated Infrastructure / Exadata Infrastructure 전제 조건, 네트워크, IAM, 과금 모델을 확인해야 합니다.
OCI
+-- Oracle AI Database / Autonomous AI Database
+-- Exadata Infrastructure
...
여기서 중요한 점은 단순히 "다른 클라우드에 Oracle Database를 둔다"는 이야기가 아니라는 것입니다.
Oracle AI Database@Azure / @Google Cloud / @AWS는 각각의 클라우드 환경의 애플리케이션이나 AI 서비스 근처에서 Oracle AI Database를 이용하기 위한 선택지입니다.
따라서 다음과 같은 구성을 검토할 수 있습니다.
- Azure 상의 애플리케이션에서 Oracle AI Database@Azure로 저레이턴시 (Low Latency) 연결
- Google Cloud의 Vertex AI와 Oracle AI Database@Google Cloud를 결합
- AWS의 Bedrock / SageMaker와 Oracle AI Database@AWS를 결합
- Oracle Database의 데이터를 이동시키지 않고 각 클라우드의 AI 서비스와 결합
- 데이터 레지던시 (Data Residency) 요구사항에 맞춰 이용 리전이나 배치처를 선택
GDAI와 @Hyperscaler를 결합하는 경우에는 대상 리전, 서비스 제공 상태, Autonomous AI Database on Dedicated Exadata Infrastructure 등 서비스별 Exadata 기반, 네트워크, 보안, IAM, 과금 모델을 반드시 확인해야 합니다.
GDAI의 기본 구성은 다음과 같이 생각할 수 있습니다.
+----------------------+
| Application |
+----------+-----------+
...
각 샤드 (Shard)는 독립된 Oracle AI Database 인스턴스입니다. 샤드 카탈로그 (Shard Catalog)가 분산 DB 전체의 관리와 멀티 샤드 쿼리 (Multi-shard Query)를 지원하며, 샤드 디렉터 (Shard Director)가 애플리케이션 연결을 적절한 샤드로 라우팅 (Routing)합니다.
고가용성 (High Availability) 관점에서는 샤드가 Data Guard 등으로 복제됩니다. Raft 기반 복제 (Raft-based Replication) 또한 분산 DB의 고가용성과 일관성을 뒷받침하는 중요한 요소입니다.
@Hyperscaler를 포함하는 경우의 이미지는 다음과 같습니다.
Application on Azure
|
+-- Oracle AI Database@Azure
...
이 구성에서는 애플리케이션이 동작하는 클라우드 근처에 Oracle AI Database를 배치하고, 데이터 배치와 복제 (Replication)를 설계함으로써 저레이턴시, 고가용성, 데이터 주권 요구사항을 충족하기 용이해집니다.
여기서는 실제 화면 조작이 아닌, Oracle Docs의 구성에 따라 GDAI를 생성할 때의 주요 흐름을 정리합니다.

Oracle Docs의 Get Started 페이지에는 다음과 같은 항목이 준비되어 있습니다.
- Learn About the Service
- Set Up the Prerequisites
- Access the User Interface
- Define Policies
- Creation and Deployment Work Flow
- Add Shards (Scale Out)
- Remove Shards (Scale In)
- Stop and Start the Distributed Database
- Monitor the Deployment
- Manage Private Endpoints
이를 바탕으로 구축 흐름은 다음과 같습니다.
먼저, GDAI가 대상 리전(Region), 대상 클라우드, 대상 테넌시(Tenancy)에서 이용 가능한지 확인합니다.
확인 포인트는 다음과 같습니다.
- GDAI 제공 리전
- 이용 가능한 Autonomous AI Database / Dedicated Infrastructure
- Exadata VM Cluster 또는 Dedicated Infrastructure의 전제 조건
- @Hyperscaler 상에서 이용할 경우의 제공 상태
- 테넌시에서 활성화된 서비스
- 필요한 IAM 권한
다음으로 네트워크, 권한, 인프라를 준비합니다.
확인 포인트는 다음과 같습니다.
- VCN / subnet / routing
- private endpoint
- security list / network security group
- DNS
- IAM policy
- compartment
- vault / key management
- backup / recovery policy
- Exadata VM Cluster / Dedicated Infrastructure
GDAI는 분산 DB이므로 네트워크 설계가 매우 중요합니다.
동일 리전 내의 DB 생성보다 다음과 같은 관점이 늘어납니다.
- shard 간의 통신
- 애플리케이션에서 Shard Director로의 접속
- 관리 평면(Management Plane)으로의 액세스
- private endpoint 이용
- @Hyperscaler와 OCI의 경계
- 모니터링 및 로그 취득
Oracle Docs에서는 Define Policies가 Get Started의 중요한 단계로 준비되어 있습니다.
GDAI에서는 데이터베이스 생성뿐만 아니라, 분산 구성 관리, shard의 추가·삭제, 모니터링 등이 필요합니다.
따라서 최소 권한 원칙(Principle of Least Privilege)에 기반하여 다음을 정리합니다.
- 누가 GDAI를 생성할 수 있는가
- 누가 shard를 추가·삭제할 수 있는가
- 누가 네트워크 설정을 변경할 수 있는가
- 누가 모니터링할 수 있는가
- 누가 백업·복구(Backup/Recovery) 작업을 할 수 있는가
- 누가 보안 설정을 변경할 수 있는가
Oracle Docs에는 Creation and Deployment Work Flow가 준비되어 있습니다.
실제 화면 조작은 환경에 따라 다르므로, 여기서는 주요 확인 항목으로서 정리합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기