NVIDIA가 Hugging Face에 4D-RGPT를 출시했습니다
요약
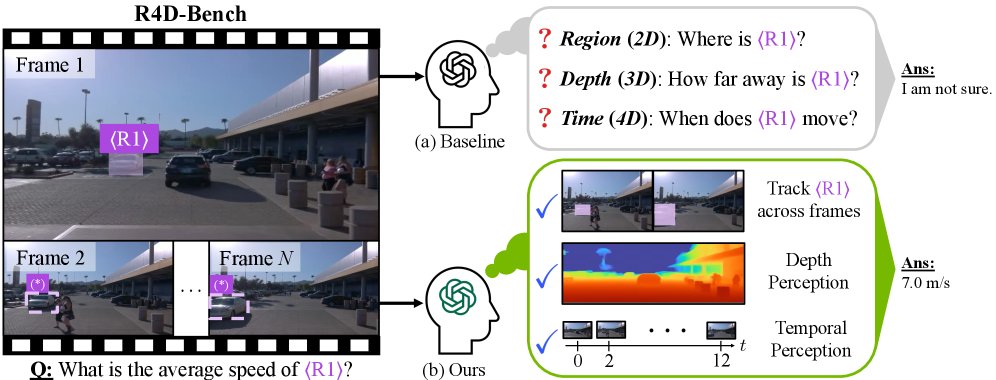
NVIDIA가 CVPR 2026 Highlight 모델인 4D-RGPT를 Hugging Face에 출시했습니다. 이 모델은 추가 추론 비용 없이 학습 단계에서 깊이와 움직임을 학습하여 영역 수준의 4D 비디오 이해를 지원합니다. 또한 ByteDance는 음향적 일관성을 유지하며 다수 화자의 대화를 합성하는 SwanVoice를 공개했습니다.
핵심 포인트
- NVIDIA 4D-RGPT: 추가 비용 없는 4D 비디오 이해 모델
- 학습 단계에서 깊이(depth)와 움직임(motion) 학습
- ByteDance SwanVoice: 다수 화자 간의 일관된 대화 합성
- SwanVoice는 flow-matching DiT 기술 활용
NVIDIA가 Hugging Face에 4D-RGPT를 출시했습니다.
영역 수준 (region-level)의 4D 비디오 이해 (4D video understanding)를 위한 CVPR 2026 Highlight 모델입니다.
이 모델은 추론 (inference) 시 추가 비용 없이, 학습 (training) 단계에서 전문가로부터 깊이 (depth)와 움직임 (motion)을 학습합니다.
모델:
https://huggingface.co/nvidia/4D-RGPT
-8B
...
논문 페이지:
https://huggingface.co/papers/2512.17012
...
ByteDance가 SwanVoice를 출시합니다.
이 모델은 최대 4명의 화자가 참여하는 긴 형태의 독백 (monologue)과 대화 (dialogue)를 합성합니다.
모델은 대화 차례 (turns) 전반에 걸쳐 음향적 일관성 (acoustic consistency)을 유지합니다.
이 모델은 화자 차례 조건화 (speaker-turn conditioning)가 포함된 flow-matching DiT를 사용합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기