
monday Service + LangSmith: 첫날부터 구축하는 코드 우선 평가 전략
요약
Monday.com이 LangSmith를 활용하여 AI 에이전트의 품질을 개발 초기 단계부터 검증하는 '평가 주도 개발 프레임워크' 구축 사례를 소개합니다. LangGraph 기반 ReAct 에이전트의 자율성으로 인한 오류를 방지하기 위해 오프라인 평가와 실시간 모니터링을 결합한 이중 계층 접근 방식을 제안합니다.
핵심 포인트
- 평가 피드백 루프를 162초에서 18초로 약 8.7배 단축
- GitOps 스타일의 CI/CD를 통한 '코드로서의 평가(Evals as code)' 구현
- LangGraph 기반 ReAct 에이전트의 추론 연쇄 오류 방지 전략
- 오프라인 골든 데이터셋 테스트와 실시간 프로덕션 모니터링의 병행
[이 글은 Gal Ben Arieh(Group Tech Lead)가 이끄는 Monday.com의 고객용 AI 서비스 에이전트를 위한 평가 전략 수립 과정을 담은 게스트 포스트입니다. 기여해 주셔서 감사합니다!]
많은 팀이 평가를 마지막 단계의 확인 작업으로 취급하지만, 우리는 이를 Day 0 요구사항으로 만들었습니다.
monday Service는 모든 서비스 부서의 문의를 자동화하고 해결하도록 설계된 AI 네이티브 기업 서비스 관리 (ESM, Enterprise Service Management) 플랫폼입니다. 우리의 새로운 AI 서비스 인력(인간 상담원의 티켓 부담을 덜어주는 맞춤형, 역할 기반 (role-based) AI 에이전트 군단)을 구축할 때, 우리는 알파 사용자가 격차를 발견할 때까지 기다리는 대신 개발 주기 초기부터 평가를 내장했습니다.
이 글은 사용자가 문제를 발견하기 전에 AI 품질 문제를 포착할 수 있도록 우리가 어떻게 **평가 주도 개발 프레임워크 (evals-driven development framework)**를 구축했는지 보여줍니다.
우리가 달성한 성과:
속도: 평가 피드백 루프 8.7배 빨라짐 (162초에서 18초로 단축).
커버리지 (Coverage): 몇 시간이 아닌 몇 분 만에 수백 개의 예시에 대한 포괄적인 테스트 수행.
에이전트 관찰 가능성 (Agent observability): Multi-Turn Evaluators를 사용하여 프로덕션 트레이스(production traces)에 대한 실시간 엔드 투 엔드 품질 모니터링.
코드로서의 평가 (Evals as code): GitOps 스타일의 CI/CD 배포를 통해 버전 관리되는 프로덕션 코드로 평가 로직 관리.
AI 서비스 인력은 모든 기업 서비스 관리 유스케이스에서 문의를 자동화하고 해결하도록 설계된 맞춤형, LangGraph 기반의 ReAct 에이전트입니다.
**IT, HR 또는 법무 (Legal)**와 같은 분야에 적용되든, monday Service 고객은 자체 지식 베이스 (KB, Knowledge Base) 문서와 **도구 (tools)**를 활용하여 어떤 서비스 부서 내에서도 실행을 주도할 수 있도록 에이전트를 맞춤 설정할 수 있습니다.
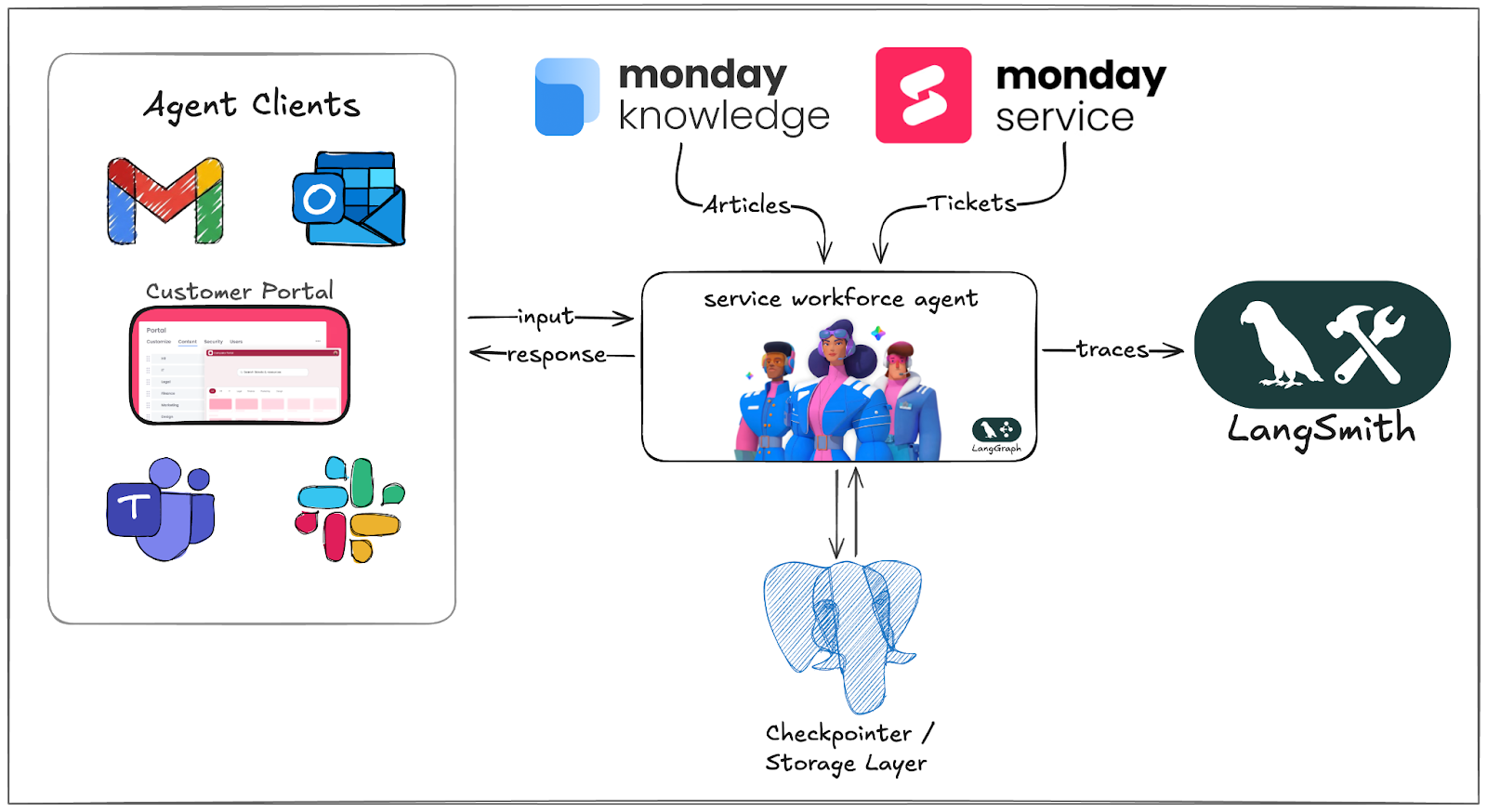
하지만 ReAct 에이전트를 매우 강력하게 만드는 바로 그 **자율성 (autonomy)**은 독특한 과제를 안겨줍니다. 추론 체인의 각 단계가 이전 단계에 의존하기 때문에, 프롬프트나 도구 호출(tool-call) 결과에서의 **미세한 편차 (minor deviation)**가 결과적으로 크게 다르거나 잠재적으로 잘못된 결과로 **연쇄 반응 (cascade)**을 일으킬 수 있기 때문입니다.
평가의 두 기둥
에이전트 평가 모범 사례에 대한 연구를 통해, 우리는 이중 계층 접근 방식 (dual-layered approach)이 필수적이라는 것을 빠르게 깨달았습니다.
오프라인 평가 (Offline Evaluations) — "안전망 (The Safety Net)": 유닛 테스트 (unit-testing) 계층과 유사하게 작동하며, 선별된 "골든 데이터셋 (golden datasets)"을 대상으로 에이전트를 실행합니다. 핵심 로직 (core logic) (예: 근거성 (groundedness), 검색 정확도 (retrieval accuracy), 도구 호출 (tool-calling))과 특정 엣지 케이스 (specific edge cases) (예: 지식 베이스 (KB) 문서 충돌 또는 우선순위 해결)를 모두 테스트합니다. 이 계층은 단순한 프롬프트 수정이 에이전트의 다른 작업 처리 능력을 의도치 않게 망가뜨리지 않도록 보장하는 데 도움을 줍니다.
온라인 평가 (Online Evaluations) — "모니터 (The Monitor)" (지속적인 품질): 이 계층은 엔드 투 엔드 (end-to-end) 비즈니스 관점에서 에이전트의 **성능 (performance)**을 지속적으로 수집, 분석 및 개선하는 작업을 처리합니다. 온라인 (online) 평가 파이프라인을 활용함으로써, 우리는 비즈니스 시그널 (business signals) (예: 자동 해결 및 봉쇄율 (Automated Resolution and Containment rates))을 추적하고 개선하며, **실시간 (real time)**으로 **실제 환경 (in the wild)**에서의 에이전트 성능을 보장합니다.
Pillar A: 오프라인 평가 (Offline Evaluations) — "안전망 (The Safety Net)"
평가 커버리지 전략 설계
단 하나의 평가를 작성하기 전에, 우리는 근본적인 질문에 답해야 했습니다: 실제로 무엇을 평가해야 하는가? 도전 과제는 완벽한 커버리지 전략을 설계하는 것이 아니라, 단순히 실용적인 시작점을 선택하는 것이었습니다.
우리는 다음과 같은 일반적인 요청 카테고리를 다루기 위해 내부 IT 헬프 데스크에서 선정된 약 30개의 실제 (익명화된) 해결된 IT 티켓으로 구성된 작은 데이터셋을 구축했습니다:
- 액세스 및 ID (Access & Identity) (예: IDP, SSO, 소프트웨어 액세스)
- VPN 및 연결 문제
- 장치 / OS 지원 (업데이트, 성능, 하드웨어 문제)
그 첫 번째 스위트 (suite)에서 우리의 점검 항목은 의도적으로 단순했습니다:
결정론적 (Deterministic) "스모크 (smoke)" 테스트:
- 런타임 상태 (Runtime health): 에이전트가 충돌이나 타임아웃 없이 실행되었으며, 요청이 엔드 투 엔드 (end-to-end)로 성공했는지 확인합니다.
- 출력 형태 (Output shape): (내용을 평가하기 전이라도) 응답이 예상된 스키마 (schema)/형식과 일치하는지 확인합니다.
- 상태 및 지속성 (State & persistence): 스레드/세션이 생성되었고 대화 내용이 애플리케이션 데이터베이스에 적절히 저장되었는지 확인합니다.
- 기본 도구 무결성 점검 (Basic Tool Sanity Check): 모든 필요한 도구들이 적절한 입력값과 함께 올바르게 호출되었으며, 오류 없이 실행을 완료했는지 확인합니다.
LLM-as-judge: 우리는 OpenEvals에서 제공하는 기성 평가기 (off-the-shelf evaluator, Correctness)를 사용하여, 에이전트의 응답을 동일한 해결된 티켓 (resolved-ticket) 데이터셋의 참조 출력 (reference output)과 비교하는 것부터 시작했습니다.
이러한 기준점 (baseline)이 마련된 후, 우리는 세션 메모리, 지식 베이스 (KB) 검색, 근거 제시 (grounding) 및 충돌 해결, 그리고 가드레일 (guardrails)을 포함한 **특정 동작 (specific behaviors)**을 조사하기 위해 더 작고 사용 사례별 (use-case-specific) 데이터셋으로 확장했습니다. 이러한 동작들이 더 미묘해짐에 따라, 우리는 **단일 정답 점수 (one correctness score)**에서 더 포괄적인 점검 세트로 이동했습니다:
KB 근거 제시 (KB grounding) / 인용 (Citations): "모든 사실적 주장이 제공된 KB 콘텐츠로 추적 가능한가?" (우리는 LangSmith의 사전 구축된 환각 (hallucination) / 답변 관련성 (answer relevance) 점검을 사용하여 이를 검증합니다).
충돌 처리 (Conflict handling): "지역/시간에 따라 정책이 다를 때, 에이전트가 명확한 설명을 요청했는가, 아니면 최신의 적용 가능한 정책을 선택했는가?" (또는 사전 구축된 정답 점검).
가드레일 (Guardrails): "필요할 때 에이전트가 거절했는가?" / "내부 도구 이름이나 프롬프트 내용을 노출하는 것을 피했는가?" (또는 사전 구축된 유해성 (toxicity) / 간결성 (conciseness) 점검).
KB 사용 타이밍 (KB usage timing): AgentEvals의 Trajectory LLM-as-judge를 사용하여, KB가 적절한 시점(너무 빠르지도, 답변이 이미 형성된 후도 아닌 시점)에 호출되는지 확인해야 합니다.
가드레일 순서 (Guardrail ordering): 안전/정책 가드레일은 적절한 단계(최종 답변을 생성하기 전)에서 실행되어야 합니다. 이는 또 다른 궤적 (trajectory) 점검입니다.
프레임워크: langsmith/vitest
이 계층을 구현하기 위해, 우리는 LangSmith Vitest 통합 기능을 활용했습니다. 이 접근 방식은 검증된 테스트 프레임워크 (Vitest)의 강력한 성능을 제공하는 동시에, **LangSmith 생태계 (ecosystem)**와 원활하게 통합된 상태를 유지합니다.
이 설정을 통해 모든 CI 실행은 LangSmith 플랫폼에서 별도의 실험으로 자동 기록되며, 각 테스트 스위트 (test suite)는 하나의 데이터셋 (dataset) 역할을 합니다. 이를 통해 우리는 특정 **실행 (runs)**을 상세히 파고들어 에이전트가 **정답 (ground truth)**에서 정확히 어느 지점에서 벗어났는지 확인할 수 있는 가시성을 확보하게 되었으며, 코드 변경 사항이 **프로덕션 (production)**에 도달하기 전에 그 영향을 쉽게 검증할 수 있게 되었습니다.
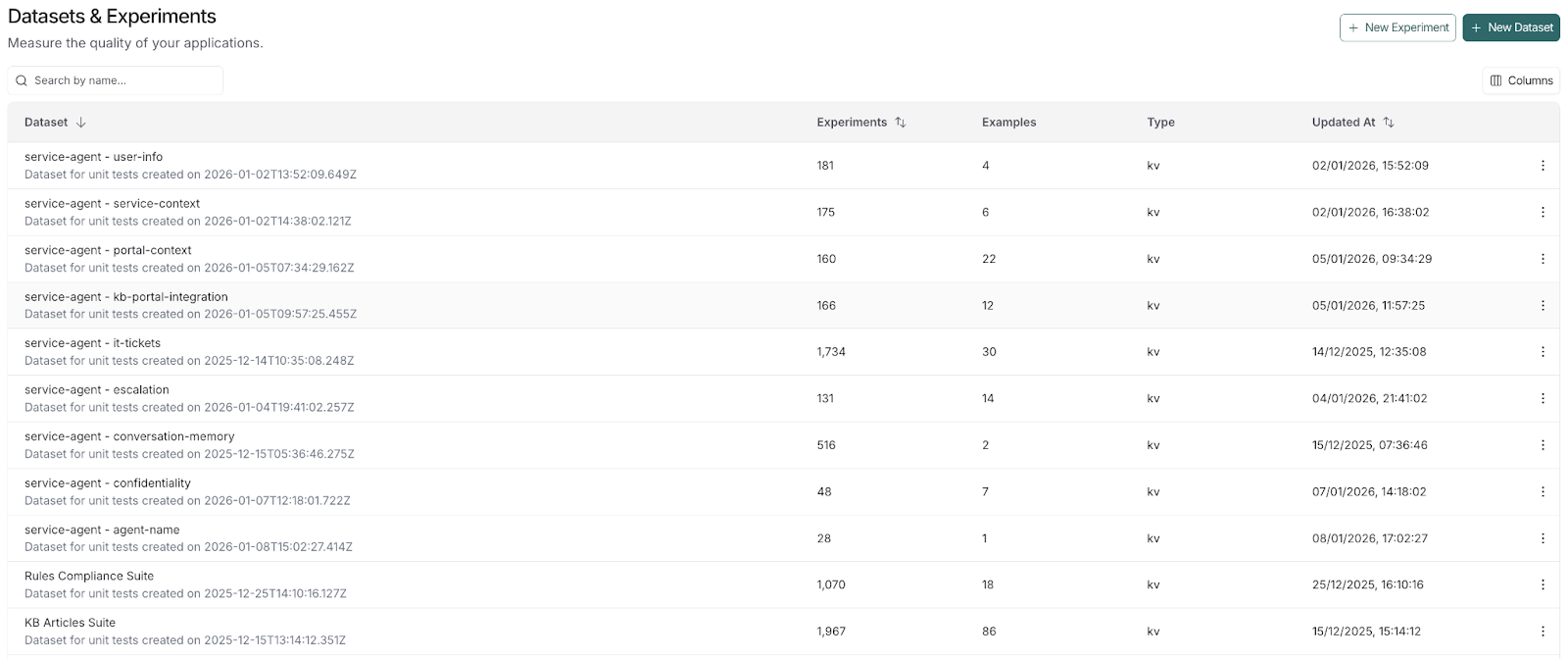
뼈아픈 교훈: 개발자 경험 (DevEx)을 타협하지 마세요
처음에 우리의 오프라인 평가는 직렬 (serially)로 실행되었습니다. 표준적인 개발 루프—평가 (실패) → 수정 → 재평가 (성공)—가 주요 병목 현상이 되었습니다.
우리는 피드백 루프가 느려지면 테스트의 깊이나 개발 속도 중 하나가 필연적으로 저하된다는 것을 발견했습니다. 회귀 (regression) 없이 높은 속도로 배포를 지속하기 위해서는, 평가 프로세스가 마찰 없는 반복 루프 (iteration loop)를 보장할 수 있을 만큼 충분히 빨라야 한다는 것을 깨달았습니다.
해결책: Vitest + ls.describe.concurrent를 통한 병렬화
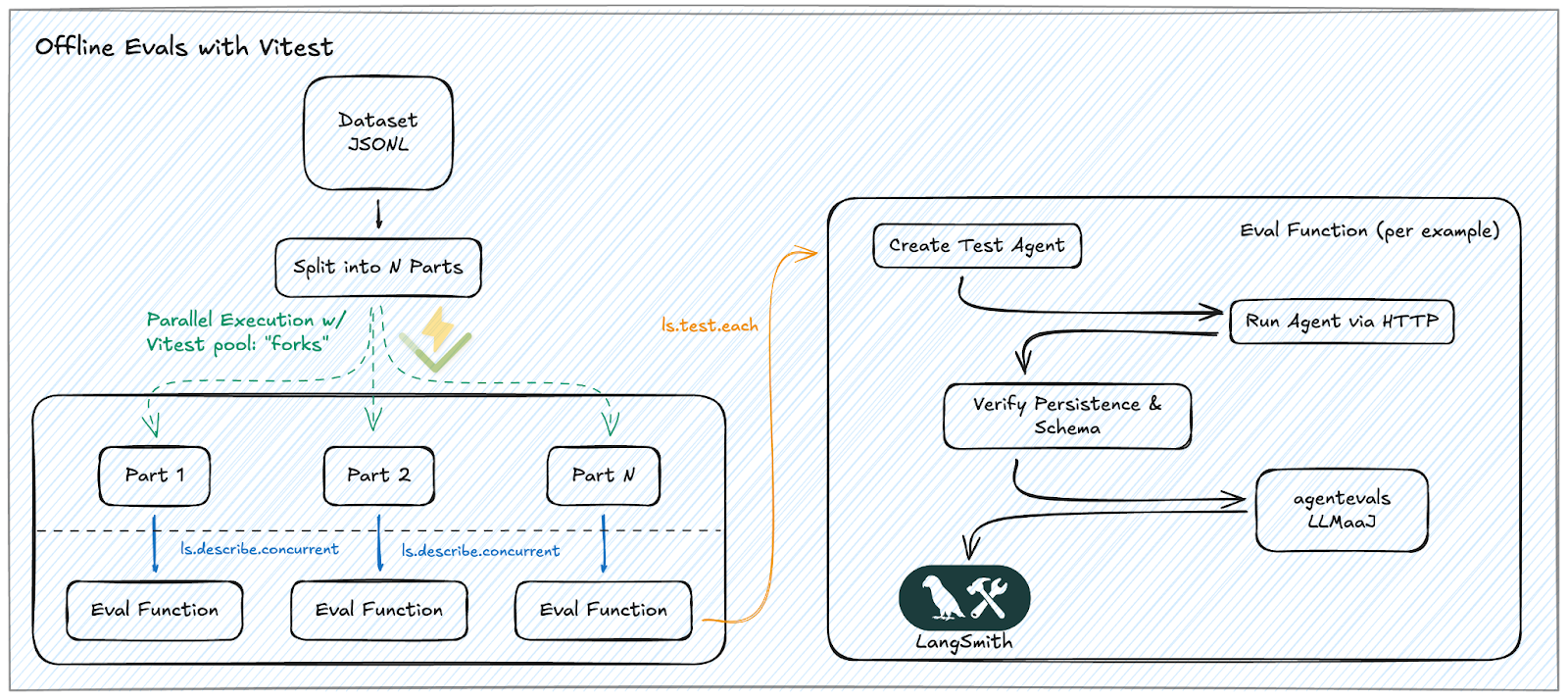
Vitest와 LangSmith 통합을 최적화함으로써, 우리는 **로컬 워커 (local workers)와 원격 API 호출 (remote API calls)**로 부하를 분산하여 엄청난 속도 향상을 달성했습니다. 핵심은 하이브리드 접근 방식이었습니다. 즉, CPU 사용량을 극대화하기 위해 **테스트 파일들을 병렬화 (parallelizing)**하고, I/O 바운드 (I/O-bound) 지연 시간을 처리하기 위해 **LLM 평가를 동시 실행 (running LLM evaluations concurrently)**하는 것이었습니다.
병렬성 (CPU 바운드): Vitest의 풀(pool) 기능인 ‘forks’를 활용하여 워크로드를 여러 코어에 분산시킵니다. 각 Dataset Shard를 별도의 테스트 파일에 할당함으로써, 여러 워커 프로세스가 CPU 경쟁 없이 병렬로 실행되도록 합니다. 이러한 설정은 데이터셋이 성장하더라도 사용 가능한 코어에 샤드(shard)를 분산시켜 빠르게 처리할 수 있도록 보장합니다.동시성 (I/O 바운드): 각 테스트 파일 내에서는 ls.describe.concurrent를 사용하여 처리량(throughput)을 극대화합니다. LLM 평가는 지연 시간(latency)이 높기 때문에, 동시성을 활용하여 수십 개의 평가를 한 번에 실행함으로써 지연 시간을 겹치게 하고, 러너가 유휴 상태로 머무는 일이 없도록 합니다.평가 함수 (The Eval Function): 이 부분은 각 예제를 평가하는 핵심 로직입니다. 이를 사용하여 단일 패스(single pass)에서 두 단계의 검증을 수행합니다:**결정론적 기준선 (Deterministic Baseline): 에이전트가 **응답 스키마(response schema)**를 준수하고 **상태 지속성(state persistence)**을 유지하는지 확인하기 위한 엄격한 단언(hard assertions)입니다.**LLM 기반 평가자 (LLM-as-a-Judge):
우리의 에이전트는 복잡한 다회차 (multi-turn) 대화를 처리하기 때문에, 성공 여부는 종종 단일 응답이 아니라 전체 대화 (entire conversation) 궤적에 의해 정의됩니다. 이를 위해서는 에이전트가 **여러 차례의 턴 (several turns)**에 걸쳐 사용자를 해결책으로 어떻게 안내하는지를 고려하는 평가 전략이 필요합니다.
우리는 LangSmith의 Multi-Turn Evaluator에서 완벽한 해결책을 찾았습니다. 이는 **LLM-as-a-judge (LLM 기반 평가자)**를 활용하여 엔드 투 엔드 (end-to-end) 스레드에 점수를 매깁니다. 개별 실행을 고립시켜 평가하는 대신, 이제 커스텀 프롬프트를 사용하여 전체 대화 궤적을 채점함으로써 **사용자 만족도, 어조, 목표 해결 (user satisfaction, tone, and goal resolution)**과 같은 상위 수준의 결과를 측정할 수 있습니다.
가장 인상적인 점은 얼마나 빠르게 실제 서비스에 적용할 수 있었느냐 하는 것입니다. LangSmith 플랫폼은 다회차 설정을 **믿을 수 없을 정도로 직관적 (incredibly intuitive)**으로 만들어 줍니다. 우리는 **커스텀 비활성 창 (custom inactivity window)**을 정의하여 세션이 언제 "완료 (complete)"되어 평가 준비가 되었는지 정확히 짚어낼 수 있었고, 데이터 볼륨과 LLM 비용 사이의 균형을 맞추기 위해 **샘플링 비율 (sampling rate)**을 쉽게 적용할 수 있었습니다.
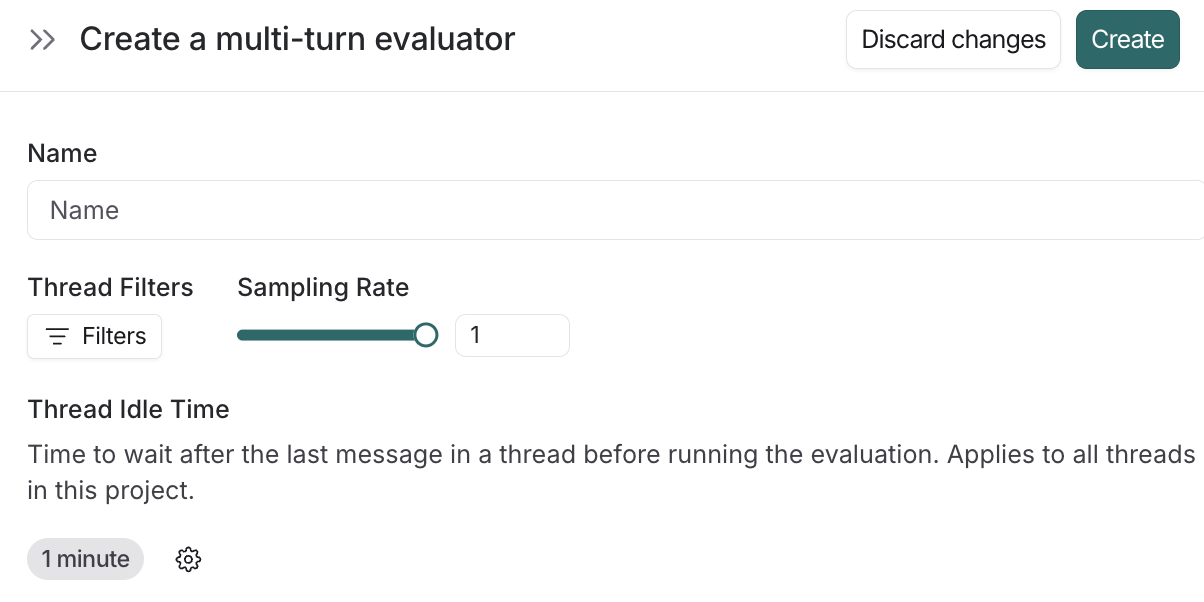
코드로서의 평가 (Evaluations as Code, EaC)
프로토타입에서 프로덕션 단계로 넘어가면서, 우리는 다른 프로덕션 코드에 적용하는 것과 동일한 표준, 즉 **버전 관리 (version control), 피어 리뷰 (peer reviews), 그리고 자동화된 CI/CD 파이프라인 (automated CI/CD pipelines)**을 통해 우리의 "판사 (judges)"를 관리하고 싶었습니다.
이를 달성하기 위해, 우리는 신뢰할 수 있는 단일 원천 (source of truth)을 리포지토리로 옮겼으며, 우리의 "판사"를 구조화된 TypeScript 객체로 정의했습니다.
// conversation-analysis.ts
export const conversationAnalysis = new MultiSignalEvaluationPrompt({
name: 'conversation-analysis',
variables: ['all_messages'],
modelConfig: { model: 'gpt-5.2-pro', reasoning: { effort: 'high' } },
extractionFields: [
new ExtractionField({ key: 'human_handoff', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'meaningful_interaction', type: 'boolean', includeComment: true }),
new ExtractionField({ key: 'is_automated_resolution', type: 'boolean', includeComment: true }),
// ... 추가적인 원자적 신호 (additional atomic signals)
],
systemPrompt: 당신은 전문적인 대화 분석가입니다...,
humanPrompt: `다음 대화를 분석하세요:
<conversation>{{{all_messages}}}
</conversation>`,
});
판단자(judges)를 코드로 이동시킨 것은 두 가지 핵심적인 역량을 확보해주었습니다:
- Cursor 및 Claude Code와 같은 AI IDE (통합 개발 환경)를 활용하여 기본 작업 공간 내에서 직접 복잡한 프롬프트(prompts)를 개선할 수 있게 되었습니다.
- 판단자가 실제 운영 트래픽(production traffic)에 투입되기 전, 정확성을 보장하기 위해 오프라인 평가(offline evaluations)를 작성하는 것이 자연스러운 흐름이 되었습니다.
LangChain의 IDE 통합 기능 덕분에 마이그레이션은 비교적 쉬웠습니다. 우리는 Documentation MCP를 사용하여 라이브러리 컨텍스트(context)를 에디터로 가져왔고, LangSmith MCP를 사용하여 실행(runs) 및 피드백을 직접 가져왔습니다. LangChain Chat 또한 특정 구현 세부 사항을 명확히 하는 데 유용한 참고 자료가 되었습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기