
MAI-Thinking-1 소개
요약
Microsoft AI가 발표한 중간 규모의 추론 모델 MAI-Thinking-1을 소개합니다. 이 모델은 지식 증류 없이 깨끗한 상업용 데이터로 바닥부터 학습되었으며, 수학적 추론과 소프트웨어 엔지니어링 분야에서 뛰어난 성능을 입증했습니다.
핵심 포인트
- 지식 증류 없이 순수 데이터로 학습된 MoE 모델
- SWE-Bench 및 수학적 추론에서 선도적 모델과 대등한 성능
- 지속적 역량 향상을 위한 Hill-Climbing Machine 파이프라인 도입
- 데이터 품질과 전체 스택의 자급자족을 강조하는 설계 철학
MAI-Thinking-1 소개
오늘 우리는 Microsoft AI의 추론 모델(reasoning model)인 MAI-Thinking-1을 소개합니다. 이 모델은 해당 파라미터 규모(weight class) 내에서 가장 강력한 모델 중 하나로 꼽히는 중간 규모(medium-sized) 모델입니다. 주요 소프트웨어 엔지니어링 벤치마크(benchmarks)에서 선도적인 모델들과 대등한 성능을 보이며, 고급 수학적 추론(mathematical reasoning) 능력을 입증하였고, 당사의 블라인드 인간 사이드 바이 사이드(blind human side-by-side) 평가에서는 Sonnet 4.6보다 선호되었습니다. 우리는 제3자 모델로부터의 지식 증류(distillation) 없이, 기업급(enterprise grade)의 깨끗하고 상업적 라이선스가 확보된 데이터를 사용하여 바닥부터(from the ground up) 이 모델을 학습시켰습니다.
MAI-Thinking-1은 인간 중심의 초지능(Humanist Superintelligence)을 구축하기 위한 우리의 광범위한 작업의 일환입니다. 여기서 초지능이란 사람과 조직을 대체하는 것이 아니라, 그들을 돕기 위해 설계된 고급 AI 역량을 의미합니다. 이 모델은 무엇을 할 수 있는지와 어떻게 구축되었는지라는 두 가지 축 모두에서 중요합니다.
Hill-Climbing Machine
단일 모델을 넘어, 우리는 우리의 Hill-Climbing Machine을 소개하게 되어 기쁩니다. 이는 모델 개발의 모든 구성 요소를 '클라이밍(climbable, 향상 가능)'하게 만들어, 시간이 지남에 따라 역량이 지속적이고 신뢰할 수 있게 향상되도록 설계된 공동 설계 파이프라인(co-designed pipeline)입니다. 목표는 더 나은 데이터, 더 강력한 보상(rewards), 더 유능한 환경, 그리고 더 많은 컴퓨팅 자원(compute)을 흡수할 수 있는 반복 가능한 시스템을 만드는 것입니다.
세 가지 주요 원칙이 우리의 철학을 안내합니다.
첫째, 역량은 상속되는 것이 아니라 학습되어야 합니다. 상속된 지능은 습득 속도는 빠를지 모르나, 실제 환경에서의 사용에 필수적인 조종 가능성(steerability)이 부족합니다. 모방자는 근본적으로 스승(teacher)의 설계 선택에 묶여 있으며 새로운 상황에 적응하는 데 어려움을 겪습니다. MAI-Thinking-1은 제3자 모델로부터의 지식 증류(distillation) 없이 학습되어, 모델이 당면한 과제를 진정으로 학습하도록 강제했습니다.
둘째, 깨끗한 데이터입니다. MAI-Thinking-1은 사전 학습(pre-training) 단계에서 AI 생성 콘텐츠를 제외하고, 깨끗하고 적절하게 라이선스가 확보된 데이터로 학습되었습니다. 이는 품질, 출처(provenance), 그리고 제어 측면에서 중요합니다. 모델을 형성한 요소를 설명할 수 없다면, 모델의 행동을 완전히 이해하거나 신뢰할 수 있게 개선할 수 없기 때문입니다.
셋째, 전체 스택에 걸친 자급자족 (self-sufficiency). MSFT 자체 가속기(accelerators)와의 모델 공동 설계(co-design)부터 강화학습 (RL) 프레임워크에 이르기까지, 우리는 자체 훈련 인프라에 노력을 집중해 왔습니다. 이는 우리의 힐클라이밍 머신 (hill-climbing machine)을 구축하는 데 있어 매우 중요한 부분이며, 우리의 요구 사항을 가장 잘 충족할 수 있도록 시스템을 엔드 투 엔드 (end-to-end)로 완전히 최적화하고 형성할 수 있도록 보장합니다.
강력한 소프트웨어 엔지니어링 성능을 갖춘 중간 크기 모델
MAI-Thinking-1은 35B-active, ~1T-total 파라미터를 가진 희소 전문가 혼합 (sparse Mixture of Experts, MoE) 모델로, 훨씬 더 큰 모델들보다 추론 발자국 (inference footprint)이 작습니다. 그럼에도 불구하고, 우리 모델은 SWE-Bench Pro에서 Claude Opus 4.6과 대등한 성능을 보여줍니다. 이는 개발자와 기업에게 중요한데, 모델의 크기가 고급 코딩 지원이 어디에 배포될 수 있는지, 얼마나 자주 사용될 수 있는지, 그리고 예외적인 작업에서 일상적인 워크플로 (workflows)로 이동할 수 있는지 여부를 결정하기 때문입니다.
우리는 에이전트 기반 코딩 (agentic coding)에 필요한 훈련 환경에 집중적으로 투자했습니다. 검증된 각 환경은 결정론적 (deterministic)이며 실행 가능하고, 실제 테스트 스위트 (test suites)에 의해 채점됩니다. 이를 통해 모델은 개발자들이 실제로 수행하는 유형의 다단계 작업, 즉 코드 읽기, 파일 편집, 테스트 실행, 실패 관찰 및 중간 단계의 실수로부터 복구하는 작업을 연습할 수 있습니다.
고급 수학적 추론 능력
MAI-Thinking-1은 AIME 2025에서 97.0%, AIME 2026에서 94.5%를 달성하며, 해당 체급에서 강력한 수학적 및 과학적 추론 능력을 보여주었습니다. 이 분야에서의 강력한 성능은 우리의 훈련 루프 (training loop)가 자체 데이터, 보상 (rewards) 및 평가 프로세스로부터 바닥부터 끝까지 실제 추론 이득을 창출할 수 있다는 확신을 주며, 이러한 지능이 시간이 지남에 따라 다른 도메인으로 일반화될 수 있도록 합니다.
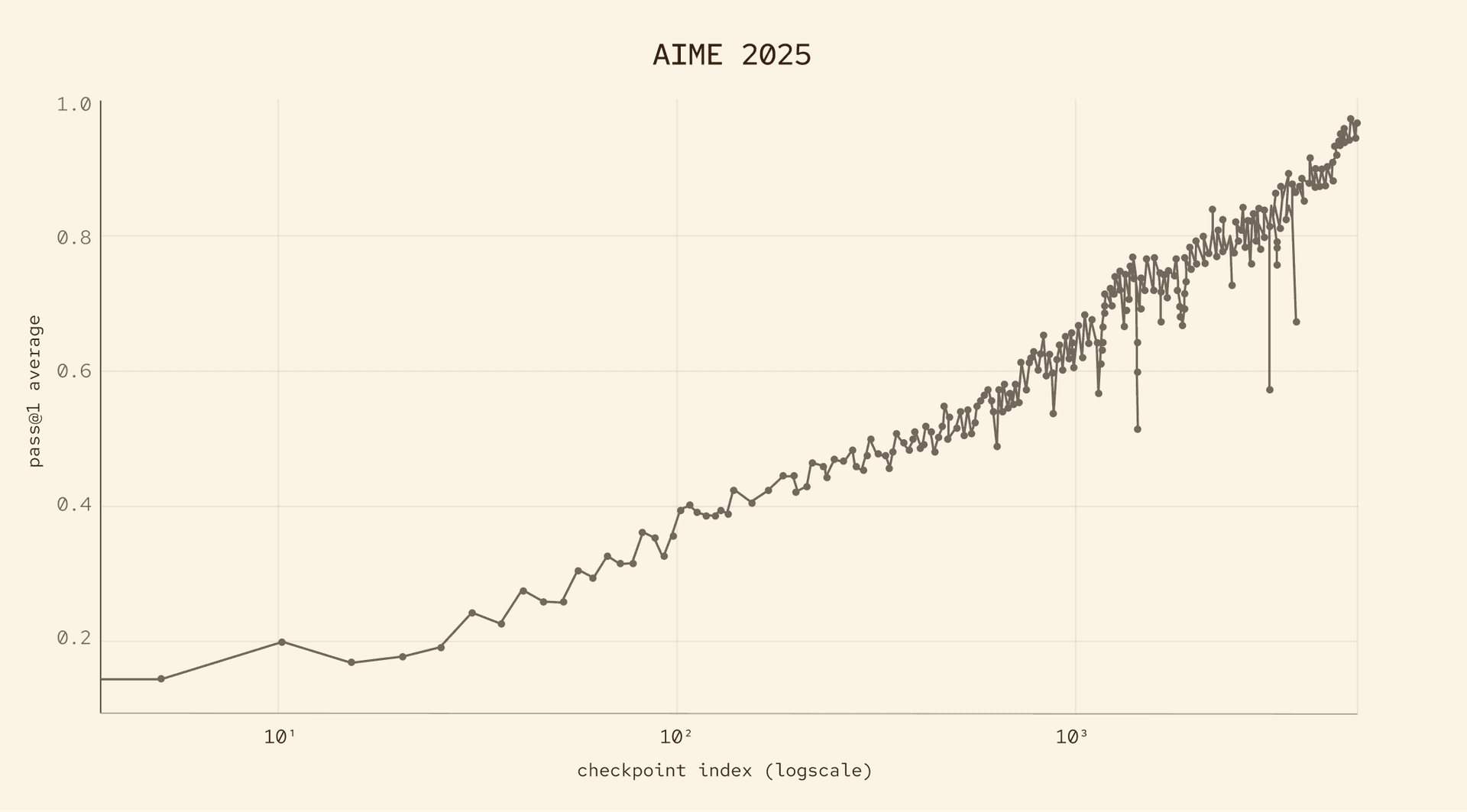
Sonnet 4.6 대비 인간 사이드 바이 사이드 (human side-by-sides) 선호
사람들은 모델이 작업을 이해하는지, 지침을 따르는지, 적절한 수준의 세부 사항을 사용하는지, 명확하게 작성하는지, 그리고 그들의 시간을 존중하는지에 관심을 가집니다.
우리는 파트너사 중 하나인 Surge와 함께 전문 평가사 풀을 활용하여, 이러한 특성들을 기준으로 다양한 모델을 측정하는 블라인드 사이드 바이 사이드 (blind side by side) 인간 평가를 구축했습니다. 이는 단일 턴 (single-turn) 및 멀티 턴 (multi-turn) 대화 모두에서 다양한 작업에 걸친 모델의 능력을 테스트하도록 설계된 1,276개의 평가로 구성되었으며, 사용자 응답이 얼마나 도움이 되는지, 그리고 실제로 사용자의 목표를 진전시키는지 측정하는 데 중점을 두었습니다. 이러한 평가에서 사용자들은 Claude Sonnet 4.6보다 MAI-Thinking-1을 선호했습니다.
이는 사후 학습 (post-training)의 핵심 초점이었습니다. 우리는 모델이 취약하지 않으면서도 유능하고, 불완전하지 않으면서도 간결하며, 과도하지 않으면서도 도움이 되기를 원합니다. 인간 선호도 데이터 (human preference data)는 벤치마크의 개선이 사용자에게 더 나은 경험으로 이어지는지에 대한 직접적인 신호를 제공합니다.
엔터프라이즈 준비 완료 (Enterprise ready)
MAI-Thinking-1은 엔터프라이즈 준비성을 염두에 두고 구축되었습니다. 이 모델은 256k 토큰 윈도우 (600페이지 분량의 문서를 담기에 충분한 크기)를 통한 긴 컨텍스트 (long context) 지원, 함수 호출 (function calling), 그리고 개발자 지침 (developer instructions)을 추가할 수 있는 유연성을 지원합니다. 우리는 모델이 다층적인 지침을 따르도록 학습시켰으며, 기본 스타일을 엔터프라이즈 요구 사항에 맞게 정렬했습니다. 또한 널리 사용되는 Chat Completions API와 호환됩니다. 모든 MAI 모델은 Microsoft Foundry를 통해 엔터프라이즈급 보안 및 규정 준수 (compliance)를 제공합니다.
결과 (Results)
우리는 두 가지 관점에서 결과를 보고합니다: 사후 학습된 (post-trained) MAI-Thinking-1 평가, 그리고 베이스 모델 (base model)의 사전 학습 (pre-training) 지표입니다.
표 1. MAI-Thinking-1 지표
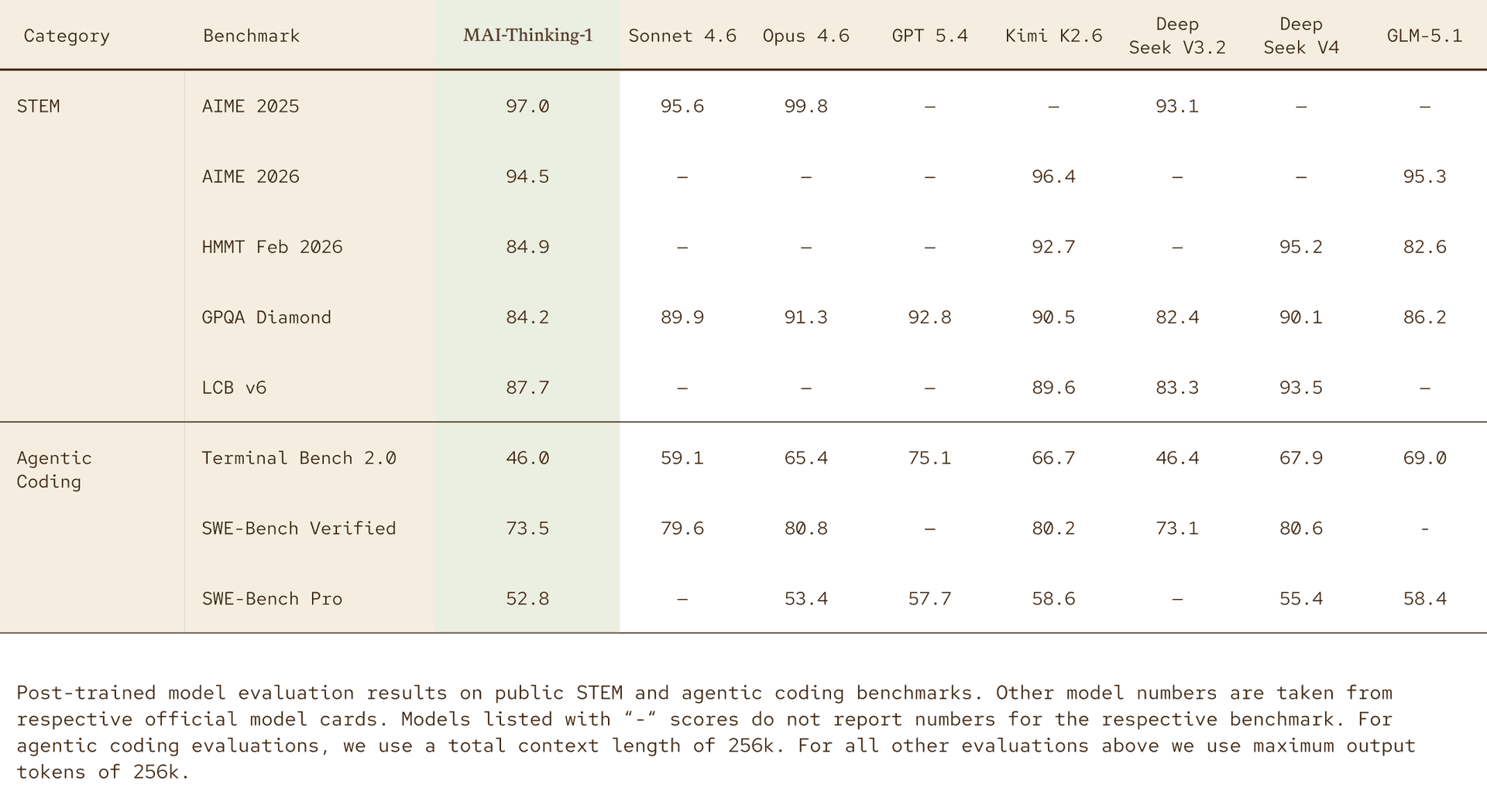
공개된 STEM 및 에이전틱 코딩 (agentic coding) 벤치마크에 대한 사후 학습 모델 평가 결과입니다. 다른 모델의 수치는 각 공식 모델 카드 (model cards)에서 가져왔습니다. 별도의 언급이 없는 한 점수는 백분율이며, 대시(-)는 사용 불가능한 모델 값을 나타냅니다.
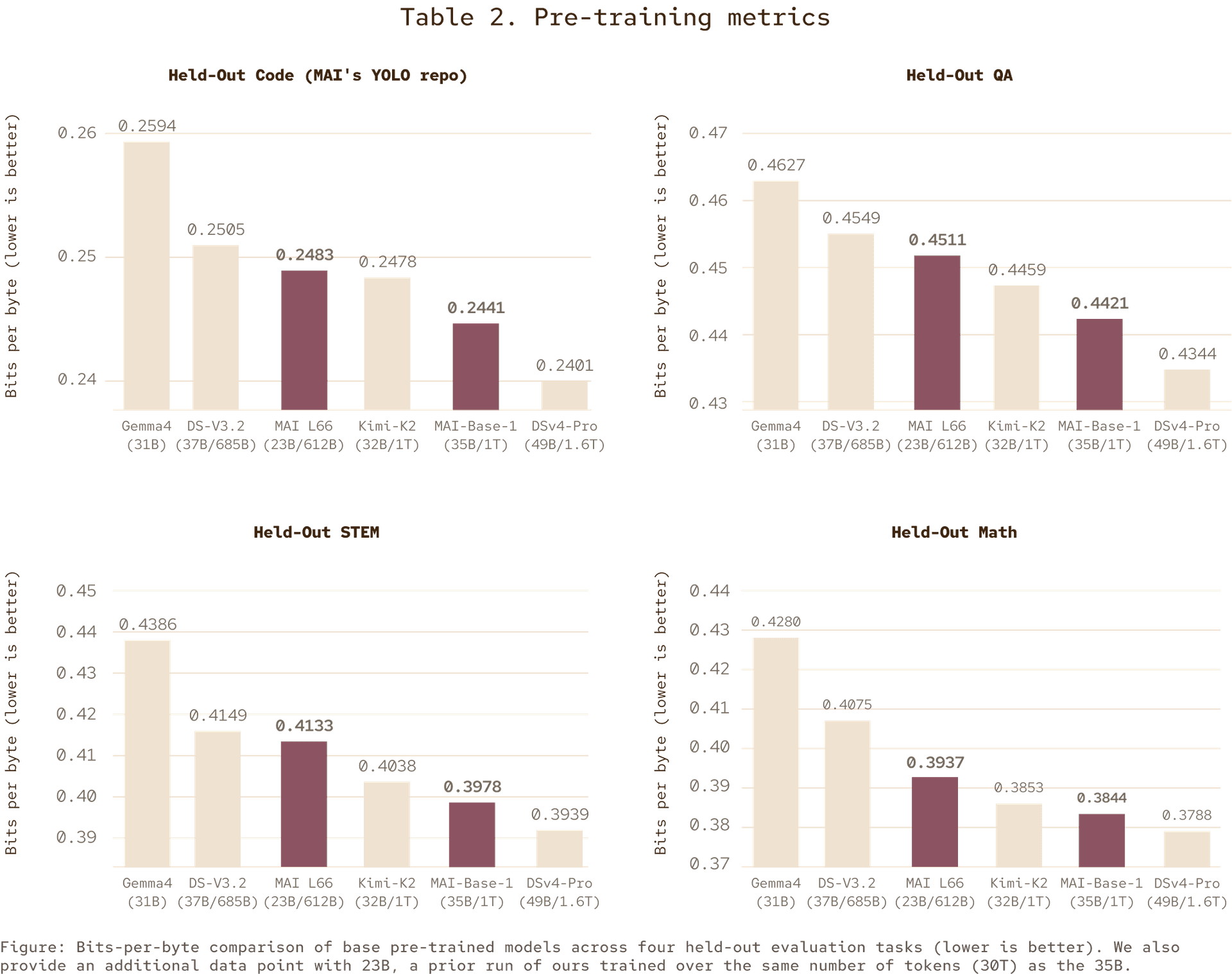
표 2. 사전 학습 지표
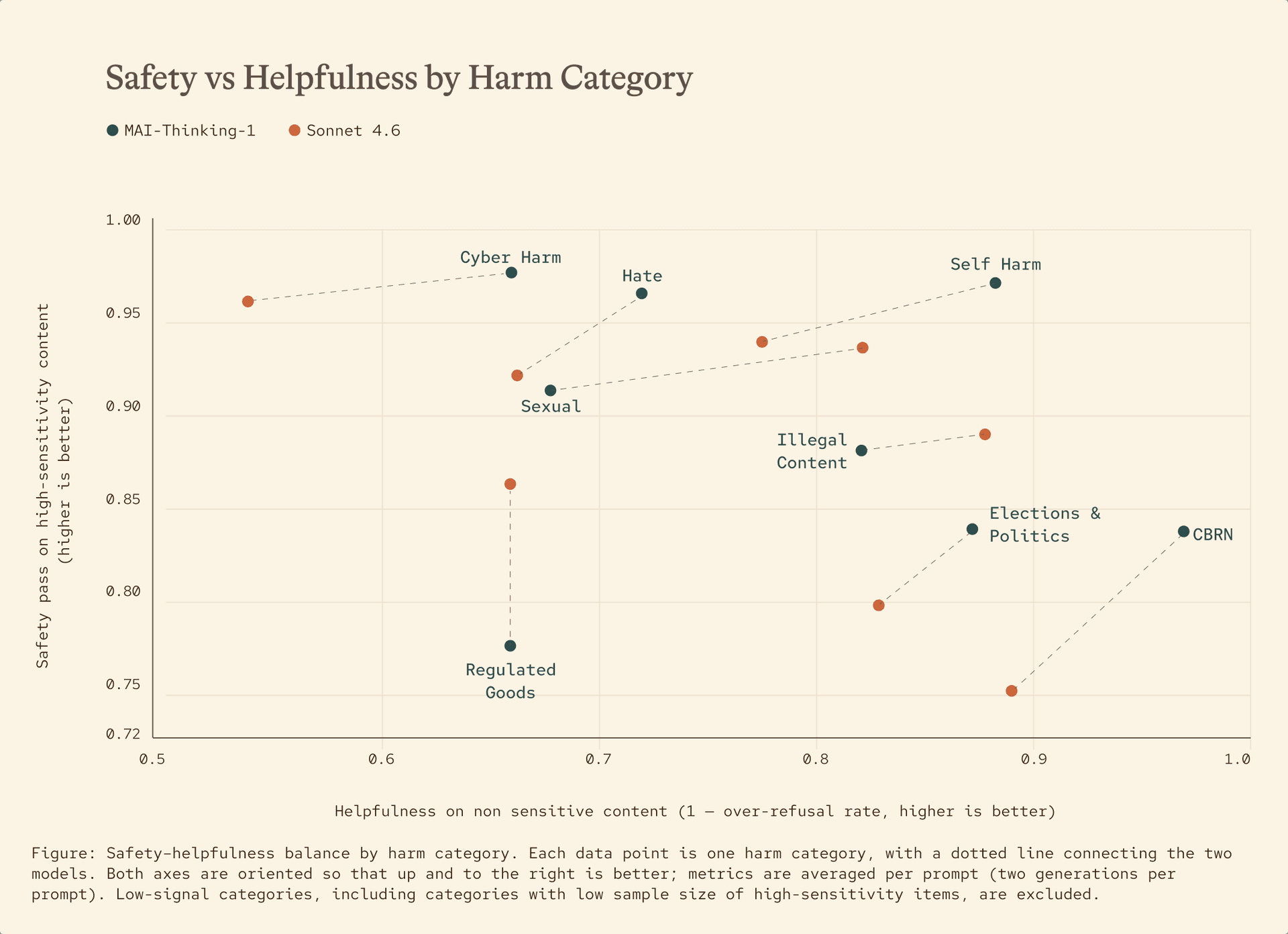
인간을 최우선으로 (Putting humans first)
우리는 인본주의적 초지능 (Humanist Superintelligence)을 향해 나아가고 있습니다. 이는 사람을 대체하는 것이 아니라, 사람과 조직을 돕기 위해 설계된 고도의 AI 역량을 의미합니다. 우리의 모델은 인간의 자율성을 유지하고 도움이 되는 것을 목표로 하며, 인간의 통제하에 있는 종속적인 기술로 남아 있어야 합니다. 즉, 우리의 모델이 안전과 준수 (compliance)를 구실로 정당한 요청을 거부해서는 안 된다는 것을 의미합니다. 그렇게 된다면 모델은 진정으로 인간에게 봉사하는 것이 아니기 때문입니다.
도움이 되는 것과 안전한 것 사이의 미묘한 균형을 맞추는 것은 쉽지 않습니다. MAI-Thinking-1의 경우, 우리는 잠재적 위해의 심각성에 따라 집계되는 동일한 보상 구성 (reward construction) 내에서, 안전하지 않은 준수와 불필요한 거부를 결함으로 취급함으로써 이 균형을 달성하고자 했습니다. 안전은 역량 (capability)을 위해 사용되는 것과 동일한 강화학습 (RL) 인프라를 통해 학습되므로, 안전 보상은 동일한 힐 클라이밍 (hill-climbing) 루프의 일부가 됩니다. 이를 통해 안전이 역량과 항상 정렬되도록 하며, 부수적인 요소가 되지 않도록 보장합니다.
그 결과, 우리의 모델이 민감하고 안전하지 않은 요청에 대해서는 안전 기준을 보장하는 동시에, 민감하지 않은 콘텐츠에 대해서는 유용함을 유지하며 균형을 잡을 수 있음을 확인했습니다.
우리와 함께 미래를 만드세요
우리는 세계에서 가장 재능 있는 인재들로 구성된 작고 빠르게 움직이는 연구소입니다. MAI는 빠르게 그리고 광범위하게 확장 중인 흥미로운 컴퓨팅 로드맵을 보유하고 있습니다. 또한 우리는 진심으로 믿는 야심 찬 미션을 가지고 있습니다. 우리는 또한 우리의 모델이 수십억 명의 사용자에게 도달하고 엄청난 긍정적 영향을 미칠 수 있는 기회를 제공하는 놀라운 제품 팀들과 파트너십을 맺는 행운을 누리고 있습니다. 만약 당신이 명석하고, 매우 야심 차며, 자아(ego)가 낮은 개인이라면 우리와 완벽하게 어울릴 것입니다. 우리의 차세대 모델을 함께 만들어 나갈 동료로 합류하세요!
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기