
Lyft가 LangGraph와 LangSmith를 사용하여 셀프 서비스 AI 에이전트 플랫폼을 구축한 방법
요약
Lyft는 LangGraph와 LangSmith를 활용하여 비기술적 도메인 전문가가 직접 AI 에이전트를 구축할 수 있는 셀프 서비스 플랫폼을 개발했습니다. 이를 통해 에이전트 개발 기간을 6개월에서 수 주 단위로 단축하고 멀티 에이전트 아키텍처로 복잡한 고객 지원 워크플로우를 자동화했습니다.
핵심 포인트
- LangGraph 기반의 라우터형 멀티 에이전트 아키텍처 구축
- 비기술적 전문가를 위한 셀프 서비스 에이전트 개발 환경 제공
- LangSmith를 통한 트레이싱, 모니터링 및 LLM-as-a-judge 평가
- 에이전트 개발 사이클을 6개월에서 수 주 단위로 대폭 단축
핵심 요약 (Key Takeaways)
Lyft는 에이전트 개발을 고객 문제를 가장 잘 이해하는 사람들에게 더 가까이 가져갔습니다. 운영 팀, VoC(Voice of Customer) 리드, 제품 관리자가 프롬프트와 설정을 통해 에이전트를 정의할 수 있게 함으로써, Lyft는 모든 반복 작업을 MLE(Machine Learning Engineer)가 관리해야 하는 필요성을 줄였습니다.
라우터 기반의 멀티 에이전트 (multi-agent) 아키텍처가 복잡한 고객 워크플로우를 지원하는 데 도움이 되었습니다. Lyft는 LangGraph를 사용하여 승객 및 운전자의 요청을 전문화된 서브 에이전트 (subagents)로 라우팅하며, 이 흐름에는 안전 점검, 상태 관리 (state management), 핸드오프 (handoffs)가 내장되어 있습니다.
프로덕션 품질은 평가, 모니터링 및 프롬프트 규율에 달려 있습니다. Lyft는 트레이싱 (tracing), 대시보드, LLM-as-a-judge 평가를 위해 LangSmith를 사용하지만, 팀은 구조화된 프롬프트 작성이 에이전트 신뢰성의 가장 큰 요인 중 하나가 되었다는 것을 발견했습니다.
이 글은 Lyft의 친구들이 작성한 게스트 포스트로, SCX 데이터 과학 및 MLE 팀이 비기술적 도메인 전문가가 AI 에이전트를 배포할 수 있는 멀티 에이전트 고객 지원 시스템을 구축한 사례를 다룹니다. 머신러닝 엔지니어(Machine Learning Engineer)인 Akshay Sharma가 이끌었습니다. 기여해 주셔서 감사합니다.
요약 (TL;DR)
LangGraph를 활용하여 정교한 멀티 에이전트 시스템을 오케스트레이션함으로써, Lyft는 승객과 운전자를 위한 수백만 건의 상호작용을 관리하며 고객 지원 운영을 혁신했습니다. 우리의 "셀프 서비스" 플랫폼은 LangGraph의 서브그래프 (subgraph) 아키텍처를 LangSmith의 강력한 트레이싱 및 모니터링 도구와 통합하여, 비기술적 도메인 전문가가 독립적으로 AI 에이전트를 개발하고 개선할 수 있도록 지원합니다. 이러한 변화를 통해 에이전트 개발 기간을 약 6개월에서 단 몇 주로 단축했으며, 동시에 자동화된 LLM-as-a-judge 평가 시스템을 통해 높은 표준을 유지하고 있습니다.
Lyft의 목표: 안전하게 에이전트 반복 속도 높이기
계정 접속, 파손 청구, 요금 검토, 수익 분쟁을 포함한 수많은 카테고리에 걸쳐, Lyft의 AI Assist는 승객과 운전자를 위한 고객 지원을 관리합니다. 우리의 여정은 2023년에 시작되었지만, 그 과정은 노동 집약적이었습니다. 각 AI 에이전트(AI agent)를 개발하는 데 머신러닝 엔지니어(Machine Learning Engineers, MLEs)와 엔지니어링 팀의 수개월에 걸친 전담 작업이 필요했습니다. 비록 점점 더 높은 효율성으로 승객과 운전자를 위한 에이전트를 성공적으로 출시해 왔지만, 전반적인 속도는 여전히 상당한 병목 현상(bottleneck)으로 남아 있었습니다.
2026년까지, 우리의 기존 운영 모델은 새로운 사용자 세그먼트, 추가적인 이슈 유형, 자율 주행 차량 지원 등에 따른 지속 불가능한 수요 급증에 직면했습니다. 개발 사이클은 느린 반복 루프(iterative loop)에 의존했습니다. 도메인 전문가가 워크플로(workflow) 동작을 정의하면, MLE가 이를 도구 구성(tool configurations)과 프롬프트(prompts)로 변환하는 방식이었습니다. 트레이스(traces)를 검토하고, 문제를 식별하며, 코드를 조정하는 이러한 반복적인 과정은 에이전트 하나당 매번 몇 주간의 협업을 필요로 했습니다. 결과적으로, 고객 이슈를 가장 깊이 이해하고 있는 사람들도 기술적인 중간 매개자 없이는 솔루션을 구현할 수 없었습니다.
이는 우리에게 중대한 질문을 던졌습니다: 운영 팀(ops teams), 고객의 소리(VoC) 리드, 그리고 제품 관리자(product managers)가 자연어(natural language)를 사용하여 직접 에이전트를 구축하고 개선할 수 있도록 권한을 부여할 수 있을까? 우리의 목표는 학습과 배포를 가속화하기 위해 일상적인 반복 프로세스에서 기술적 중간 매개자를 제거하는 것이었습니다. 결정적으로, 이러한 셀프 서비스(self-service)로의 전환은 경험, 정확성 및 안전성에 대한 우리의 엄격한 표준을 타협해서는 안 되었습니다. 모든 에이전트는 여전히 우리가 수동으로 설계한 시스템의 품질과 일치해야 했습니다.
아키텍처: LangGraph를 기반으로 구축된 멀티 에이전트 시스템
라우터 멀티 에이전트 패턴 (The Router Multi-Agent Pattern)
우리의 시스템은 LangGraph의 라우터 멀티 에이전트(router multi-agent) 아키텍처를 따릅니다. 메타 에이전트(meta agent)가 상태 유지 라우터(stateful router) 역할을 합니다. 이 에이전트는 들어오는 요청을 분류하고 Command(goto=...)를 사용하여 적절한 전문 서브 에이전트(specialized subagent)로 전달합니다. 각 서브 에이전트는 완전한 LangGraph StateGraph입니다.
, 메타 에이전트(meta agent)의 서브그래프 노드(subgraph node)로 등록됩니다.
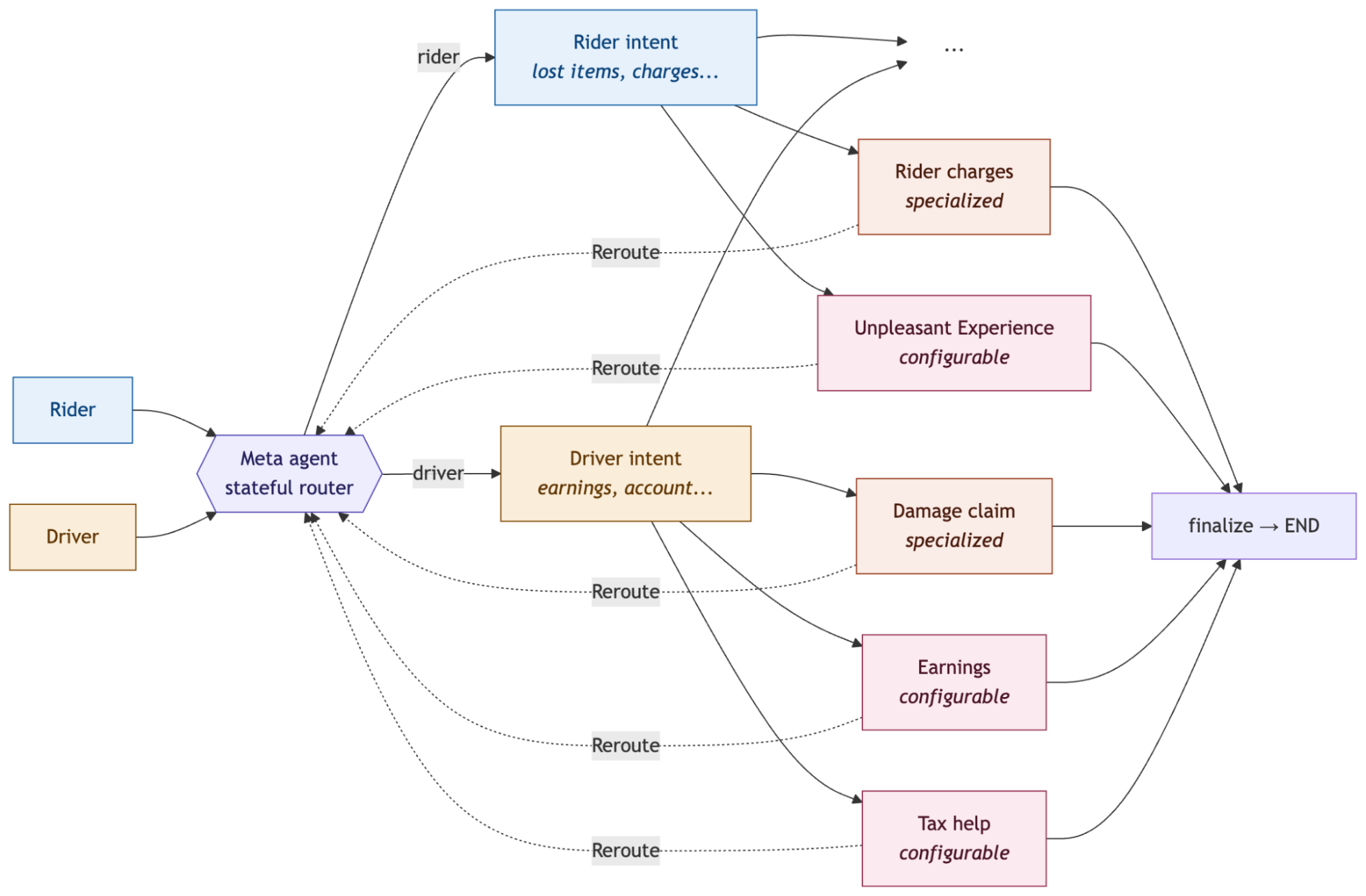
우리는 승객(rider)과 운전자(driver)를 위해 별도의 라우터(router) 인스턴스를 실행합니다. 승객이 고객 지원팀에 연락하면, 메타 에이전트는 rider_intent 서브 에이전트(subagent)로 경로를 지정하며, 이 에이전트는 승객 특화 의도(예: 분실물, 결제 분쟁, 여정 문제)에 따라 분류를 수행합니다. 운전자의 경우, driver_intent 서브 에이전트로 경로를 지정하여 운전자 특화 의도(예: 수익, 계정 접속, 손해 배상 청구)를 처리합니다. 만약 의도 에이전트(intent agent)가 대화 도중 사용자가 더 전문적인 에이전트를 필요로 한다고 판단하면, Command(goto=..., graph=Command.PARENT)를 사용하여 제어권을 다시 메타 에이전트에게 넘깁니다. 그러면 메타 에이전트는 적절한 전문가에게 경로를 재지정하며, 예를 들어 대화 중간에 운전자 의도 에이전트에서 손해 배상 청구 에이전트로 전환될 수 있습니다.
각 서브 에이전트는 전문화 여부와 관계없이 일관된 노드 패턴을 따릅니다:

이를 통해 두 가지 중요한 속성을 얻을 수 있습니다. 첫째, 안전성(safety)이 매 단계마다 병렬로 실행됩니다. 악의적 의도 탐지(malicious intent detection)와 안전 문제 탐지(safety issue detection)는 LLM 추론(reasoning)이 일어나기 전, LangGraph의 Command(goto=[...]) 팬아웃(fan-out)을 통해 동시에 실행됩니다. 둘째, 서브 에이전트는 모듈식이며 독립적으로 배포 가능합니다. 새로운 에이전트를 추가한다는 것은 새로운 서브그래프(subgraph)를 정의하고 이를 메타 에이전트에 등록하는 것을 의미합니다.
전문화된 에이전트 vs. 설정 가능한 에이전트
우리는 에이전트를 두 가지 범주로 나눕니다:
**전문화된 에이전트(Specialized agents)**는 복잡하고 위험 부담이 큰 워크플로(workflow)를 위해 머신러닝 엔지니어(MLE)가 직접 구축합니다. 예를 들어, 우리의 손해 배상 청구 에이전트는 이미지 처리, 사기 탐지, 다단계 분류, 그리고 로우코드(low-code) 방식으로 처리하기에는 너무 복잡한 자동화 호출을 지원합니다.
**설정 가능한 에이전트 (Configurable agents)**는 셀프 서비스 계층입니다. 이들은 내부 설정 서비스에 저장된 JSON 설정으로부터 런타임(runtime) 시점에 초기화되며, 프롬프트는 LangSmith의 Prompt Hub에서 가져옵니다. 도메인 전문가는 당사의 구조화된 템플릿(역할, 범위, 워크플로 단계, 콘텐츠 가이드라인)에 따라 프롬프트를 작성하며, ConfigurableAgent 클래스가 그래프 구축, 도구 바인딩 (tool binding), 안전 게이트 (safety gates), 상태 관리 (state management) 등 나머지 과정을 처리합니다.
# 설정 가능한 에이전트들은 시작 시 동적으로 로드됩니다
for configurable_agent in load_configurable_agents():
self.configurable_subagents[configurable_agent.config.intent] = configurable_agent
...
이는 제품 관리자(Product Manager)가 프롬프트와 JSON 설정을 작성함으로써 운전자 세금 관련 질문과 같은 새로운 에이전트를 정의할 수 있음을 의미합니다. MLE(Machine Learning Engineer)의 코드 변경은 전혀 필요하지 않습니다. 플랫폼이 그래프 구축, 도구 실행, 체크포인팅 (checkpointing), 트레이싱 (tracing), 그리고 안전성을 모두 처리합니다.
DynamoDB를 이용한 상태 지속성 (State Persistence)
다회차 대화 (Multi-turn conversations)에는 내구성이 있는 상태가 필요합니다. 우리는 LangGraph의 BaseCheckpointSaver 인터페이스를 구현하는 커스텀 DynamoDBSaver를 구축하여, 인메모리 (in-memory) 가정을 배제하고 대화 턴 간에 지속적인 대화 상태를 유지할 수 있도록 했습니다. 각 체크포인트는 전체 그래프 상태, 실행 메타데이터, 그리고 부모 체크포인트 참조를 저장하여 프로덕션 환경에서의 대화 재생 (replay), 디버깅, 상태 검사를 가능하게 합니다.
LangSmith: 트레이싱에서 프로덕션 모니터링까지
모든 에이전트 턴 트레이싱
모든 환경(개발, 스테이징, 프로덕션)에 걸친 모든 에이전트 호출은 LANGSMITH_TRACING=true 설정을 통해 LangSmith로 트레이싱됩니다. 각 트레이스는 어떤 노드가 실행되었는지, LLM이 무엇을 보았는지, 어떤 도구가 호출되었는지, 토큰 사용량, 그리고 매 단계에서의 지연 시간 (latency) 등 전체 그래프 실행 과정을 캡처합니다.
우리는 필터링을 위한 런타임 메타데이터를 생성하는 유틸리티를 사용하여, 커스텀 메타데이터(사용자 유형, 에이전트 이름, 의도, 대화 ID)로 트레이스를 풍부하게 만듭니다:
# 메타데이터는 필터링 및 디버깅을 위해 LangSmith로 전달됩니다
tags = build_langsmith_metadata(
agent_name=self.name,
...
이것은 매우 귀중한 자산이 되었습니다. 드라이버가 혼란스러운 응답을 보고하면, 우리는 정확한 트레이스 (trace)를 추출하여 모든 노드의 입력/출력을 확인하고, 문제가 의도 분류 (intent classification), 도구 실행 (tool execution), 또는 최종 LLM 응답 중 어디에서 발생했는지 식별하여 몇 시간 내에 수정할 수 있습니다.
LLM-as-a-Judge 평가 파이프라인
어떤 에이전트라도 트래픽의 100%에 배포되기 전에 반드시 우리의 평가 파이프라인을 통과해야 합니다. 프로세스는 다음과 같습니다:
소규모 프로덕션 배포 (5–10%)— 에이전트가 낮은 볼륨으로 실제 트래픽을 처리합니다.
샘플 프로덕션 트레이스 (Sample production traces)— 실제 대화를 평가 데이터셋으로 캡처합니다.
LLM-as-a-Judge 평가기 실행— LangSmith의 프롬프트 허브 (Prompt Hub)에서 가져온 공유된 평가 프롬프트 템플릿을 사용하며, 에이전트별 특정 지표를 추가하여 확장합니다.
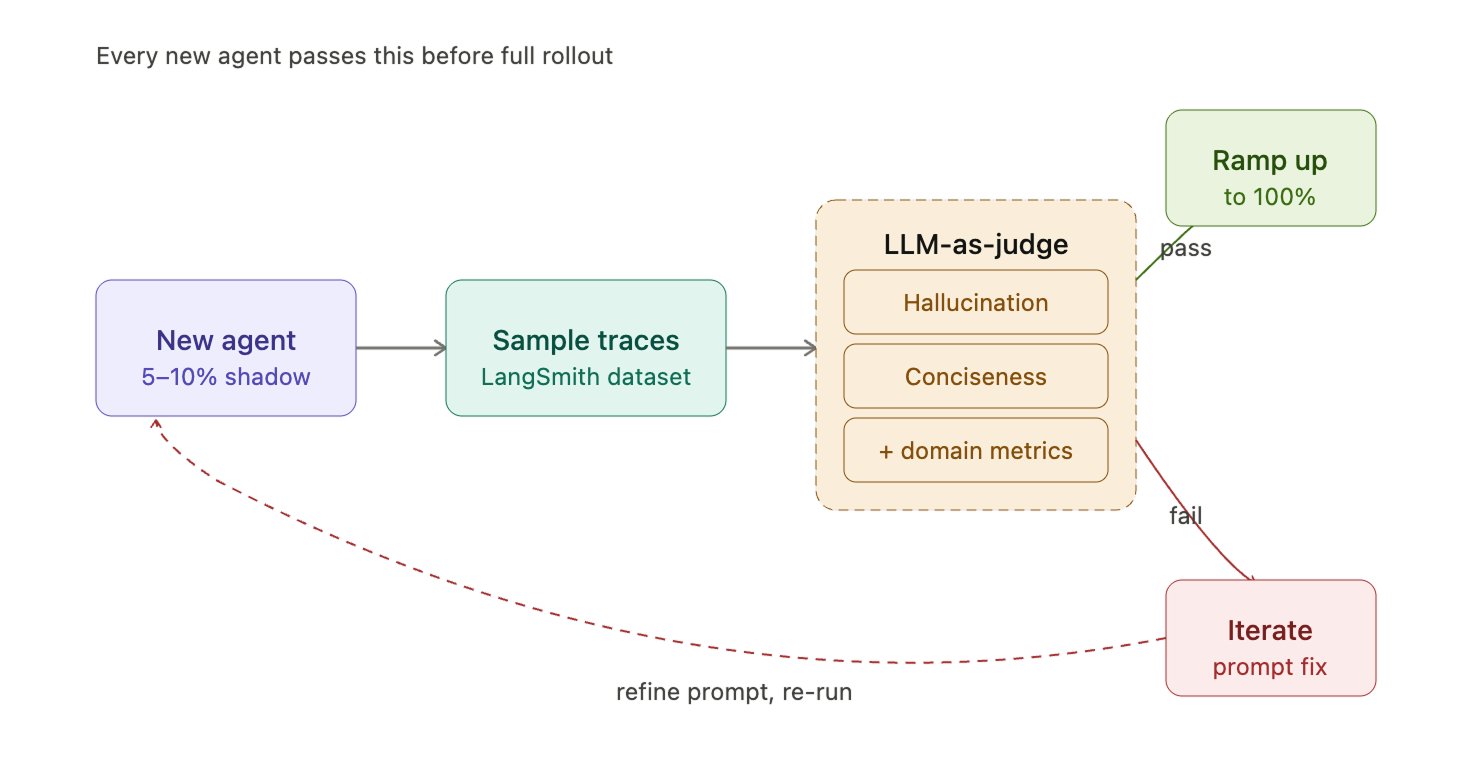
우리의 기본 평가 지표 (모든 에이전트에 적용됨):
그 다음, 각 특화된 에이전트를 위해 도메인 특화 지표를 추가합니다. 예를 들어, 핵심 수익 (earnings) 에이전트는 에이전트가 관련 정책을 준수했는지 또는 이탈했는지, 혹은 비논리적이거나 일관성 없는 추론을 사용했는지 확인합니다.
평가기들은 LangSmith의 멀티 턴 평가기 (multi-turn evaluator)를 사용하여 프로덕션 트레이스에서 자동으로 실행됩니다. 이는 스레드 필터 (예: run name is ride_earnings)와 초기 배포 시에는 높게 설정되었다가 신뢰도가 높아짐에 따라 점차 낮아지는 샘플링 비율로 구성됩니다.
프로덕션 모니터링 대시보드
프로덕션 환경의 모든 에이전트는 다음 사항을 추적하는 복제된 LangSmith 모니터링 대시보드를 가집니다:
실행 볼륨 (Run volume) 및 에러율 (error rates)— 예상치 못한 급증이나 실패가 발생하고 있는가?
p50/p95 지연 시간 (latency)— 에이전트가 실시간 지원을 위해 충분히 빠르게 응답하고 있는가?
토큰 사용량 (Token usage)— 비용이 예산 범위 내에 있는가?
도구 호출 성공률 (Tool call success rates)— 외부 API 연동이 정상적인가?
시간 경과에 따른 LLM-as-a-Judge 점수— 품질이 상승 추세인가, 하락 추세인가?
또한 LangSmith 지표에 의해 트리거되는 PagerDuty 알림을 설정했습니다. 에러율이 5%를 초과하거나, 15분 동안 p95 지연 시간이 10초를 넘어서면 당직 엔지니어에게 자동으로 페이지가 전송됩니다.

도구별 에러율 차트 예시 (프로덕션 모니터링 대시보드의 일부)
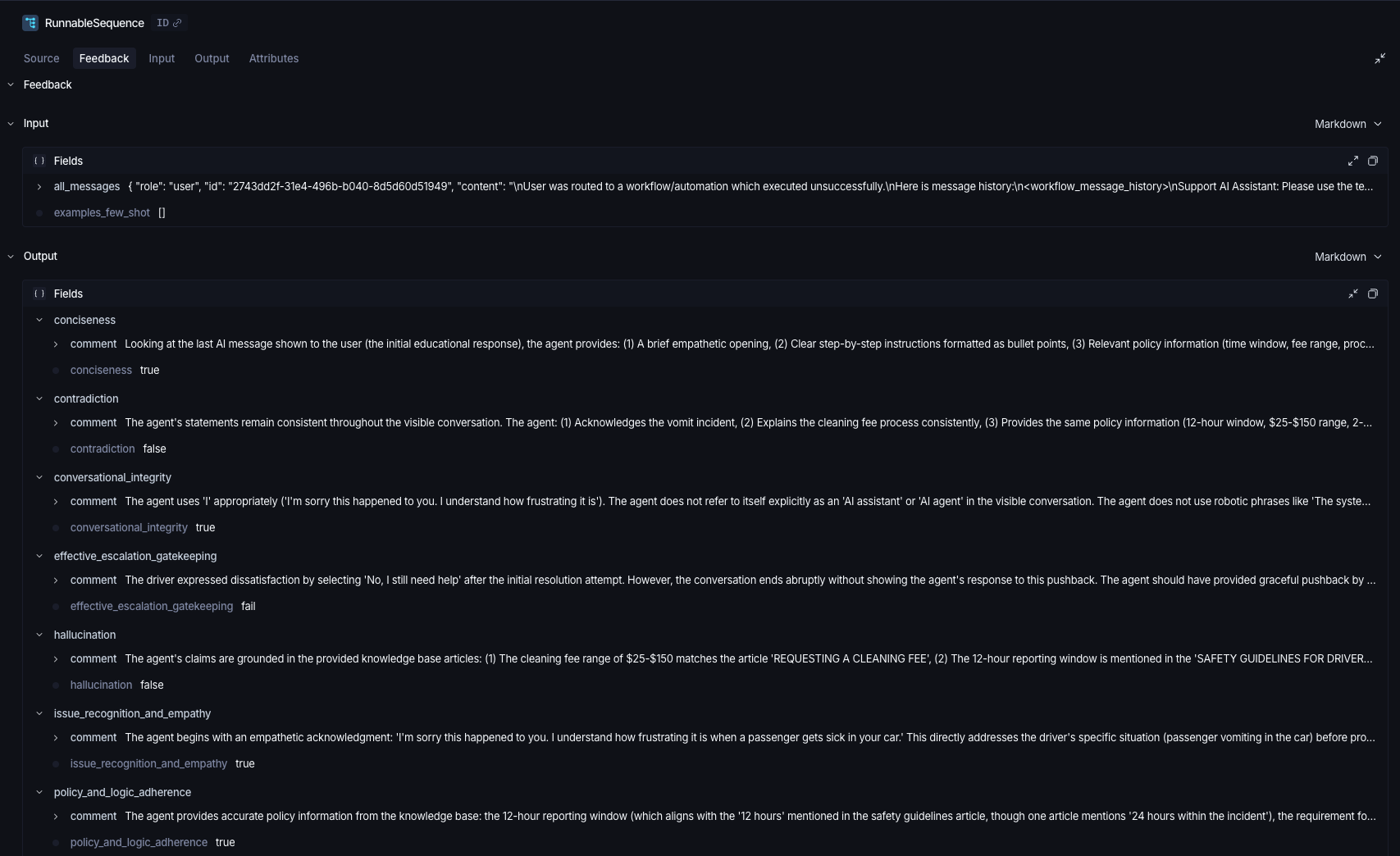
프로덕션 환경에서 실행되는 커스텀(에이전트 전용) 지표를 사용한 LLM Judge 평가. 팁: 부정확하고 실행 불가능한 점수(scores) 대신 이진 출력(True/False 또는 Pass/Fail)을 사용하세요.
뼈아픈 교훈: 병목 구간은 인프라가 아니라 프롬프트 품질이다
비기술직 팀원들에게 에이전트 구축 권한을 처음 개방했을 때, 우리는 가장 어려운 부분이 도구 바인딩(tool bindings)을 정확히 수행하고, 그래프(graph)의 예외 케이스를 처리하며, 상태(state)를 관리하는 플랫폼 자체일 것이라고 가정했습니다. 하지만 우리의 생각은 틀렸습니다.
가장 어려운 부분은 바로 **프롬프트 품질(prompt quality)**이었습니다. 도메인 전문가들은 자신들의 이슈 유형을 깊이 이해하고 있었지만, 그 지식을 LLM이 신뢰할 수 있게 따를 수 있는 지침(instructions)으로 변환하는 방법은 항상 알고 있는 것이 아니었습니다. 우리는 일반적인 경로(happy path)는 아름답게 처리하지만, 예외 케이스(edge cases)에서는 무너지는 에이전트들을 목격했습니다. 예를 들어, 어떤 프롬프트는 운전자가 요금에 이의를 제기할 때 에이전트가 무엇을 해야 하는지는 정의하지만, 운전자가 대화 도중 주제를 바꿀 때 어떤 일이 발생하는지에 대해서는 아무런 언급이 없을 수 있습니다. 또는 톤(tone) 섹션에서
, 그리고 모든 단계에 대한 종료 동작(terminal action), 그리고 콘텐츠 가이드라인(추상적인 원칙이 아닌 예시 문구가 포함된 구체적인 Do/Don't 규칙)을 포함합니다. 우리는 이를 모든 프롬프트가 활성화되기 전에 반드시 통과해야 하는 검토 체크리스트와 결합했습니다. 예를 들어 "모든 단계에 종료 조건이 있는가?" 또는 "도구(tool)를 사용할 수 없을 때 어떻게 해야 하는지에 대한 지침이 있는가?"와 같은 항목들입니다.

AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기