LLM과 함께 사용할 때는 지루한 언어를 사용하라
요약
LLM과 코딩 에이전트를 활용할 때는 파편화가 적고 일관된 관습을 가진 '지루한' 언어와 생태계를 사용하는 것이 유리합니다. 학습 데이터의 분산이 낮은 기술일수록 모델이 더 신뢰성 있고 예측 가능한 결과물을 생성하기 때문입니다.
핵심 포인트
- LLM은 일관성 있는 기술을 강화하고 파편화된 기술을 증폭시킴
- 학습 코퍼스의 분산이 낮은 언어가 에이전트 실행에 더 유리함
- 최신 트렌드보다 강력한 관습을 가진 생태계가 모델 성능에 도움을 줌
- 예측 가능한 중앙값의 결과물을 얻기 위해 일관된 툴체인 선택이 중요
LLM과 함께 사용할 때는 지루한 언어를 사용하라
나는 일관성(consistency)이 복리로 작용한다는 생각으로 계속 되돌아오게 된다. 지난 2년 동안 여러 다양한 프로젝트에서 컨설턴트로 일하며 이를 절실히 느꼈다. 대규모 언어 모델(Large language models, LLM)은 일관성 없는 기술을 증폭시키고, 일관성 있는 기술을 조용히 강화한다. 가장 많은 파편화(fragmentation)를 겪는 언어와 생태계는 최악의 에이전트적(agentic) 결과물을 만들어내며, 가장 강력한 관습(conventions)을 가진 생태계는 최고의 결과물을 만들어낸다. 나는 이러한 효과가 대규모 코퍼스(corpuses)로 학습된 거대 모델 패러다임에서 어떤 도구가 살아남을지를 점점 더 결정하게 될 것이라고 생각한다.
코드가 저렴할지라도, 추론(inference)을 실행하는 것은 도박이다. 모델이 어느 순간 패키지를 설치하기로 결정하거나, 2019년의 기괴한 코딩 패턴을 만들어낼지 알 방법은 없다. 우리가 토큰(tokens)을 가지고 도박을 하고 있다는 점을 고려한다면, 우리는 중앙값(median)의 결과물을 생성하기 위해 강력하게 일관되고 강화된 모델 가중치(model weights)를 나타내는 임베딩(embeddings) 세트에 베팅해야 한다. 소프트웨어 개발 측면에서 이는 실제로 이상적이다. 왜냐하면 중앙값의 프로그램은 일반적으로 정보를 처리하고, 파일을 읽고 쓰고, 네트워크 요청에 응답하는 등의 기본적인 작업을 수행하기 때문이다.
AI 이전에도 엔지니어들은 매년 바뀌는 것처럼 느껴지는, 스스로를 재발명하는 언어들에 대해 불평했다. 이러한 불만은 실재했지만, 대부분 미적인 문제였으며 인간이 불필요하게 변화하는 생태계를 유지하거나 따라가야 한다는 좌절감의 증상이었다.
되돌아보면, 2024 State of JS 설문조사는 상대적으로 파편화된 생태계를 묘사한다. 인간에게 파편화는 짜증 나는 일이다. 하지만 그 모든 공공 코퍼스(public corpus)로 학습된 모델에게 파편화는 강화학습(reinforcement learning)이나 에이전트 하네스(agent harnesses)에서 해결해야 할 문제에 더 가깝다 (예를 들어, Claude Code의 유출은 Anthropic이 JavaScript 프레임워크에 대해 어느 정도 편향(bias)을 하드코딩했음을 보여주었다).
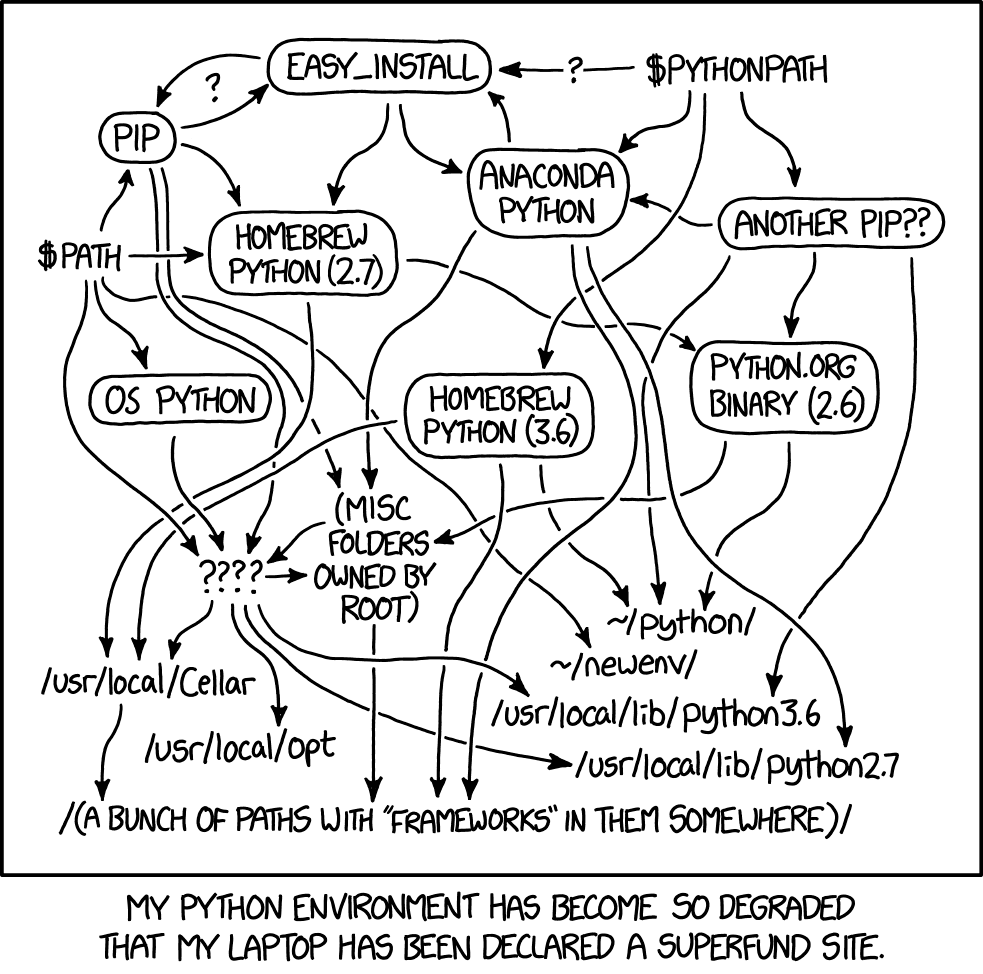
Python도 마찬가지이지만 다른 조(key)로 불리는 이야기일 뿐입니다. “어떤 패키지 매니저를 사용하나요?”와 같은 간단한 질문을 던지면 언어 버전, 패키지 매니저 버전, 그리고 OS 호환성이 뒤섞인 매트릭스가 생성되는데, 기술 리드(technical lead)로서 저는 이것이 완전히 정신을 아득하게 만든다고 느낍니다.
pip, poetry, uv 중 무엇을 사용해야 할까요? 툴체인(toolchain)이 중요한가요, 아니면 크로스 컴파일(cross-compiling)을 하고 있나요? Python 패키지가 C 의존성(dependency)과 암묵적으로 연결되어 있는지 어떻게 알 수 있을까요? 비동기(async)를 사용 중인가요, 아니면 태스크 큐(task queue)를 사용하고 있나요? Django인가요, 아니면 FastAPI인가요?
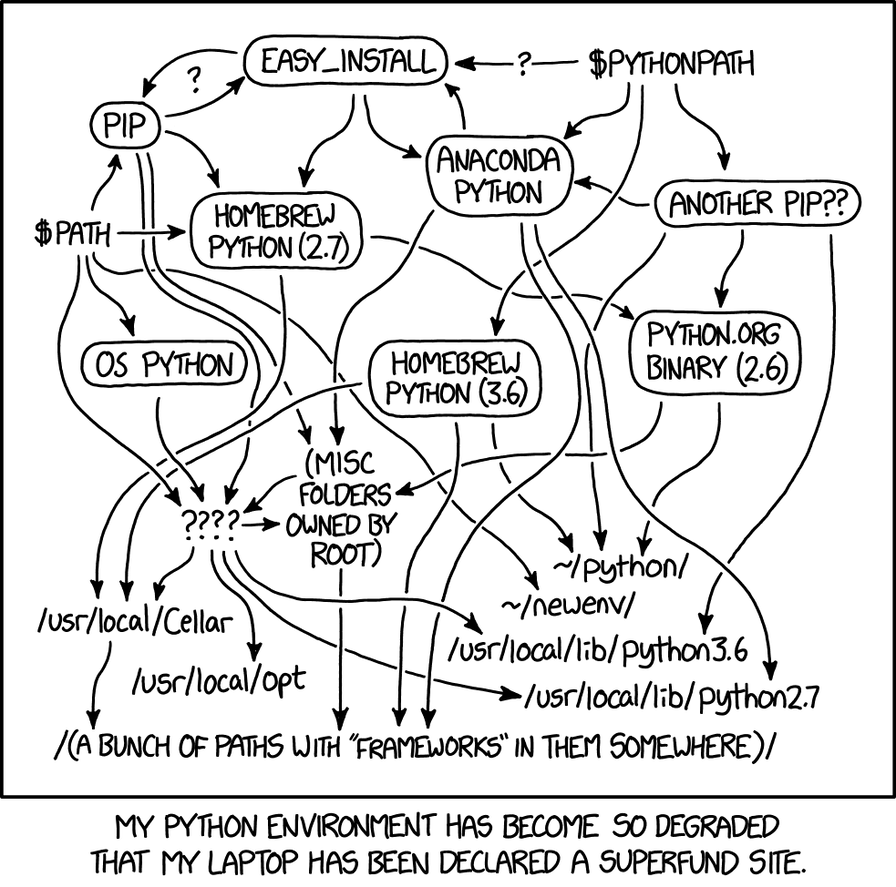
모델의 관점에서 보면, 이 모든 것을 작성하는 방법이 너무나 많으며, 학습 시점에 최신성 편향(recency bias)이 도입되지 않는 한 코퍼스(corpus, 말뭉치)는 그 모든 방법을 대략 동일한 비중으로 반영합니다. 이것이 의미하는 바는 저에게 명확하며 여러분에게도 명확할 것입니다… 학습 코퍼스의 분산(variance)이 낮은 언어와 생태계가 코딩 에이전트(coding agents)에 의해 더 잘 표현되고 더 신뢰성 있게 실행됩니다. 고차원 벡터 공간(higher dimension vector spaces)에서, 학습 데이터의 코사인 유사도(cosine similarity)는 모델의 어텐션(attention) 및 MLP 레이어가 다음 토큰을 예측하도록 학습하는 기질(substrate)이 됩니다. 일관된 코퍼스는 일관된 추론(inference) 토큰을 생성합니다.
이 패턴은 다른 언어에서도 유지됩니다. 에이전트 기반 작업(agentic work)에서 Rails 프로젝트에 대한 추론은 일반적인 JavaScript 백엔드에 비해 더 일관된 출력을 생성하는데, 이는 Ruby가 어떤 플라톤적(Platonic) 의미에서 더 나은 언어이기 때문이 아니라, 본질적으로 '하나의 Rails'가 존재하기 때문입니다. 반면, 동일한 기본 기능들에 대해 서로 다른 벤 다이어그램을 제공하는 프로덕션급 JavaScript 프레임워크는 적어도 12개 이상 존재합니다. 설정보다 관습(Convention over configuration)은 인간 프로그래머에게 승리였습니다. 왜냐하면 유연성은 과대평가되었고 제약은 해방을 가져다주기 때문입니다. 20년이 지난 지금, 기계에게도 똑같은 사실이 적용되며, 어쩌면 그 효과는 더 클 수도 있습니다. 모델은 단지 어떤 결과가 가장 가능성이 높은지를 해결하고 있을 뿐입니다…
Go는 거의 우연하게도 이 원칙을 가장 잘 구현하고 있습니다. 수년 동안 Golang은 프로그래머들이 지속적으로 요구해 온 편의성과 고수준 표현식(특히 제네릭 (generics))에 저항해 왔으며, 이러한 저항은 현업 개발자들 사이에서 매우 인기가 없었습니다. 저 또한 그 개발자들 중 한 명이었습니다. 저는 수십만 줄의 Go 코드를 작성해 왔으며, 프로그래머로서 이 언어가 종종 화가 날 정도로 답답하다고 느꼈습니다.
저는 Golang 팀의 몇몇 사람들을 알고 있으며, 프로그램의 미래를 향한 그들의 완고한 헌신을 존경합니다. 저는 Google이 대부분 의도치 않게, 지금 이 순간을 위한 세계 최고의 언어를 만들어냈다고 생각하게 되었습니다. 별도의 설정 없이도, Go는 에이전트 (agent)에게 다른 어떤 주류 언어도 동일한 조합으로 제공하지 못하는 일련의 이점들을 제공합니다.
첫 번째는 동시성 모델 (concurrency model)입니다. Goroutine은 스레드 (threads), 콜백 (callbacks), async/await, 또는 다른 곳에서 지배적인 컬러 함수 (colored-function) 체계보다 코딩 에이전트에게 훨씬 더 다루기 쉬운 기본 단위 (primitive)입니다. 이는 단순하고, 타입 안정성 (type-safe)을 갖추고 있으며, 모델이 학습한 말뭉치 (corpus) 내에서 유비쿼터스하게 사용됩니다. 함수의 색상이 무엇인지에 대한 문제는 존재하지 않기 때문에, 고민할 필요조차 없습니다.
results := make(chan string, len(urls))
for _, u := range urls {
go func(u string) {
...
두 번째는 표준 라이브러리 (standard library)입니다. net/http 하나만으로도 인터넷 마이크로서비스 (microservices)의 무시할 수 없는 상당 부분을 실행하고 있으며, (Google이 자금을 지원하고 유지 관리하는) 암호화 패키지들은 세계적인 수준입니다. 저는 Zoom과 Keybase에서 이러한 기본값들에 의존하는 프로덕션 시스템을 배포해 왔으며, 단 한 번도 이 범위를 벗어날 필요가 없었습니다.
package main
import (
"fmt"
...
세 번째는 툴체인 (toolchain)이며, 아마도 가장 과소평가된 부분일 것입니다. Go는 설계상 대부분의 일을 수행하는 단 하나의 올바른 방법을 가지고 있습니다. gofmt, go vet, 그리고 이제는 go fix가 협상의 여지 없이 단일한 표준 스타일 (canonical style)을 강제합니다. 언어 모델 (language model)에게 가능한 최상의 조합은 학습할 수 있는 일관된 말뭉치와, 런타임 (runtime)에서의 테스트 및 피드백을 위한 '단 하나의 올바른 방법'을 가진 툴링 (tooling)의 결합입니다. gopls
is 에이전트(agent)를 위한 환상적인 가드레일(guardrail)입니다. 왜냐하면 실시간 시맨틱 피드백(semantic feedback)을 제공하기 때문이며, golangci-lint는 에이전트에게 준수하도록 프롬프트(prompt)를 입력할 필요 없이 코딩 스타일과 프리미티브(primitives)를 정적으로 강제할 수 있게 해줍니다.
$ go vet ./...
./user.go:22:2: result of fmt.Errorf call not used
./user.go:38:9: declaration of "err" shadows declaration at line 34
...
네 번째 장점은 가비지 컬렉션(garbage collection)을 통한 성능입니다. 언어 모델(Language models)은 메모리 관리 측면에서 일관성이 없는데, 이는 잘 문서화된 한계이며 곧 사라질 문제도 아닙니다. Rust는 타입(type)과 빌림 검사(borrow-checking) 수준에서 메모리 안전성을 강제하는데, 이는 인간에게는 훌륭하지만 에이전트에게는 끊임없는 싸움입니다. 코딩 에이전트와 함께 C 또는 C++를 작성하는 것은 훨씬 더 어렵습니다. 왜냐하면 학습 데이터(training data)가 메모리 버그, use-after-free 오류, 그리고 모델이 피할 수 있는 만큼이나 똑같이 재현해낼 수 있는 수십 년간의 값비싼 실수들로 가득 차 있기 때문입니다. Go는 에이전트에게 메모리를 직접 관리하도록 요구하지 않으면서도 네이티브(native)에 가까운 성능을 제공합니다.
func parseLines(r io.Reader) []string {
var out []string
s := bufio.NewScanner(r)
...
다섯 번째는 작고 잘 알려진 실수 유발 요소(footguns)의 집합입니다. nil 포인터(pointers)는 적절한 도구가 있다면 에이전트가 놀라울 정도로 잘 처리할 수 있는 부분이지만, 인간 엔지니어에게는 프로덕션 스택 트레이스(stack traces)에서 추적하기 어려울 수 있습니다. 관용적인(idiomatic) Go에서 잘못될 수 있는 일들의 집합은, 예를 들어 임의의 메타클래스(metaclasses)를 사용하는 Python에서 잘못될 수 있는 일들의 집합과는 달리 제한적입니다.
data, err := os.ReadFile(path)
if err != nil {
return fmt.Errorf("read config %q: %w", path, err)
...
이 글을 읽을 때 적절한 반응은 “Go가 최고의 언어다”가 아니라 더 구체적인 것이어야 합니다. 이 언어와 툴체인(toolchain)은 숙련된 엔지니어가 원하는 비시각적(non-visual) 소프트웨어의 대부분을 작성할 수 있습니다. 다음 CLI, 백엔드 서버, 에이전트 오케스트레이터(agent orchestrator)를 구축하기 위해 에이전트와 함께 Go를 사용하는 것을 고려해 보십시오.
만약 이 내용 중 공감 가는 부분이 있다면 연락해 주세요. 팀이 일관된 결과물을 낼 수 있도록 도와줄 기술 리드(technical lead)를 찾고 계신다면 말이죠.
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기