LangSmith를 활용한 쌍체 평가 (Pairwise Evaluations)
요약
LangSmith의 새로운 기능인 쌍체 평가(Pairwise Evaluations)를 소개합니다. LLM 응답을 개별 점수로 매기는 대신, 두 응답을 동시에 비교하여 인간의 선호도를 더 효과적으로 모방하고 모델 성능을 정밀하게 측정하는 방법을 다룹니다.
핵심 포인트
- 쌍체 평가를 통해 LLM 응답 간의 상대적 우위를 직접 비교 가능
- LLM-as-a-judge 방식을 활용한 평가 프로세스 자동화 지원
- 기존 개별 점수 방식보다 정교한 회귀 테스트 및 벤치마킹 가능
- LangSmith의 'Pairwise Experiments' 기능을 통한 워크플로우 구현
모델 출력(model outputs)을 평가하는 것은 LLM 애플리케이션 개발에서 가장 중요한 과제 중 하나입니다. 하지만 많은 작업(예: 채팅 또는 글쓰기)에 대한 인간의 선호도(human preference)를 일련의 규칙으로 인코딩하는 것은 어렵습니다. 대신, 여러 후보 LLM 답변에 대한 쌍체 평가 (pairwise evaluation)가 LLM에게 인간의 선호도를 가르치는 더 효과적인 방법이 될 수 있습니다.
아래에서는 쌍체 평가가 무엇인지, 왜 이것이 필요한지 설명하고, LLM 애플리케이션 개발 워크플로우에서 LangSmith의 최신 쌍체 평가기 (pairwise evaluators)를 사용하는 방법에 대한 단계별 예시를 제시합니다.
쌍체 평가의 기원
쌍체 평가 (Pairwise evaluation)는 LLM 모델 성능의 테스트 및 벤치마킹 (benchmarking)에 관한 논의에서 중요한 역할을 하기 시작했습니다. 예를 들어, 인간 피드백으로부터의 강화학습 (RLHF, reinforcement learning from human feedback)은 LLM 정렬 (alignment)에서 쌍체 평가의 개념을 채택합니다. 인간 트레이너는 동일한 입력에 대한 한 쌍의 LLM 응답을 보고, 어떤 것이 특정 기준(예: 유용성, 정보성 또는 안전성)에 더 잘 부합하는지 선택합니다.
가장 인기 있는 LLM 벤치마크 중 하나인 Chatbot Arena 또한 이 아이디어를 채택하고 있습니다. 이는 주어진 사용자 프롬프트에 대해 두 개의 익명 LLM 생성물을 제시하고 사용자가 더 나은 것을 선택할 수 있도록 합니다. Chatbot Arena는 쌍체 평가를 위해 인간의 피드백에 의존하지만, LLM-as-a-judge를 사용하여 인간의 선호도를 예측하고 이 쌍체 평가 프로세스를 자동화하는 것도 가능합니다.
공공 벤치마킹 및 LLM 정렬에서의 인기에도 불구하고, 많은 사용자가 자신의 LLM 애플리케이션을 개선하기 위해 커스텀 쌍체 평가를 어떻게 사용하는지는 모를 수 있습니다. 이러한 한계를 염두에 두고, 저희는 LangSmith에 새로운 기능으로 쌍체 평가를 추가했습니다.
LangSmith의 쌍체 평가기 (Pairwise evaluators)
LangSmith의 쌍체 평가 (pairwise evaluation)를 사용하면 사용자는 (1) 원하는 기준을 사용하여 사용자 정의 쌍체 LLM-as-judge 평가기를 정의하고, (2) 이 평가기를 사용하여 두 개의 LLM 생성물을 비교할 수 있습니다. 비교할 실행(runs)을 선택하는 대신, "Datasets and Testing" 탭을 클릭하면 "Pairwise Experiments"라는 새로운 하위 헤더가 나타납니다.
비교 뷰 (comparison view)와는 어떻게 다른가요?
여러분은 "이것이 비교 뷰 (comparison view)와 어떻게 다른가요?"라는 질문을 던질 수도 있습니다.
혹시 놓치셨을 수도 있는데, 몇 주 전에 회귀 테스트 (regression testing)를 위한 개선된 비교 뷰를 출시했습니다. 이를 통해 두 실행 (runs)을 비교하고 회귀 (regressions)를 식별할 수 있습니다. 쌍체 평가 (Pairwise evaluation)는 목표는 유사하지만, 구현 방식은 현저히 다릅니다.
이전의 비교 뷰에서는 각 실행을 개별적으로 평가한 다음 점수를 비교했습니다. 예를 들어, 각 실행에 대해 (독립적으로) 1-10점 척도로 점수를 매긴 다음, 한 실행이 다른 실행보다 높은 점수를 받은 사례를 찾는 방식이었습니다.
쌍체 평가 (Pairwise evaluation)는 결과를 동시에 살펴봅니다. 이를 통해 두 결과를 명시적으로 비교하는 평가기 (evaluator)를 정의할 수 있습니다. 그러면 해당 쌍 (pair)에 대한 점수를 얻게 됩니다. 이는 각 실행을 개별적으로 채점하는 것이 아닙니다.
언제 쌍체 평가를 사용할 수 있나요?
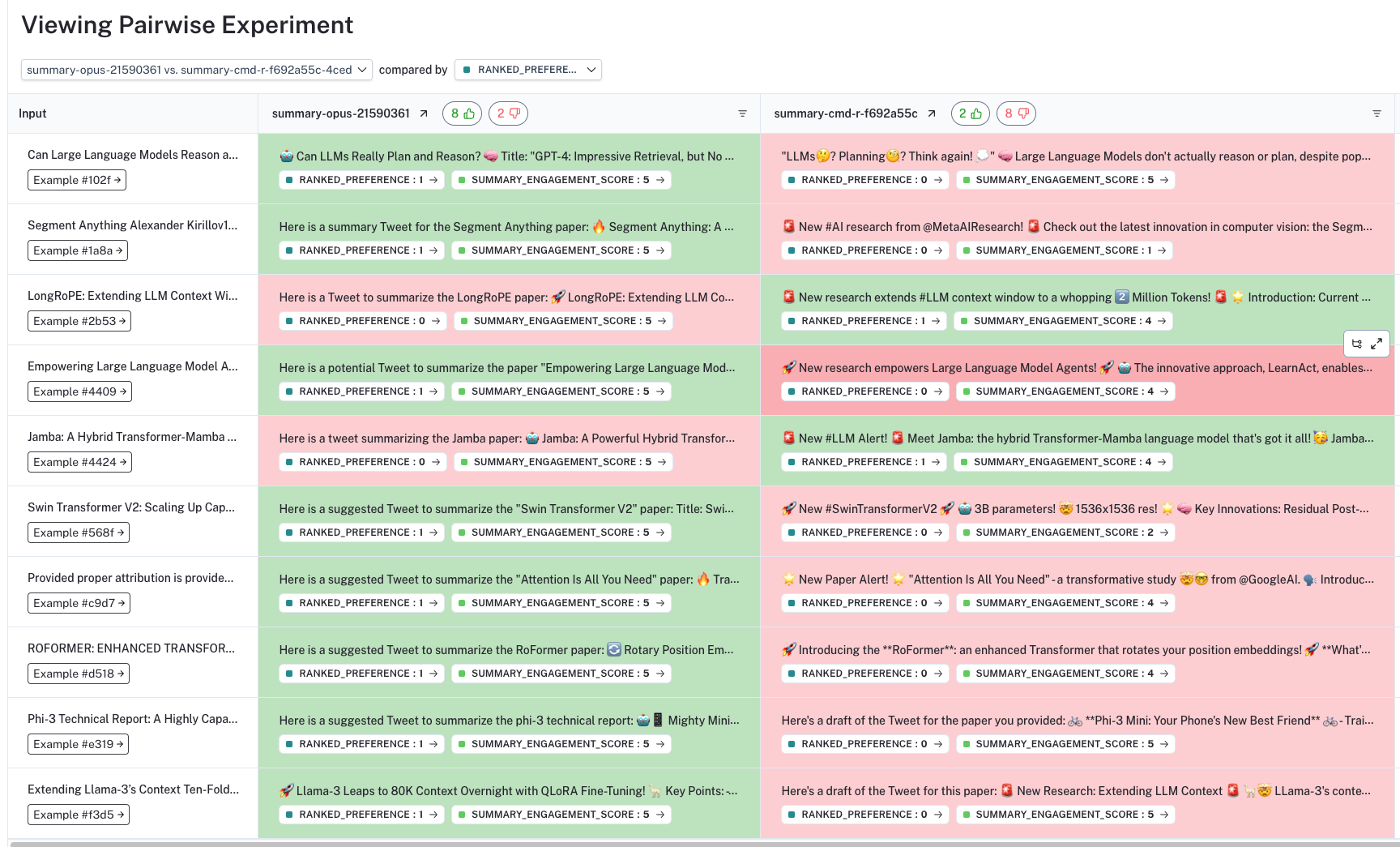
이 기능의 동기를 부여하기 위해, 이 영상은 콘텐츠 생성과 관련된 일반적인 사용 사례를 보여줍니다. 이 예시에서 우리는 LLM이 학술 논문을 요약하는 매력적인 트윗 (Tweets)을 생성하기를 원합니다. 우리는 예시로 10개의 서로 다른 논문이 포함된 데이터셋을 구축하였고 (여기), 4개의 서로 다른 LLM으로부터 요약본을 생성했습니다.
LLM이 생성하기를 원하는 단일한 "정답 (ground truth)" 논문 요약본이 없기 때문에, 우리는 5가지 기준(예: 이모지 사용, 매력적인 제목 등)을 바탕으로 요약 트윗을 1점(최악)에서 5점(최고)까지 채점하는 평가 프롬프트와 기준 평가기 (criteria evaluator)를 사용했습니다.
아래에 표시된 것처럼, 우리는 이 summary_engagement_score를 데이터셋에 캡처합니다.
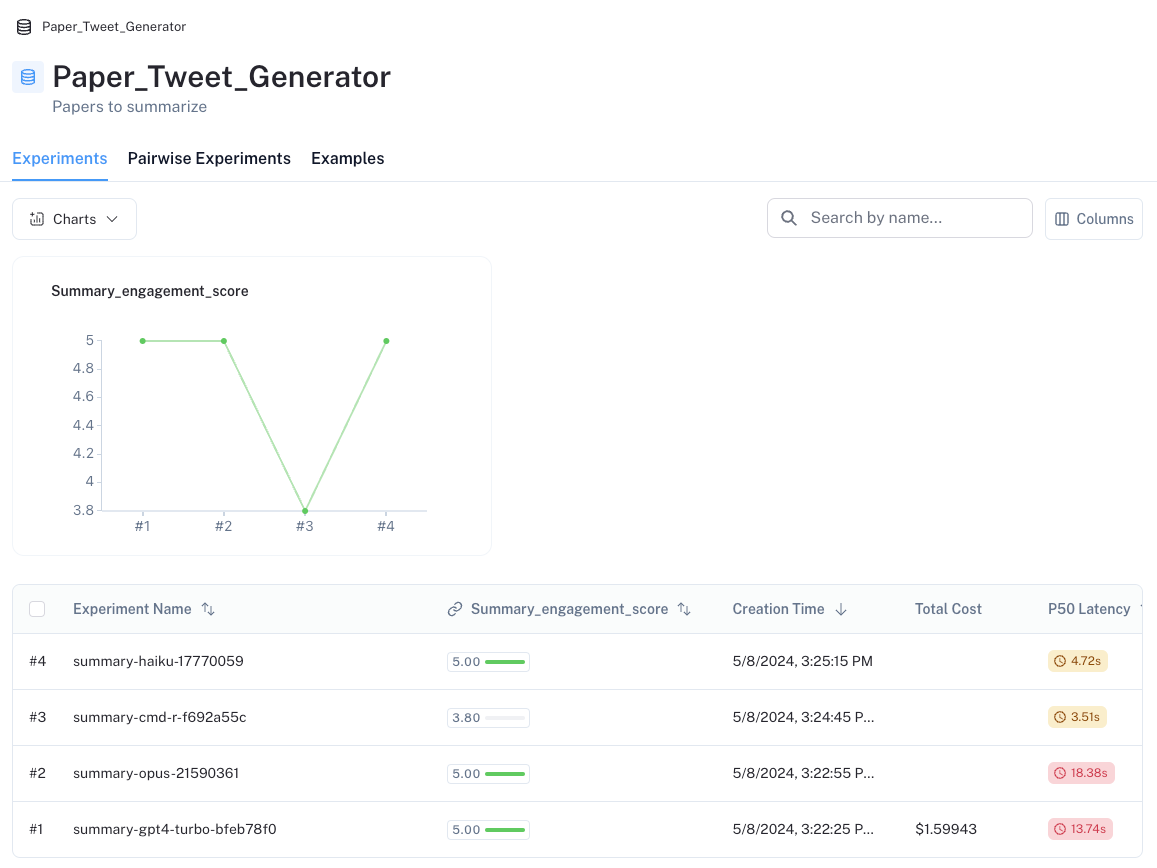
하지만 이는 즉시 한 가지 문제를 드러냅니다. 4개의 LLM 중 3개가 우리의 summary_engagement_score에서 차별점 없이 모두 **만점 (perfect score)**을 기록했다는 점입니다. 단독 평가(In isolation)만으로는 다양한 LLM을 구분할 수 있는 평가 기준 (criteria evaluator)을 정의하기 어려울 수 있습니다. 그러나 쌍체 평가 (pairwise evaluation)는 이 과제에 접근하는 대안적인 방법을 제시합니다.
커스텀 쌍체 평가 사용하기 (Using Custom Pairwise Evaluation)
영상(문서 링크)에서 보여주듯, 우리는 LangSmith SDK에서 커스텀 쌍체 평가기 (custom pairwise evaluators)를 사용하고, LangSmith UI에서 쌍체 평가 결과를 시각화합니다. 위에서 언급한 문제에 이를 적용하기 위해, 먼저 우리가 중요하게 생각하는 기준을 인코딩하는 쌍체 평가 프롬프트 (pairwise evaluation prompt)를 정의합니다 (예: 제목, 불렛 포인트 등을 기반으로 두 개의 트윗 요약 중 어느 것이 더 매력적인가).
그 다음, 우리 데이터셋에서 이미 실행된 임의의 두 실험에 대해 커스텀 평가기인 evaluate_pairwise를 실행하기만 하면 됩니다 (여기에 사용된 전체 코드 참조).
from langsmith.evaluation import evaluate_comparative
evaluate_comparative(
["summary-cmd-r-f692a55c", "summary-opus-21590361"],
evaluators=[evaluate_pairwise],
`)
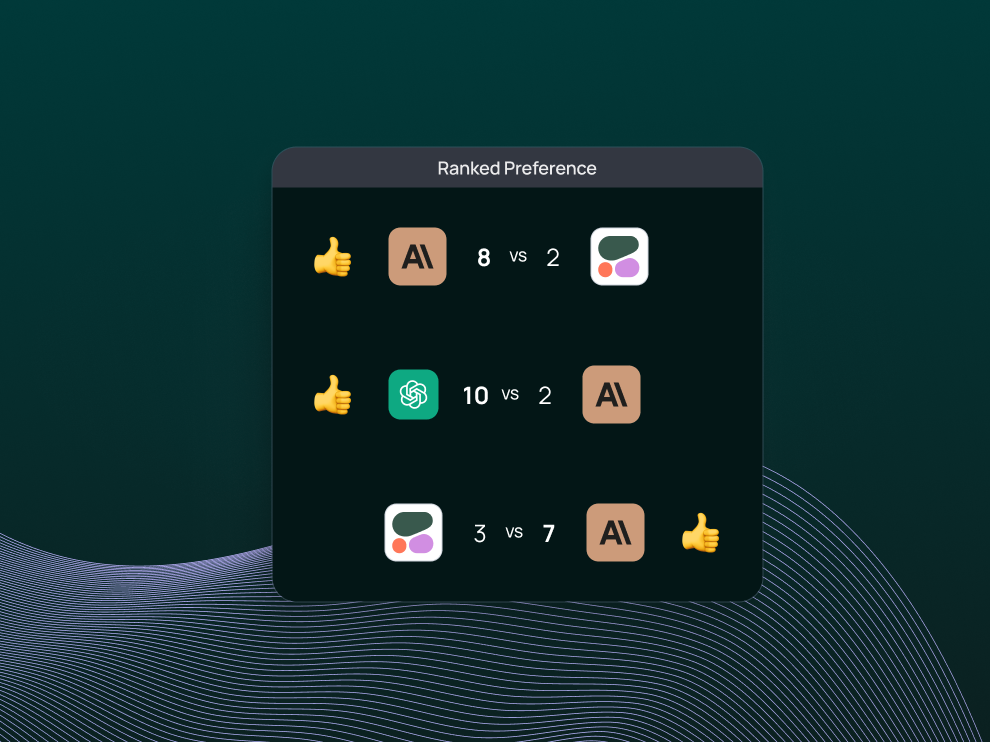
UI에서는 데이터셋의 Pairwise Experiments 탭에서 모든 쌍체 평가 결과를 확인할 수 있습니다. 중요한 점은, 구별 능력이 거의 없었던 단독 기준 평가 (stand-alone criteria evaluation)와 달리, 쌍체 평가를 통해 특정 LLM이 다른 LLM보다 명확하게 선호된다는 것을 확인할 수 있다는 것입니다.
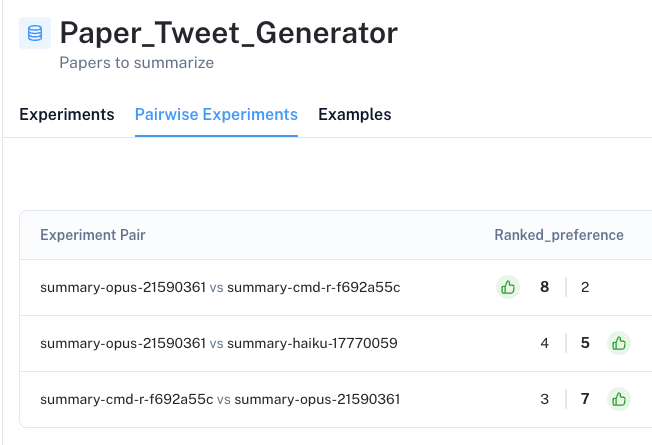
UI를 통해 각 쌍체 실험을 자세히 살펴볼 수 있으며, 우리의 기준에 따라 어떤 LLM의 생성물이 선호되는지 확인할 수 있습니다 (열 상단의 색상과 엄지 손가락 아이콘으로 표시). 각 답변 아래의 ranked_preference 점수를 클릭하면 각 평가 트레이스 (evaluation trace)를 더 깊이 파고들 수 있으며 (여기 예시 참조), 이를 통해 (프롬프트에 정의된 대로) 순위에 대한 설명을 확인할 수 있습니다.
결론
텍스트 생성(text generation)이나 채팅(chat)과 같은 많은 LLM 활용 사례(use-cases)는 평가에 사용할 단일하거나 특정한 "정답"이 존재하지 않습니다. 이러한 경우, 사람이나 LLM이 선호하는 응답을 선택하는 쌍체 평가 (pairwise evaluation) 방식이 강력한 접근법이 될 수 있습니다.
이 블로그 포스트에서 우리는 트윗 요약 생성(Tweet summary generation)을 평가하는 모호한 작업을 어떻게 테스트할 수 있었는지 보여주었으며, 단독 평가 기준(stand-alone evaluation criteria)의 단점을 드러냈습니다. 우리의 커스텀 쌍체 평가기(custom pairwise evaluator)를 통해 생성된 결과물들을 서로 직접 비교할 수 있었으며, 모델 간의 명확한 선호도를 확인할 수 있었습니다.
**더 자세히 알고 싶다면, 쌍체 평가에 관한 우리의 영상과 ****문서(documentation)**를 확인해 보세요. 또한, 프롬프트 버전 관리(prompt versioning), 디버깅(debugging), 그리고 사람의 주석(human annotations)을 지원하여 견고한 실험과 평가가 가능한 LangSmith를 오늘 바로 사용해 보세요. 이를 통해 LLM 애플리케이션을 구축하면서 프로덕션 관측성(production observability)을 확보할 수 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기