Huawei CSL, vLLM을 위한 KV-cache 양자화 플러그인 개발
요약
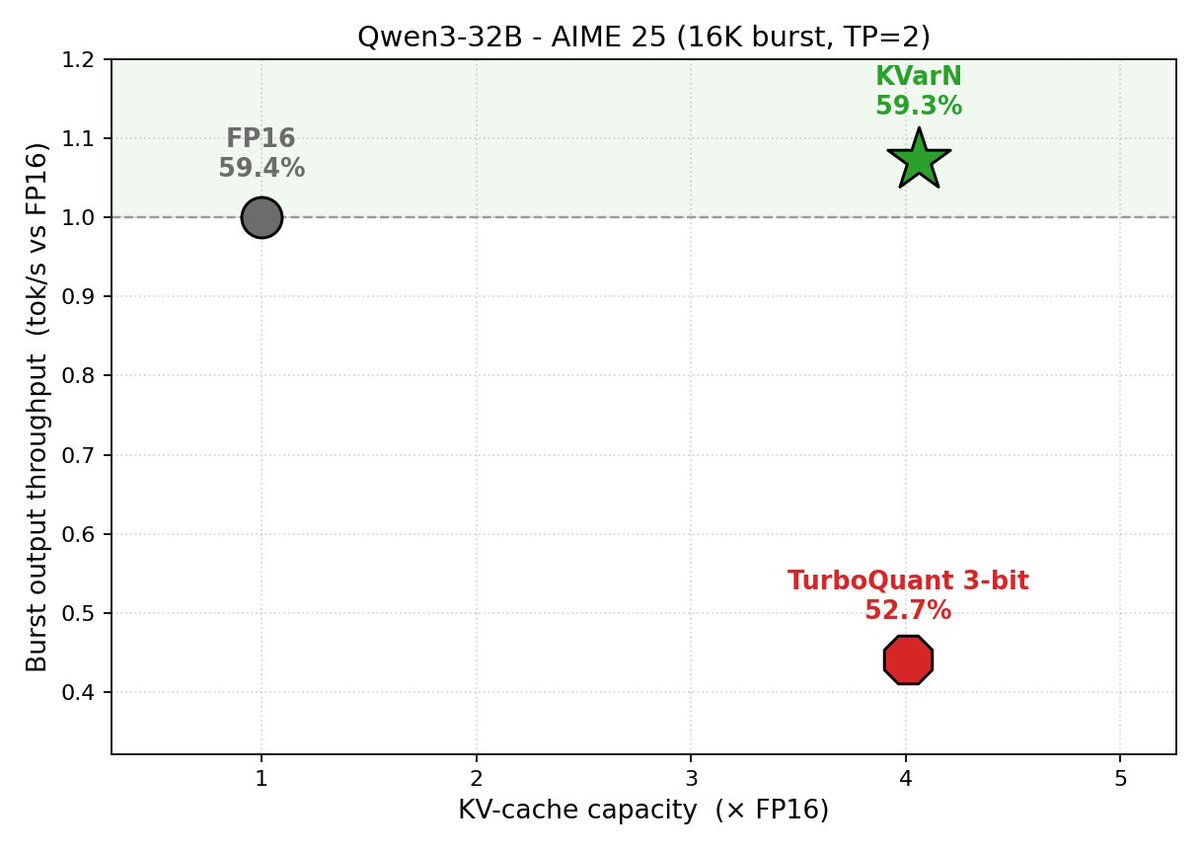
Huawei CSL이 vLLM용 KV-cache 양자화 플러그인을 개발했습니다. Hadamard 회전과 분산 정규화를 활용해 별도의 교정 없이도 높은 정밀도와 처리량을 제공합니다.
핵심 포인트
- 별도의 교정(Calibration) 과정 없이 즉시 사용 가능
- 캐시 용량을 3~5배 확장하여 긴 문맥 처리에 유리
- TurboQuant 대비 2.4배 빠른 속도와 높은 정밀도 구현
- Qwen3-32B 테스트 결과 FP16 수준의 정밀도 유지
Huawei CSL이 vLLM을 위해 개발한 KV-cache 양자화 (Quantization) 플러그인은 파라미터 하나만 추가하면 바로 사용할 수 있으며, 별도의 교정 (Calibration) 과정이 필요하지 않습니다. 이 방식은 캐시를 작은 블록으로 나누고, Hadamard 회전 (Hadamard Transform)과 분산 정규화 (Variance Normalization)를 사용하여 양자화를 수행합니다. Qwen3-32B 모델 테스트 결과, FP16과 동일한 정밀도를 유지하면서도 처리량 (Throughput)은 더 높아졌으며, 캐시 용량은 3~5배 증가했습니다. TurboQuant보다 2.4배 빠르며 정밀도 또한 더 뛰어납니다. 논문은 arXiv에 공개되어 있으며, 긴 문맥 (Long-context) 처리 및 에이전트 (Agent) 시나리오에 적합합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @qingq77 (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기0