
Harbor x LangChain: 에이전트 평가를 위한 통합 스택
요약
Harbor와 LangChain을 통합하여 에이전트 성능을 평가하기 위한 통합 스택을 소개합니다. 격리된 샌드박스 환경에서 에이전트를 병렬로 실행하고, LangSmith를 통해 트레이스를 분석하여 평가 결과의 원인을 파악할 수 있습니다.
핵심 포인트
- Harbor를 통한 에이전트의 격리된 환경 실행 및 수평적 확장 가능
- LangSmith 플러그인을 활용한 트레이스 기반의 상세한 평가 피드백
- 모델에 구애받지 않는(model-agnostic) 에이전트 연결 방식 제공
- 재현 가능한 환경 구축을 위한 Docker 기반의 태스크 구성 지원
핵심 요약 (Key Takeaways)
- 하나의 작은 진입점만으로 에이전트를 Harbor에 연결할 수 있습니다.
langgraph.json레지스트리와make_graph팩토리(factory)가 작성해야 할 유일한 접착제이며, 이 팩토리는 커맨드 라인에서 Harbor가 전달하는 모델을 읽음으로써 모델에 구애받지 않는(model-agnostic) 상태를 유지할 수 있습니다. 클라우드 샌드박스(Cloud sandboxes)를 통해 평가를 수평적으로 확장하고 에이전트를 격리된 상태로 실행할 수 있습니다. 각 트라이얼(trial)은 새로운 LangSmith 샌드박스를 할당받으므로 트라이얼 간에 상태를 공유하지 않으며, 한 대의 기기에서 순차적으로 처리하는 대신 수백 개를 병렬로 실행할 수 있습니다. - 트레이스(Traces)는 점수를 설명으로 변환합니다.
langsmith플러그인을 사용하면 모든 작업이 데이터셋과 실험(experiment)으로 등록되며, 검증기(verifier)의 보상(reward)을 피드백으로 활용할 수 있습니다. 또한 에이전트 트레이스가 직접 연결되어 트라이얼이 통과했는지 여부뿐만 아니라 왜 통과했는지 또는 실패했는지를 확인할 수 있습니다.
에이전트의 능력이 향상됨에 따라 평가(evaluations)는 더욱 어려워졌습니다. Claude Code, Pi, Deep Agents와 같은 에이전트 하네스(agent harnesses)는 이제 에이전트가 파일을 읽고, 스크립트를 실행하며, 코드를 실행하는 등 컴퓨터 전체에 접근할 수 있도록 합니다. 이제 모든 에이전트는 주어진 작업에 대해 자체적인 깨끗하고 재현 가능한 환경에서 실행되어야 합니다.
장시간 실행되는 상태 유지형(stateful) 에이전트를 평가하려면 새로운 평가 러너(eval runner)가 필요합니다. Harbor는 이 분야의 업계 리더로 부상했습니다. 이 블로그에서는 먼저 에이전트 평가를 수행하는 모든 사람이 왜 Harbor가 무엇인지 알아야 하는지 설명하고, 이어서 Deep Agents, LangSmith Sandboxes, LangSmith Experiments를 Harbor에 통합하는 방법을 보여줍니다.
궁극적으로 우리는 에이전트를 실제적이고 재현 가능하며 격리된 환경에서, 마지막에는 결정론적인(deterministic) 체크와 함께 수없이 많이 병렬로 실행해야 합니다. Harbor는 이 문제를 해결하며, 현재 Deep Agents, LangSmith Sandboxes, LangSmith Observability에 직접 연결되어 있습니다.
Harbor의 작동 방식
Harbor는 **평가 하네스(eval harness)**입니다. 사용자는 세 가지를 가져옵니다:
사용자의 에이전트 (Your agent)
사용자의 데이터셋 (Your dataset)
사용자의 샌드박스 (Your sandbox)
각 데이터셋에는 다음과 같이 구성된 태스크(tasks)가 있습니다:
- 환경 (Environment) (Dockerfile / Docker Compose YAML)
- 지침 (Instruction) (Markdown)
- 평가 스크립트 (Evaluation script) (test.sh)
더 단순한 LLM 평가와 비교했을 때, 두 가지 주요한 차이점이 있습니다:
- 에이전트가 실행되는 환경이 매우 중요합니다. 작업(task)의 일부로 명시해야 할 정도로 중요합니다! 더 단순한 LLM 평가에는 환경이 필요하지 않습니다. 단순히 LLM을 호출할 뿐입니다. 하지만 에이전트에게는 환경이 필요합니다!
- 에이전트를 판단하는 것은 스크립트를 통해 이루어집니다. 종종 에이전트는 다른 파일들을 생성하거나 어떤 방식으로 상태(state)를 수정합니다. 에이전트의 최종 응답만 보는 것으로는 충분하지 않습니다. 에이전트가 진행 과정에서 생성한 아티팩트(artifacts)들을 살펴봐야 합니다.
LangChain은 세 가지 지점에서 Harbor에 연결됩니다. 우리는 Deep Agents와 통합되어 있어, 여러분이 구축한 어떤 Deep Agent라도 Harbor의 샌드박스(sandboxed) 환경 내에서 실행될 수 있습니다. 우리는 LangSmith Sandboxes와 통합되어 있어 Harbor가 각 작업을 LangSmith 샌드박스에서 실행할 수 있게 하며, 각 실행에 대해 고유하고 깨끗한 머신을 제공합니다. 그리고 우리는 결과를 상세히 확인할 수 있는 평가 플랫폼인 LangSmith Observability와 통합됩니다. 모든 작업은 데이터셋(dataset)으로 저장되며, 에이전트가 지원하는 경우 에이전트 트레이스(agent traces)가 첨부된 실험(experiment)으로 기록됩니다.
LangChain 에이전트와 Harbor의 통합
--agent langgraph로 선택되는 내장 langgraph 에이전트를 통해 Harbor에 커스텀 에이전트를 연결할 수 있습니다. 이는 Deep Agents를 포함한 모든 LangGraph 애플리케이션을 실행합니다.
Harbor는 langgraph.json을 레지스트리(registry)로 취급합니다. 여기에는 에이전트에 필요한 종속성(dependencies)이 나열되어 있으며, 그래프 이름이 이를 구축하는 함수에 매핑됩니다:
{
"dependencies": [
"deepagents>=0.6.10,<0.7.0",
...
여기서 deep_agent는 agent.py의 make_graph로 해결(resolves)되며, 이 함수는 Deep Agent를 구축하고 Harbor가 호출할 컴파일된 그래프를 반환합니다:
from deepagents import create_deep_agent
from deepagents.backends import LocalShellBackend
def make_graph():
...
이것이 여러분이 작성해야 하는 유일한 접착제(glue) 코드입니다. 에이전트는 여러분의 고유한 코드로 유지되며, make_graph는 단지 Harbor가 호출하는 진입점(entry point)일 뿐입니다. 기본적으로 create_deep_agent는 파일을 샌드박스에 전혀 닿지 않는 인메모리 가상 파일 시스템(in-memory virtual filesystem)에 보관하므로, LocalShellBackend와 함께 사용하십시오.
Harbor가 실행하는 환경에 에이전트가 실제 파일 및 셸(shell) 액세스 권한을 부여하기 위함입니다.
모든 시도(trial)마다 Harbor는 이 에이전트를 해당 시도의 샌드박스(sandbox)로 복사하고, 그곳의 새로운 가상 환경(virtual environment)에 langgraph.json 의존성(dependencies)을 설치한 뒤 컨테이너 내부에서 그래프(graph)를 실행합니다. 각 샌드박스는 자신만의 복사본을 가지므로, 시도들은 결코 상태(state)를 공유하지 않으며 에이전트는 완전히 격리된 상태로 실행됩니다.
참고: 그래프는 모델을 하드코딩할 수 있지만, 엔트리(entry)는 Harbor가 실행 설정(run config)과 함께 호출하는 **팩토리 함수 (factory function)**가 될 수도 있습니다. Harbor는 --model로 선택된 모델을 configurable.model에 넣으므로, 위의 팩토리는 모델 불가지론적(model-agnostic)인 상태를 유지하며 명령줄(command line)을 통해 전달된 값을 create_deep_agent로 직접 전달합니다.
from deepagents import create_deep_agent
from deepagents.backends import LocalShellBackend
def make_graph(config):
...
LangSmith 샌드박스와 Harbor의 통합
클라우드 기반 샌드박스에서 평가(evals)를 실행하면 **수평적 확장 (horizontally scale)**이 가능하여 훨씬 빠른 피드백을 받을 수 있습니다. 즉, 한 대의 머신이 직렬로 처리하는 대신 수백 개의 시도를 동시에 진행할 수 있습니다. 또한 샌드박스는 **제한된 실행 환경 (constrained execution environment)**이며, 이는 환경에 영향을 미치는 장기 실행 에이전트(long-running agent)가 필요로 하는 바로 그것, 즉 외부의 무엇도 영향을 주지 않고 행동할 수 있는 깨끗하고 격리된 공간을 제공합니다.
모든 시도는 각자의 클라우드 샌드박스에서 실행됩니다. -e langsmith로 선택하는 **LangSmith 샌드박스 (LangSmith Sandbox)**를 가져올 수 있지만, 환경은 교체 가능(pluggable)합니다. Harbor는 Daytona, Docker, Modal, E2B도 지원하며, 모두 동일한 -e 플래그 뒤에서 상호 교환 가능합니다. 제공자(provider)를 변경해도 에이전트, 데이터셋(dataset), 또는 검증기(verifier)에는 영향을 주지 않습니다.
**시도 (trial)**는 작업의 원자적 단위(atomic unit of work)로, 하나의 작업에 대한 에이전트의 한 번의 실행을 의미합니다. 에이전트는 비결정론적(non-deterministic)이기 때문에, 보통 각 작업을 여러 번 실행합니다. n_attempts는 Harbor가 모든 작업을 반복하는 횟수이며, 점수를 평균 내어 단 한 번의 운 좋은 또는 운 나쁜 실행이 결과를 결정짓지 않도록 합니다. 따라서 전체 **작업 (job)**은 n_attempts × tasks가 됩니다. 즉, 모든 작업에 대해 n_attempts만큼 실행합니다.
번, 각 반복(repetition)은 자체적인 시행(trial)이 됩니다. Harbor는 이 모든 과정을 오케스트레이션(orchestration)합니다.
각 시행(trial)에 대해, Harbor는 새로운 샌드박스(sandbox)를 프로비저닝(provision)하고 실행에 필요한 모든 것을 복사합니다: 에이전트 코드, 작업(task, 디스크에 캐싱된 후 샌드박스 VM으로 로드됨), 그리고 실행이 시작되는 모든 시작 파일들입니다. 그런 다음 지시 사항(instruction)에 따라 에이전트를 실행하고, 검증기(verifier)를 실행하며, 결과를 기록합니다. Harbor는 여러 시행(trial)에 걸친 결과들을 평균 내어 사용자가 중요하게 생각하는 지표(metrics)를 포함한 단일 작업(job) 결과로 산출합니다.
LangSmith 관측성(Observability)과 Harbor의 통합
harbor-langsmith 통합은 Harbor에 **LangSmith 트레이싱(tracing)에 대한 퍼스트 클래스 지원(first-class support)**을 제공하며, 데이터셋(datasets) 및 실험(experiments)에 대한 로깅(logging) 기능도 함께 제공합니다.
--plugin langsmith라는 단일 플래그(flag)로 이를 활성화할 수 있습니다. 그러면 Harbor는 모든 작업(job)을 LangSmith에 기록합니다: 데이터셋을 동기화하고, 실험을 생성하며, 검증기(verifier)의 보상(reward)을 피드백으로 하여 시행(trial)당 하나의 실행(run)을 로깅합니다. 테스트 중인 에이전트가 LangSmith 트레이싱(tracing)을 지원하는 경우, 해당 트레이스(traces)가 실험에 직접 연결되어 점수와 함께 전체 단계별 궤적(trajectory)을 확인할 수 있습니다. 트레이싱을 지원하지 않더라도 데이터셋, 실험, 결과 및 피드백은 여전히 얻을 수 있습니다.
'Datasets & Experiments' 메뉴 아래에서 현재 사용 중인 모든 활성 데이터셋을 확인할 수 있습니다.
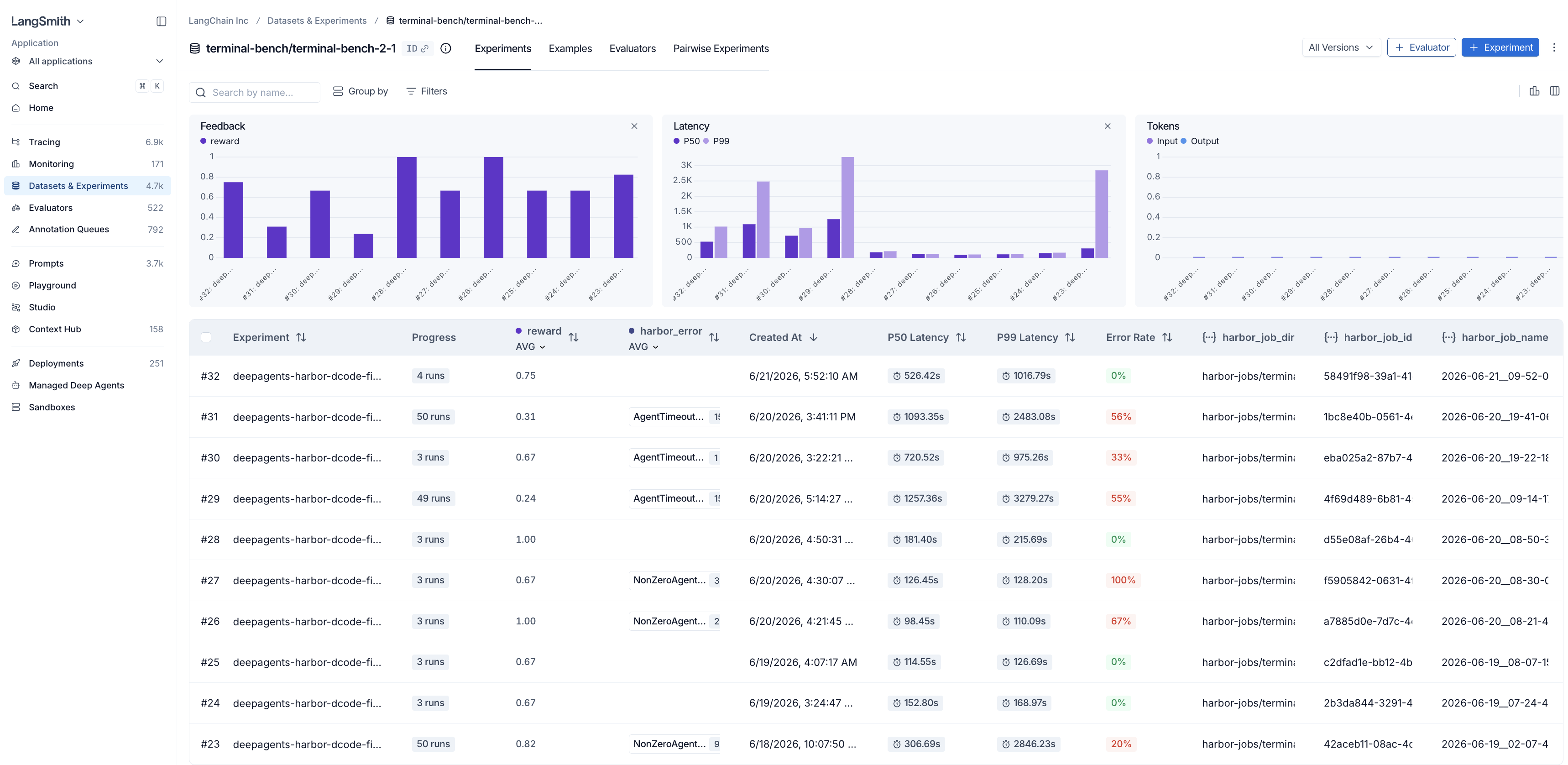
실험(experiment)은 특정 데이터셋에 대한 전체 실행(run)을 의미합니다. 특정 데이터셋에 대한 구체적인 실험과 각각의 점수 및 통계를 보려면 해당 데이터셋을 클릭하십시오.
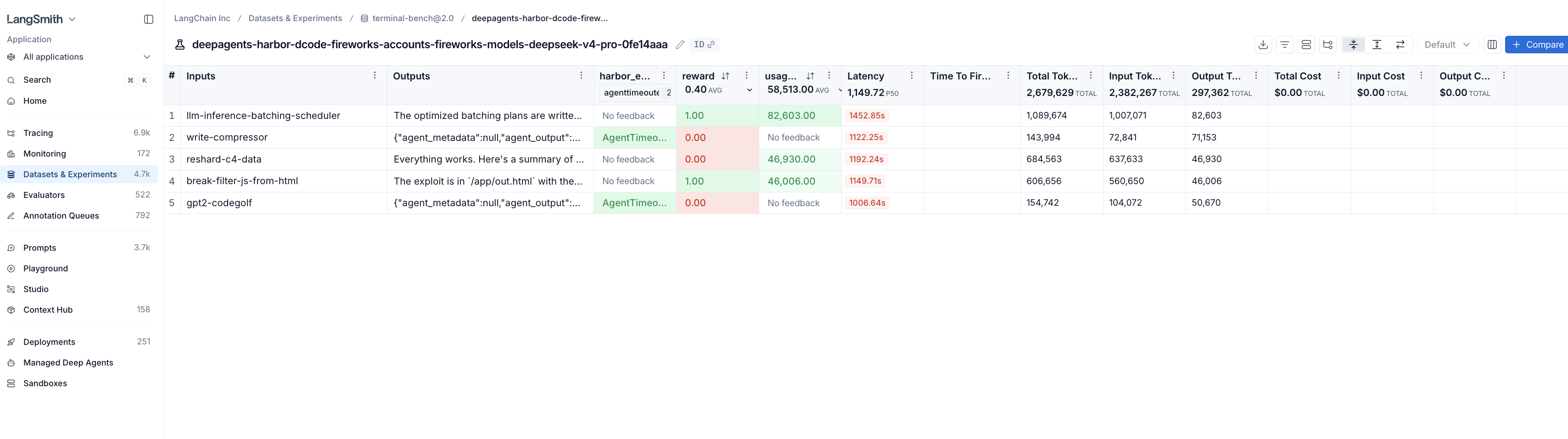
우리는 트레이스(traces)를 평가(evals)에 통합함으로써 평가를 더욱 정교하게 만들 수 있고, 결과적으로 에이전트를 더 잘 이해하고 개선할 수 있다고 믿습니다. 점수는 시행(trial)이 통과했는지 여부(whether)를 알려주지만, 트레이스(trace)는 그 이유(why)를 알려줍니다.
결과: 에이전트를 위한 완전한 평가 스택
이들을 모두 합치면, 각 계층이 하나의 작업을 잘 수행하는 에이전트 평가를 위한 완전한 스택이 됩니다:
Harbor - 테스트를 오케스트레이션(orchestrate)하는 평가 하네스 (eval harness).
Deep Agents - 테스트 대상인 에이전트를 구축하기 위한 도구.
LangSmith sandboxes - 격리된 클라우드 실행 환경.
LangSmith - 데이터셋, 실험, 트레이스 (traces), 그리고 점수 (scores)를 기록하는 시스템.
그리고 사용자가 준비해야 할 부분은 최소화됩니다:
사용자의 에이전트 - 트레이싱 (tracing) 여부와 상관없이.
사용자의 데이터셋 - 레지스트리(registry)에 원격으로 있거나 디스크에 로컬로 존재.
사용자의 클라우드 샌드박스 — -e langsmith 옵션을 사용한 LangSmith.
사용자의 UI 뷰 — --plugin langsmith 옵션.
LangSmith 계정과 데이터셋이 있다면, LangSmith 샌드박스 환경과 평가 플러그인 (eval plugin)을 모두 제공하는 langsmith extra를 포함하여 Harbor를 설치함으로써 전체 과정을 시도해 볼 수 있습니다. 그런 다음 LangSmith 및 모델 자격 증명 (credentials)을 설정하고, 에이전트의 트레이스 (traces)가 실험에 연결되도록 트레이싱 (tracing)을 활성화하십시오:
pip install "harbor[langsmith]"
export LANGSMITH_API_KEY="<LANGSMITH_API_KEY>"
export LANGSMITH_PROFILE=prod
...
harbor run \
--agent langgraph \
--model fireworks:accounts/fireworks/models/glm-5p2 \
# agent
...
시작하려면 Harbor 통합 문서를 읽어보세요. Harbor에서 평가를 실행하는 방법에 대한 자세한 내용은 Run evals를 참조하십시오.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기