HackerRank가 ATS를 오픈 소스로 공개했습니다. 제 이력서 점수는 90/100점이었으나, 아니 74점, 아니 88점, 사실은
요약
HackerRank가 공개한 오픈 소스 ATS(지원자 추적 시스템)를 테스트한 결과, LLM 기반 채점의 심각한 비결정성을 확인했습니다. 동일한 이력서임에도 LLM의 판단에 따라 점수가 크게 요동치며, 이는 채용 과정이 운에 좌우될 수 있음을 시사합니다.
핵심 포인트
- HackerRank의 오픈 소스 ATS는 LLM을 활용해 이력서를 파싱하고 채점함
- 동일한 입력값에도 불구하고 LLM의 비결정성으로 인해 점수 변동폭이 매우 큼
- 기술 스택 체크리스트는 일관적이나, 프로젝트 평가 항목에서 큰 변동성 발생
- Temperature를 낮추더라도 LLM의 근본적인 비결정성 문제는 해결되지 않음
HackerRank가 ATS를 오픈 소스로 공개했습니다. 제 이력서 점수는 90/100점이었으나, 아니 74/100점, 아니 — 88/100점, 사실은 83/100점이었습니다.
채용이 어떻게 운의 필터가 되어가고 있는가.
HackerRank가 공개한 이 오픈 소스 ATS (Applicant Tracking System, 지원자 추적 시스템)가 최근 큰 화제가 되고 있습니다: https://github.com/interviewstreet/hiring-agent
이 도구는 LinkedIn과 Reddit에서 수백, 때로는 수천 개의 좋아요를 받으며 등장했습니다.1 며칠 전 동료가 지나가는 말로 저에게 이 이야기를 해주었습니다.
저는 이것을 테스트해 보기로 했습니다.
첫 번째 실행 결과: 90/100. 기분이 꽤 좋았습니다!
설정 과정에서 문제를 해결하기 위해 여기저기 흩어놓았던 디버그 출력(debug prints)들이 있어서, 그것들을 정리하고 다시 실행했습니다.
74/100.
동일한 이력서. 동일한 명령어. 제가 바꾼 유일한 것은 print 문을 삭제한 것뿐이었습니다.
저는 DEVELOPMENT_MODE를 비활성화하고
백 번 실행되도록 루프(loop)에 넣었습니다.
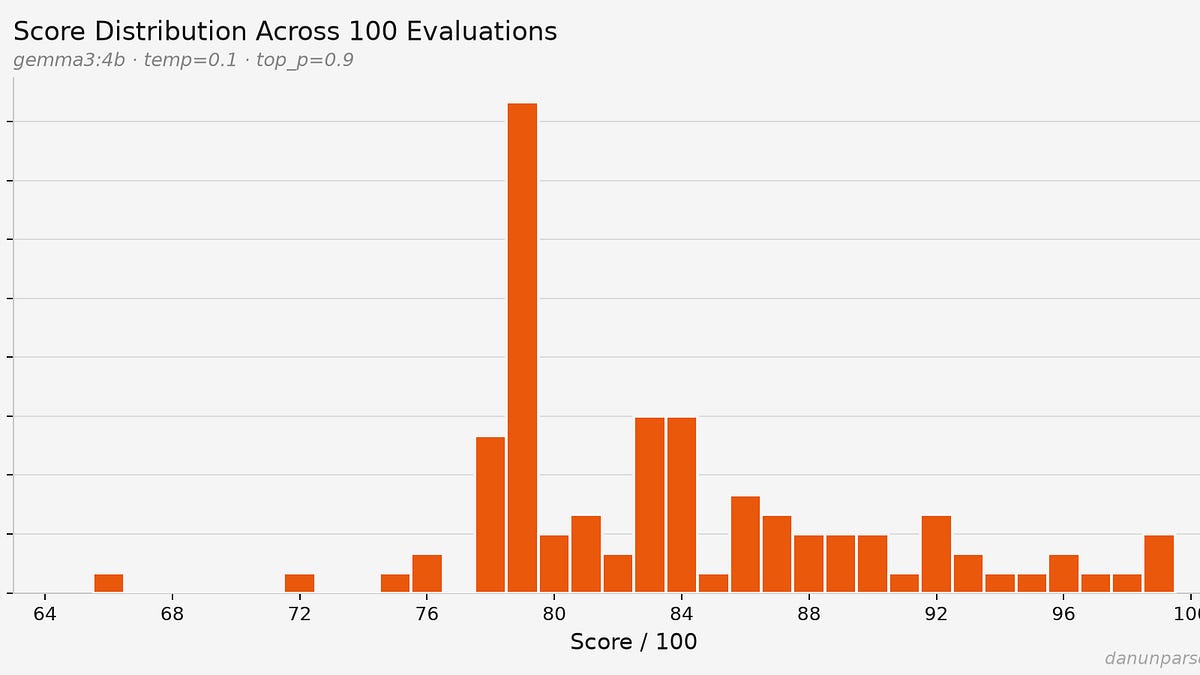
점수는 66점에서 99점 사이를 오갑니다.
만약 귀사의 합격 커트라인이 85점이라면, 저는 65%의 확률로 탈락합니다. 완전히 동일한 이력서임에도 불구하고, 운에 따라 결과가 달라집니다.
이 도구가 어떻게 작동하는지에 대한 간략한 요약은 다음과 같습니다:
사용자의 PDF가 텍스트로 파싱(parsing)됩니다. LLM (Large Language Model, 거대 언어 모델)이 6번 호출되어 기본 정보, 경력, 학력, 기술, 프로젝트, 수상 경력과 같은 구조화된 정보를 추출합니다. 또한 사용자의 GitHub 프로필을 가져오고, 주요 리포지토리(repos)를 스캔하여 추가적인 컨텍스트(context)로 덧붙입니다. 그 다음 모든 정보가 한꺼번에 LLM에 입력되어 채점됩니다.
점수는 100점 만점이며, 여기에 최대 20점의 보너스 점수가 추가됩니다:
오픈 소스 기여도 35점
개인 프로젝트 30점
경력 사항 25점
기술적 기술(technical skills) 10점
스타트업 경험, 포트폴리오 사이트, 기술 블로그 등에 대해 최대 20점의 보너스 점수
기본 모델은 gemma3:4b이며, temperature(온도) 0.1로 실행됩니다. 이는 낮은 수치로, 모델이 결정론적(deterministic)인 출력을 내도록 유도하기 위함입니다.
각 개별 카테고리를 살펴보았을 때 제가 발견한 사실은 다음과 같습니다.
기술적 기술(technical skills) 항목을 보십시오. 100번의 실행 중 98번에서 10점 만점에 8점을 받았습니다. 거의 완벽한 일관성입니다. 왜 그럴까요? 기술적 기술은 체크리스트이기 때문입니다. React를 알거나 모르거나 둘 중 하나입니다. LLM이 판단할 여지가 없습니다. 다섯 살 아이라도 이 체크리스트를 맞출 수 있을 것입니다.
이제 프로젝트(projects)를 보십시오. 여기에는 엄청난(HUGE) 변동성이 존재합니다.
LLM은 그러한 판단을 일관되게 내리는 데 어려움을 겪습니다. 어떤 때는 제 프로젝트가 "아키텍처 복잡성(architectural complexity)이 부족하다"고 하고, 어떤 때는 "실제 환경 배포(real-world deployment)를 입증한다"고 합니다. LLM이 어떤 결과를 내뱉을지는 주사위 던지기와 같습니다.
Temperature(온도) 0.1은 이미 낮은 수치이지만, Temperature 0까지 낮춘다고 해도 이 문제는 해결되지 않습니다. 지난 10월, 누군가가 GitHub issue를 통해 Temperature 0.2 환경에서 6회 연속 실행했을 때 각각 27, 34, 32, 34, 34, 30점을 받은 사례를 공개했습니다. 이러한 비결정성(non-determinism)은 단순히 미세 조정(fine-tune)으로 해결할 수 있는 버그가 아니라, 근본적인 설계 결함입니다.
저는 이 문제의 일부가 모델 때문일 수도 있다고 걱정했습니다. 결국 gemma3:4b는 제 컴퓨터에서 실행되는 로컬 모델이었으니까요.
Gemini는 더 좁은 분포(tighter distribution)를 보였습니다. 점수가 48점에서 64점 사이에 밀집되어 있었습니다. 하지만 커트라인이 60점이라면, 당신의 잘못이 없음에도 불구하고 여전히 28%의 확률로 탈락하게 됩니다.
오픈 소스(Open Source) 점수는 일관성을 갖게 되었습니다. 이는 정당한 개선입니다. 하지만 프로젝트 점수는 여전히 제각각입니다.
경력(Experience) 항목이 저를 가장 걱정하게 만듭니다.
25/25.
매 실행마다 말입니다.
저는 예전 이력서를 다시 꺼내 보았습니다. 인턴십 경험이 하나 포함된 이력서였습니다.
그것 역시 25/25였습니다.
힌트는 프롬프트(prompt)에 있습니다...
### Production (0-25 points)
- 'work' 및 'volunteer' 섹션을 분석하여 실제 업무, 인턴십 또는 프로덕션(production) 경험이 있는지 확인하십시오.
- **특별 고려 사항**: 스타트업의 창업자(founder) 역할, 공동 창업자(co-founder) 직책, 또는 초기 단계 엔지니어 역할(초기 10-20명 직원)에 대해 추가 점수를 부여하십시오.
전체 내용이 단 두 줄뿐입니다.
채점 기준(rubric)도 없습니다. 예시도 없습니다. 15점을 받는 것과 25점을 받는 것을 가르는 기준점(anchors)도 없습니다.
인턴십이 하나 있는 주니어 엔지니어도 25/25를 받습니다. 분산 시스템(distributed systems) 분야에서 10년의 경력을 가진 수석 엔지니어(principal engineer)도 25/25를 받습니다. 저도 25/25를 받습니다. 경력 항목은 두 줄뿐이고 기준점도 없기에 일관적이지만 쓸모가 없습니다. 프로젝트 항목은 예시와 함께 상세한 채점 기준이 있지만 가장 노이즈가 심한 카테고리이며, 일관성이 없어 이 또한 쓸모가 없습니다. 프롬프트를 어떻게 작성하든 LLM이 그냥 잘 해내지 못하는 것들이 있습니다.
LLM을 사용하여 이력서를 구조화된 데이터 (structured data)로 파싱하는 것 — 좋습니다, 그건 그들이 잘하는 일입니다. LLM을 사용하여 누군가가 Python을 아는지 확인하는 것 — 놀랍죠. 하지만 LLM을 사용하여 후보자의 경력이 18점의 가치가 있는지 아니면 24점의 가치가 있는지 판단하게 한다고요? 당신은 그저 '느낌적인 느낌 (vibe-check)'을 받게 될 뿐입니다. 이는 인사(HR) 팀, 채용 기준 강화자 (bar raisers), 그리고 수십 가지의 다른 이니셔티브들이 수십 년 동안 피하려고 노력해 온 것입니다.
오픈 소스 (open source) + 프로젝트에 65%의 가중치를 두는 것 또한 도움이 되지 않습니다. 저는 S3를 구축한 30년 경력의 엔지니어를 두 번의 인턴십과 하나의 오픈 소스 프로젝트를 가진 사람보다 선호하겠지만, 이 도구는 그렇지 않을 것입니다. 제가 아는 최고의 엔지니어 중 일부는 GitHub에 올라가지 않은 것들을 만들어 왔습니다. 이는 어떤 사람이 이력서를 검토하기도 전에 그들의 점수 절반 이상이 사라진다는 것을 의미합니다.
만약 당신이 회사의 이력서 스크리닝 (resume screening) 방식을 결정할 권한이 있는 엔지니어라면: AI 스크리닝 도구를 매우 주의해서 다뤄주십시오. 차별화할 수 없는 도구는 품질을 필터링하는 것이 아니라, 그저 필터링만 할 뿐입니다. 차라리 이력서의 절반을 그냥 버리고 지원자들에게는 운이 없어서 안 된다고 말하는 게 나을 정도입니다.
수정 사항 (6월 28일): 한 독자가 resume_evaluation_criteria.jinja 템플릿의 1번 라인에 "Software Intern"이라고 적혀 있음을 지적했습니다. 이는 문서화된 적도 없고, 저장소(repo)의 다른 곳에서도 참조되지 않았습니다. 이 템플릿은 나중에 "창업자 역할 (founder roles), 공동 창업자 직책 (co-founder positions), 또는 초기 단계 엔지니어 역할 (early-stage engineer roles)"에 대해 가산점을 부여합니다. 명시적인 시니어 소프트웨어 엔지니어 (Senior SWE) 프롬프트를 사용하여 다시 실행해 보았으나 동일한 결과가 나왔습니다 — 즉, 점수 산정 기준은 직책에 관계없이 동일하게 적용됩니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기