
【G검정 대책】 음성 처리의 중요 용어를 「AI 처리 플로우」로 체계적으로 정리하기
요약
G검정 대비를 위해 음성 처리의 핵심 용어를 AI 처리 플로우에 따라 체계적으로 정리한 가이드입니다. 태스크 정의부터 신호 처리, 특징량 추출, 모델링까지의 5단계 과정을 설명합니다.
핵심 포인트
- 음성 처리의 5단계: 태스크, 소리 구조, 신호 처리, 특징량, 모델
- 신호 처리의 핵심: ADC 변환 및 FFT를 통한 주파수 데이터 변환
- 주요 특징량: 음성 인식의 핵심인 MFCC와 멜 스케일 이해
- 음성 관련 태스크: 음성 인식, 합성(TTS), 화자 식별 등
G검정(제너럴리스트 검정) 학습에 있어, 음성 처리 분야는 전문 용어가 많아 혼란스러워하기 쉬운 포인트 중 하나입니다.
본 기사에서는 단순히 용어를 나열하는 것이 아니라, **「AI가 음성을 처리할 때의 흐름」**에 따라 체계적으로 정리했습니다.
학습 시 「지금 어느 단계의 이야기를 하고 있는가」를 의식함으로써 이해를 원활하게 할 수 있습니다.
음성 처리는 크게 다음과 같은 5가지 단계로 구성됩니다.
【태스크 (Task)】: 무엇을 하고 싶은가 (목적) -
【소리의 구조】: 다루는 「소리·언어」의 기초 지식 -
【신호 처리 (Signal Processing)】: 아날로그에서 디지털로, 그리고 주파수로 (전처리) -
【특징량 (Feature)】: AI가 학습하기 쉬운 형태로 가공 -
【모델 (Model)】: AI 알고리즘에 의한 학습·추론
먼저, 음성 처리로 무엇을 실현하고 싶은지 분류합니다.
| 용어 | 해설 |
|---|---|
| 음성 처리 | 음성과 관련된 기술의 총칭. |
| 음성 인식 | 음성을 텍스트(문자)로 변환하는 태스크. (예: 자동 받아쓰기) |
| 음성 합성 | 텍스트로부터 음성을 생성하는 태스크 (TTS). (예: 카 내비게이션 안내) |
| 화자 식별 | 목소리의 주인공이 누구인지 특정하는 태스크. (예: 목소리를 통한 생체 인증) |
인간이 발하는 언어나 소리의 최소 단위에 대한 정의입니다.
음소 (Phoneme)- 물리적인 소리의 최소 단위. (예: 「아」 소리, 영어의 「L」과 「R」의 차이)
음운 (Phonology)- 의미를 구별하는, 뇌 내에서 인식되는 추상적인 최소 단위.
- 일본어의 「ん」은 뒤에 이어지는 말에 따라 발음이 변하지만 (음소가 다름), 의미상으로는 동일함 (음운).
마이크로 포착한 아날로그 소리를 컴퓨터가 다룰 수 있는 형태로 변환하는 단계입니다.
A-D 변환 (ADC)- 연속적인 「아날로그 신호」를 이산적인 「디지털 신호」로 변환하는 처리.
펄스 부호 변조기 (PCM)- A-D 변환의 대표적인 방식. 표본화, 양자화, 부호화 순서로 디지털화함.
고속 푸리에 변환 (FFT)- 시간에 따라 변화하는 「파형 데이터」를 어떤 높이의 소리가 얼마나 포함되어 있는지에 대한 「주파수 데이터」로 고속 변환하는 알고리즘.
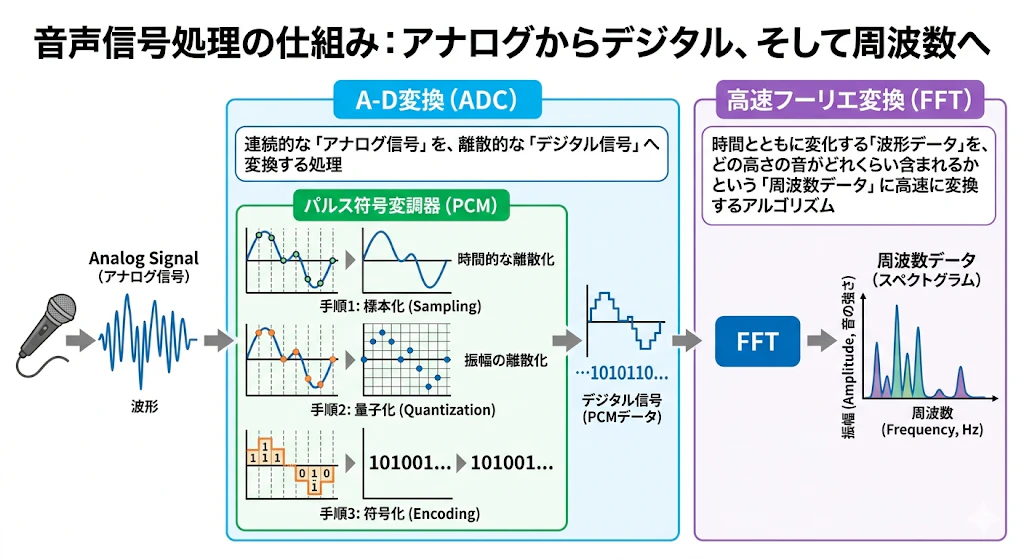
※ 이미지는 처리의 전체상을 이해하기 위한 이미지입니다. 엄밀한 파형이나 전문적인 회로도를 나타내는 것은 아닙니다.
FFT로 얻은 데이터를 더욱 인간의 들리는 방식이나 목소리의 특징에 특화된 수치로 변환합니다.
스펙트럼 포락선 (Spectral Envelope)- 주파수 데이터의 세밀한 굴곡을 이은 대략적인 윤곽. 여기에 「목소리의 음색」이나 「모음」의 정보가 포함됨.
포먼트 (Formant, 포먼트 주파수)- 스펙트럼 포락선에 있는 「산의 솟아오름」을 말함. 낮은 쪽부터 제1포먼트(F1)...라고 부르며, 그 조합으로 「아 이 우 에 오」를 판별할 수 있음.
멜 스케일 (Mel Scale)- 인간의 청각(낮은 소리에는 민감, 높은 소리에는 둔감)에 맞춘 주파수의 척도.
멜 주파수 케프스트럼 계수 (MFCC)- 멜 스케일을 이용하여 추출되는, 음성 인식에서의 가장 대표적인 특징량.
추출된 특징량을 사용하여 최종적인 예측이나 생성을 수행하는 핵심부입니다.
은닉 마르코프 모델 (HMM)- 시계열 데이터를 확률적으로 다루는 모델. 딥러닝 이전 음성 인식의 주류.
WaveNet- CNN (합성곱 신경망)을 이용한 음성 생성 모델.
- 매우 고품질이며 자연스러운 음성 합성을 실현함 (Google DeepMind 개발).
음성 처리 용어는 다음과 같은 흐름으로 이어져 있습니다.
아날로그 소리 (PCM)
↓ FFT로 변환
주파수 데이터
↓ 특징 추출
MFCC (멜 스케일 이용)
↓ 모델 학습
HMM이나 WaveNet
↓
음성 인식·음성 합성 실현!
이 흐름을 파악해 둠으로써 「어느 페이즈의 기술인가」를 혼동하지 않게 될 것이라 생각합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기