
Group DRO 논문 해설: 과잉 매개변수화 모델의 최악 그룹 일반화
요약
Sagawa et al.의 논문을 통해 과잉 매개변수화된 모델에서 Group DRO 적용 시 정규화의 중요성을 분석합니다. 가짜 상관관계로 인한 그룹 시프트 문제를 해결하기 위해 최악 그룹의 손실을 최소화하는 메커니즘을 다룹니다.
핵심 포인트
- 가짜 상관관계(spurious correlation)가 그룹 시프트의 주요 원인임
- 과잉 매개변수화 모델은 훈련 데이터의 최악 그룹 손실을 쉽게 낮출 수 있음
- 훈련 손실 감소가 반드시 테스트 시 최악 그룹 성능 향상으로 이어지지는 않음
- 최악 그룹 일반화를 위해서는 적절한 정규화(regularization)가 필수적임
Group DRO 논문 해설: 과잉 매개변수화 모델의 최악 그룹 일반화
본 기사에서는 Sagawa et al.의 논문 Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization을 해설한다.
이 논문은 Group DRO를 과잉 매개변수화(over-parameterized)된 뉴럴 네트워크(neural network)에 적용할 때, 단순히 worst-group training loss를 최소화하는 것만으로는 불충분하며, worst-group generalization에는 정규화(regularization)가 중요하다는 것을 보여준 연구이다.
머신러닝(machine learning) 모델은 통상적으로 훈련 데이터상의 평균 손실(average loss)을 작게 하도록 학습된다. 이 목적은 독립 동일 분포(independent and identically distributed; i.i.d.) 테스트 세트에서 높은 평균 정확도를 얻는다는 표준적인 평가 설정과 대응한다. 즉, 많은 머신러닝 모델은 훈련 분포와 테스트 분포가 동일하다는 전제하에, 평균적으로 좋은 예측을 수행하도록 설계되어 있다.
하지만 평균 정확도가 높다는 것이 모든 데이터 그룹에서 성능이 높다는 것을 의미하지는 않는다. 데이터 중에 희귀하고 비전형적인 그룹이 존재하는 경우, 모델은 평균적으로는 고정밀도일지라도 해당 그룹에 대해서는 일관되게 실패할 수 있다. 이 문제는 모델이 **가짜 상관관계 (spurious correlation)**에 의존하고 있을 때 현저하게 나타난다.
가짜 상관관계란, 훈련 데이터 중 많은 예시에서는 라벨(label)과 상관되어 있지만, 예측 대상의 본질적인 특징은 아닌 속성을 말한다. 예를 들어, 자연어 추론(natural language inference)에서는 never와 같은 부정어의 존재가 '모순'이라는 라벨과 강하게 상관되어 있는 경우가 있다. 이때 모델은 문장의 의미적 관계 그 자체가 아니라, 부정어의 유무를 단서로 예측할 가능성이 있다. 그러한 모델은 i.i.d. 테스트 세트상에서는 높은 평균 정확도를 보일 수 있다. 하지만 부정어를 포함하지 않는 모순문처럼, 그 가짜 상관관계가 성립하지 않는 그룹에서는 크게 실패한다.
본 논문이 다루는 문제 설정은 이러한 가짜 상관관계에 기인하는 **그룹 시프트 (group shift)**이다. 훈련 시에는 라벨

*Figure 1. 본 논문에서 다루는 데이터셋에서의 대표적인 훈련 예시와 테스트 예시. 훈련 시에 존재하는 라벨 *
이러한 문제에 대해 자연스러운 방침은 평균 손실이 아니라, 그룹별 최악 케이스 손실(worst-case loss)을 작게 만드는 것이다. 이에 본 논문에서는 Distributionally Robust Optimization (DRO)의 일종인 Group DRO를 사용한다. Group DRO는 사전에 정의된 그룹 집합에 대해, 최악 그룹의 훈련 손실을 최소화하도록 모델을 학습한다.
단, 본 논문의 주장은 "Group DRO를 사용하면 최악 그룹 성능이 개선된다"라는 단순한 것이 아니다. 오히려 중요한 것은, 과잉 매개변수화된 뉴럴 네트워크에 naive하게 Group DRO를 적용해도 실패할 수 있다는 관찰이다. 과잉 매개변수화 모델은 훈련 데이터를 완전히 피팅(fit)할 수 있다. 따라서 평균 훈련 손실이 소멸하는 모델은 이미 최악 케이스 훈련 손실도 소멸시킨 상태이다. 다시 말해, 훈련 데이터상에서는 ERM과 Group DRO의 차이가 보이기 어려워진다.
이때 문제가 되는 것은 최악 그룹의 훈련 손실이 아니다. 모델은 훈련 시에는 최악 그룹조차 거의 완벽하게 분류하고 있다. 그럼에도 불구하고 테스트 시의 최악 그룹 성능은 낮다. 따라서 문제의 본질은 worst-group training loss가 아니라, **그룹별 일반화 갭 (generalization gap)**에 있다.
본 논문은 이 지점에서 정규화의 중요성을 보여준다. 과잉 매개변수화 영역에서는 평균 일반화 관점에서는 강한 정규화가 불필요해 보일 수 있다. 하지만 최악 그룹 일반화를 고려하면, 통상적인 경우보다 더 강한
본 기사에서는 먼저 ERM, DRO, Group DRO의 정식화를 정리한다. 다음으로 Group DRO가 보고 있는 리스크(risk)를 명확히 한 뒤, 과잉 매개변수화 모델에서 naive Group DRO가 실패하는 이유를 설명한다. 그 후 정규화, group adjustment, importance weighting과의 차이점, 최적화 알고리즘, 실험 결과 순으로 살펴본다.
1. Setup: ERM, DRO, Group DRO
입력 특징량
とする。ここで、
표준적인 지도 학습 (Supervised Learning)에서는 동일한 분포
를 최소화하는 모델
ERM은 훈련 데이터상의 평균 손실 (Average Loss)을 최소화하는 방법이다. 따라서 훈련 분포와 테스트 분포가 동일하고, 평가 지표도 평균 성능인 경우에는 자연스러운 목적 함수 (Objective Function)이다.
하지만 본 논문이 다루는 문제에서는 테스트 시에 훈련 분포와 동일한 혼합비 (Mixing Ratio)로 데이터가 나타난다고 보장할 수 없다. 특히, 훈련 데이터 중에서는 다수파인 그룹이 테스트 시에도 지배적이라고 할 수 없으며, 훈련 데이터상에서는 희귀한 그룹이 테스트 시에 중요해질 가능성이 있다. 이러한 분포 변화 (Distribution Shift)를 다루기 위해, 분포 로버스트 최적화 (Distributionally Robust Optimization; DRO)를 고려한다.
DRO에서는 단일 훈련 분포에 대한 평균 손실이 아니라, 분포의 불확실성 집합 (Uncertainty Set)
여기서,
일반적으로는 훈련 분포 주변의 다이버전스 구 (Divergence Ball)로서
따라서 본 논문에서는 의사 상관 (Spurious Correlation)에 관한 사전 지식을 사용하여 훈련 데이터를 그룹으로 분할하고, 그 그룹에 기반하여 불확실성 집합
훈련 분포
여기서,
이다.
이 정의에서 잠재적인 테스트 분포는 그룹 분포 그룹 간의 혼합비가 변하는 group shift를 다루는 방법이다.
이때, DRO의 최악 사례 리스크 (Worst-case Risk)는 각 그룹에서의 기대 손실 (Expected Loss)의 최댓값으로 표현된다.
즉, Group DRO는 평균 리스크가 아니라, 가장 손실이 큰 그룹의 리스크를 작게 만든다. ERM이 훈련 분포상의 평균 손실을 최소화하는 것에 반해, Group DRO는 그룹별 손실의 최댓값을 최소화한다.
실제로는 진정한 그룹 분포
경험적인 (Empirical) Group DRO의 목적 함수는 다음과 같다.
여기서,
식 (4)는 훈련 데이터상에서 가장 손실이 큰 그룹을 기준으로 모델을 학습하는 것을 의미한다. 따라서 Group DRO는 그룹 간에 양호한 최악 그룹 훈련 손실 (Worst-group Training Loss)을 갖는 모델을 학습하는 방법이다.
단, 여기서 주의해야 할 점이 있다. Group DRO가 직접 최소화하고 있는 것은 어디까지나 경험적인 최악 그룹 리스크 (Empirical Worst-group Risk)
따라서 Group DRO를 통해 양호한 최악 그룹 훈련 손실을 얻었다 하더라도, 그것만으로 양호한 최악 그룹 테스트 손실 (Worst-group Test Loss)이 보장되는 것은 아니다. 이 점이 본 논문의 핵심적인 문제 의식이다. 특히, 과잉 매개변수화된 (Over-parameterized) 신경망에서는 충분한 정규화 (Regularization)를 적용하지 않는 한, 이 일반화 갭 (Generalization Gap)이 커질 수 있다.
왜 Group DRO의 최악 사례 리스크는 그룹 리스크의 최댓값이 되는가
Group DRO에서는 불확실성 집합을
라고 정의한다. 따라서 DRO의 최악 사례 리스크는
이다. 이
로서 표현되기 때문에,
여기서 각 그룹의 리스크를
라고 두면,
를 평가하면 된다.
이는
따라서,
이다. 즉,
가 된다. 이것이 식 (3)이다.
소문자
는 그룹 혼합비를 나타내는 벡터이며, q는 그 혼합비에 의해 결정되는 하나의 분포이다. Q는 그러한 분포 $\mathcal{Q}$를 모두 모은 불확실성 집합이다. Q
2. Group DRO가 보고 있는 리스크
전 장에서는 ERM, DRO, Group DRO의 정식화를 살펴보았다. ERM은 훈련 데이터상의 평균 손실을 최소화한다. 반면, Group DRO는 그룹별 손실의 최댓값을 최소화한다.
여기서 중요한 것은 Group DRO가 "무엇을 보고 있는가"이다. Group DRO는 그룹 레이블
본 논문에서는 각 훈련 점이 어느 그룹에서 유래했는지 알고 있다고 가정한다. 즉, 훈련 데이터는
의 삼중항 (Triplet)으로 구성된다. 단, 테스트 시에는
따라서 Group DRO가 보고 있는 리스크는 입력
이며, Group DRO는 그 최댓값
을 문제 삼는다.
즉, Group DRO는 "평균적으로 좋은 모델"이 아니라, "가장 나쁜 그룹에서도 너무 나빠지지 않는 모델"을 구한다. 이 목적은 훈련 데이터 중의 다수파 그룹에 끌려가는 ERM과는 다르다.
그룹은 어떻게 정의되는가
본 논문에서 다루는 3가지 응용 사례에서는 각 데이터 점이
를 갖는다고 생각한다. 이
그룹은 의사 속성 (Spurious Attribute)
의 각 값에 대응하여 그룹을 만든다. 따라서 그룹 수는
이다.
이 정의의 의미는 단순히 속성
예를 들어, Waterbirds에서는 레이블(label)이 새의 종류이며, 가상 속성(spurious attribute)은 배경입니다. waterbird는 water background 위에, landbird는 land background 위에 나타나기 쉽도록 훈련 데이터가 구성됩니다. 이때 모델은 새 그 자체가 아니라 배경에 의존하여 분류할 가능성이 있습니다.
CelebA에서는 레이블이 머리카락 색상이며, 가상 속성은 성별입니다. 머리카락 색상과 성별이 훈련 데이터 상에서 상관관계가 있는 경우, 모델은 머리카락 색상 그 자체가 아니라 성별에서 유래하는 특징을 이용해 버릴 가능성이 있습니다.
MultiNLI에서는 레이블이 entailment, neutral, contradiction 중 하나이며, 가상 속성은 부정어의 유무입니다. 훈련 데이터 중에서 부정어와 contradiction이 상관관계가 있는 경우, 모델은 문장의 의미적 관계가 아니라 부정어의 유무에 의존할 가능성이 있습니다.
이 구조를 정리하면 다음과 같습니다.
| 데이터셋 | 레이블 | 가상 속성 | 그룹 |
|---|---|---|---|
| Waterbirds | waterbird / landbird | water background / land background | 새 종류 |
| CelebA | blond / dark | male / female | 머리카락 색상 |
| MultiNLI | entailment / neutral / contradiction | no negation / negation | NLI 레이블 |
Figure 1에서 보여준 것은 이러한 구조입니다. 훈련 시에는, 레이블
Group DRO는 무엇을 방지하려고 하는가
ERM은 훈련 분포 상의 평균 손실(average loss)을 작게 만듭니다. 따라서 훈련 데이터 중에서 다수를 차지하는 그룹의 손실이 목적 함수(objective function)에 강하게 반영됩니다. 만약 다수 그룹에서 가상 상관관계(spurious correlation)가 유효하다면, ERM은 그 가상 상관관계를 이용하는 모델을 선택하기 쉽습니다.
반면, Group DRO는 그룹별 손실의 최댓값(maximum loss)을 작게 만듭니다. 그 때문에 특정 그룹에서 가상 상관관계가 성립하지 않아 손실이 커지는 경우, 해당 그룹이 목적 함수를 지배하게 됩니다. 모델은 그 그룹의 손실을 낮추지 않는 한, Group DRO 목적을 개선할 수 없습니다.
이런 의미에서 Group DRO는 가상 상관관계에 의존한 예측 규칙을 피하는 방향으로 작동합니다. 가상 상관관계는 다수 그룹에서는 유효할지라도, 소수 그룹이나 비전형적인 그룹에서는 무너집니다. 따라서 최악 그룹 손실(worst-group loss)을 낮추기 위해서는 가상 상관관계가 아니라, 그룹 간에 더 안정적인 특징(feature)을 사용해야 합니다.
다만, 이는 어디까지나 목적 함수 상의 기대치입니다. Group DRO가 최소화하는 것은 경험적 최악 그룹 리스크(empirical worst-group risk)입니다. 따라서 Group DRO는 최악 그룹의 훈련 손실을 직접 제어하지만, 최악 그룹의 테스트 손실을 직접 관측하고 있는 것은 아닙니다.
여기에 본 논문의 핵심적인 문제가 있습니다. Group DRO가 보고 있는 것은 worst-group training risk입니다. 반면, 우리가 정말로 원하는 것은 worst-group test risk입니다. 이 두 가지가 일치하기 위해서는 각 그룹에서 일반화 격차(generalization gap)가 충분히 작아야 합니다.
과잉 매개변수화(over-parameterized)된 뉴럴 네트워크에서는 이 점이 문제가 됩니다. 모델이 모든 그룹에 대해 훈련 데이터를 완전히 피팅(fit)할 수 있는 경우, Group DRO는 훈련 데이터 상에서는 잘 작동하는 것처럼 보입니다. 하지만 그것이 테스트 시의 최악 그룹 성능으로 이어진다는 보장은 없습니다. 다음 장에서는 이러한 naive Group DRO의 실패가 왜 발생하는지 자세히 살펴보겠습니다.
ERM과 Group DRO가 최소화하는 리스크의 차이
훈련 분포를 $P$라고 합시다. 여기서 $P = \sum_{g \in \mathcal{G}} P_g$라고 쓸 수 있습니다. 이때 ERM이 대상으로 하는 기대 손실(expected loss)은 $\mathbb{E}_{g \sim P} [\mathcal{L}_g]$입니다.
따라서 ERM은 그룹별 리스크를 훈련 분포 상의 혼합 비율 $P_g$에 따라 $\sum_{g \in \mathcal{G}} P_g \mathcal{L}_g$로 취급합니다.
반면, Group DRO는 $\max_{g \in \mathcal{G}} \mathcal{L}_g$를 최소화합니다.
두 방식의 차이는 그룹 리스크를 집계하는 방법에 있습니다. ERM은 $\sum_{g \in \mathcal{G}} P_g \mathcal{L}g$라는 가중 평균을 봅니다. 반면, Group DRO는 $\max{g \in \mathcal{G}} \mathcal{L}_g$를 봅니다.
그렇기 때문에 ERM에서는 샘플 수가 많은 그룹, 즉 $P_g$가 큰 그룹의 리스크가 중요하게 작용합니다.
이러한 차이로 인해, ERM은 평균 성능을 중시하는 목적 함수이며, Group DRO는 최악 그룹 성능을 중시하는 목적 함수라고 해석할 수 있습니다.
3. 과잉 매개변수화 모델에서 naive Group DRO가 실패하는 이유
앞 장까지에서 Group DRO는 평균 손실이 아니라, 그룹별 손실의 최댓값을 작게 만드는 목적 함수(Objective Function)임을 확인했다. 따라서 언뜻 보기에는 Group DRO를 사용하면 가상 상관(Spurious Correlation)에 의존하는 모델을 피하고, 최악 그룹 성능을 개선할 수 있을 것처럼 보인다.
하지만 본 논문의 중요한 주장은, 과잉 매개변수화(Over-parameterized)된 신경망에 naive하게 Group DRO를 적용하더라도 반드시 최악 그룹 성능이 개선되는 것은 아니라는 점이다.
그 이유는 과잉 매개변수화 모델이 훈련 데이터를 거의 완벽하게 피팅(Fit)할 수 있기 때문이다. 모델이 훈련 데이터상의 각 샘플을 거의 완벽하게 분류할 수 있다면, 평균 훈련 손실(Average Training Loss)은 작아진다. 동시에 각 그룹에서의 훈련 손실도 작아진다. 즉, 평균 훈련 손실이 소멸하는 모델은 이미 최악 그룹 훈련 손실도 소멸시킨 상태이다.
이러한 상황에서는 훈련 데이터상에서 ERM과 Group DRO의 차이가 보이지 않게 된다. ERM은 평균 훈련 손실을 작게 만든다. 반면, Group DRO는 최악 그룹 훈련 손실을 작게 만든다. 하지만 모델이 모든 훈련 데이터 포인트에 피팅될 수 있다면, 두 목적 함수 모두 동시에 작아진다.
따라서 과잉 매개변수화 영역에서의 문제는 worst-group training loss가 크다는 것이 아니다. 오히려 훈련 시에는 최악 그룹에서조차 높은 성능을 보임에도 불구하고, 테스트 시에는 최악 그룹 성능이 낮아지는 것이 문제이다. 이는 그룹별 일반화 격차(Generalization Gap)가 서로 다름을 의미한다.
3.1 ERM과 DRO는 모두 훈련 데이터에 피팅된다
본 논문에서는 Waterbirds와 CelebA에서는 ResNet50을, MultiNLI에서는 BERT를 사용하여 ERM과 Group DRO의 거동을 비교하고 있다. 이들은 각각 이미지 분류 및 자연어 추론(Natural Language Inference)에서 높은 평균 테스트 정확도를 달성하는 표준적인 모델들이다.
먼저, 표준적인 정규화(Regularization)와 하이퍼파라미터 설정 하에서 모델이 수렴할 때까지 훈련한다. 이 설정에서 ERM 모델은 3개의 데이터셋 모두에서 최악 그룹 훈련 정확도로 최소 99.9%라는 거의 완벽한 정확도를 달성한다. 또한, 평균 테스트 정확도도 Waterbirds, CelebA, MultiNLI에서 각각 97.3%, 94.8%, 82.5%로 높게 나타난다.
그러나 테스트 시의 최악 그룹 정확도는 각각 60.0%, 41.1%, 65.7%까지 떨어진다. 평균 테스트 정확도는 높음에도 불구하고, 최악 그룹에서는 크게 실패하고 있다.
Group DRO에서도 유사한 현상이 발생한다. ERM 모델은 거의 모든 훈련 데이터 포인트를 완벽하게 분류하고 있기 때문에, ERM 목적뿐만 아니라 DRO 목적에 대해서도 거의 최적(Optimal) 상태이다. 실제로 naive한 Group DRO 모델 역시 거의 완벽한 훈련 정확도와 높은 평균 테스트 정확도를 달성하는 한편, 최악 그룹 테스트 정확도는 낮다.
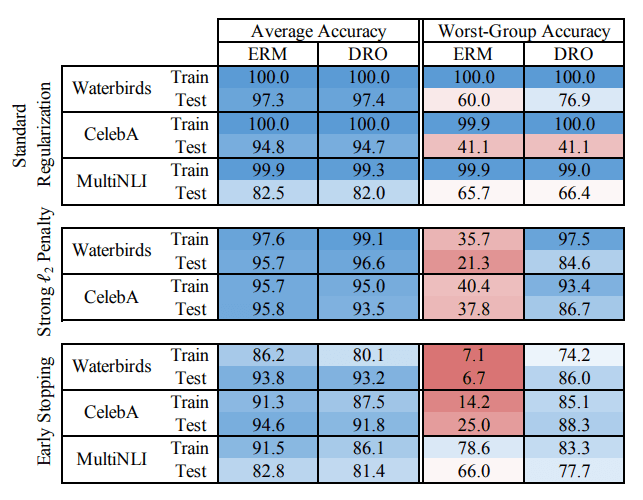
Table 1. 각 훈련 기법에서의 평균 정확도와 최악 그룹 정확도. 정규화가 없는 경우, ERM 모델과 DRO 모델 모두 최악 케이스 그룹에서 낮은 성능을 보인다.
Table 1의 상단이 이 현상을 보여준다. standard regularization 하에서는 ERM과 DRO 모두 높은 average accuracy를 보인다. 하지만 worst-group accuracy는 낮다. 이는 Group DRO가 최악 그룹 성능을 개선하도록 설계되었음에도 불구하고, 과잉 매개변수화 영역에서는 naive하게 적용했을 때 충분히 기능하지 않음을 보여준다.
단, 이것이 Group DRO의 목적 함수 자체가 무의미하다는 뜻은 아니다. 문제는 Group DRO가 최소화하고 있는 경험적 최악 그룹 리스크(Empirical Worst-group Risk)가 테스트 시의 최악 그룹 리스크와 일치하지 않는다는 점에 있다.
3.2 훈련 성능의 문제가 아니라, 일반화 격차의 문제이다
Figure 2는 CelebA에서의 훈련 중 그룹별 훈련 정확도와 검증(Validation) 정확도를 보여준다. 연한 색 선이 훈련 정확도이며, 진한 색 선이 검증 정확도이다.
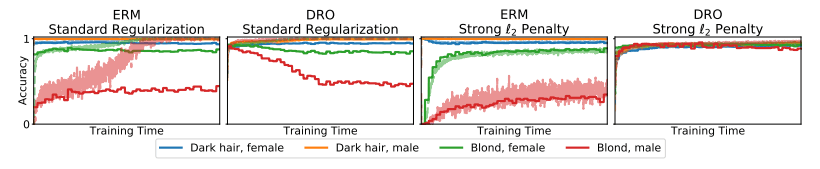
Figure 2. CelebA에서의 훈련 중 훈련 정확도와 검증 정확도. 기본 설정에서는 ERM과 DRO가 모든 그룹에서 완벽한 훈련 정확도를 달성하는 반면, 최악 케이스 그룹에는 나쁘게 일반화된다.
Figure 2의 왼쪽 패널을 보면, 기본 하이퍼파라미터로 수렴할 때까지 훈련했을 경우 ERM 모델과 DRO 모델 모두 모든 그룹에서 거의 완벽한 훈련 정확도를 달성한다. 하지만 검증 정확도를 보면, 최악 케이스 그룹의 성능은 낮다.
이는 최악 그룹에서의 훈련 성능이 낮은 것이 문제가 아니라는 점을 보여준다. 모델은 훈련 시에는 최악 그룹에서조차 거의 완벽하게 fit(적합)된다. 그럼에도 불구하고, 검증 시에는 해당 그룹에서 성능이 저하된다.
따라서 평균 테스트 정확도와 최악 그룹 테스트 정확도의 차이는 worst-group training performance의 문제가 아니다. 오히려 그룹별로 일반화 격차 (generalization gap)가 다르기 때문에 발생한다.
여기서 진정한 그룹 리스크 (true group risk)와 경험적 그룹 리스크 (empirical group risk)의 차이를 생각해보자. 그룹을 $g$라고 쓰자. 이때 경험적 그룹 손실이 작더라도, Group DRO가 직접 최소화하는 것은 $ ext{loss}_g^{ ext{emp}}$이다. 반면, 우리가 정말로 평가하고 싶은 것은 $ ext{loss}_g^{ ext{true}}$이다.
과잉 매개변수화 (over-parameterized) 모델에서는 $ ext{loss}_g^{ ext{emp}} o 0$ 이다.
이 때문에 naive Group DRO의 실패는, Group DRO가 바라보는 훈련상의 목적과 실제로 개선하고자 하는 테스트상의 목적 사이에 격차가 존재하기 때문에 발생한다.
3.3 왜 ERM과 naive DRO가 동일해 보이는가
ERM과 Group DRO는 본래 서로 다른 목적 함수 (objective function)를 가진다. ERM은 평균 훈련 손실을 최소화한다.
반면, Group DRO는 최악 그룹 훈련 손실을 최소화한다.
일반적인 상황이라면 평균 손실을 낮추는 해와 최악 그룹 손실을 낮추는 해는 다를 수 있다. 평균 손실을 낮추기 위해서는 다수파 그룹의 성능을 우선시하면 되는 반면, 최악 그룹 손실을 낮추기 위해서는 성능이 낮은 그룹을 개선해야 하기 때문이다.
하지만 과잉 매개변수화 모델에서는 훈련 데이터를 모든 그룹에서 거의 완벽하게 fit 할 수 있다. 이 경우 평균 훈련 손실도, 최악 그룹 훈련 손실도 동시에 작아진다. 따라서 훈련 데이터상에서는 ERM과 Group DRO의 목적 함수의 차이가 실질적으로 사라져 버린다.
이 관점에서 보면 naive Group DRO가 실패하는 이유는 명확하다. Group DRO는 최악 그룹 훈련 손실을 개선하기 위한 목적 함수이다. 그러나 과잉 매개변수화 영역에서는 최악 그룹 훈련 손실이 이미 작다. 따라서 Group DRO는 최악 그룹 테스트 성능을 개선하기 위한 추가적인 제약으로서 기능하기 어렵다.
필요한 것은 최악 그룹 훈련 손실을 작게 만드는 것만이 아니다. 최악 그룹 훈련 손실이 테스트 성능으로 이어지도록 그룹별 일반화 격차를 제어하는 것이다.
이 역할을 담당하는 것이 다음 장에서 다룰 정규화 (regularization)이다.
평균 훈련 손실이 사라지면 worst-group training loss도 사라진다
여기서는 과잉 매개변수화 모델에서 평균 훈련 손실이 소멸하는 모델이 최악 그룹 훈련 손실도 소멸시킨다는 것을 확인한다.
손실이 비음수 (non-negative)라고 가정하자. 즉, 임의의 훈련 점 $x$에 대해 $ ext{loss}(x) ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ } ext{ }
따라서 문제는 worst-group training loss가 아니다. 문제는 훈련 데이터(training data) 상에서 작은 worst-group training loss가 테스트 데이터(test data) 상의 worst-group performance로 이어지지 않는다는 것이다. 다시 말해, 문제의 본질은 group-wise generalization gap에 있다.
이 격차를 제어하기 위해 본 논문이 강조하는 것이 정규화 (regularization)이다. 여기서 말하는 정규화란 모델이 훈련 데이터를 완전히 fit 하는 것을 방지하고, 일반화 격차 (generalization gap)를 작게 만들기 위한 제약이다. 본 논문에서는 주로 강력한
$\ell_2$ 페널티 (penalty)
4.1 강력한 정규화
전통적으로 정규화는 모델군 (model family)의 훈련 데이터에 대한 적합 능력을 제한하고, 일반화 격차를 제어하기 위해 사용된다. 반면, 현대의 과잉 매개변수화 (over-parameterization) 영역에서는 명시적인 정규화가 평균 성능을 위해서는 필수적이지 않은 경우가 있다. 모든 정규화를 제거하더라도 모델이 평균적으로는 잘 일반화될 수 있기 때문이다.
하지만 본 논문이 보여주는 것은 평균 일반화와 최악 그룹 일반화(worst-group generalization)는 상황이 다르다는 점이다. 평균 성능을 위해서는 강력한 정규화가 불필요해 보일 때라도, 최악 그룹 성능을 위해서는 정규화가 중요해진다.
ResNet50에서의 표준적인 $\ell_2$ 정규화이며, 기본 계수(default coefficient)는 $\lambda$이다.
- 첫째, ERM 모델과 DRO 모델 모두 완전한 훈련 정확도(training accuracy)를 달성할 수 없게 된다.
- 둘째, 각 그룹의 일반화 격차가 대폭 작아진다.
이 변화가 중요하다. 정규화가 약하면 모델은 모든 그룹에서 훈련 데이터를 거의 완벽하게 fit 할 수 있다. 그 때문에 ERM과 DRO 모두 훈련 데이터 상에서는 높은 성능을 보인다. 그러나 테스트 시에는 최악 그룹에서 크게 실패한다.
반면, 강력한 $\ell_2$ 정규화는 모델이 훈련 데이터를 완전히 fit 하지 못하도록 강제한다.
ERM은 평균 훈련 정확도를 높이기 위해 다수파 그룹을 우선시한다. 그 결과, 희소 그룹의 훈련 성능을 희생시킨다. 실제로 강력한 $\ell_2$ 정규화 하에서 ERM은 평균 훈련 정확도는 높지만, 최악 그룹의 훈련 정확도는 낮다.
반면 DRO는 최악 그룹의 훈련 정확도를 높게 유지하도록 학습한다. 강력한 $\ell_2$ 정규화 하에서 DRO는 최악 그룹의 훈련 정확도와 테스트 정확도 모두를 높게 유지한다.
여기서 중요한 점은 DRO가 단독으로 효과를 내는 것이 아니라는 점이다. DRO는 최악 그룹 훈련 손실(training loss)을 낮추는 목적 함수(objective function)이다. 하지만 이것이 테스트 시의 최악 그룹 성능으로 이어지기 위해서는 그룹별 일반화 격차가 작아야만 한다. 강력한 정규화는 이 격차를 줄여줌으로써 DRO가 최악 그룹 성능을 개선할 수 있는 환경을 만든다.
Table 1의 중간 부분은 이 결과를 보여준다. 정규화가 약할 경우 ERM과 DRO 모두 worst-group accuracy가 낮다. 반면, 강력한 $\ell_2$ 정규화를 적용하면 DRO의 worst-group accuracy가 크게 향상된다.
Figure 2에서도 동일한 구조가 보인다. 강력한 $\ell_2$ 정규화는 ERM과 DRO 사이의 성능 차이를 극대화한다.
4.2 조기 종료 (Early Stopping)
본 논문에서는 또 다른 정규화 방법으로 조기 종료도 검토하고 있다. 조기 종료는 모델이 훈련 데이터를 완전히 fit 하기 전에 학습을 멈춤으로써 과적합 (overfitting)을 억제하는 암묵적 정규화 (implicit regularization)이다.
강력한 조기 종료는 모델이 훈련 데이터에 완전히 fit 하는 것을 방지한다.
본 논문에서는 Section 3.1과 동일한 설정을 사용하면서, 각 모델을 고정된 적은 수의 에포크 (epoch) 동안만 훈련시킨다. 이 설정에서도 DRO는 최악 그룹 테스트 정확도에서 ERM을 크게 앞선다.
구체적으로 조기 종료를 사용했을 때, 최악 그룹 테스트 정확도는 Waterbirds에서 6.7%에서 86.0%로, CelebA에서 25.0%에서 88.3%로, MultiNLI에서 66.0%에서 77.7%로 개선된다. 평균 테스트 정확도는 ERM과 DRO 모두 비슷하게 높지만, DRO에서는 1~3% 정도의 미미한 저하가 관찰된다.
여기서도 정규화의 역할은 명확하다. 조기 종료는 모델이 훈련 데이터를 완전히 fit 하는 것을 방지한다. 그러면 ERM과 DRO는 서로 다른 훈련상의 선택을 하게 된다. ERM은 평균 정확도를 위해 최악 그룹을 희생하기 쉽다. 반면 DRO는 최악 그룹을 개선하도록 학습한다.
정규화가 없다면 두 목적 함수 모두 훈련 손실이 0에 수렴해버리기 때문에 이러한 차이가 표면화되기 어렵다. 정규화를 통해 완전한 fit이 방해됨으로써, 비로소 ERM과 DRO의 목적 함수 차이가 실제 성능 차이로 나타나게 된다.
4.3 정규화는 Group DRO의 보조 도구가 아니라 실질적인 성립 조건이다
이상의 결과로부터 본 논문은 최악 그룹 일반화에 있어 정규화의 중요성을 강조한다. 여기서 주의해야 할 점은 정규화가 단순한 성능 개선 테크닉이 아니라는 점이다.
Group DRO는 경험적 최악 그룹 리스크 (empirical worst-group risk) $\hat{\mathcal{R}}{worst}$를 작게 만든다. 하지만 우리가 평가하고자 하는 것은 진정한 최악 그룹 리스크 (true worst-group risk) $\mathcal{R}{worst}$이다.
경험적 최악 그룹 리스크가 작다고 해서 진정한 최악 그룹 리스크가 반드시 작은 것은 아니다. 두 차이를 결정하는 것이 바로 그룹별 일반화 격차이다.
따라서, Group DRO가 효과적으로 작동하기 위해서는 다음의 두 가지가 동시에 필요하다.
- 첫 번째는, Group DRO를 통해 최악 그룹 훈련 손실 (worst-group training loss)을 작게 만드는 것이다.
- 두 번째는, 정규화 (regularization)를 통해 해당 훈련 손실이 테스트 손실 (test loss)로 이어지도록 일반화 격차 (generalization gap)를 억제하는 것이다.
정규화가 불충분할 경우, Group DRO는 경험적 최악 그룹 리스크 (empirical worst-group risk)를 작게 만들 수 있다. 하지만 일반화 격차가 크다면, 테스트 시의 최악 그룹 성능은 개선되지 않는다. 따라서, 과잉 매개변수화 (over-parameterized) 모델에서는 Group DRO와 정규화를 분리해서 생각할 수 없다.
이 점이 본 논문의 핵심적인 메시지이다. 평균 일반화 (average generalization) 측면에서 보면, 과잉 매개변수화 모델에 강력한 정규화는 불필요해 보일 때가 있다. 하지만 최악 그룹 일반화 (worst-group generalization)를 보면, 정규화는 여전히 중요하다. 즉, 평균 성능과 최악 그룹 성능은 동일한 일반화 현상을 보고 있는 것이 아니다.
worst-group test risk 와 group-wise generalization gap
Group DRO가 경험적으로 최소화하는 것은 각 그룹의 경험 분포 (empirical distribution)
한편, 정말로 평가하고자 하는 것은 각 그룹의 진 분포 (true distribution)
각 그룹의 일반화 격차 (generalization gap)를
[수식 생략]
라고 정의한다. 이때, 각 그룹의 진 리스크 (true risk)는
[수식 생략]
라고 쓸 수 있다.
따라서, 최악 그룹 테스트 리스크 (worst-group test risk)는
[수식 생략]
이다.
이 식에서 알 수 있듯이, Group DRO가 경험적 그룹 손실 (empirical group loss)
[수식 생략]
을 작게 만들더라도, 어떤 그룹에서
AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기