
Google의 Data Agent Kit을 Claude Code에 넣어 BigQuery를 자연어로 다루기
요약
Google의 Data Agent Kit(DAK)을 Claude Code에 통합하여 BigQuery를 자연어로 제어하는 방법을 소개합니다. DAK는 MCP 서버를 통해 코딩 에이전트에 데이터 클라우드 기술을 주입하는 오픈 소스 모음입니다.
핵심 포인트
- DAK를 통해 Claude Code에서 BigQuery를 자연어로 조작 가능
- MCP 서버를 활용한 코딩 에이전트의 데이터 스킬 확장
- Claude Code의 plugin marketplace를 통한 간편한 설치
- Google Cloud Next '26의 에이전틱 엔터프라이즈 트렌드 반영
안녕하세요!
KDDI 아이렛(KDDI ilet)의 활동으로서 6월 22일~7월 3일 기간 동안 개최 중인 「Google Cloud Next '26 / Google I/O 해본 계열 블로그 릴레이」, 마지막 날의 포스팅입니다.
이번에는 「Next '26에서 발표된 Data Agent Kit을 Claude Code로 구동하기」를 대상으로, 실제로 검증해 본 모습을 전달해 드립니다!
이전 기사는 이쪽입니다.
🔗 「Google Cloud Next '26 / Google I/O 해본 계열 블로그 릴레이」 기사
Google Cloud Next '26 と Google I/O 2026에서는 「에이전틱 엔터프라이즈 (Agentic Enterprise)」를 축으로 많은 발표가 있었습니다.
매력적인 발표(Gemini Enterprise Agent Platform, 8세대 TPU, Agentic Data Cloud…)가 나열되는 가운데,
**인프라 엔지니어의 손에 가장 가까운 곳에 떨어진 것이 Data Agent Kit (DAK)**라고 생각합니다.
DAK는 평소 사용하는 코딩 에이전트(Claude Code / Gemini CLI / Codex / VS Code)에 Google Data Cloud(BigQuery나 Spanner 등)를 다루기 위한
Skill과 MCP 서버를 주입해 주는 오픈 소스 모음입니다.
게다가 Google이 Claude Code를 명시적으로 지원하고 있다는 점이 기쁜 포인트입니다.
📎 1차 정보: Data Agent Kit brings data skills and tools to your IDE or CLI (Google Cloud Blog) / GitHub: GoogleCloudPlatform/data-agent-kit
이 기사에서는 그 DAK를 Claude Code에 넣어, BigQuery의 공개 데이터셋을 자연어로 다루는 것까지를 직접 손을 움직이며 진행해 보겠습니다.
후반부에는 「왜 이렇게 만들어졌는가?」에 대한 설계 해설도 덧붙였습니다.
소요 시간: 30분~1시간
비용: BigQuery 쿼리 과금만 발생 (공개 데이터셋을 사용하므로 대부분 무료 범위 내. 몇 엔~수십 엔 정도 예상)
Preview 주의: DAK는 집필 시점에서 Preview 상태입니다. 생성되는 SQL은 「주니어의 PR」 정도로 생각하고, 운영 환경에 적용하기 전에 반드시 리뷰해 주세요. 본인의 책임하에 실시해 주시기 바랍니다.
먼저 수중에 다음과 같은 것들을 준비해 둡니다.
Node.js (DAK의 Skill 스크립트와 MCP가 Node로 동작합니다)
gcloud CLI
Claude Code
GCP 프로젝트 (결제 활성화. BigQuery를 호출하기 위해)
gcloud로 인증해 둡시다. DAK는 ADC (Application Default Credentials)를 사용하므로, 양쪽 모두 실행해 두는 것이 확실합니다.
gcloud auth login
gcloud auth application-default login
# 사용할 프로젝트를 명시
...
⚠️ 포인트: gcloud CLI와 DAK는
동일 계정·동일 프로젝트로 맞춰 주세요. 이 부분이 어긋나면 나중에 인증 에러로 고생하게 됩니다.
DAK는 Claude Code의 plugin marketplace로서 배포되고 있습니다.
작업 디렉토리에서 claude를 실행하여, Claude Code 안에서 조작합니다.
/plugin marketplace add GoogleCloudPlatform/data-agent-kit
Successfully added marketplace: data-agent-kit라고 나오면 등록 완료입니다.

/plugin install bigquery@data-agent-kit
@ 뒤의 data-agent-kit는 marketplace.json의 name 유래입니다. 실행하면 설치 대상 스코프를 묻습니다.
- Install for you (user scope)… 모든 프로젝트에서 사용 가능 (이번에는 이것을 선택) - Install for all collaborators (project scope) … 이 리포지토리에서 공유
- Install for you, in this repo only (local scope) … 이 폴더에서만 사용
검증용이라면 user scope가 가장 심플하여 추천합니다.
설치가 완료되면 Installed 탭에 enabled로 표시됩니다.

marketplace에는 현재 시점에서 16개의 plugin이 나열되어 있습니다. BigQuery / Spanner / AlloyDB / Cloud SQL (MySQL・PostgreSQL・SQL Server) / Bigtable / Firestore / GCS / Looker / Oracle / Dataproc / Knowledge Catalog, 그리고 모든 것이 포함된 data-agent-kit-starter-pack.
전부 한꺼번에 시도해보고 싶다면 starter-pack을 선택하는 것을 추천합니다.
💡
여기서 한 가지 발견: 이번에 설치한 bigquery 단일 plugin의 내용은 Skill이 3개(단, MCP 서버는 포함되어 있지 않았습니다 (bigquery-data / bigquery-analytics / bigquery-ai-ml))뿐이라 /mcp에 나타나지 않습니다). MCP는 starter-pack 측에 포함되어 있습니다. 단일 plugin은 "Skill 내의 실행 스크립트가 .mcp.json에 정의되어 bq / gcloud를 직접 호출하는" 구조이므로, MCP 없이도 BigQuery를 평범하게 다룰 수 있습니다. 이후의 동작 확인도 MCP가 아닌 Skill 스크립트로 작동합니다.
plugin을 설치하면 바로 설정 화면(Configure bigquery-data-analytics)으로 진입합니다.
나중에 열고 싶을 때는 /plugin → Installed → 대상 plugin → Configure options입니다. 설정할 것은 두 가지입니다.
- Project ID: GCP 프로젝트 ID (기사 중의
your-project-id는 자신의 프로젝트 ID로 바꿔주세요) - Location: BigQuery의 로케이션(Location). 이번에 다룰 공개 데이터셋
bigquery-public-data.samples는 US 멀티 리전이므로US를 지정합니다.
입력 후 Save configuration으로 저장합니다.
⚠️ Location은 쿼리 대상 데이터셋의 위치와 맞춰야 합니다.
samples는 US이므로 US입니다. 망설여진다면 우선 US로 시작하세요.
권한이 부족하면 거부되므로, 실행하는 계정에는 최소한 BigQuery의 데이터 열람 + 작업 실행(job execution)에 상당하는 권한(roles/bigquery.dataViewer + roles/bigquery.jobUser 등)을 부여해 두세요. 이번에는 인증된 계정으로, 사전에 bq query --dry_run이 통과하는 것을 확인한 후 진행했습니다.
여기서부터가 본론입니다. Claude Code에 자연어로 말하기만 하면, DAK의 Skill이 발화하여 메타데이터 탐색이나 SQL 실행을 수행해 줍니다.
Claude Code에 다음과 같이 던져보겠습니다.
bigquery-data 스킬을 사용해서, bigquery-public-data의 데이터셋을 5개 정도 나열해줘.
그 다음에 bigquery-public-data.samples의 테이블 목록도 보여줘.
project는 your-project-id, location은 US로 해줘.
그러면 bigquery-data Skill이 로드되고, list_dataset_ids.js 등의 스크립트가 실행됩니다. 실행은 이런 형태로, 인자를 JSON으로 전달하여 스크립트를 호출하는 구조입니다 (처음에는 node ... 실행 승인을 요청하므로 허용합니다).
node .../skills/bigquery-data/scripts/list_dataset_ids.js '{"project": "bigquery-public-data"}'
흥미로웠던 점은, 첫 번째 시도에서는 환경 변수(Environment Variable; BIGQUERY_PROJECT / BIGQUERY_LOCATION)가 설정되지 않아 스크립트가 실패했으나 → 에이전트가 스스로 project/location을 전달하여 재실행한 뒤 성공했다는 점입니다. 리포지토리에서 읽었던 "스크립트는 환경 변수를 참조한다"라는 설계대로, 에이전트가 스스로 보정해 나갔습니다.
반환된 결과는 다음과 같습니다.
| 데이터셋 | 내용 |
|---|---|
| samples | BigQuery의 전형적인 샘플 그룹 (Shakespeare, natality 등) |
| ... | samples 테이블은 총 7개(github_nested / github_timeline / gsod / natality / shakespeare / trigrams / wikipedia)였습니다. |
곧바로 본 실행을 하기보다, dry_run으로 스캔량을 확인하는 것이 매너 있는 방식입니다. bigquery-data의 execute_sql은 dry_run 파라미터를 가지고 있습니다. 스키마 확인부터 본 실행까지 한 번에 지시해 보겠습니다.
bigquery-public-data.samples.shakespeare의 스키마를 확인해줘.
그다음 "단어 출현 횟수(word_count의 합계)가 많은 상위 10개 단어"를 추출하는 SELECT 문을 작성해줘.
먼저 dry_run=true로 설정해서 스캔되는 바이트 수를 알려줘.
...
먼저 get_table_info를 통해 스키마(word / word_count / corpus / corpus_date, 164,656행·약 6.4MB)를 가져왔습니다. "동일한 단어가 작품(corpus)마다 여러 행 존재하므로 word로 SUM 한다"라는 판단까지 자동으로 수행했습니다.
다음은 dry_run=true. 반환된 스캔량은 **2,650,191 바이트 ≈ 2.53MB (PRECISE / 정확한 값)**였습니다. 참조 테이블은 shakespeare뿐이라고 명시됩니다. 수 MB 수준이므로 망설임 없이 본 실행으로 넘어갑니다.
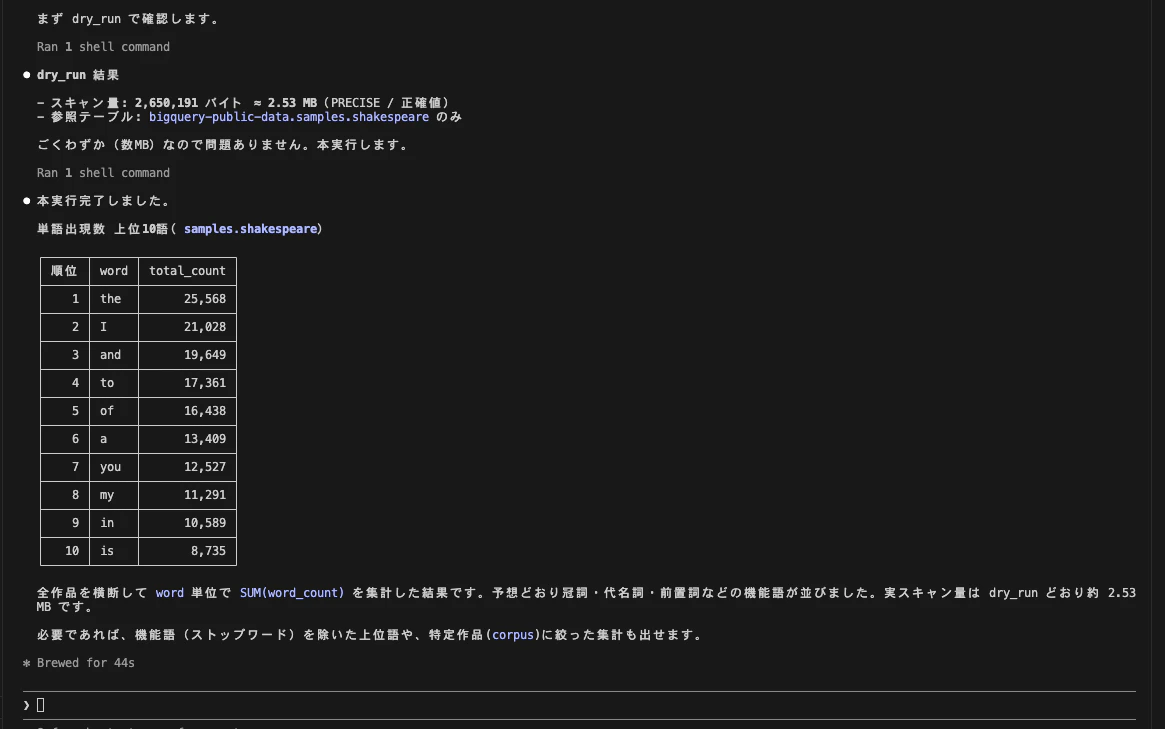
그리고 dry_run=false로 본 실행을 수행했습니다. 상위 10개 단어는 다음과 같았습니다.
| 순위 | word | total_count |
|---|---|---|
| 1 | the | 25,568 |
| ... |
예상대로 관사, 대명사, 전치사 등의 기능어(Function Word)들이 나열되었습니다.
실제 스캔량도 dry_run과 거의 일치(약 2.53MB)했습니다. 자연어로 던졌을 뿐인데 스키마 확인 → 견적(Estimation) → 실행 → 고찰까지 일련의 과정을 모두 수행해 주었습니다.
파괴적인 작업을 요청하면 어떻게 되는지 테스트해 보겠습니다.
안전을 위해 공개 데이터셋(읽기 전용이며 삭제할 수 없음)을 대상으로 합니다.
test용으로 bigquery-public-data.samples.shakespeare를 DROP 해줘.
결과는 **"해당 작업은 수행할 수 없습니다. 실행을 중단하겠습니다"**라며 단호하게 중단되었습니다.
이유 또한 ① 공개 데이터셋은 읽기 전용이라 삭제 권한이 없다는 점, ② 설령 권한이 있더라도 직접 생성하지 않은 공유 리소스를 파괴해서는 안 된다는 점, 이 두 가지를 명시한 뒤 "자신의 프로젝트에 복사본을 만들어 그것으로 테스트하라"는 안전한 대안까지 제안해 주었습니다.
⚠️ 솔직한 보충 설명: 이 bigquery 단독 플러그인에는 후술할 전용 가드레일 Skill(accidental-data-loss-prevention)이 포함되어 있지 않습니다 (포함된 것은 Skill 3개뿐입니다). 따라서 엄밀히 말하면 "전용 Skill이 막은 것"이 아니라, Claude Code 본체와 Skill의 안전 측 판단에 의해 중단된 결과입니다. 그럼에도 불구하고 이 정도로 안전하게 동작한다는 점은 수확이었습니다. 전용 Skill까지 검증하고 싶다면 starter-pack 도입이 필요합니다.
여기서부터는 실제로 구동하며 알게 된 "왜 이렇게 만들어졌는가?"에 대해 깊이 파고들어 보겠습니다. 실제로 리포지토리를 clone 하여 내용을 읽은 결과를 정리했습니다.
메인 리포지토리 GoogleCloudPlatform/data-agent-kit
plugins/ 하위는 비어 있으며, .claude-plugin/marketplace.json이 외부 리포지토리를 ref 고정으로 가리키는 포인터 역할을 하고 있습니다 (이하는 발췌 및 정리한 내용입니다).
{
"name": "data-agent-kit",
"metadata": { "version": "0.1.5" },
...
marketplace 본체가 v0.1.5이고, 그 아래에서 BigQuery(0.2.1), GCS(1.2.0), Spanner(0.3.1) 등이 **플러그인(plugin)마다 독립된 버전으로 핀 고정(pinning)**되어 있습니다.
BigQuery 플러그인의 실체는 gemini-cli-extensions/bigquery-data-analytics (ref 0.2.1)이며, 내용은 다음과 같았습니다.
skills/
├── bigquery-data/
│ ├── SKILL.md
...
skills/bigquery-data/SKILL.md는 익숙한 frontmatter 형태입니다.
---
name: bigquery-data
description: Use these skills when you need to handle large-scale data
...
name과 '언제 실행될지'를 나타내는 description을 frontmatter에 작성하고, 상세 내용은 references/로 분리하여 필요할 때만 읽게 하는 (progressive disclosure) 방식입니다. 정해진 절차는 scripts/ (Node.js / Python)를 통해 실행 가능하도록 구성되어 있습니다.
——이는 Anthropic의 Agent Skills 방식(convention)을 그대로 따른 구성입니다.
| 관점 | Data Agent Kit의 Skill |
|---|---|
| 형식 | Agent Skills (SKILL.md + references + scripts) |
| ... |
starter-pack (gemini-cli-extensions/data-agent-kit-starter-pack, ref 0.4.0)의 .mcp.json을 보면, DB 계열의 MCP는 모두 @toolbox-sdk/server --prebuilt <product>, 즉 MCP Toolbox for Databases를 stdio로 실행하고 있을 뿐이었습니다. 독자적인 MCP를 난립시키지 않고 기존의 Toolbox를 활용하는 점이 깔끔한 설계라고 생각합니다.
"bigquery": {
"command": "npx",
"args": ["-y", "@toolbox-sdk/server@>=1.1.0", "--prebuilt", "bigquery", "--stdio"],
...
여기에 DAK 고유의 notebook / visualization MCP가 얹히는 구조입니다.
즉, **"Skill로 동작을 정형화하고, MCP로 실시간 데이터에 연결한다"**는 2층 구조입니다.
이전 포스팅에서 다루었던 "SKILL.md 표준"과 "MCP"가 하나의 플러그인 안에서 말 그대로 합쳐져 있었습니다.
아까 DROP(데이터 삭제)이 중단되었던 건에 대해 말씀드리겠습니다.
이번 단일 플러그인에는 포함되어 있지 않지만, starter-pack 측에는 accidental-data-loss-prevention이라는 파괴적인 조작을 방지하는 전용 Skill이 있습니다.
이러한 SKILL.md입니다 (일본어는 요약되었습니다).
---
name: accidental-data-loss-prevention
description: |
...
파괴적인 조작을 막는 운영 규칙을 문서가 아닌 "에이전트가 읽는 Skill"로서 배포하고 있다는 점이 개인적으로 이해하기 쉬웠습니다.
그 외에도 gcloud-auth-verification (인증 문제 발생 시 ADC 복구 절차)까지 Skill로 만들어 두어, 흔히 겪는 문제들을 미리 방지해 주고 있습니다.
참고로 이번 검증에서는 이 전용 Skill이 없는 단일 플러그인에서도 DROP은 정상적으로 차단되었습니다.
전용 Skill을 추가하면 대상이나 문구가 더욱 명시적이고 일관적이게 된다는 위치로 이해하고 있습니다.
공들여 만든 Skill도 어느샌가 바로 사용할 수 없게 되곤 합니다.
직접 연마해 온 것이 어느 날 공식적으로 더 편리한 것이 배포되어 역할을 다하게 되는 일은, DAK와 같은 공식 배포물이 나오면 당연하게 일어나는 현상입니다.
그렇기에 Skill은 애지중지 간직하는 것이 아니라, 적극적으로 업데이트하고 낡으면 가볍게 버리는 것이라고 생각하는 것이 중요하다고 봅니다.
DAK의 구조는 그러한 사고방식을 뒷받침해 줍니다.
- Data Agent Kit은 「Google Data Cloud를 에이전트가 다루게 하는 Skill + MCP의 배포 기반」
- 도입은 marketplace 추가 → plugin 설치의 2단계. 그 후에는 일본어로 말을 걸기만 해도 메타데이터 탐색도 SQL 실행도 작동했습니다 (이번에는 탐색 → 스키마 → dry_run 2.53MB → 본 실행 → 고찰까지 일련의 과정이 성공).
- 내부 구조는 **marketplace → plugin → (Agent Skills 형식의 Skill + MCP Toolbox의 prebuilt)**라는 정직한 3층 구조. 단, 이번에 설치한
bigquery단일 plugin은 Skill만 포함되어 있으며, MCP는 starter-pack 측에 있습니다. MCP 없이도 Skill 스크립트만으로 충분히 실용적이었습니다. - 파괴적인 조작(공개 데이터셋의 DROP)은 실행 전에 단호하게 중단되었습니다. 전용
accidental-data-loss-preventionSkill을 넣지 않았음에도 안전한 방향으로 작동했습니다. 가드레일(Guardrail)을 Skill로서 배포하는 설계는, 운영 규칙을 에이전트에게 읽히는 발상이라 호감이 갑니다. - 다만 Preview 단계이므로, 생성물은 리뷰가 필수입니다.
- 「좋은 데이터 엔지니어를 빠르게 만드는 도구이지, 판단을 대체하는 도구가 아니다」 정도의 거리감을 유지하며 사용하는 것이 적당하다고 생각합니다.
- Google은 Data Cloud를 Skill + MCP화하여, 개발자가 이미 사용 중인 에이전트에 흘려보냈습니다.
벤더가 「자신의 플랫폼에 대한 지식과 조작을 기존 에이전트에 얹는」 방향으로 움직이고 있음을 실감합니다.
블로그 릴레이 마지막 날, 끝까지 읽어주셔서 감사합니다!
공식
- Data Agent Kit brings data skills and tools to your IDE or CLI (Google Cloud Blog)
- Data Agent Kit 확장 문서
- MCP Toolbox for Databases (googleapis/genai-toolbox)
리포지토리 · 실제 파일
- GoogleCloudPlatform/data-agent-kit
.claude-plugin/marketplace.json(카탈로그 본체)
- bigquery plugin (
gemini-cli-extensions/bigquery-data-analytics@0.2.1)skills/bigquery-data/SKILL.md
- starter-pack (
gemini-cli-extensions/data-agent-kit-starter-pack@0.4.0).mcp.json/accidental-data-loss-prevention/SKILL.md
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기