
GLM 5.1의 전략적 사고, 심화되는 데이터 센터 반란, 도움이 되던 LLM이 도움이 되지 않을 때, 그리고 업무를 시작하는 휴머노이드 로봇
요약
코딩 에이전트가 소프트웨어 개발의 각 단계(프론트엔드, 백엔드, 인프라, 연구)에 미치는 가속화 효과를 분석합니다. 프론트엔드는 매우 높은 가속화를 보이는 반면, 복잡한 트레이드오프가 필요한 인프라와 깊은 사고가 필요한 연구 분야는 가속화 효과가 낮습니다.
핵심 포인트
- 프론트엔드는 에이전트의 높은 숙련도로 인해 가장 큰 가속화 효과를 보임
- 백엔드는 예외 케이스와 디버깅의 어려움으로 인해 프론트엔드보다 가속도가 낮음
- 인프라 구축은 복잡한 트레이드오프와 전문 지식이 필요하여 에이전트 활용에 한계가 있음
- 연구 분야는 가설 설정과 깊은 사고가 필수적이어서 에이전트의 가속화가 가장 어려움
친구 여러분,
코딩 에이전트 (Coding agents)는 다양한 유형의 소프트웨어 작업을 각기 다른 정도로 가속화하고 있습니다. 팀을 구성할 때 이러한 차이를 이해하는 것은 현실적인 기대치를 갖는 데 도움이 됩니다. 가장 많이 가속화되는 것부터 가장 적게 가속화되는 순서대로 기능을 나열하자면, 제가 생각하는 순서는 프론트엔드 개발 (frontend development), 백엔드 (backend), 인프라 (infrastructure), 그리고 연구 (research)입니다.
프론트엔드 개발 (Frontend development) — 예를 들어, 이커머스 사이트의 제품 설명을 제공하기 위한 웹 페이지를 구축하는 작업 — 은 코딩 에이전트가 TypeScript 및 JavaScript와 같은 인기 있는 프론트엔드 언어와 React 및 Angular와 같은 프레임워크에 능숙하기 때문에 극적으로 빨라졌습니다. 또한, 웹 브라우저를 작동시켜 구축한 결과물을 검토함으로써, 코딩 에이전트는 이제 루프를 닫고(closing the loop) 스스로 구현을 반복하는 데 매우 능숙합니다. 물론 오늘날의 LLM (Large Language Models)은 시각적 디자인에는 여전히 약하지만, 디자인이 주어지면 (또는 세련된 디자인이 중요하지 않다면), 구현 속도는 매우 빠릅니다!
백엔드 개발 (Backend development) — 예를 들어, 제품 데이터를 요청하는 쿼리에 응답하기 위한 API를 구축하는 작업 — 은 더 어렵습니다. 미묘한 버그나 보안 결함으로 이어질 수 있는 예외 케이스 (corner cases)를 모델이 깊이 생각하도록 유도하기 위해서는 인간 개발자의 더 많은 노력이 필요합니다. 게다가, 백엔드 버그는 가끔 잘못된 결과를 반환하는 손상된 데이터베이스와 같이 직관적이지 않은 다운스트림 영향 (downstream effects)을 초래할 수 있으며, 이는 일반적인 프론트엔드 버그보다 디버깅하기 더 어려울 수 있습니다. 마지막으로, 데이터베이스 마이그레이션 (database migrations)은 코딩 에이전트를 통해 더 쉬워질 수 있지만, 여전히 까다로우며 데이터 손실을 방지하기 위해 주의 깊게 처리해야 합니다. 백엔드 개발은 코딩 에이전트를 통해 훨씬 빨라지긴 하지만, 가속화되는 정도는 그보다 낮으며, 숙련된 개발자는 여전히 코딩 에이전트를 사용하는 미숙한 개발자보다 훨씬 더 나은 백엔드를 설계하고 구현합니다.
인프라 (Infrastructure). 에이전트(Agents)는 99.99%의 신뢰성을 유지하면서 이커머스 사이트를 1만 명의 활성 사용자 규모로 확장하는 것과 같은 작업에서는 효과가 훨씬 더 떨어집니다. LLM의 지식은 인프라 및 숙련된 엔지니어가 내려야 하는 복잡한 트레이드오프 (tradeoffs) 측면에서 여전히 상대적으로 제한적이기 때문에, 저는 중요한 인프라 결정에 LLM을 신뢰하는 경우가 거의 없습니다. 좋은 인프라를 구축하는 것은 종종 테스트와 실험의 기간을 필요로 하며, 코딩 에이전트가 그 과정을 도울 수는 있지만, 궁극적으로 이는 빠른 AI 코딩이 큰 도움이 되지 않는 상당한 병목 구간입니다. 마지막으로, 미묘한 네트워크 설정 오류와 같은 인프라 버그를 찾아내는 것은 믿기 힘들 정도로 어려울 수 있으며 깊은 엔지니어링 전문 지식을 요구합니다. 따라서 저는 코딩 에이전트가 백엔드 개발보다 핵심 인프라를 가속화하는 정도가 훨씬 더 낮다는 것을 발견했습니다.

연구 (Research). 코딩 에이전트는 연구 작업의 속도를 더욱 더 가속화하지 못합니다. 연구는 새로운 아이디어를 깊이 생각하고, 가설을 설정하고, 실험을 수행하고, 가설을 수정하기 위해 실험 결과를 해석하며, 결론에 도달할 때까지 반복하는 과정을 포함합니다. 코딩 에이전트는 연구용 코드를 작성하는 속도를 높여줄 수는 있습니다. (저 또한 실험을 조율하고 추적하는 데 도움을 받기 위해 코딩 에이전트를 사용하며, 이는 단일 연구자가 더 많은 실험을 관리하기 쉽게 만들어 줍니다.) 하지만 연구에는 코딩 이외의 작업이 매우 많으며, 오늘날의 에이전트들은 연구에 아주 미미한 수준의 도움만을 줄 뿐입니다.
소프트웨어 작업을 프론트엔드, 백엔드, 인프라, 연구로 분류하는 것은 극단적인 단순화이지만, 각기 다른 작업들이 얼마나 빨라졌는지에 대한 간단한 정신적 모델 (mental model)을 갖는 것은 제가 소프트웨어 팀을 조직하는 데 유용했습니다. 예를 들어, 저는 이제 프론트엔드 팀에게 1년 전보다 훨씬 더 빠르게 제품을 구현할 것을 요구하지만, 연구 팀에 대한 기대치는 그만큼 크게 변하지 않았습니다.
저는 속도를 달성하기 위해 코딩 에이전트를 활용하도록 소프트웨어 팀을 조직하는 방법에 매료되어 있으며, 앞으로의 뉴스레터를 통해 저의 발견을 계속 공유하겠습니다.
계속해서 만들어 나가세요!
Andrew
DEEPLEARNING.AI의 메시지

“Building Multimodal Data Pipelines”에서는 이미지, 오디오, 비디오를 엔드 투 엔드 (end-to-end)로 처리하는 파이프라인을 구축하는 방법을 배우게 됩니다. 비정형 데이터 (unstructured data)를 쿼리 가능한 형태로 변환해 보세요. 무료로 등록하세요.
뉴스
GLM 5.1, 장기 실행 작업 목표
Z.ai는 단일 작업에 대해 최대 8시간 동안 자율적으로 작동할 수 있도록 자사의 플래그십 오픈 웨이트 (open-weights) 대규모 언어 모델 (LLM)을 업데이트했습니다.
새로운 기능: GLM-5.1은 코딩 및 에이전트 (agentic) 작업을 위해 설계되었습니다. Z.ai에 따르면, 이 모델은 특정 접근 방식을 시도하고, 결과를 평가하며, 결과가 불충분할 경우 전략을 수정할 수 있습니다. 즉, 조기에 포기하는 대신 이 루프를 수백 번 반복할 수 있습니다.
입력/출력: 입력 텍스트 (최대 200,000 토큰), 출력 텍스트 (최대 128,000 토큰)
아키텍처 (Architecture): 전문가 혼합 (Mixture-of-experts) 트랜스포머 (transformer), 총 7,540억 개의 파라미터 (parameters), 토큰당 400억 개의 활성 파라미터
특징: 추론 (Reasoning), 함수 호출 (function calling), 구조화된 출력 (structured output)
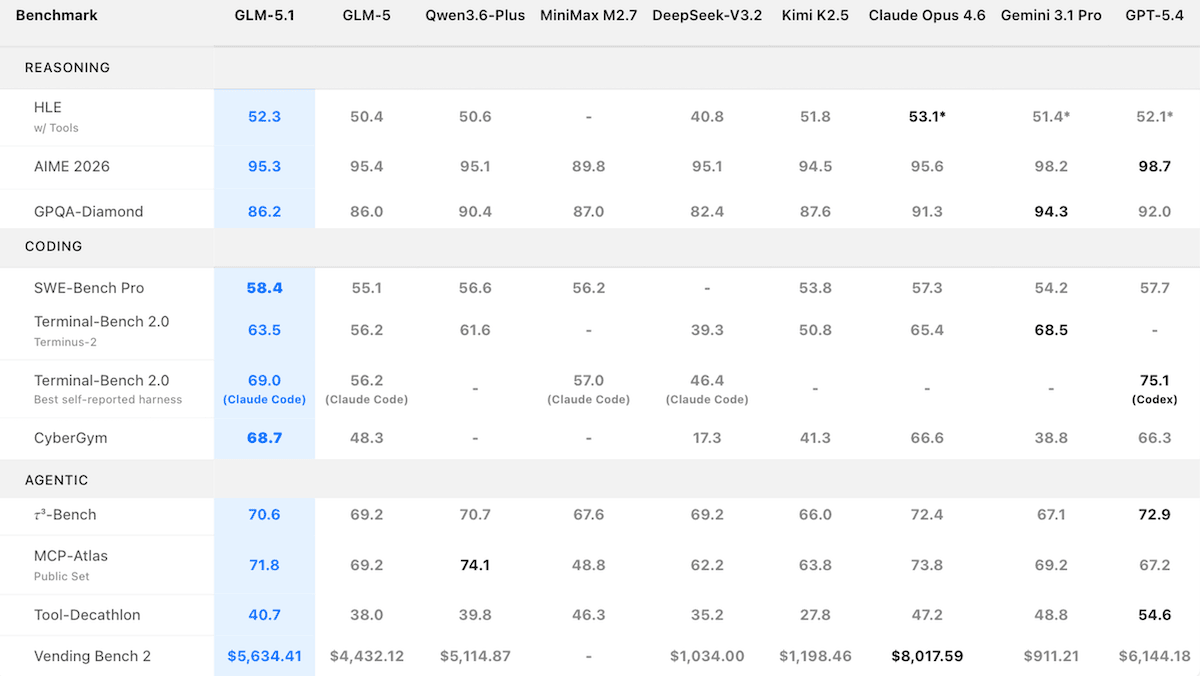
성능: Artificial Analysis Intelligence Index에서 가장 높은 점수를 받은 오픈 웨이트 모델, Arena Code 리더보드 3위, SWE-Bench Pro 선두 (Z.ai 테스트 기준)
가용성/가격: MIT 라이선스에 따라 상업적 및 비상업적 용도로 HuggingFace를 통해 웨이트 (weights) 사용 가능, API 가격은 입력/캐시된/출력 토큰 100만 개당 각각 $1.40/$0.26/$4.40, 코딩 플랜은 분기당 $48.60에서 $432
미공개 사항: 구체적인 아키텍처, 학습 데이터 및 방법론
작동 원리: Z.ai는 GLM-5.1에 특화된 기술 보고서를 발표하지 않았으나, 이 모델은 GLM-5의 기본 아키텍처, 어텐션 메커니즘 (attention mechanism), 사전 학습 (pretraining) 및 입출력 크기 제한을 따르는 것으로 보입니다. 핵심적인 개선 사항은 장기 실행 작업에서의 지속적인 생산성입니다.
- GLM-5 및 다른 많은 모델들이 특정 토큰 예산 내에서 또는 추가적인 추론이 결과에 영향을 미치지 않을 것이라고 판단될 때까지 최종 출력을 생성하는 것과 달리, GLM-5.1은 작업이 완료되었다고 판단될 때까지 계획 (planning), 실행 (execution), 중간 결과의 평가 (evaluation of intermediate results), 그리고 접근 방식의 평가 (evaluation of its approach) 과정을 순환합니다. 만약 현재의 접근 방식이 미흡하다고 판단되면 전략을 변경하며, Z.ai의 테스트에서는 때때로 수 시간에 걸쳐 수천 번의 도구 호출 (tool calls)을 사용하기도 합니다.
- 해당 기업은 GLM-5.1을 에이전트 기반 코딩 (agentic coding)에 최적화했다고 밝혔으나, 구체적인 방법은 명시하지 않았습니다.
성능 (Performance): GLM-5.1은 오픈 웨이트 (open-weights) 모델들 사이에서 강력한 코딩 결과를 달성했으나, 추론 (reasoning) 및 수학 테스트에서는 폐쇄형 (closed) 모델들에 뒤처졌습니다.
-
경제적으로 유용한 작업 10가지를 결합한 Artificial Analysis의 지능 지수 (Intelligence Index)에서, 추론 모드로 설정된 GLM-5.1 (51)은 오픈 웨이트 모델 중 가장 높은 점수를 기록했으나, 추론 모드로 설정된 Gemini 3.1 Pro Preview 및 xhigh 추론 모드로 설정된 GPT-5.4 (57로 공동 1위), 그리고 max 추론 모드로 설정된 Claude Opus 4.6 (53)과 같은 독점 (proprietary) 모델들에는 미치지 못했습니다.
-
블라인드 헤드 투 헤드 (blind head-to-head) 비교를 기반으로 모델 순위를 매기는 Arena의 코드 리더보드 (Code leaderboard)에서, GLM-5.1은 출시 며칠 만에 1,530 Elo에 도달하며 Claude Opus 4.6 (1,542 Elo) 및 추론 모드로 설정된 Claude Opus 4.6 (1,548 Elo)에 이어 3위를 차지했습니다.
-
Z.ai 자체 테스트에서 GLM-5.1은 GitHub에서 추출한 실제 소프트웨어 엔지니어링 문제 테스트인 SWE-Bench Pro에서 58.4%를 기록하며 선두를 달렸으며, 이는 GPT-5.4 (57.7%), Claude Opus 4.6 (57.3%), Gemini 3.1 Pro (54.2%)를 상회하는 수치입니다.
-
사이버 보안 추론을 테스트하는 CyberGym에서 GLM-5.1 (68.7)은 Claude Mythos (Anthropic이 보고한 83.1)의 등장 이전, Claude Opus 4.6 (66.6) 및 GPT-5.4 (66.3)를 포함하여 Z.ai가 테스트한 모델 중 가장 높은 점수를 기록했습니다. Gemini 3.1 Pro와 GPT-5.4는 안전상의 이유로 특정 작업의 실행을 거부했으며, 이는 해당 모델들의 지표를 낮추는 요인이 되었을 가능성이 큽니다.
-
GPU(그래픽 처리 장치)에서 실행되는 머신러닝 (Machine Learning) 코드를 모델이 얼마나 가속할 수 있는지를 측정하는 KernelBench Level 3에서, Z.ai는 GLM-5.1 (3.6x)이 Claude Opus 4.6 (4.2x)에 뒤처진다는 것을 측정했습니다.
-
GLM-5.1은 추론 (Reasoning) 및 수학 테스트에서 폐쇄형 모델 (Proprietary models)들과 더 큰 격차로 뒤처졌습니다. 예를 들어, 대학원 수준의 과학 질문을 던지는 GPQA Diamond에서 GLM-5.1 (정확도 86.2%)은 Gemini 3.1 Pro (정확도 94.3%)보다 낮은 성능을 보였습니다. 경시대회 수학 문제인 AIME 2026에서 GLM-5.1 (95.3%)은 GPT-5.4 (98.7%)에 뒤처졌습니다.
가격 인상: Z.ai는 GLM-5.1의 가격을 이전 모델보다 상당히 높게 책정했습니다. API 토큰 가격은 약 40% 더 높으며, 코딩 플랜 구독료는 약 두 배에 달합니다. 해당 API는 여전히 유사한 폐쇄형 모델들보다는 저렴하지만 (Claude Opus 4.6의 입력 토큰 100만 개당 5달러 대비 1.40달러), 그 격차는 좁혀지고 있습니다.
중요한 이유: 몇 분이 아닌 몇 시간 동안 자율적으로 작업할 수 있는 능력은 LLM 경쟁의 성장 분야입니다. 독립 테스트 기관인 METR에 따르면, AI 에이전트 (AI agents)가 자율적으로 완료하는 작업의 길이는 약 7개월마다 두 배씩 늘어나고 있으며, Anysphere의 Cursor 통합 개발 환경 (IDE)은 일주일 동안 에이전트 군집 (Swarm of agents)을 실행했습니다. 그러나 SWE-EVO와 같이 지속적인 성능을 테스트하도록 설계된 벤치마크 (Benchmarks)에 따르면, 최상위 모델들조차 장기 실행 코딩 작업의 약 25%만을 성공적으로 완료하는 것으로 나타납니다.
우리의 생각: 만약 GLM-5.1이 긴 세션 동안 막다른 길을 인식하고 전환하는 능력이 독립적인 테스트에서도 입증된다면, 이는 현재의 벤치마크가 놓치고 있는 훈련 목표 (Training objective), 즉 실패하는 접근 방식을 언제 포기해야 하는지를 인식하는 능력을 시사합니다.

휴머노이드 로봇이 공장 바닥에서 작업하다
소수의 휴머노이드 로봇 (Humanoid robots)이 산업 현장에 투입되었으며, 이들은 인간 노동 비용과 거의 비슷한 수준을 유지하면서 일부 노동자들을 더 높은 수준의 역할로 밀어 올리고 있습니다.
새로운 소식: The Wall Street Journal의 보도에 따르면, 오리건(Oregon)에 본사를 둔 Agility Robotics가 휴머노이드 로봇의 첫 운영 배치 사례로 독일의 자동차 부품 제조업체인 Schaeffler에 휴머노이드 로봇을 공급하고 있습니다. Agility의 Digit 로봇은 사우스캐롤라이나(South Carolina)에 위치한 Schaeffler 공장에서 새로 제작된 부품이 가득 담긴 빈(bin)을 운반하며, 이 작업은 이전에는 관리직으로 승진한 인간 작업자가 수행하던 업무였습니다. 두 회사 모두 현재 사용 중인 Digit의 대수는 공개하지 않았으나, Schaeffler는 2030년까지 미국과 유럽의 공장에 수백 대를 배치할 계획이라고 밝혔습니다.
작동 방식: Schaeffler 공장에서 Digit은 25파운드 무게의 바구니를 스탬핑 프레스(stamping press)에서 컨베이어 벨트로 운반하며, 이 이동은 완료하는 데 약 1분이 소요됩니다. 이 로봇는 주변의 인간을 감지하도록 장착되어 있지 않으며(이 기능은 Agility가 내년에 구현할 계획입니다), 따라서 플렉시글라스(plexiglass) 차단벽 뒤에서 작동합니다. 로봇은 중간에 재충전을 위한 휴식 시간을 포함하여 4시간씩 두 번의 교대 근무를 수행합니다. 해당 기업은 프로세싱 하드웨어(processing hardware) 및 AI 모델(AI models), 데이터셋(datasets), 또는 학습 방법(training methods)을 포함한 기술에 대한 세부 사항을 거의 공개하지 않았습니다.
- Digit은 인간의 체구(5피트 9인치, 143파운드)에 맞춰 제작되었으며, 물건을 들어 올리기 위해 역방향 무릎(inverted knees)이 달린 다리, 소포를 들어 올리고 균형을 유지하도록 설계된 팔, 네 손가락 그리퍼(four-fingered grippers), 프로세싱 장치·배터리·센서가 들어 있는 몸체, 그리고 현재 집중하고 있는 곳을 향하는 LED "눈"을 갖추고 있습니다. 이 로봇은 2016년경 Oregon State University와의 협업을 통해 개발된, 몸체·머리·인지 시스템이 없는 이족 보행 로봇 연구 플랫폼인 Cassie를 기반으로 합니다.
- 로봇의 센서에는 RGB 깊이 카메라(RGB depth cameras), LiDAR, 동작 감지 관성 측정 장치(IMU), 그리고 관절의 위치와 속도를 측정하는 미상(unspecified)의 인코더(encoders)가 포함될 수 있습니다.
- 보행 제어(Walking control)는 불규칙한 지형을 관리하고, 방해 요소로부터 회복하며, 계단과 경사로를 오를 수 있도록 동적으로 작동합니다.
- Agility의 엔지니어들은 배포 전에 작업 환경을 매핑하고 현장에서 특정 작업을 구성합니다. 작업은 관절 모터 명령(joint-motor commands) 대신 구조화된 워크플로(structured workflows)로 공식화되며, 집어 올리는 위치, 내려놓는 위치, 물체 유형과 같은 변수를 지정합니다.
- Agility는 Digit의 가격을 공개하지 않았으나, 각 로봇의 비용은 시간당 10달러에서 25달러 사이라고 밝혔습니다. 반면 Schaeffler 공장의 초급 직무 임금은 시간당 20달러입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Batch의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기