Gemma 4 12B — 인코더 프리(Encoder-free) 아키텍처로 구현하는 온디바이스 멀티모달 AI
요약
Google이 온디바이스 멀티모달 에이전트 워크플로를 위해 설계한 Gemma 4 12B를 공개했습니다. 별도의 인코더 없이 단일 디코더 구조를 사용하는 Encoder-free 아키텍처를 통해 레이턴시를 줄이고 효율성을 극대화했습니다.
핵심 포인트
- Encoder-free 아키텍처로 레이턴시 및 메모리 효율 개선
- 비전 및 오디오 데이터를 LLM 은닉 공간에 직접 사영
- 단일 디코더 구조로 파인튜닝 프로세스 간소화
- Google AI Edge와 결합하여 로컬 온디바이스 실행 최적화
본 기사는 Gemma 4 12B Enables On-Device, Multimodal Agentic Workflows with an Encoder-free Architecture의 일본어 번역 및 해설이다. 원저자는 Sergio De Simone (InfoQ)이다.
Gemma 4 12B — 인코더 프리(Encoder-free) 아키텍처로 구현하는 온디바이스 멀티모달 AI
Google은 노트북 상에서 에이전트적·멀티모달 워크플로(Workflow)를 직접 실행하는 것을 염두에 두고 설계한 모델인 「Gemma 4 12B」를 공개했다. Google은 본 모델에 대해 "에이전트적인 멀티모달 인텔리전스를 노트북에 직접 가져오기 위해 설계되었다"라고 설명하며, Google AI Edge와 결합함으로써 "일상적인 머신에서 로컬로 빌드 및 실험할 수 있다"라고 밝혔다. 이러한 통합을 통해 자율적인 데이터 처리부터 시각적 인사이트 생성, 웹 페이지 구축, 도구 실행에 이르기까지 폭넓은 용도가 가능해진다.
인코더 프리(Encoder-free) 아키텍처의 개요
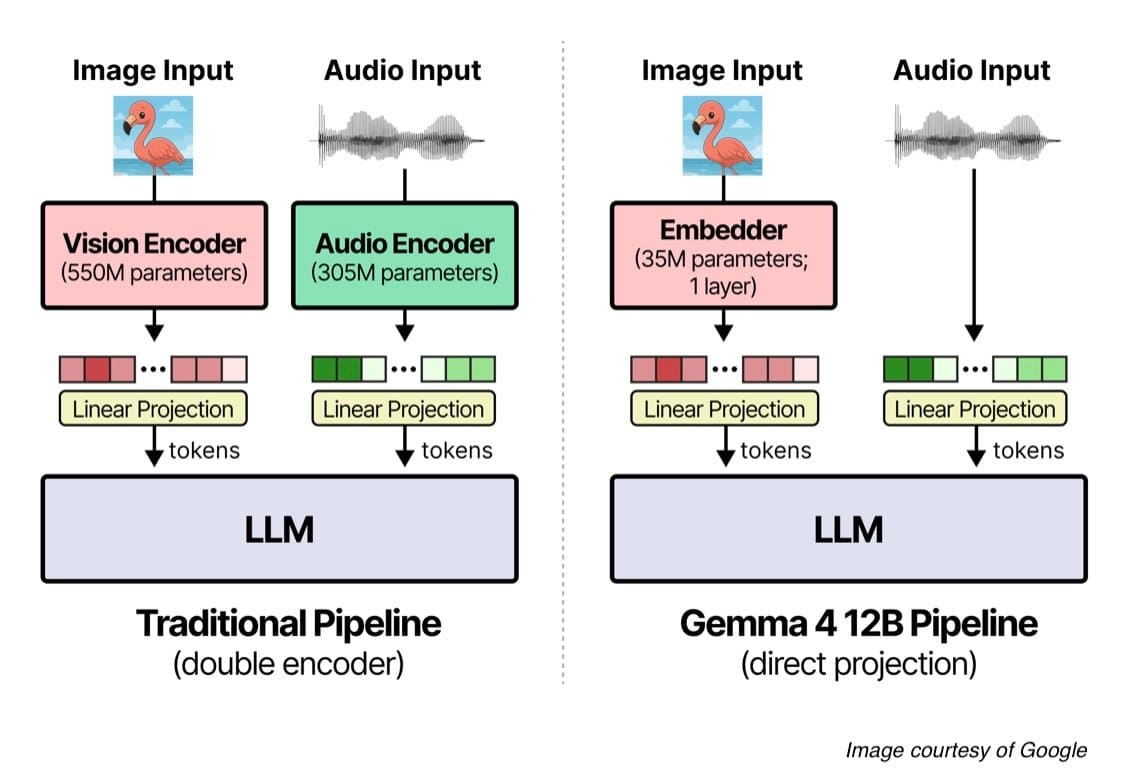
Gemma 4 12B의 가장 큰 특징은 새로운 통합 멀티모달 인코더 프리(Encoder-free) 아키텍처를 채택하고 있다는 점에 있다. 기존의 멀티모달 모델이 의존했던 영상·음성별 독립된 인코더(Encoder)를 통한 전처리 단계를 폐지하고, 멀티모달 데이터를 LLM에 직접 입력하는 설계로 되어 있다.
기존 방식의 멀티모달 모델에서는 별도의 비디오 인코더(Video Encoder)나 오디오 인코더(Audio Encoder)를 전단 처리로 사용했기 때문에, 레이턴시(Latency) 증가나 메모리 풋프린트(Memory Footprint)의 파편화라는 비효율이 발생했다. Gemma 4 12B는 이러한 문제를 Gemma 4 31B Dense 모델과 동일한 고도의 디코더 구조를 포함하는 단일 디코더 온리 트랜스포머(Decoder-only Transformer)로 해결하고 있다.
비전 처리 방식
비전 처리에서는 **3,500만 파라미터의 비전 임베더(Vision Embedder)**가 다른 중규모 Gemma 4 모델에서 사용되었던 27층의 비전 트랜스포머(Vision Transformer)를 대체한다. 가공되지 않은 **48×48 픽셀의 패치(Patch)**를 단일 행렬 곱셈을 통해 LLM의 은닉 공간(Hidden Space)에 직접 사영(Projection)하며, 입력 단계에서는 인수분해된 X–Y 좌표 룩업(Lookup)을 통해 공간적인 위치 정보를 주입하는 설계로 되어 있다.
오디오 처리 방식
오디오 처리에서도 마찬가지로 독립된 오디오 인코더를 필요로 하지 않는다. 대신, 16 kHz의 음성을 40밀리초 프레임(640 샘플)으로 직접 슬라이스하고, 이를 LLM의 입력 공간에 선형 사영하는 「오디오 웨이브 프로젝션(Audio Wave Projection)」 메커니즘을 채택하고 있다.
파인튜닝(Fine-tuning)의 이점
멀티모달 입력에 동일한 가중치를 사용하는 아키텍처상의 이점은 파인튜닝(Fine-tuning)에도 미친다. LoRA와 같은 어댑터(Adapter)나 전체 튜닝(Full Tuning)을 사용할 때, 멀티모달 루프 전체를 단 한 번의 패스(Pass)로 업데이트할 수 있기 때문에 튜닝 작업이 대폭 간소화된다.
액세스 수단 및 대응 플랫폼
Gemma 4 12B는 다음 수단을 통해 액세스할 수 있다.
- Google AI Edge Gallery 쇼케이스 앱
- Google AI Edge Eloquent — 온디바이스 음성 받아쓰기 앱 LiteRT-LM
Google AI Edge Gallery 앱에서는 개발자가 "스크립트를 즉석에서 생성·실행"하여 자연어 지시를 동작하는 코드로 변환할 수 있다. Google이 보여준 데모에서는 2024년과 2025년에 태어난 여자아이 이름 상위 10개를 비교하는 PNG 차트를 렌더링하는 Python 프로그램을 생성하는 능력이 공개되었다.
또한, LiteRT-LM의 litert-lm serve 명령으로 OpenAI 호환 서버를 기동함으로써 OpenCode 등의 기존 하네스(Harness)와도 연동할 수 있다. llama.cpp와의 조합도 가능하다. 모델 입수처로는 Hugging Face, Ollama, LM Studio, Google Cloud 등 여러 플랫폼을 지원한다.
# LiteRT-LM으로 OpenAI 호환 서버를 기동하는 예
litert-lm serve
커뮤니티의 반응
Reddit에서 LoveMind_AI는 "이것은 오랫동안 들어본 것 중 가장 흥미로운 모델 중 하나일지도 모른다. 인코더 프리 (Encoder-free) 모델은 정말 멋지다. 12B 모델에서 네이티브 오디오 (Native Audio)를 사용할 수 있다는 점은 매우 흥분되는 일이다"라고 작성했다.
Wrong_Mushroom은 인코더 프리 (Encoder-free) 방식의 장점으로, "이미지나 음성을 추가 파일 없이 공유할 수 있게 된다. 또한, 모델의 데이터셋이 이를 염두에 두고 훈련된다는 것을 의미하므로, 이론적으로는 더 높은 정확도를 가질 것이다"라고 설명했다.
코딩 능력에 대한 평가
코딩 능력에 대해서는 회의적인 의견이 있는 한편, 실제로 활용할 수 있었다는 보고도 올라오고 있다. 한 댓글 작성자는 "서버와 클라이언트 사이드 (Client-side)를 갖춘 Python 앱을 빌드하는 데 사용했다. 그 결과물에 놀라고 있다. 컨텍스트 (Context)는 (좋은 의미로) 엄청나다. 실수 없이 방대한 양의 작업을 원샷 (One-shot)으로 해내고 있다"라고 언급했다.
반면, triynizzles는 "단순한 작업에서는 준수한 성능을 발휘하지만, qwen 3.6의 대체재는 될 수 없다"라는 견해를 밝혔다. 코드 경로를 설명하거나 로직의 버그를 수정하는 데에는 충분히 기능했지만, "더 모호한 요구사항에 대해서는 무너지기 시작할 것이다"라고 설명했다.
모델의 아키텍처 (Architecture)에 대해 더 깊이 알고 싶은 독자라면, Maarten Grootendorst의 상세 분석을 참조할 것을 권장한다.
출처:
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기