
Fireworks를 활용하여 100배 더 저렴한 Trace Judge 구축하기
요약
LangSmith가 Fireworks와 협력하여 비용 효율적인 '인지된 오류(Perceived Error)' 감지 모델을 구축했습니다. Qwen 모델을 미세 조정하여 프론티어 모델 수준의 성능을 유지하면서도 비용을 최대 100배 절감했습니다.
핵심 포인트
- Qwen 모델 미세 조정을 통해 저비용 고성능 Trace Judge 구현
- 사용자의 수정, 거부, 반복 요청 등 트레이스 신호 기반 오류 감지
- 프론티어 모델 대비 최대 100배 저렴한 비용으로 운영 가능
- 에이전트 시스템의 프로덕션 환경 모니터링 효율성 극대화
핵심 요약 (Key Takeaways)
- LangSmith는 프로덕션 트레이스(production traces) 전반에 걸쳐 하루에 수십억 개의 토큰을 처리합니다. 우리의 핵심 과제 중 하나는 이러한 트레이스 전반에서 신호(signals)를 효율적으로 채굴하는 것입니다.
- 우리는 효율적인 Trace Judge를 구축하기 위해 Fireworks와 파트너십을 맺었습니다. 우리는 모든 프로덕션 트레이스에서 "인지된 오류 (Perceived Error)"를 감지하도록 Qwen 모델을 미세 조정(fine-tuned)했습니다. 이 모델은 프론티어 모델(frontier model)의 성능과 일치하거나 이를 능가하며, 비용은 최대 100배 더 저렴합니다. - 이 "인지된 오류" 모델의 조기 테스터가 되고 싶다면, 여기에서 신청해 주세요.
에이전트(Agents)는 이제 전 세계 데이터의 대부분을 생성하며 우리가 오늘날 사용하는 많은 애플리케이션을 구동합니다. 더 많은 에이전트가 프로덕션 환경으로 이동함에 따라, 트레이스는 에이전트 시스템이 실제 사용자와 어떻게 상호작용하는지 이해할 수 있는 가장 풍부한 데이터 소스 중 하나로서 더욱 중요해질 것입니다.
연구 질문: 어떻게 하면 **프론티어 성능 (frontier performance)**을 유지하면서, 모든 개별 트레이스에서 중요한 신호를 비용 효율적으로 채굴할 수 있을까?
이 질문에 답하기 위해, 우리는 Fireworks와 협력하여 사용자 상호작용에서 "인지된 오류 (Perceived Error)"를 감지하는 Qwen judge 모델을 미세 조정(fine-tune)했습니다.
인지된 오류 (Perceived Error)란 무엇인가:
인지된 오류는 사용자가 어시스턴트가 실수를 했거나 수정이 필요한 결과물을 생성했다고 생각하는 경우를 의미합니다. 인지된 오류는 객관적인 정확성이나 사용자의 행복도를 판단하는 것이 아닙니다. 예를 들어, 에이전트가 정답을 제공했더라도 사용자가 (에이전트가 아닌) 정보 자체에 대해 좌절감을 느낄 수 있습니다.
우리는 보통 팀들이 애플리케이션 특화 평가자(application specific evaluators)를 구축하도록 권장합니다. 트레이스를 판단하는 로직에는 해당 애플리케이션의 문맥(context)이 필요할 때가 많기 때문입니다. 하지만 우리는 "인지된 오류"가 범용적으로 사용될 수 있는 평가자의 한 예라고 믿습니다. 이 평가자가 찾는 신호들은 애플리케이션 전반에 걸쳐 보편적일 것이라고 믿습니다.
"인지된 오류"의 범용성은 핵심적인 질문입니다. 이후에 진행할 실험 중 일부는 이 지표의 범용성을 테스트하는 것을 구체적인 목표로 합니다.
우리는 사용자의 수정(user corrections), 에이전트 동작의 거부(rejection of an agent action), 반복된 요청(repeated requests), 그리고 에러에 대한 어시스턴트의 인정(assistant acknowledgements of errors)과 같은 트레이스 신호(trace signals)로부터 인지된 오류(perceived error)를 추론합니다. 그러면 인지된 오류 평가기(perceived error evaluator)는 아래와 같은 형식의 정보로 트레이스를 풍부하게 만듭니다.
{"perceived_error": true, "reason": "사용자가 어시스턴트가 사용한 회의 날짜를 수정합니다."}
데이터셋 구축 방법
태스크에 적용되는 에이전트는 해당 에이전트를 학습시키는 데 사용된 데이터의 품질만큼만 성능을 발휘합니다. 우리는 프로덕션에서 사용하는 두 가지 내부 트레이싱 데이터셋(internal tracing datasets)에서 데이터를 확보했습니다.
LangChain의 라이브러리와 제품에 관한 질문에 답하는 Docs Q&A 에이전트입니다. 사용자는 개념적인 질문, 디버깅 질문, 또는 무언가를 만드는 데 필요한 도움을 요청할 수 있습니다. 이러한 대화는 종종 기술적이며 상당한 수준의 세부 정보를 포함합니다.
문서 작성이나 리서치와 같이 실제 작업을 수행하는 에이전트를 생성하기 위한 노코드(no-code) 도구입니다. 사용자는 다양한 태스크를 위해 Fleet을 사용할 수 있습니다. 이들은 매우 다양한 도구(tools)나 스킬(skills)을 호출할 수 있습니다.
우리는 각 트레이싱 데이터셋에서 트레이스의 일부를 선택하여 학습 세트(training set)와 홀드아웃 세트(holdout set)로 구성했습니다. 트레이스 풀(pool of traces)에서 필터링할 때, 우리는 멀티 턴 트레이스(multi-turn traces)를 선택했는데, 이는 "인지된 오류"를 판단하기 위해서는 AI 결과에 대한 인간의 반응(예: 어시스턴트를 수정하거나 요청을 반복하는 것)이 필요하기 때문입니다.
여러 데이터셋을 사용한 동기 중 일부는 "인지된 오류"의 범용성을 테스트하기 위함이었습니다. 하나의 데이터셋에서 인지된 오류를 감지하도록 학습된 모델이 두 번째 데이터셋으로 전이(transfer)될 수 있을까요?
데이터 준비 (Data Preparation)
학습 및 예측을 위한 데이터를 준비할 때, 우리는 모든 도구 호출(tool calls)을 무시하고 인간(Human)과 AI의 메시지만 포함하기로 결정했습니다. 우리가 찾고자 하는 신호들에 있어 인간과 AI의 메시지가 주요 정보원이라는 가설을 세웠기 때문입니다. 이는 향후 우리가 실험해 보고자 하는 레버(lever) 중 하나입니다.
또한 긴 콘텐츠를 자르지 않고 모든 메시지를 있는 그대로 포함했습니다. 이 역시 향후 실험해 보고자 하는 또 다른 레버입니다.
레이블 (Labels)
레이블을 생성하기 위해, 우리는 모델 보조 레이블링 (model-assisted labeling)과 인간 검토 (human review)를 혼합하여 각 트레이스 (trace)에 대한 짧은 JSON 레이블과 근거 (rationales)를 생성했습니다. 구체적으로, 먼저 모델 패널에게 트레이스를 판단하도록 요청했습니다. 만약 모델들이 모두 동의한다면, 이를 정답 레이블 (ground truth label)로 채택했습니다. 만약 의견이 일치하지 않는다면, 그들의 모든 레이블과 근거를 가져와 또 다른 모델 패널에게 전달하여 누구의 판단이 맞는지 판단하도록 요청했습니다. 해당 패널이 동의한다면, 이를 정답 (ground truth)으로 채택했습니다. 만약 그들조차 의견이 일치하지 않는다면, 우리가 직접 수동으로 어노테이션 (human annotated)을 수행했습니다. 전체 데이터셋에 걸쳐 chat-langchain과 Fleet은 각각 24%와 18%의 트레이스에서 오류로 인지된 레이블 (perceived error label)을 가졌습니다.
파인튜닝 설정 (Fine-tuning setup)
학습을 위해, 우리는 다른 모델들을 테스트하는 몇 차례의 소규모 실험을 거친 후 Qwen-3.5-35B를 베이스 모델 (base model)로 선택했습니다. 훨씬 더 작은 모델들은 오류율이 높았고 우리의 멀티턴 트레이스 (multi-turn traces)를 추론할 만큼 강력하지 않았습니다. Qwen-3.5-35B를 사용함으로써, 우리는 파인튜닝 (fine-tuning)을 통해 프런티어 성능 (frontier performance)에 도달할 수 있는 여지를 가진, 강력하고 저렴한 오픈 모델을 확보할 수 있었습니다.
우리는 chat-langchain 데이터셋의 데이터로만 학습했습니다. 단 하나의 데이터셋으로만 학습한 이유는 이것이 완전히 다른 도메인으로 전이 (transfer)될 수 있는지 테스트하기 위함이었습니다.
또한 베이스 모델에 대한 소규모 실험에서 공통적인 실패 모드 (failure modes)를 관찰한 후 입력 프롬프트 (input prompt)를 가볍게 최적화했습니다. 학습을 위해, 우리는 Fireworks에서 LoRA를 사용하여 관리형 SFT (managed SFT) 학습을 진행했습니다.
실험 및 결과 (Experiments & results)
우리는 세 가지 질문을 중심으로 실험을 구성했습니다:
- 파인튜닝이 베이스라인 판사 (baseline judge)의 품질을 프런티어 모델 성능까지 향상시키는가?
- 학습된 판사가 데이터셋 간에 전이되는가?
- 파인튜닝된 모델을 서빙하는 것이 비용 효율적인가?
오픈 모델의 파인튜닝은 프런티어 모델을 능가하거나 대등할 수 있음
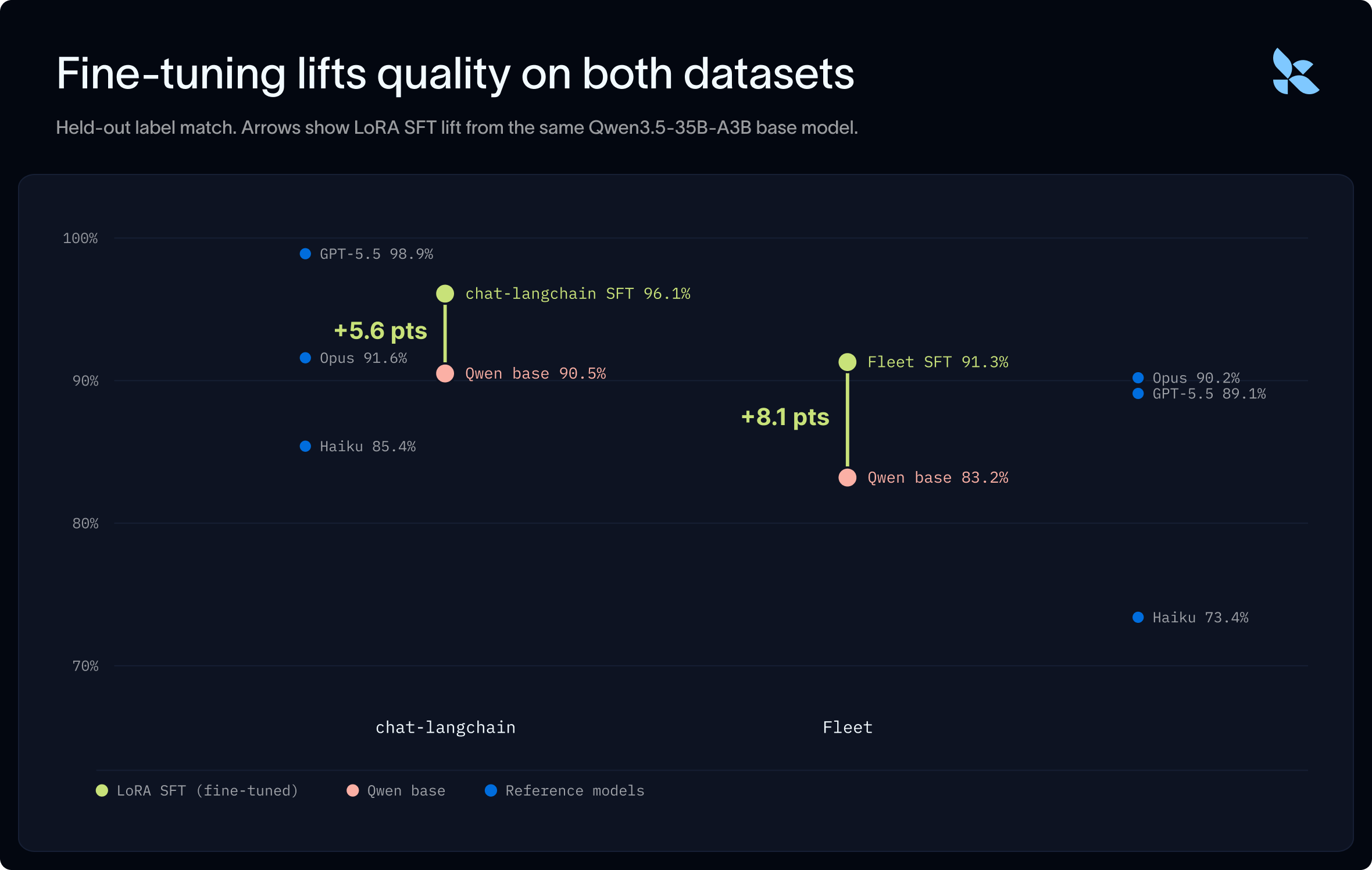
우리는 적절한 프롬프팅 (prompting)을 적용한 베이스 Qwen 모델이 오류 인지 분류 (perceived error classification)에 있어 강력한 즉시 사용 가능한 (out of the box) 모델임을 발견했지만, 프런티어 모델의 분류 정확도에는 뒤처졌습니다. 두 데이터셋 모두에서, LoRA SFT 작업을 실행한 결과 베이스 모델의 성능이 프런티어 성능에 근접하거나 이를 상회하도록 끌어올려졌습니다.
프런티어 모델(frontier models)과의 벤치마킹 외에도, 우리는 더 작고 저렴한 모델들과도 비교했습니다. 대규모의 저비용 추론(inference) 워크로드를 실행하기 위한 일반적인 전략은 Haiku와 같은 가장 작은 폐쇄형 프런티어 모델을 사용하는 것입니다. 하지만 우리는 강력한 오픈 모델들이 훨씬 더 저렴한 비용으로 실행되면서도, 별도의 추가 학습 없이도(out of the box) Haiku보다 뛰어난 성능을 일관되게 보여준다는 것을 발견했습니다.
미세 조정된 판사(Fine-tuned judge)는 미학습 데이터에도 잘 전이됩니다
우리의 초기 결과는 Fleet가 모든 모델에게 더 도전적인 데이터셋임을 보여주었습니다. chat-langchain 데이터로 미세 조정(fine-tuning)을 수행한 후, 우리는 이 모델이 Fleet 전용 학습 없이 Fleet 데이터로 얼마나 잘 전이(transfer)되는지 테스트했습니다. chat-langchain 데이터로 학습된 모델은 Fleet 데이터에서 모든 프런티어 모델의 성능을 능가했습니다.
그 후 우리는 Fleet 데이터에 특화하여 모델을 학습시키는 실험을 진행했습니다. 그 결과, chat-langchain SFT(Supervised Fine-Tuning) 모델보다 약간의 성능 향상이 있었습니다.
이것은 다음과 같은 이유로 중요한 결과입니다:
- 우리가 인지한 에러 모델(perceived error model)이 다른 도메인으로 전이될 수 있으며, 여전히 프런티어 수준(이 경우에는 그보다 약간 높은 수준)의 성능을 유지할 수 있음을 보여줍니다.
- 자신의 데이터셋에서 인지된 에러(또는 기타 미세 조정된 판사)의 성능을 더욱 높이고 싶은 개발자들은, 추가적인 성능 향상을 위해 애플리케이션 특화 트레이스(application specific traces)로 미세 조정을 할 수 있는 옵션이 있습니다.
미세 조정된 모델은 실행 비용이 훨씬 저렴합니다
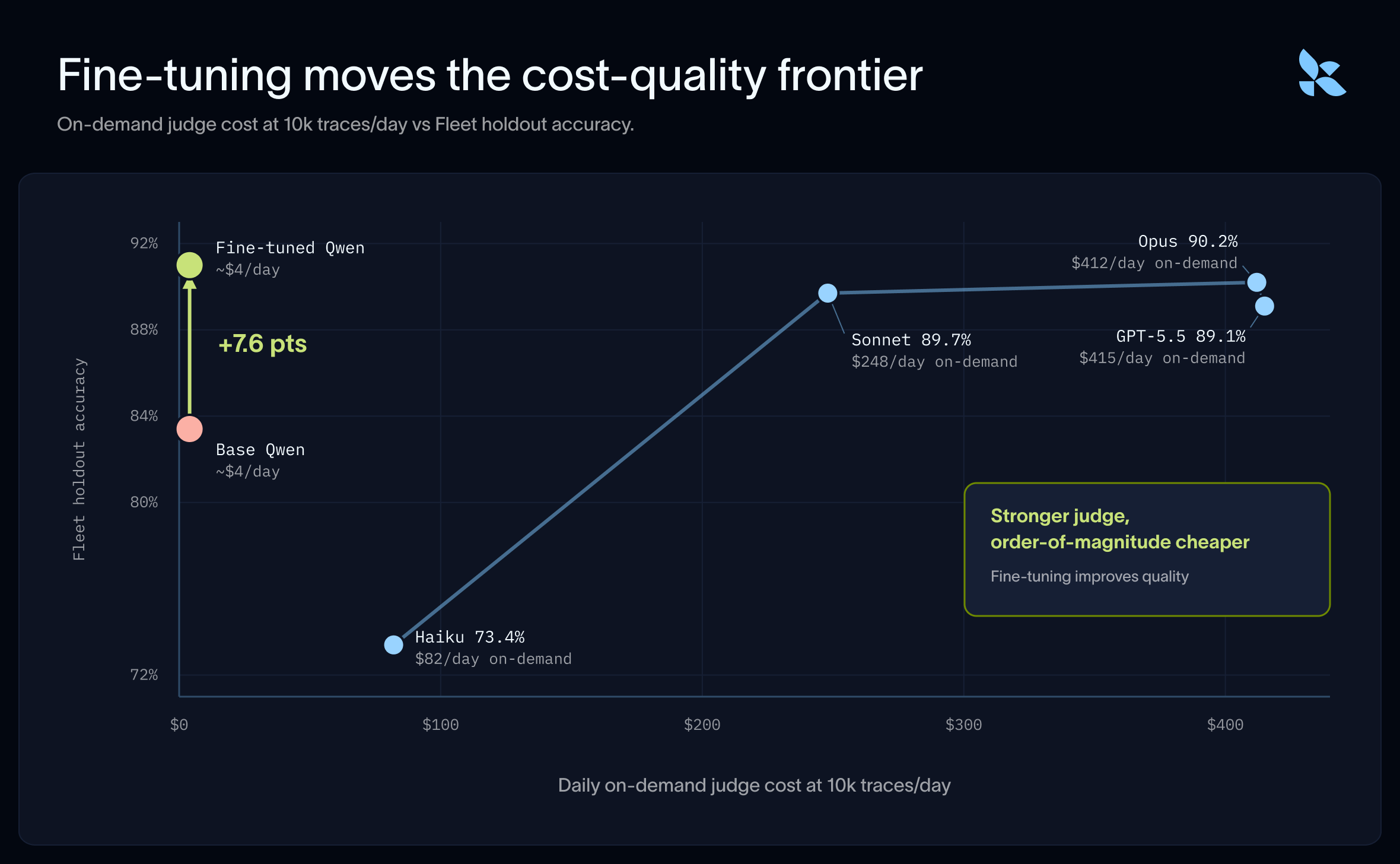
미세 조정된 모델은 프런티어 모델의 정확도와 일치하면서도, 트레이스(trace) 양과 모델 선택에 따라 규모에 따라 실행할 때 10~100배 더 저렴합니다. 트레이스 양이 증가함에 따라 미세 조정된 모델을 통한 비용 절감 효과는 계속해서 커집니다. 그리고 성능 면에서, 미세 조정된 Qwen 모델은 모든 크기의 모델인 Haiku, Sonnet, Opus (그리고 gpt-5.5)를 능가합니다.
트레이스 이해에 관한 향후 연구
지속적 학습(Continual Learning)을 해결하는 것은 트레이스 이해를 둘러싼 대규모 데이터 마이닝 문제를 다루는 것을 포함할 것입니다. 일반적으로 우리는 트레이스를 더 잘 이해하기 위해 특화되고 비용 효율적인 모델을 구축하는 레시피를 발전시켜 나가는 것에 대해 기대하고 있습니다.
오픈 모델 (Open models)은 지능의 임계점을 넘어섰으며, 이제 많은 작업에 대해 별도의 튜닝 없이도 강력하고 비용 효율적인 분류기 (classifiers) 역할을 수행합니다. Fireworks의 사용하기 쉬운 학습 및 추론 인프라를 통해, 우리는 오픈 모델의 성능을 프런티어 (frontier) 수준으로 끌어올리는 동시에 운영 비용을 수십 배 더 저렴하게 유지할 수 있습니다.
향후 연구 방향에는 팀들이 에이전트 트레이스 (agent traces)를 위한 자체 평가 모델 (evaluator models)을 구축할 수 있도록 좋은 학습 목표 (training objectives) 및 루브릭 (rubrics)을 설계하는 것을 돕는 것이 포함됩니다. 에이전트 트레이스를 더 많이 이해할수록, 에이전트를 개선하기 위한 변경 사항을 적용할 때 더 정확한 정보를 바탕으로 결정할 수 있습니다.
우리의 인지 오류 모델 (perceived error model)을 체험해 보세요
우리는 향후 한두 달 내에 광범위한 출시를 진행하기에 앞서, 앞으로 몇 주 동안 선정된 일부 고객을 대상으로 미세 조정된 (fine-tuned) 인지 오류 모델을 출시할 예정입니다. 이 인지 오류 판사 (perceived error judge)를 테스트하고 피드백을 제공하는 데 관심이 있으시다면, 여기에서 신청해 주세요.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기