digiKam이 당신을 이해하도록 가르치기: 로컬 LLM을 활용한 자연어 검색
요약
GSoC 프로젝트의 일환으로 digiKam에 로컬 LLM을 통합하여 자연어 기반 사진 검색 기능을 구현하는 설계 과정을 소개합니다. LLM이 직접 데이터를 검색하는 대신 사용자의 자연어 의도를 구조화된 쿼리로 번역하는 '번역가' 역할을 수행하도록 설계되었습니다.
핵심 포인트
- LLM을 활용해 복잡한 고급 검색 기능을 자연어 인터페이스로 전환
- 모델이 직접 검색하지 않고 구조화된 쿼리로 번역하는 안전한 설계 방식 채택
- 데이터베이스 직접 접근을 차단하여 환각(Hallucination) 및 보안 문제 방지
- 로컬 LLM을 활용한 개인정보 보호 및 효율적인 검색 파이프라인 구축
GSoC 2026 • digiKam • Post 1: 설계 및 진행 상황
저는 십 대 시절부터 KDE 앱 주변을 맴돌아 왔기에 :), 이번 여름을 다시 그 안에서 보내게 된 것은 마치 집에 돌아온 것 같은 기분이 듭니다. 이번에는 바로 digiKam입니다!
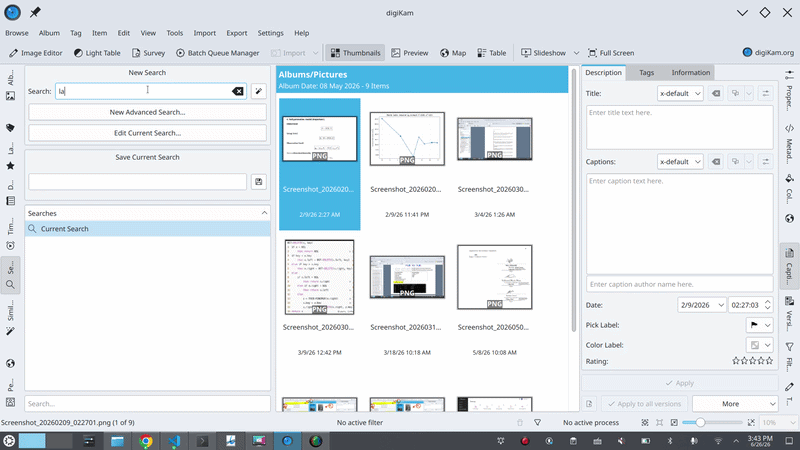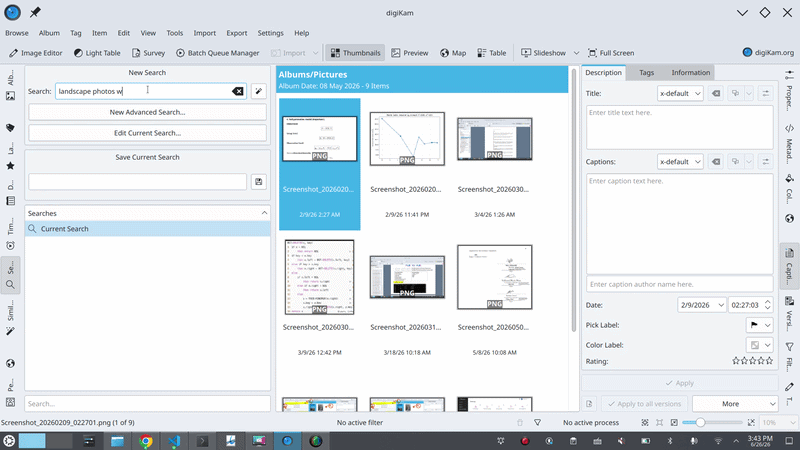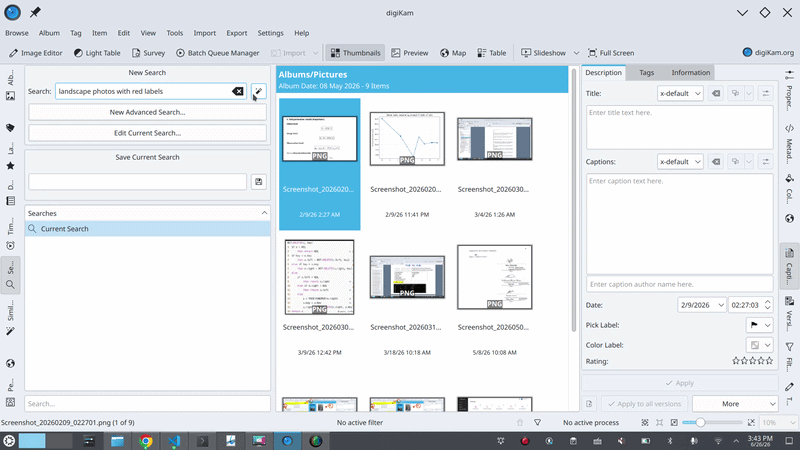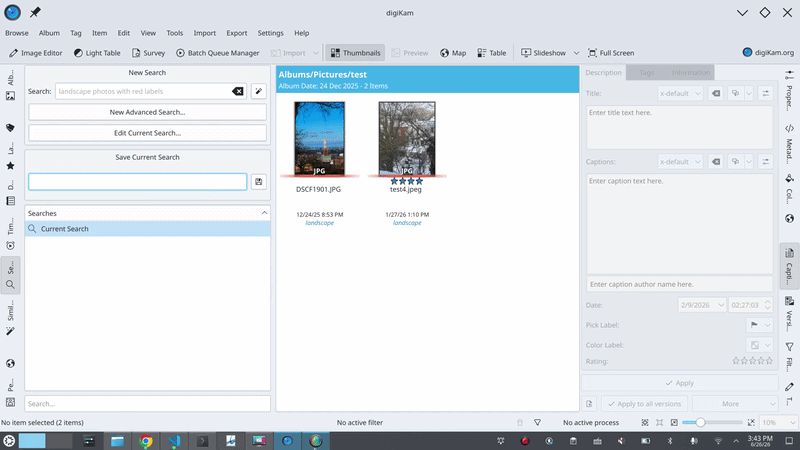
제가 digiKam이 해주길 바라는 것은 다음과 같습니다: 검색창에 “지난 여름에 찍은 사진 중 별점이 높은 산 사진들”이라고 입력하면, 그것이 그냥... 찾아내는 것입니다. 복잡한 필터도, 어디를 클릭해야 할지 고민할 필요도 없이, 마치 여행을 함께 다녀온 친구에게 말하듯 평범한 영어(자연어)로 말이죠.
이것이 한 문장으로 요약된 저의 GSoC 프로젝트입니다: digiKam의 검색 엔진을 AI 기반의 **LLM (Large Language Model)**과 인터페이스하여, 사용자가 자연어로 사진 컬렉션을 검색할 수 있도록 하는 것입니다. 많은 사용자에게 digiKam의 Advanced Search (고급 검색) 기능은 강력하지만 다소 위협적으로 느껴질 수 있는 숨겨진 보석과 같습니다. 자연어 지원을 추가함으로써, 우리는 초보자부터 시간을 절약하고 싶은 전문가에 이르기까지 모든 사람이 이 기능을 쉽게 사용할 수 있도록 만들고 있습니다. 그리고 수년간 KDE 앱을 사용해 온 사람으로서, digiKam의 강력한 기능과 원하는 것을 단순히 묻는 것 사이의 간극을 메운다는 아이디어가 정말 마음에 들었습니다.
저는 최근 트랜스포머 (transformers)를 깊이 파고들고 있었는데, 이 프로젝트는 실제 소프트웨어 개발과 LLM에 대한 실제적인 이해(어떤 아키텍처가 어디에 적합한지, 인코더 (encoder) 대 디코더 (decoder) 중 언제 무엇을 원하는지, 그리고 모델이 실제 애플리케이션에 연결되었을 때 어떻게 작동하는지 등)가 거의 완벽하게 결합된 프로젝트로 다가왔습니다.
이 첫 번째 포스트는 전반적인 설계와 지금까지의 진행 상황에 관한 것입니다. 어떤 모델을 사용할지, 얼마나 빠를지, 얼마나 정확할지와 같은 실제 언어 모델에 관한 더 흥미로운 부분들은 두 번째 포스트에서 다룰 예정이니, 이번 글은 배경 설정 단계라고 생각해주세요.
(약간의 기술적인 내용이 포함되어 있지만, 어려운 부분은 선택 사항으로 남겨두겠다고 약속합니다. ;) )
프로젝트 전체의 근간이 되는 하나의 아이디어
digiKam에는 이미 강력한 Advanced Search (고급 검색) 기능이 있습니다. 태그, 날짜, 별점, 앨범, 색상 라벨 등을 위한 드롭다운 메뉴가 가득 찬 대화 상자입니다. 복잡한 쿼리를 처리할 수 있지만, 사용자가 이를 탐색하는 방법을 알아야 합니다.
따라서 제 프로젝트의 **LLM (Large Language Model)**은 사용자의 사진을 직접 검색하지 않습니다. 이 점을 다시 한번 강조하겠습니다. 이는 가장 중요한 설계 결정이기 때문입니다. 모델은 데이터베이스를 절대 건드리지 않으며, 무엇이 일치하는지 결정하지도 않고, 결과를 지어내지도 않습니다. 모델이 하는 일은 오직 사용자의 문장을, 사용자가 직접 대화 상자를 클릭하여 만들 수 있는 것과 정확히 동일한 구조화된 쿼리(structured query)로 **번역(translate)**하는 것뿐입니다. 모델은 '의도(intent)'를 생성하고, digiKam의 기존의 신뢰할 수 있는 검색 엔진이 실제 검색을 수행합니다.
저는 이러한 프레임워크가 AI의 역할을 명확한 영역 안에 머물게 한다는 점이 마음에 듭니다. LLM은 이미 존재하는 문 앞에 앉아 있는 번역가와 같습니다. 새로운 문을 만드는 것이 아니며, 멋대로 돌아다니며 무언가를 지어내는 것도 결코 허용되지 않습니다. 모델이 생성하는 모든 것은 사람이 클릭을 통해 생성할 수 있는 것입니다. 이것이 안전 보장 장치이며, 파이프라인의 모든 요소는 이를 강제하도록 구축되었습니다.
파이프라인의 작동 방식
사용자의 쿼리가 거치는 여정은 다음과 같습니다:
사용자의 문장
|
v
...
단계별 설명:
- 사용자가 문장을 입력합니다.
- **프롬프트 빌더 (prompt builder)**가 모델에게 어떤 형식으로 답변해야 하는지 정확히 알려주는 지침과 함께 문장을 감쌉니다.
- **언어 백엔드 (language backend)**가 모델을 실행하고 답변을 받아옵니다.
- **의도 파서 (intent parser)**가 그 답변을 읽고, 무엇보다도 이를 *엄격하게 검증(validates it strictly)*합니다. 모델의 출력값은 결코 직접적으로 신뢰되지 않습니다. 만약 출력값이 형식이 올바르지 않거나 알려진 필드 및 연산자와 일치하지 않으면 즉시 거부됩니다. 부분적인 추측은 허용되지 않습니다.
- **기능 사전 (capability dictionary)**이 모호한 인간의 단어를 digiKam의 실제 필드에 매핑합니다. 예를 들어, "최고(best)"는 높은 별점이나 "Accepted" 선택 라벨을 의미할 수 있고, "색상 라벨(colour label)"은 실제 색상 라벨 필드에 매핑되는 식입니다.
- **의도 해결사 (intent resolver)**가 검증되고 매핑된 의도를 구체적인 검색 기준으로 변환합니다.
- 해당 기준들이 고급 검색(Advanced Search) 위젯을 채우게 되며, digiKam은 사용자가 직접 수동으로 입력한 것과 똑같이 검색을 실행합니다.
이렇게 분리함으로써 얻는 좋은 결과는 모델을 우리가 원하는 만큼 작고 단순하게 만들 수 있다는 점이며, 그 이후의 모든 레이어(layer)는 모델이 숙제를 제대로 했는지 재차 확인하는 데 집중한다는 것입니다. 만약 모델이 터무니없는 말을 한다면 파서(parser)가 이를 잡아냅니다. 만약 모델이 존재하지 않는 필드 이름을 지정한다면 사전(dictionary)이 이를 매핑하지 못할 것입니다. 어떤 정보가 데이터베이스(database)에 도달할 때쯤이면, 이미 "이것이 실제로 digiKam이 할 수 있는 일인가?"라는 여러 단계의 검증 과정을 거쳐 정제된 상태가 됩니다.
왜 로컬 모델(Local Models)인가?
잠시 중요하게 짚고 넘어가야 할 부분이 있습니다. 모델은 특정 회사의 클라우드(cloud)가 아니라 사용자의 기기에서 *로컬(locally)*로 실행됩니다. 모델을 로컬에서 실행하는 것은 단순히 성능 때문만이 아니라, 프라이버시(privacy) 때문입니다.
그리고 여기서 프라이버시는 처음 생각하는 것보다 훨씬 더 중요합니다. 사진 라이브러리에 실제로 무엇이 들어있는지 생각해 보세요. 당신이 어디에 사는지, 가족과 친구가 누구인지, 어디로 언제 여행을 갔는지, 집 안의 모습, 당신의 아이들, 그리고 당신에게 중요한 사건들 말입니다. 사진 컬렉션은 사람이 컴퓨터에 보관하는 가장 개인적인 것 중 하나입니다. 또한 그 사진들을 대상으로 실행하는 검색(searches) 자체도 매우 많은 것을 드러냅니다. 사진을 찾기 위해 입력하는 단어들은 당신이 무엇을 찾고 있는지, 그리고 왜 찾는지에 대해 말해줍니다.
만약 이 중 어떤 것이라도 처리를 위해 원격 서버(remote server)로 전송된다면, 당신은 대부분의 사람들이 가장 넘겨주고 싶지 않아 할 바로 그 정보를 제3자에게 맡기는 셈이 됩니다. 모든 것을 기기 내(on-device)에서 실행하면 이 문제를 완전히 피할 수 있습니다. 당신의 사진은 기기를 떠나지 않고, 당신의 쿼리(queries)도 기기를 떠나지 않으며, 계정도, API 키도, 인터넷 연결도 필요하지 않습니다. 이 기능은 집에서와 마찬가지로 비행기 안에서도 동일하게 작동합니다.
문제는 로컬 모델이 매우 큰 파일이라서 어떻게든 사람들의 컴퓨터에 옮겨야 한다는 점인데, 이는 제가 이번 기간 동안 실제로 구축하는 데 대부분의 시간을 보낸 부분으로 이어집니다.
digiKam 인프라에 연결하기
C++는 10대 시절부터 제가 가장 좋아했던 언어이며, 이번 프로젝트의 소소한 즐거움 중 하나는 이를 제대로 다시 다듬을 수 있었다는 점입니다. 하지만 Qt는 이야기가 다릅니다. 제 Krita 관련 포스트를 읽어보셨다면 익숙하실 것입니다. Qt와 함께하는 매 순간 저는 조금씩 더 배우게 되지만, 동시에 Qt가 디자인 패턴 (design patterns)에 매우 크게 의존하기 때문에 익숙해지기 어려운 프레임워크 중 하나라는 사실을 매번 깨닫게 됩니다. Qt는 단순히 "배우는" 것이라기보다, 서서히 그것에 놀라지 않게 되는 과정에 가깝습니다.
"모델을 사용자의 컴퓨터로 다운로드해야 한다"는 생각을 처음 했을 때, 제 본능은 그저 파일을 다운로드하는 무언가를 작성하는 것이었습니다. 충분히 간단해 보였죠. 하지만 그 본능은 틀렸습니다. digiKam은 이미 대규모 모델 파일을 다운로드하는 방법을 알고 있습니다. 얼굴 인식 (face recognition), 객체 탐지 (object detection), 자동 회전 (auto-rotation), 미적 점수 산정 (aesthetics scoring)을 위해 수년 동안 그 작업을 수행해 왔습니다. 이를 위한 전체 시스템이 이미 존재합니다. 각 모델을 설명하는 설정 파일을 읽는 중앙 DNNModelManager와, KDE 서버에서 파일을 가져와 검증하는 FilesDownloader가 그것입니다. 제 멘토의 가이드는 명확하고 정확했습니다. 병렬 다운로드 메커니즘을 만들지 말고, 기존 시스템에 연결하라는 것이었습니다.
문제는 이 전체 시스템이 OpenCV 비전 모델 (OpenCV vision models), 즉 이미지를 살펴보는 모델들을 위해 구축되었다는 점입니다. 제가 사용하는 모델은 완전히 다른 라이브러리(llama.cpp)로 실행되는 **언어 모델 (language model)**입니다. 이는 OpenCV 메커니즘에 전혀 맞지 않는 전혀 다른 종류의 괴물입니다.
해결책은 기분 좋게 모듈화되어 있었습니다. 경량화된 DNNModelNaturalLanguage 클래스를 생성함으로써, digiKam의 핵심 로직을 수정하지 않고도 기존 모델 다운로드 시스템에 연결할 수 있었습니다. 이는 GGUF 파일이 digiKam의 다른 AI 모델(예: 얼굴 인식용)과 마찬가지로 다운로드되고, 검증되며, 관리됨을 의미합니다. digiKam에는 이미 존재하는 모델 타입(DNNModelConfig
)이 파일을 등록하고 검증하지만 OpenCV 로딩은 수행하지 않는 방식인데, 이는 제가 필요로 했던 형태와 거의 정확히 일치했기에 제 래퍼(wrapper)도 이를 미러링(mirroring)합니다. 모델의 실제 로딩과 실행은 llama.cpp와 통신하는 SearchLlamaBackend에서 별도로 이루어집니다.
따라서 역할 분담이 깔끔합니다. digiKam의 기존 시스템은 파일을 컴퓨터로 가져오는 작업(다운로드, 체크섬 확인 등 모든 과정)을 처리하고, 저의 llama.cpp 백엔드는 모델을 실행하는 작업을 처리합니다. 중복 작업이 없으며, 제 모델은 digiKam의 다른 모든 모델과 마찬가지로 잘 검증된 경로를 그대로 이용할 수 있습니다.
왜 Qwen2.5-1.5B-Instruct인가
모델 자체에 대해 잠시 언급하겠습니다 (두 번째 포스트에서 더 자세히 다루겠습니다). 저는 몇 가지 이유로 양자화된 GGUF 형식의 Qwen2.5-1.5B-Instruct를 선택했습니다.
크기 대비 성능. 약 1.12 GB(Q4_K_M 양자화 기준)의 크기로 일반 노트북에서도 다운로드하여 실행할 수 있을 만큼 충분히 작지만, 1.5B-Instruct 변체는 지시 사항을 따르고 구조화된 JSON을 생성하는 능력이 진정으로 뛰어나며, 이는 정확히 제가 필요로 하는 기능입니다. 특정 작업에 탁월함. 이 프로젝트의 성패는 모델이 깨끗하고 파싱 가능한 스키마 형태의 출력을 안정적으로 내보내느냐에 달려 있습니다. Qwen2.5는 구조화된 출력(structured outputs)에 있어 눈에 띄게 견고합니다. 라이선스. Apache 2.0 라이선스이므로 자유롭게 재배포가 가능하며, 이는 KDE가 자체 인프라에 파일을 실제로 호스팅할 수 있음을 의미합니다.
왜 디코더 전용(decoder-only) 모델인가 (BERT가 아닌 이유)
특정 모델을 선택하기 전에 모델의 종류를 먼저 정해야 했으며, 이 과정에서 제가 Transformers 관련 문헌을 읽었던 것이 실제로 도움이 되었습니다. 잠시만 제 설명을 따라와 주시기 바랍니다.
“문장을 이해하고 분류한다”는 목적에 가장 당연해 보이는 선택지는 BERT와 같은 인코더 (Encoder) 모델입니다. 인코더는 효율적이고 결정론적(deterministic)이며, 고정된 레이블(fixed-label) 작업에 탁월합니다. 하지만 인코더는 *유한하고 미리 정의된 출력 공간 (finite, predefined output space)*을 가정하며, 이는 검색 쿼리가 가진 특성과 정확히 상충합니다. 쿼리는 무수히 많은 제약 조건을 표현할 수 있으며 (“지난 여름 파리 근처에 빨간색 라벨이 붙은 풍경 사진”은 한 번에 네 가지 제약 조건을 포함합니다), 저는 시간이 지남에 따라 새로운 검색 차원을 계속해서 추가할 것입니다. 이를 인코더에 강제로 맞추려면 의도 분류기 (intent classifiers), 개체 추출기 (entity extractors), 규칙 기반 결합기 (rule-based combiners)와 같은 수많은 보조 도구들이 필요하며, 이러한 구조물은 digiKam에 새로운 검색 필드가 추가될 때마다 점점 더 취약해질 것입니다.
디코더 전용 (decoder-only) 모델은 이 모든 문제를 우회합니다. 이 모델은 *시퀀스 (sequence)*를 생성하므로, 프롬프트에 정의한 스키마 (schema)를 따라 가변적인 수의 구조화된 제약 조건을 JSON 형식으로 직접 출력할 수 있습니다. 새로운 검색 필드가 생기나요? 스키마를 업데이트하기만 하면 되며 재학습은 필요 없습니다. 또한 모호성 (ambiguity)도 우아하게 처리합니다. “최고의 사진”이라는 표현에 대해 하나의 해석만을 강요받는 대신, 동일한 제약된 출력 내에서 명확화를 위한 요청을 내보낼 수 있습니다. (T5와 같은 인코더-디코더 (Encoder-decoder) 모델도 구조화된 출력을 생성할 수 있지만, 로컬 환경의 온디맨드 (on-demand) 데스크톱 기능으로 사용하기에는 불필요한 아키텍처 및 지연 시간 (latency) 오버헤드가 발생합니다.)
요약하자면 다음과 같습니다. 작은 규모의 디코더 전용 모델은 노트북에서도 실행 가능한 크기로, 모호성 처리가 내장된 상태에서 구성 가능하고(compositional) 스키마 형태를 따르는 생성을 제공합니다. 이것이 제가 원하던 모든 것입니다.
이 모든 것은 llama.cpp를 이용한 CPU 추론의 표준인 GGUF 형식의 4비트 (Q4) 양자화 (quantization)를 가정합니다.
| 모델 | 파라미터 (Params) | 크기 (Q4) | 라이선스 (Licence) | 비고 |
|---|---|---|---|---|
| Qwen2.5-1.5B-Instruct | 1.5B | ~0.9–1.2 GB | Apache 2.0 | 품질/효율의 균형, 우수한 구조화된 출력 (structured output), 긴 컨텍스트 (long context) — 나의 주력 모델 |
| TinyLlama 1.1B | 1.1B | ~0.7–0.9 GB | Apache 2.0 | 가장 가벼움, 빠른 CPU 추론 (inference) — 저사양 RAM 기기를 위한 대체제 |
| Gemma 2B Instruct | 2B | ~1.3–1.6 GB | (Gemma 약관) | 강력한 일반 언어 이해력 |
| ... |
이 패턴은 단순한 크기 대 성능의 트레이드오프 (trade-off) 관계를 보여줍니다. 더 큰 모델들 (Phi-3 Mini, Qwen2.5-3B)은 추론 능력이 더 뛰어나지만 더 많은 RAM을 요구하며, 전용 GPU가 없는 노트북의 CPU 환경에서는 더 느리게 작동합니다. 이 기능은 전용 GPU 없이 일반적인 하드웨어에서도 사용 가능해야 하므로, "약 1 GB의 RAM에서 원활하게 실행됨"은 선호 사항이 아닌 엄격한 제약 조건입니다. 이로 인해 기본 모델로서 더 무거운 모델들은 제외되었습니다.
경량화된 옵션들 중에서 Qwen2.5-1.5B-Instruct가 최적의 지점 (sweet spot)을 찾아냈습니다. CPU 노트북에서 사용하기에 충분히 작으면서도, 이 프로젝트가 실제로 필요로 하는 단 한 가지, 즉 깨끗하고 스키마 형태를 갖춘 구조화된 출력 (structured output)을 생성하는 데 있어 눈에 띄게 신뢰할 수 있습니다. TinyLlama 1.1B는 1.5B조차 너무 부담스러운 저사양 기기를 위한 대체제로서 고려 대상에 남아 있습니다. 두 모델 모두 Apache 2.0 라이선스이며, 이는 (위에서 언급했듯이) KDE가 호스팅하는 것을 가능하게 하는 요소입니다. 이 점은 제한적인 라이선스를 가진, otherwise 매력적이었을 일부 모델들을 조용히 배제하는 계기가 되었습니다.

현재 상황
파이프라인은 이미 모의 백엔드 (mock backend, 실제 모델을 대신함)를 사용하여 엔드 투 엔드 (end-to-end)로 작동합니다. 따라서 프롬프트(prompt) > 파싱(parse) > 해결(resolve) > 검색 채우기 및 실행(populate-the-search-and-run) 단계가 모두 기능하며 단위 테스트 (unit-tested)를 마쳤습니다. 또한 위에서 설명한 다운로드 통합 기능도 구현되었습니다. 모델은 digiKam의 중앙 관리자에 등록되었으며, 모델이 올바르게 인식되고 파일 경로가 공유 모델 디렉토리로 올바르게 해결됨을 확인했습니다.
다음 단계는?
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기