DeepSWE라는 새로운 벤치마크를 통해 깨달은 점: 기존의 최상위 모델들은 우리가 생각했던 것만큼 강력하지 않을 수도 있습니다
요약
새로운 코딩 벤치마크인 DeepSWE는 단순 코드 수정을 넘어 실제 업무 프로세스를 테스트하여 모델 간의 진정한 성능 격차를 드러냅니다. 기존 벤치마크가 프롬프트 엔지니어링에 의해 왜곡되었을 가능성을 지적하며, 긴 작업(Long-task) 기반 평가의 중요성을 강조합니다.
핵심 포인트
- DeepSWE는 파일 탐색, 버그 재현, 검증 등 실제 코딩 워크플로우를 테스트함
- 기존 벤치마크와 달리 모델 간의 성능 격차를 명확하게 구분함
- 높은 점수가 모델 자체의 성능이 아닌 프롬프트 튜닝 결과일 수 있음을 경고함
- 향후 모델 평가 시 긴 작업 기반의 벤치마크를 주목해야 함
세상에, DeepSWE라는 이 새로운 벤치마크(Benchmark)를 통해 한 가지 깨달은 점이 있습니다. 이전의 최상위 모델들은 우리가 생각했던 것만큼 강력하지 않았을지도 모른다는 사실입니다. 🤔
게다가 이번 AI 코딩 평가(Coding Evaluation)는 정말 강력한 것이 등장한 것 같습니다. 기존의 벤치마크들이 전부 잘못 측정했을 수도 있다는 생각이 드네요.
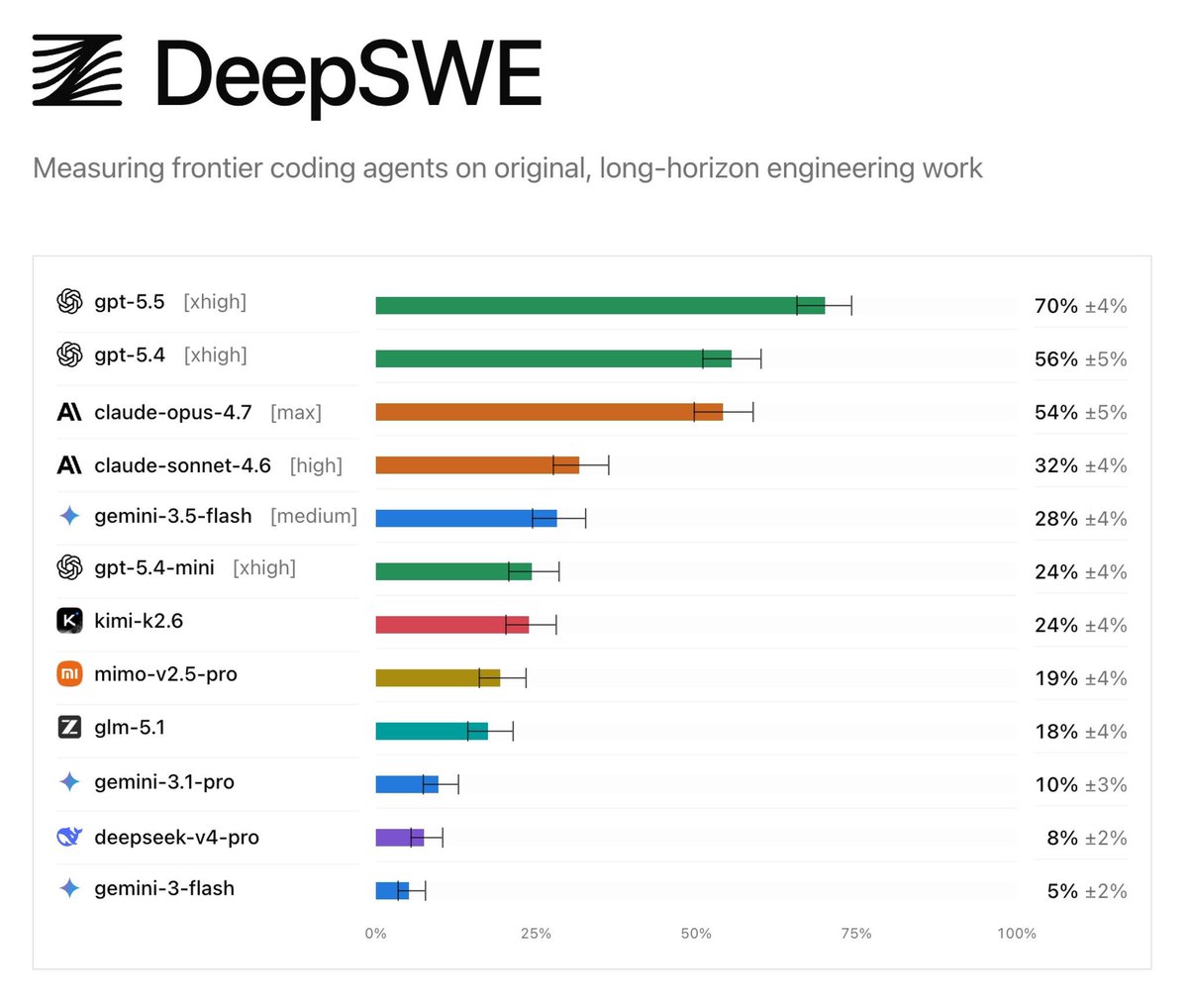
이전 SWE-Bench에서는 최상위 모델들의 점수가 모두 54%-64% 사이에 몰려 있어서 다들 비슷비슷해 보였습니다. 하지만 DeepSWE는 다릅니다. 단순히 코드 한 줄을 수정하는 것을 테스트하는 것이 아니라, 파일을 찾고, 버그를 재현하고, 수정한 후 검증하며, 엣지 케이스(Edge case)를 처리하는 등 실제로 업무를 수행하게 만듭니다. @theo는 이것이 일상적인 코딩 경험과 일치한다고 느낀 첫 번째 벤치마크라고 말했습니다.
이런 방식으로 테스트를 진행하자 격차가 확연히 벌어졌습니다. GPT-5.5는 70%, Claude Opus는 54%를 기록했으며, 나머지는 점수가 반토막 났습니다.
가장 무서운 점은 점수 차이만이 아닙니다. 그들이 아주 간단한 mini-swe-agent를 사용하여 실행했음에도 불구하고, 그 결과가 각 연구소(Lab)에서 오랫동안 튜닝한 공식 도구들과 거의 비슷하게 나왔습니다.
이는 많은 좋은 성적이 모델이 강력해서가 아니라, 프롬프트 엔지니어링 (Prompt Engineering)으로 만들어낸 결과일 수 있음을 의미합니다. 하지만 DeepSWE는 준비할 시간을 주지 않고 바로 실행하기 때문에 격차가 즉시 드러납니다.
이전에는 모두가 화장을 하고 나란히 서 있는 모습이었다면, 이제는 커튼을 걷어치우고 바로 욕실로 들어가는 격입니다. 🤣
따라서 저의 개인적인 판단은 다음과 같습니다:
- 앞으로 모델의 실제 코딩 능력을 판단할 때는, 짧고 빠르게 점수만 올리는 순위표보다는 이러한 긴 작업(Long-task) 기반의 벤치마크를 더 눈여겨보아야 합니다.
- 개발 도구를 선택할 때, 홈페이지에 표시된 점수만 보지 말고 직접 실제 버그를 던져주고 수정하게 한 뒤, 제대로 작동하는지 확인해야 합니다.
이제 새로운 벤치마크라는 거울이 등장했으니, 앞으로 점수 올리기에 급급했던 이들은 잠 못 이루게 될 것 같네요. hhh
AI 자동 생성 콘텐츠
본 콘텐츠는 X @ayi_ainotes (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기