
Deep Agents에서 RLM을 사용하는 방법
요약
에이전트의 컨텍스트 부패 문제를 해결하기 위해 재귀적 언어 모델(RLM)을 활용하는 방법을 소개합니다. RLM은 컨텍스트를 모델 윈도우에 직접 넣는 대신 REPL 환경에서 코드를 실행하여 대규모 데이터를 효율적으로 처리합니다.
핵심 포인트
- 컨텍스트 부패(context rot) 현상 방지
- REPL 기반의 프로그래밍 방식 오케스트레이션 활용
- 기존 모델 윈도우 대비 최대 100배 큰 입력 처리 가능
- 서브에이전트를 통한 작업 분할 및 데이터 격리
에이전트가 더 많은 컨텍스트 (context)를 축적할수록, 컨텍스트 부패 (context rot)라고 불리는 현상으로 인해 성능이 저하됩니다. Alex Zhang과 MIT CSAIL 연구진이 제안한 재귀적 언어 모델 (Recursive Language Models, RLMs)은 이 문제를 해결합니다. 이 모델은 턴 단위로 작동하거나 손실이 발생하는 요약 (summarization)에 의존하는 대신, 서브에이전트 (subagents)를 파견하고 입력 컨텍스트의 조각들에 대해 재귀적으로 실행되는 REPL에서 코드를 실행합니다.
10,000개의 영업 통화 스크립트 전체에서 평균 거래 규모를 찾는 에이전트를 가정해 봅시다. 턴 단위로 작동할 경우, 모델은 자신의 컨텍스트 내에서 누적 합계를 추적해야 하며, 이 합계는 계산이 길어질수록 드리프트 (drift)될 위험이 있습니다. RLM 방식의 에이전트는 오케스트레이션 (orchestration)과 계산을 모델의 일시적인 컨텍스트 윈도우 (context window)가 아닌 코드 내에서 유지합니다.
논문에 따르면 RLM은 모델의 컨텍스트 윈도우보다 최대 두 자릿수(two orders of magnitude) 더 큰 입력을 처리할 수 있으며, 이 과정에서 일반적인 (vanilla) 에이전트보다 뛰어난 성능을 보입니다. 우리는 방금 동적 서브에이전트 (dynamic subagents)를 통해 Deep Agents에 RLM 지원 기능을 구축했습니다.
RLM의 필요성
RLM은 최종 답변을 생성하기 전에 자기 자신 또는 다른 LLM을 재귀적으로 호출하는 언어 모델입니다. 전체 프롬프트 (prompt)를 컨텍스트 윈도우에 강제로 밀어 넣는 대신, 모델은 이를 REPL 내부의 변수로 로드하고, 이를 들여다보고, 분해하며, 그 조각들에 대해 재귀적으로 자기 자신을 호출하는 코드를 작성합니다.
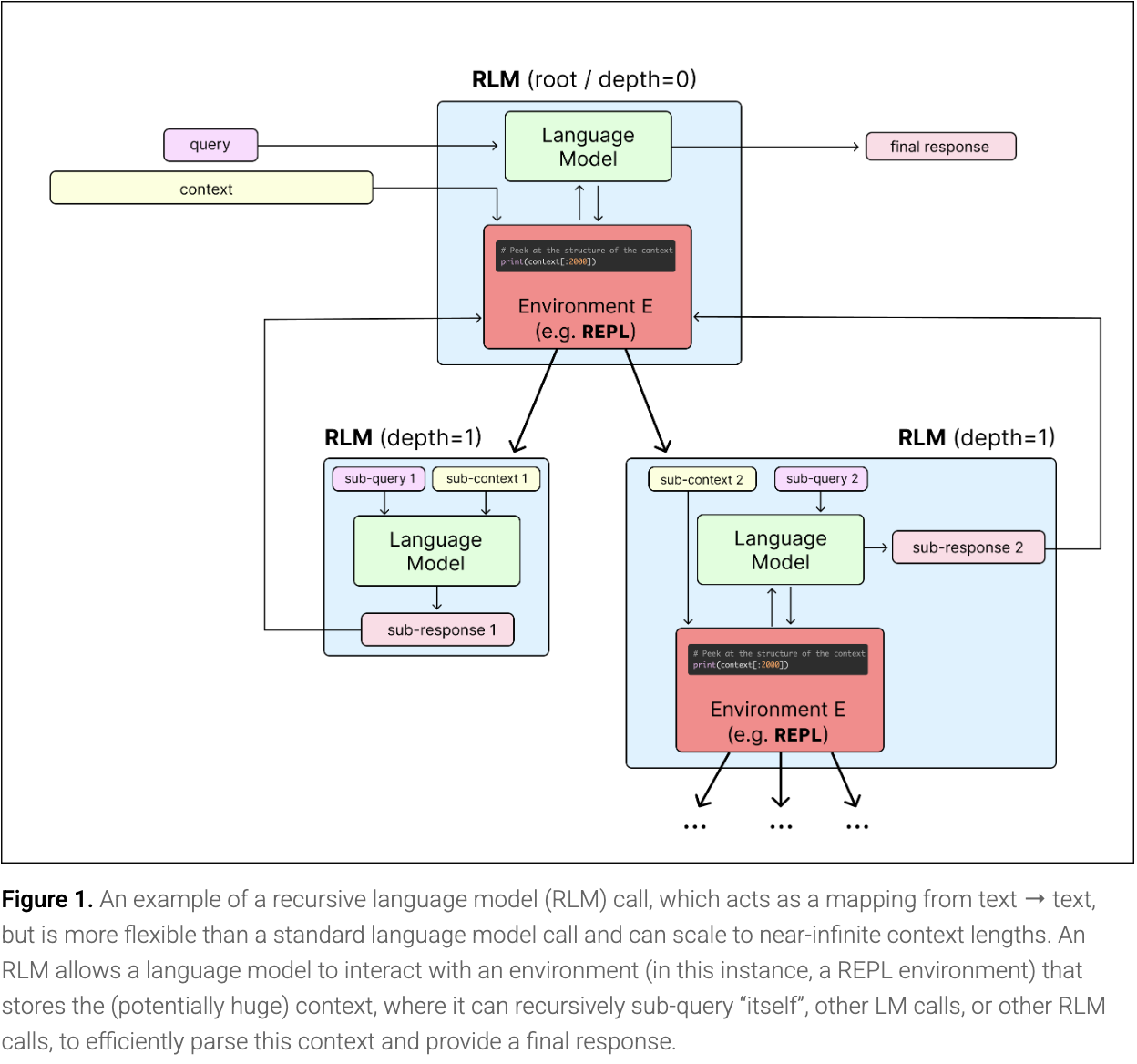
컨텍스트 부패 (context rot)에 맞서기 위한 논문의 첫 번째 가설은 간단했습니다: 모든 것을 하나에 강제로 밀어 넣는 대신, 모델 호출 (model calls)에 걸쳐 작업을 분할하는 것입니다.
자연스러운 해결책은 다음과 같은 식입니다: "음, 만약 내가 컨텍스트를 두 번의 모델 호출로 나누고, 세 번째 모델 호출에서 그것들을 결합한다면, 이 성능 저하 문제를 피할 수 있지 않을까". 우리는 이러한 직관을 재귀적 언어 모델 (recursive language model)의 기초로 삼았습니다.
이것은 대략적으로 기존의 서브에이전트(subagents)가 수행하는 방식이기도 합니다. Deep Agents의 서브에이전트는 컨텍스트(context)를 격리하고, 개별 작업 단위를 위임하며, 중간 결과물이 메인 컨텍스트 창(context window)에 들어오지 않도록 유지합니다. 하지만 일반적인 서브에이전트는 여전히 모델이 한 번의 추론 단계(reasoning turn)마다 다음에 무엇을 할지 결정하는 것에 의존하며, 이는 오케스트레이션(orchestration)에 수백 번의 호출, 분기(branching), 또는 다단계 작업과 같은 실제적인 구조가 필요할 때 한계에 부딪힙니다.
RLM은 모델이 프로그래밍 방식으로 작용할 수 있는 환경을 제공하며, 이는 대규모 데이터셋에서 사용하는 것과 동일한 기본 요소들(grep, partition, map, reduce)을 활용합니다. 서브에이전트의 프로그래밍 방식 오케스트레이션은 도구 기반(tool-based) 오케스트레이션이 안정적으로 제공할 수 없는 두 가지를 가능하게 합니다:
결정론적 커버리지 (Deterministic coverage). 커버리지는 모델의 판단이 아닌 코드로 보장됩니다. for b in batches 루프는 구조적으로 모든 배치를 처리하지만, 일반적인 모델은 이러한 반복 작업을 대규모로 수행하는 데 어려움을 겪습니다.
맞춤형 오케스트레이션 (Bespoke orchestration). 파이프라인이 코드이기 때문에, 모델이 단계별로 안정적으로 수행할 수 있는 범위에 국한되지 않고 작업에 필요한 형태(분기, 병렬, 순차 등)를 자유롭게 취할 수 있습니다.
Deep Agents에서 RLM이 작동하는 방식
Deep Agents는 경량 코드 인터프리터(code interpreter)를 통해 구동되는 동적 서브에이전트(dynamic subagents)를 통해 프로그래밍 방식의 오케스트레이션을 지원합니다. 도구 호출(tool calls)을 통해 서브에이전트를 한 단계씩 파견하는 대신, 모델은 짧은 스크립트를 작성하고 코드 인터프리터가 이를 실행합니다. 전형적인 예로, 300페이지 분량의 문서에서 페이지당 하나의 서브에이전트를 사용하는 경우는 다음과 같습니다:
const results = await Promise.all(pages.map(page =>
task({ description: `Summarize page ${page.number}`, subagentType: "summarizer" })
));
용어에 관한 참고 사항. 우리가 구축한 것은 논문의 형태를 정확히 그대로 반영하지는 않습니다. 논문의 접근 방식은 더 극단적입니다. 전체 프롬프트(prompt)를 인터프리터에 로드하여 직접 재귀적으로 처리하며, 재귀 호출은 자체적인 도구와 상태를 가진 에이전트가 아니라 일반적인 언어 모델(LM) 호출입니다.
Deep Agents에서 우리가 설명하고 있는 것은 코드에서 파견되는, 자체적인 도구 접근 권한과 컨텍스트를 가진 서브에이전트인 *재귀적 에이전트 (Recursive Agents, RA)*에 더 가깝습니다. 우리가 출시하는 기능에는 RA가 더 정확한 용어일 수 있지만, RLM 논문의 설계가 분명히 이 기능과 그에 따른 아키텍처를 동기 부여했습니다.
RLM 논문에서는 모델이 이러한 종류의 환경을 갖게 되면, 모델이 작성하는 코드가 몇 가지 경향을 따른다고 언급합니다.
RLM이 수행하는 일반적인 패턴은 컨텍스트를 더 작은 크기로 청킹(chunking)하고, 답변을 추출하거나 이러한 시맨틱 매핑 (semantic mapping)을 수행하기 위해 여러 번의 재귀적 언어 모델 (LM) 호출을 실행하는 것입니다.
Claude Code의 동적 워크플로우 (dynamic workflows) 문서에서는 이러한 패턴 중 6가지를 직접 명시하고 있습니다: 팬 아웃 및 합성 (fan out and synthesize), 분류 및 실행 (classify and act), 적대적 검증 (adversarial verification), 생성 및 필터링 (generate and filter), 토너먼트 (tournament), 완료될 때까지 루프 (loop until done). 이는 하네스 (harness)와 관계없이 유용한 어휘입니다.
Deep Agents와의 차이점은 오케스트레이터 (orchestrator)와 파견되는 모든 서브에이전트가 특정 모델 제품군에 국한되지 않고, 사용자가 선택한 임의의 모델 또는 모델의 혼합으로 실행될 수 있다는 점입니다. 비용과 성능 최적화를 위해 프론티어 모델 (frontier model) 오케스트레이터와 GLM 5.2 또는 Nemotron과 같은 오픈 웨이트 (open-weight) 서브에이전트를 결합하거나, 반대로 심층 연구 스타일의 워크플로우를 위해 오픈 웨이트 오케스트레이션이 프론티어 서브에이전트를 조정하도록 구성할 수도 있습니다.
우리는 '동적 서브에이전트 소개 (Introducing Dynamic Subagents)'와 이 가이드 영상에서 동적 서브에이전트를 위한 이와 같은 6가지 패턴을 다룹니다.
OOLONG을 통한 벤치마킹
프로그래밍 방식의 오케스트레이션이 실제로 작동하는지 확인하기 위해, 우리는 답변이 입력의 거의 모든 행을 검토해야 하는 긴 컨텍스트 추론 및 데이터 집계용 벤치마크인 OOLONG에서 테스트를 진행했습니다.
우리는 OOLONG 작업으로 구조화된 AgNews에서 실험을 수행했습니다: 수천 개의 헤드라인이 있으며, 각 헤드라인에는 날짜와 사용자가 첨부되어 있지만 눈에 보이는 주제 레이블은 없습니다. 질문에 답하기 위해 에이전트는 헤드라인을 네 가지 카테고리(세계, 스포츠, 비즈니스, 과학/기술) 중 하나로 분류하고 전체 세트에 걸쳐 집계해야 합니다.
그 후 에이전트는 난이도가 높아지는 순서대로 세 가지 카테고리에 속하는 질문에 답하는 과제를 수행합니다.
우리는 이를 포괄적인 벤치마크(benchmark)가 아닌 개념 증명(proof of concept)으로 실행했습니다:
점수는 OOLONG의 채점 방식을 사용하여 AgNews 질문 세트 전체에 대해 평균을 냈습니다. 범주형 답변은 정확히 일치(exact match)해야 하며, 수치형 답변은 0에서 1 사이의 척도로 부분 점수를 부여합니다. 수치형 답변은 0.75^|실제값 - 예측값|로 점수가 매겨지므로, 수치 차이가 1인 경우 여전히 0.75점을 받지만, 차이가 10인 경우 0.06에 가까운 점수를 받게 됩니다.
64k 컨텍스트에서 두 에이전트는 여전히 비슷한 수준에 있으며, 일반 에이전트(plain agent)도 대부분 따라잡고 있습니다:
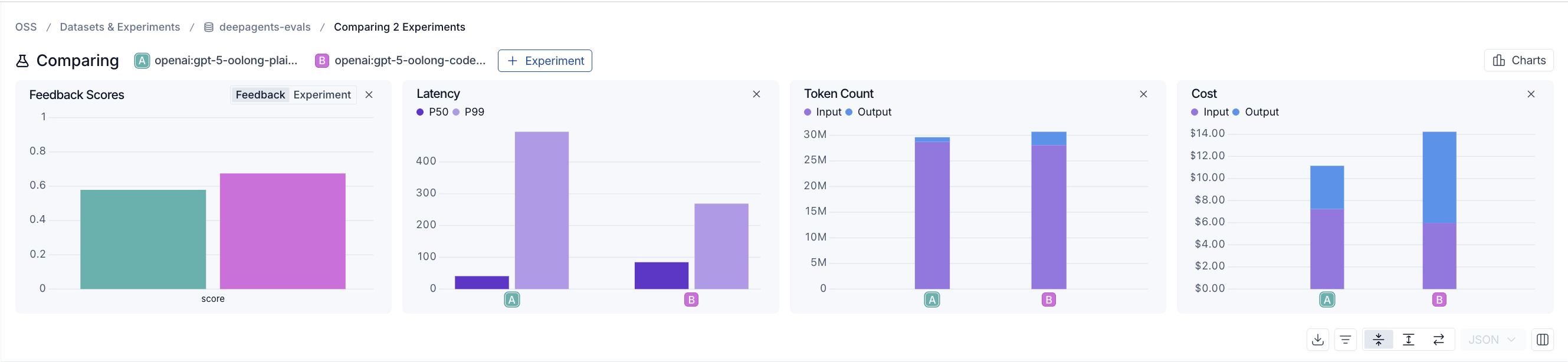
64k 토큰에서 일반 에이전트(왼쪽)는 0.58점을 기록한 반면, RLM이 활성화된 에이전트(오른쪽)는 0.67점을 기록했습니다. 토큰 수와 비용은 비슷하며, 이는 더 단순한 접근 방식이 여전히 대부분 따라갈 수 있는 영역입니다. 일반 에이전트의 지연 시간(latency)은 RLM이 활성화된 에이전트보다 눈에 띄게 낮습니다.
128k에서는 성능이 무너지기 시작하는데, 미묘하게 틀린 답을 내놓는 것이 아니라 아예 포기해 버립니다. 즉, 결과를 계산할 수 없다거나 차단되었다고 말합니다.
.png)
데이터에서도 그 차이가 명확하게 나타납니다:
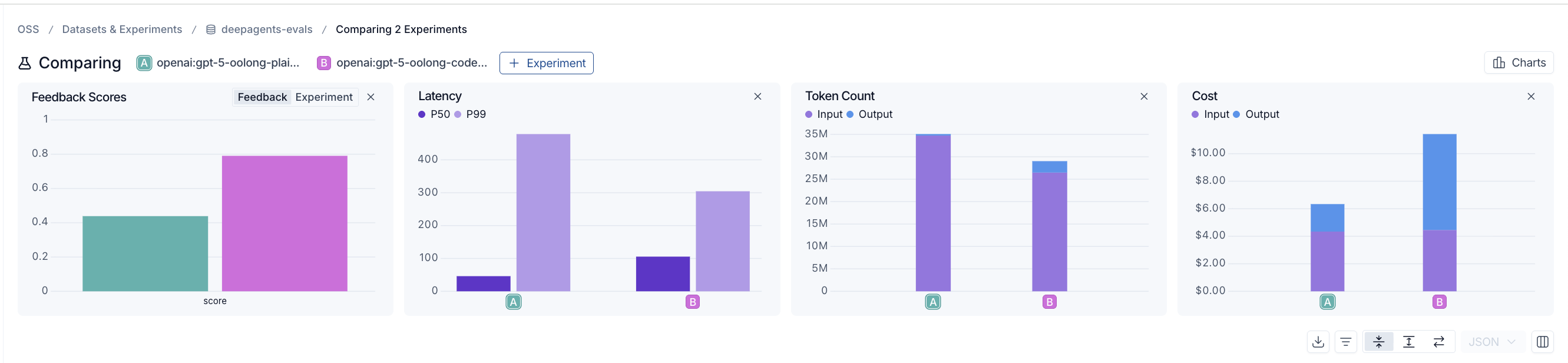
128k 토큰에서 일반 에이전트(왼쪽)는 0.44점으로 떨어지는 반면, RLM이 활성화된 에이전트(오른쪽)는 0.79점에 도달합니다. RLM이 활성화된 에이전트는 확실히 더 느리며, 실제로 더 적은 토큰을 사용함에도 불구하고 출력 토큰 비용(output token cost) 때문에 비용은 더 높습니다.
참고로, 우리는 OOLONG 워크로드에 맞춰 최적화하지 않았습니다. 이는 작업별 프롬프팅(task-specific prompting) 없이 기본 하네스(harness)가 긴 컨텍스트(long-context) 문제를 처리할 수 있는지 확인하기 위한 스모크 테스트(smoke test)였습니다. 실제로 우리는 이 수치들이 RLM의 잠재력을 과소평가하고 있다고 생각합니다.
Deep Agents에서 시작하기
동적 서브에이전트(Dynamic subagents)에는 두 가지가 필요합니다. 작업을 할당할 서브에이전트와, 모델이 오케스트레이션(orchestration) 코드를 작성하고 실행하는 안전하고 가벼운 런타임(runtime)인 코드 인터프리터(code interpreter)입니다. Deep Agents는 이 두 가지를 모두 제공합니다. QuickJS 미들웨어를 설치하고 create_deep_agent에 CodeInterpreterMiddleware를 전달하세요:
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
...
``
Deep Agents는 기본적으로 범용 서브에이전트 (subagent)를 포함하고 있지만, 각각 고유한 이름, 설명, 시스템 프롬프트 (system prompt)를 가진 특정 작업에 특화된 커스텀 서브에이전트를 구성할 수도 있습니다. 오케스트레이션 (orchestration) 스크립트는 작업에 적합한 서브에이전트에게 작업을 할당할 수 있습니다.
동적 서브에이전트 (dynamic subagents)를 트리거하려면 "workflow"라는 단어를 포함하여 프롬프트하세요:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "src/routes/의 모든 파일을 검토하고 주요 리스크를 요약하는 워크플로우 (workflow)를 실행해줘."}]
})
``
설정 없이 이를 시도하는 가장 빠른 방법은 우리의 터미널 코딩 에이전트인 dcode를 사용하는 것입니다. dcode는 코드 인터프리터 (code interpreter)가 이미 활성화된 상태로 제공되므로, 설치 후 워크플로우를 요청하기만 하면 됩니다:
curl -LsSf https://langch.in/dcode | bash
dcode
결론
효과적인 에이전트를 구축하는 핵심은 주어진 작업에 대해 모델에게 적절한 시점에 적절한 컨텍스트 (context)를 제공하는 것입니다. 에이전트 설계의 적절한 단위로서 루프 (loop)에 대한 많은 논의가 있어 왔으며, 여기에는 에이전트 루프 (agent loop), 검증 루프 (verification loop), 시스템 루프 (systems loops), 그리고 자기 개선 루프 (self-improvement loops)가 포함됩니다.
RLM은 이러한 루프 세계 (loop-verse)에 딱 들어맞습니다. RLM은 루트 모델 (root model)이 컨텍스트와 작업 형태를 모델링하여 스스로를 위한 루프를 작성할 수 있는 능력을 부여합니다.
우리는 동적 서브에이전트와 이를 통해 가능해지는 RLM 워크플로우에 대해 매우 기대하고 있습니다. 왜냐하면 이는 에이전트에게 루프를 포함하여 자신의 컨텍스트를 스스로 조직할 수 있는 능력을 부여하기 때문입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기