Deep Agents를 위한 컨텍스트 관리 (Context Management)
요약
Deep Agents SDK는 AI 에이전트의 컨텍스트 부패를 방지하고 메모리 제약을 관리하기 위한 컨텍스트 관리 기술을 제공합니다. 파일 시스템 오프로딩과 요약 기술을 통해 대규모 작업 중에도 효율적인 컨텍스트 유지가 가능합니다.
핵심 포인트
- 컨텍스트 압축을 통해 에이전트의 작업 메모리 내 정보량을 최적화함
- 대규모 도구 결과 및 입력을 파일 시스템으로 오프로딩하여 컨텍스트 창 초과 방지
- 임계값 초과 시 메시지 기록을 요약하는 단계적 압축 메커니즘 구현
- LangChain 기반의 'batteries-included' 에이전트 하네스 제공
Chester Curme 및 Mason Daugherty 작성
AI 에이전트가 처리할 수 있는 작업 길이가 계속해서 길어짐에 따라, 컨텍스트 부패 (context rot)를 방지하고 LLM의 유한한 메모리 제약을 관리하기 위한 효과적인 컨텍스트 관리 (context management)가 매우 중요해지고 있습니다.
Deep Agents SDK는 LangChain의 오픈 소스 기반의 'batteries-included' 에이전트 하네스 (agent harness)입니다. 이는 계획을 세우고, 하위 에이전트 (subagents)를 생성하며, 파일 시스템 (filesystem)과 연동하여 복잡하고 장기적인 작업을 실행할 수 있는 에이전트를 구축할 수 있는 쉬운 경로를 제공합니다. 이러한 종류의 작업은 일반적으로 모델의 컨텍스트 창 (context windows)을 초과할 수 있기 때문에, 이 SDK는 컨텍스트 압축 (context compression)을 용이하게 하는 다양한 기능을 구현합니다.
컨텍스트 압축 (Context compression)이란 작업을 완료하는 데 관련 있는 세부 사항은 보존하면서 에이전트의 작업 메모리 (working memory) 내 정보량을 줄이는 기술을 의미합니다. 여기에는 이전 상호작용을 요약하거나, 오래된 정보를 필터링하거나, 무엇을 유지하고 무엇을 버릴지 전략적으로 결정하는 과정이 포함될 수 있습니다.
Deep Agents는 에이전트가 파일 목록 생성, 읽기, 쓰기뿐만 아니라 검색, 패턴 매칭, 파일 실행과 같은 작업을 수행할 수 있도록 하는 파일 시스템 추상화 (filesystem abstraction)를 구현합니다. 에이전트는 필요에 따라 오프로드 (offloaded)된 콘텐츠를 검색하고 검색하기 위해 파일 시스템을 사용합니다.
Deep Agents는 서로 다른 빈도로 트리거되는 세 가지 주요 압축 기술을 구현합니다:
대규모 도구 결과 오프로딩 (Offloading large tool results): 대규모 도구 응답이 발생할 때마다 이를 파일 시스템으로 오프로드합니다.
대규모 도구 입력 오프로딩 (Offloading large tool inputs): 컨텍스트 크기가 임계값을 넘어서면, 도구 호출(tool calls)에서 발생한 오래된 쓰기/편집 인자(write/edit arguments)를 파일 시스템으로 오프로드합니다.
요약 (Summarization): 컨텍스트 크기가 임계값을 넘어서고 더 이상 오프로드할 수 있는 컨텍스트가 없을 때, 메시지 기록을 압축하기 위해 요약 단계를 수행합니다.
컨텍스트 제한을 관리하기 위해, Deep Agents SDK는 모델 컨텍스트 창 크기의 임계값 비율에서 이러한 압축 단계들을 트리거합니다. (내부적으로는 특정 모델의 토큰 임계값에 접근하기 위해 LangChain의 모델 프로필 (model profiles)을 사용합니다.)
대규모 도구 결과의 오프로딩 (Offloading large tool results)
도구 호출 (tool invocations)로부터의 응답(예: 대용량 파일 읽기 또는 API 호출 결과)은 모델의 컨텍스트 윈도우 (context window)를 초과할 수 있습니다. Deep Agents는 도구 응답이 20,000 토큰을 초과하는 것을 감지하면, 해당 응답을 파일 시스템 (filesystem)으로 오프로딩 (offloading)하고, 이를 파일 경로 참조와 처음 10줄의 미리보기로 대체합니다. 이후 에이전트 (Agents)는 필요에 따라 해당 콘텐츠를 다시 읽거나 검색할 수 있습니다.
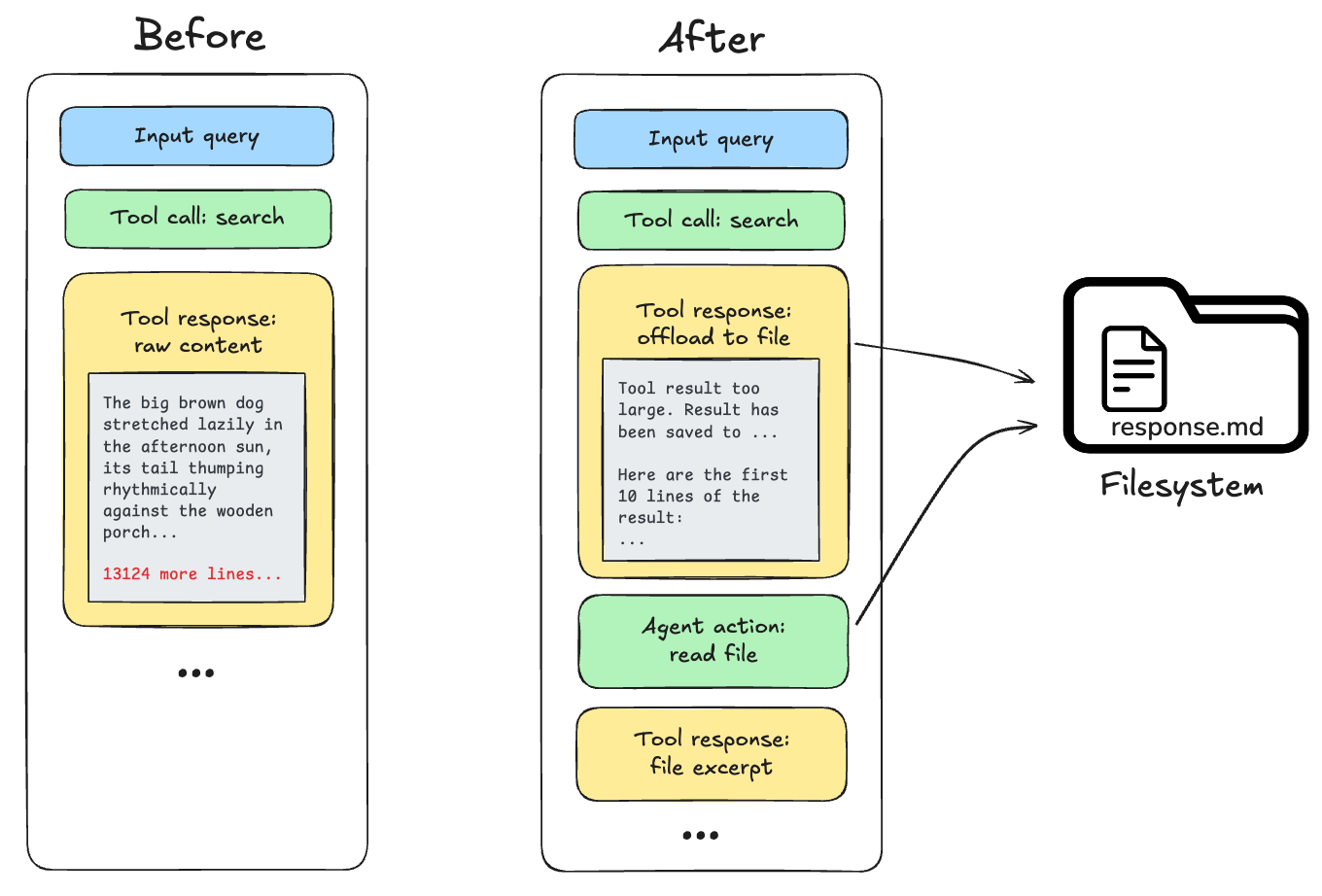
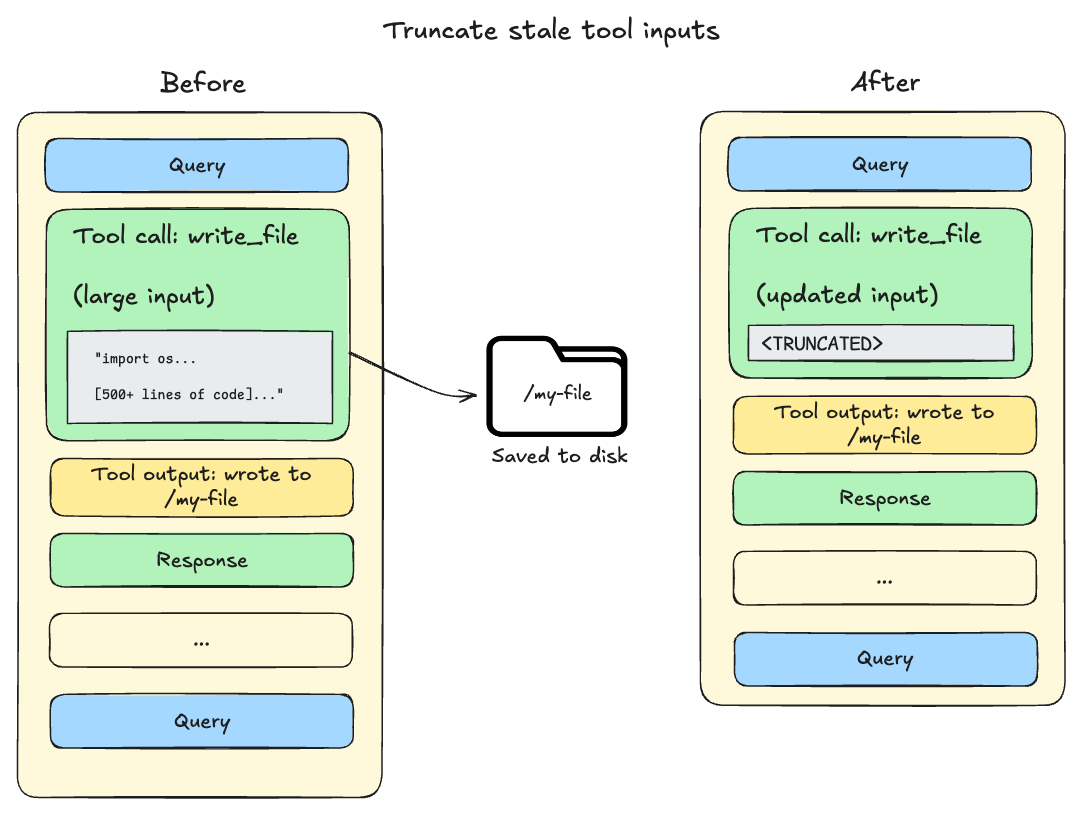
대규모 도구 입력의 오프로딩 (Offloading large tool inputs)
파일 쓰기 및 편집 작업은 에이전트의 대화 기록 (conversation history)에 전체 파일 콘텐츠를 포함하는 도구 호출 (tool calls)을 남깁니다. 이 콘텐츠는 이미 파일 시스템에 저장되어 있으므로 종종 중복되는 정보가 됩니다. 세션 컨텍스트 (session context)가 모델의 사용 가능한 윈도우의 85%를 넘어서면, Deep Agents는 오래된 도구 호출을 잘라내고(truncate), 이를 디스크 상의 파일에 대한 포인터로 대체하여 활성 컨텍스트 (active context)의 크기를 줄입니다.
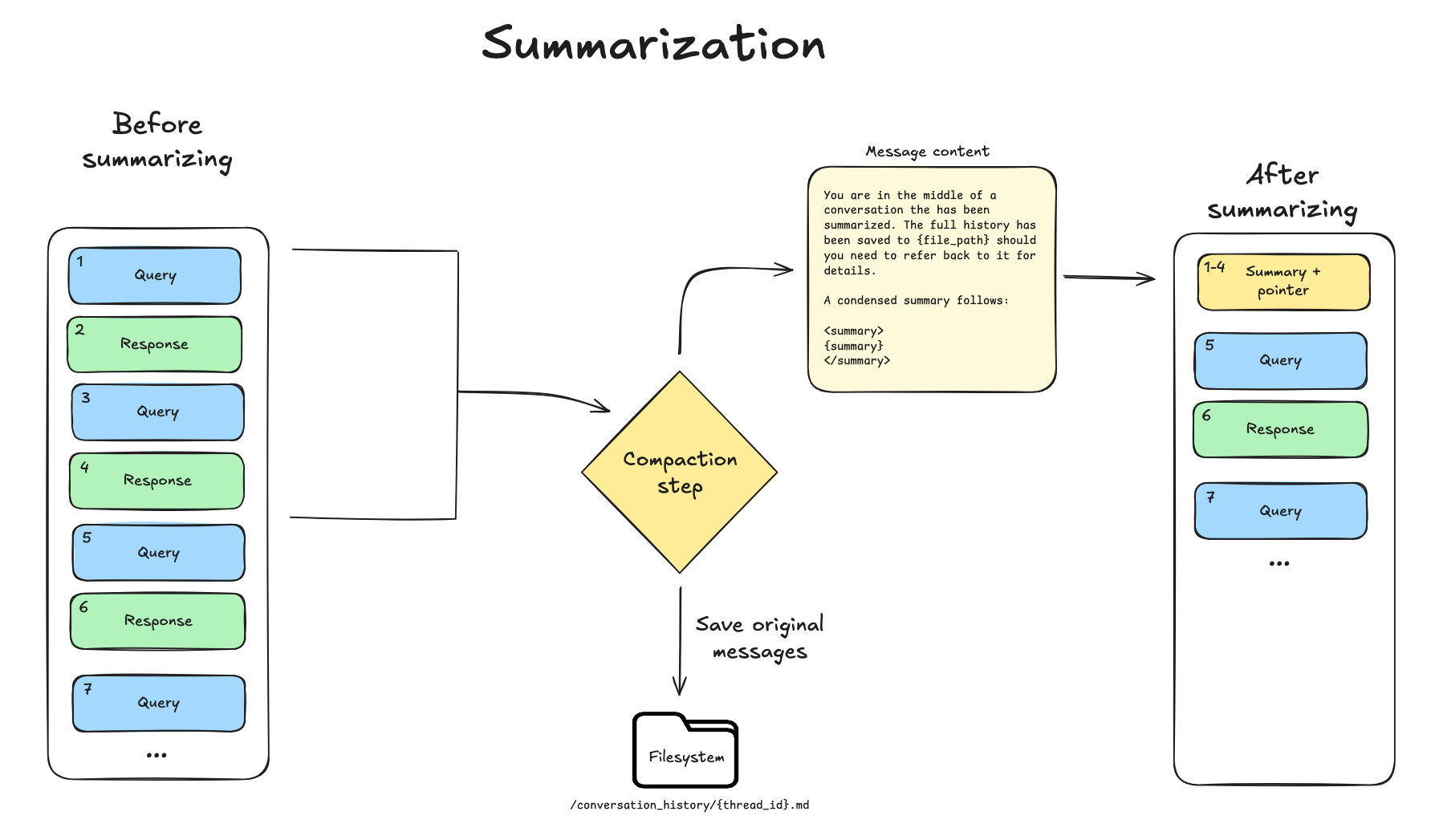
요약 (Summarization)
오프로딩만으로 충분한 공간을 확보할 수 없을 때, Deep Agents는 요약 (summarization) 방식으로 전환합니다. 이 프로세스는 두 가지 구성 요소로 이루어집니다:
- 인컨텍스트 요약 (In-context summary): LLM이 세션 의도 (session intent), 생성된 아티팩트 (artifacts), 다음 단계 (next steps)를 포함하여 대화의 구조화된 요약을 생성하며, 이는 에이전트의 작업 메모리 (working memory) 내에서 전체 대화 기록을 대체합니다. (Deep Agents 요약 프롬프트 참조)
- 파일 시스템 보존 (Filesystem preservation): 완전한 원본 대화 메시지는 정식 기록 (canonical record)으로서 파일 시스템에 기록됩니다.
이 이중 접근 방식은 에이전트가 (요약을 통해) 자신의 목표와 진행 상황에 대한 인식을 유지하는 동시에, (파일 시스템 검색을 통해) 필요할 때 특정 세부 정보를 복구할 수 있는 능력을 보존하도록 보장합니다. 모델이 이전에 오프로딩된 메시지를 가져오기 위해 read_file 도구를 사용하는 이 트레이스 (trace)의 예시를 확인하십시오.
실제 적용 사례 (What this looks like in practice)
위의 기술들이 컨텍스트 관리 (context management)를 위한 메커니즘을 제공하지만, 이것들이 실제로 작동하는지 어떻게 알 수 있을까요? terminal-bench와 같은 벤치마크 (benchmarks)에 기록된 실제 작업 수행 결과는...
, 간헐적으로 컨텍스트 압축 (context compression)을 유발할 수 있어, 그 영향을 분리하여 파악하기 어렵게 만듭니다.
저희는 벤치마크 데이터셋에서 하네스 (harness)의 개별 기능들을 더 공격적으로 활용함으로써, 각 기능의 신호 (signal)를 높이는 것이 유용하다는 것을 발견했습니다. 예를 들어, 가용 컨텍스트 윈도우 (context window)의 10~20% 지점에서 요약 (summarization)을 트리거하는 것은 전반적인 성능을 최적화되지 않은 상태로 만들 수 있지만, 훨씬 더 많은 요약 이벤트를 생성합니다. 이를 통해 서로 다른 설정값(예: 구현 방식의 변형)들을 비교할 수 있습니다. 일례로, 에이전트가 빈번하게 요약하도록 강제함으로써, 세션 의도 (session intent)와 다음 단계 (next steps)를 위한 전용 필드를 추가한 deepagents 요약 프롬프트 (summarization prompt)의 단순한 변경 사항들이 성능 향상에 어떻게 도움이 되는지 식별할 수 있었습니다.
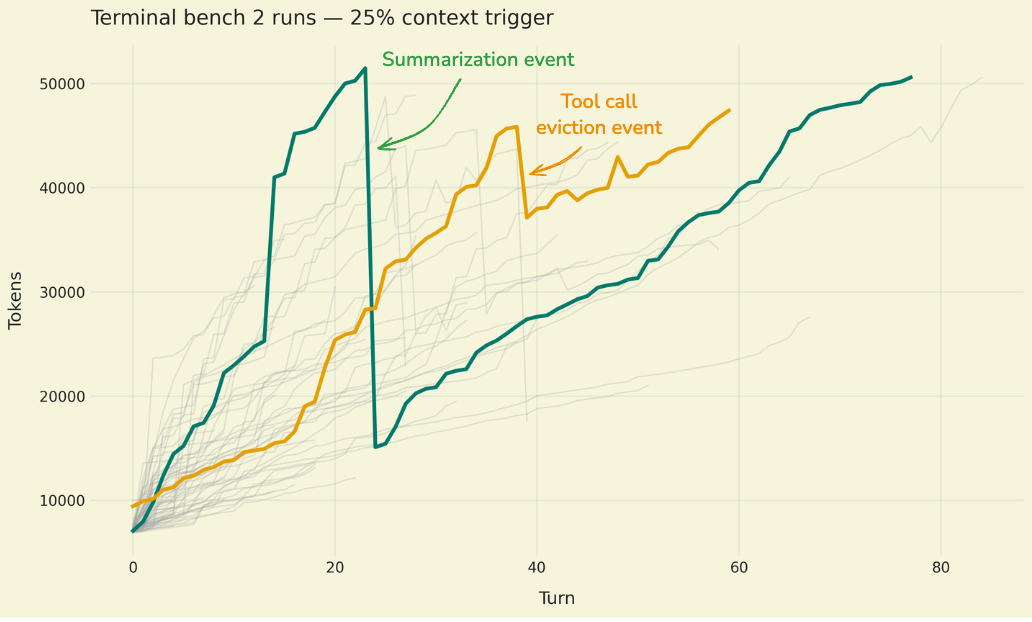
그림: terminal-bench-2에서 Claude Sonnet 4.5를 샘플 실행했을 때의 시간 경과에 따른 토큰 사용량 (회색 선은 모든 실행을 나타내며, 유색 선은 두 가지 특정 사례를 강조함). 녹색 선은 요약 이벤트가 대화 기록을 압축할 때 turn 20 부근에서 토큰이 급격히 감소하는 것을 보여줍니다. 주황색 선은 대규모 파일 쓰기 도구 호출 (file write tool call)이 컨텍스트에서 축출 (evicted)될 때 turn 40 부근에서 더 작은 감소를 보여줍니다. 컨텍스트 윈도우의 25% 지점에서 압축을 트리거함으로써 (Deep Agents의 기본값인 85% 대신), 연구를 위한 더 많은 이벤트를 생성할 수 있습니다.
타겟 평가 (Targeted evals)
Deep Agents SDK는 개별 컨텍스트 관리 (context-management) 메커니즘을 분리하고 검증하기 위해 설계된 일련의 타겟 평가 (targeted evaluations) 세트를 유지 관리합니다. 이는 특정 실패 모드 (failure modes)를 명확하게 드러내고 디버깅할 수 있도록 의도적으로 작게 설계된 테스트들입니다.
이 평가들의 목표는 광범위한 작업 해결 능력을 측정하는 것이 아니라, 에이전트의 하네스 (harness)가 특정 작업의 수행을 방해하지 않도록 보장하는 것입니다. 예를 들어:
- 요약(summarization)이 에이전트의 목적을 보존했는가? 일부 평가(evals)는 작업 중간에 의도적으로 요약을 트리거한 다음, 에이전트가 작업을 계속 수행하는지 확인합니다. 이는 요약이 에이전트의 상태(state)뿐만 아니라 그 궤적(trajectory)까지 보존하는지 보장합니다.
- 에이전트가 요약되어 사라진 정보를 복구할 수 있는가? 여기서는 대화 초기에 "건초더미 속의 바늘(needle-in-the-haystack)"과 같은 사실을 삽입하고, 강제로 요약 이벤트를 발생시킨 뒤, 에이전트가 작업을 완료하기 위해 나중에 그 사실을 회상하도록 요구합니다. 이 사실은 요약 후 활성 컨텍스트(active context)에 존재하지 않으며, 파일 시스템 검색을 통해 복구되어야 합니다.
이러한 타겟팅된 평가(evals)는 컨텍스트 관리(context management)를 위한 통합 테스트(integration tests) 역할을 합니다. 이는 전체 벤치마크 실행을 대체하는 것은 아니지만, 반복(iteration) 시간을 크게 단축시키고, 실패의 원인을 전체적인 에이전트 행동이 아닌 특정 압축 메커니즘(compression mechanisms)으로 귀인할 수 있게 해줍니다.
가이드라인 (Guidance)
자체적인 컨텍스트 압축(context compression) 전략을 평가할 때, 다음 사항을 강조합니다:
실제 세계의 벤치마크로 시작한 다음, 개별 기능에 대해 스트레스 테스트를 수행하십시오. 먼저 대표적인 작업에 하네스(harness)를 실행하여 기준 성능(baseline performance)을 설정하십시오. 그다음, 압축 이벤트를 실행당 더 많이 생성하기 위해 압축을 더 공격적으로 인위적으로 트리거하십시오 (예: 컨텍스트의 85%가 아닌 10-20% 지점에서 압축).
이는 개별 기능으로부터의 신호(signal)를 증폭시켜, 서로 다른 접근 방식(예: 요약 프롬프트의 변형)을 비교하기 쉽게 만듭니다.
복구 가능성(recoverability)을 테스트하십시오. 컨텍스트 압축은 중요한 정보에 계속 접근할 수 있을 때만 유용합니다. 에이전트가 압축 후에도 원래 목표를 향해 계속 나아갈 수 있는지, 그리고 필요할 때 특정 세부 정보를 복구할 수 있는지(예: 핵심 사실이 요약되어 사라졌지만 나중에 반드시 검색해야 하는 needle-in-the-haystack 시나리오)를 검증하는 타겟팅된 테스트를 포함하십시오.
목표 이탈(goal drift)을 모니터링하십시오. 가장 교활한 실패 모드는 요약 후에 에이전트가 사용자의 의도(intent)를 놓치는 경우입니다.
이는 에이전트가 요약(summarization) 직후 턴에서 명확한 설명을 요구하거나, 작업을 실수로 완료되었다고 선언하는 방식으로 나타날 수 있습니다. 의도된 작업으로부터 벗어나는 더 미묘한 편차(deviations)는 요약 때문이라고 단정 짓기 어려울 수 있습니다. 샘플 데이터셋에 대해 빈번한 요약을 강제하는 것은 이러한 실패 사례들을 드러내는 데 도움이 될 수 있습니다.
Deep Agents harness의 모든 기능은 오픈 소스(open source)입니다. 최신 버전을 사용해 보시고, 귀하의 사용 사례(use cases)에 어떤 압축 전략(compression strategies)이 가장 효과적인지 저희에게 알려주세요!
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기