
Cursor에서 GLM-5.2와 연동하여 비용 절약하기
요약
Z.ai가 출시한 오픈 웨이트 모델 GLM-5.2를 Cursor에 연동하여 코딩 비용을 절감하는 방법을 소개합니다. GLM-5.2는 MoE 아키텍처와 IndexShare 기술을 통해 높은 성능과 효율성을 동시에 제공합니다.
핵심 포인트
- GLM-5.2는 GPT-5.5를 상회하는 코딩 벤치마크 성능을 보유함
- IndexShare 기술로 1M 컨텍스트 환경에서 연산 효율을 2.9배 개선
- BYOK 방식을 통해 Cursor에서 저렴한 비용으로 고성능 코딩 지원 가능
- Thinking Mode를 통해 작업 복잡도에 따른 추론 단계 선택 가능
Z.ai가 2026년 6월 16일에 출시한 코딩용 플래그십 모델 GLM-5.2는 오픈 웨이트 (Open-weight) 최고 수준의 코딩 성능을 자랑하면서도, Claude Opus 4.8이나 GPT-5.5의 몇 분의 일 수준의 비용으로 이용할 수 있습니다. BYOK를 사용하여 Cursor에 통합하고 비용을 대폭 절감해 보세요.
GLM-5.2란
GLM-5.2는 중국 AI 기업 Zhipu AI (국제 브랜드: Z.ai)가 개발한 Mixture-of-Experts (MoE) 아키텍처 기반의 대규모 언어 모델 (LLM)입니다. 2026년 6월 16일에 정식 출시되었으며, 동시에 API 및 오픈 웨이트 (MIT 라이선스)로 공개되었습니다.
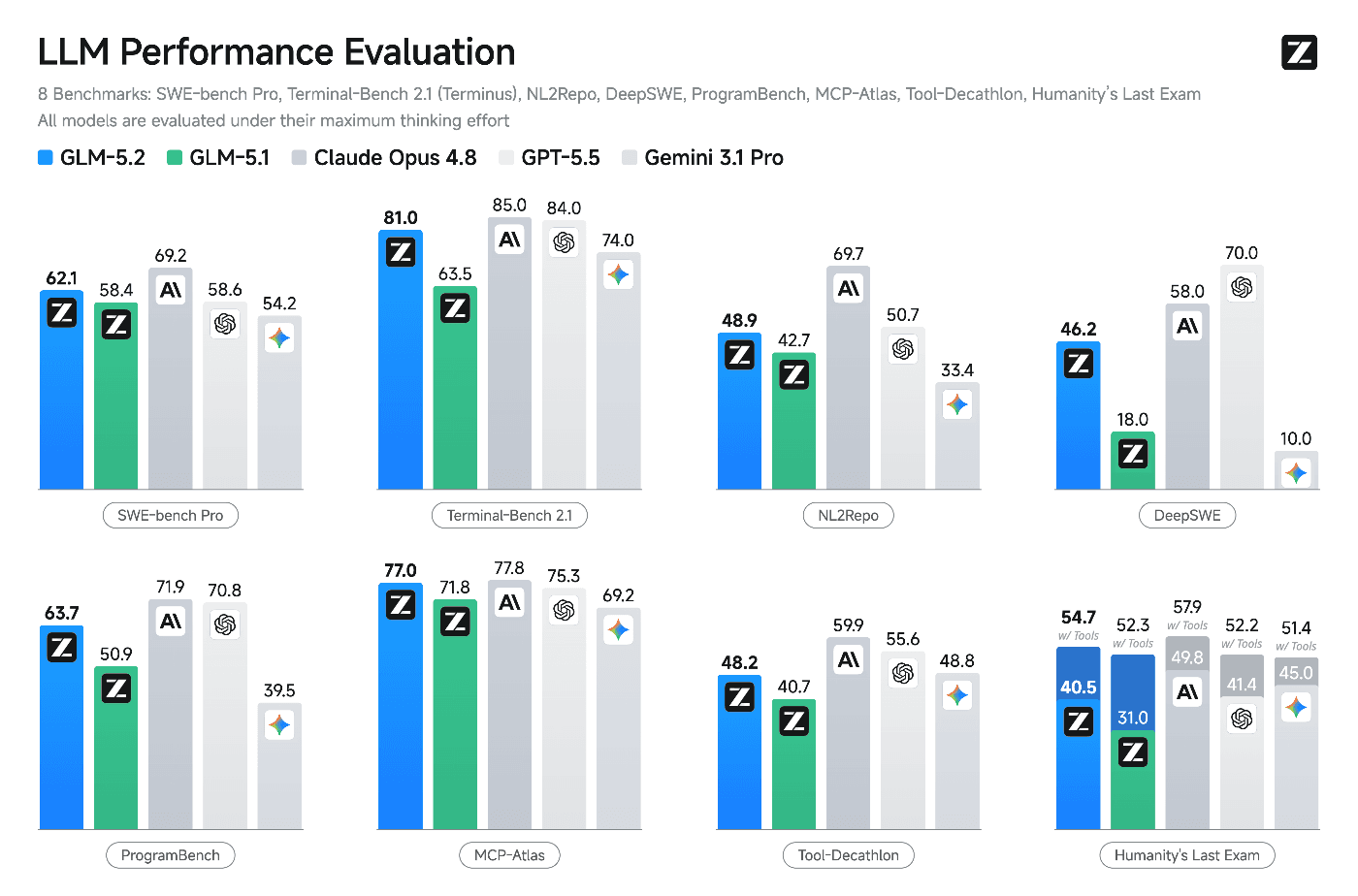
모델 스펙
| 항목 | 상세 |
|---|---|
| 총 파라미터 수 | 753B (약 7,530억) |
| 활성 파라미터 수 | 40B (약 400억) |
| 컨텍스트 길이 | 1M tokens (100만 토큰) |
| 최대 출력 토큰 | 262K tokens |
| 라이선스 | MIT (상업적 이용 및 파인튜닝 가능) |
| 출시일 | 2026년 6월 16일 |
GLM-5.2는 GLM-5.1로부터의 대폭적인 개선으로서, IndexShare라고 불리는 아키텍처 최적화를 도입했습니다. 희소 어텐션 (Sparse Attention) 층 4개마다 동일한 인덱서를 재사용함으로써, 1M 토큰의 컨텍스트 길이에서 per-token FLOPs를 최대 2.9배 절감했습니다.
Thinking Mode (추론 모드)
GLM-5.2는 Thinking Mode를 탑재하고 있어, High와 Max (xhigh)의 2단계 중 용도에 따라 선택할 수 있습니다.
- High: 표준적인 추론. 속도와 정확도의 균형
- Max (xhigh): 더 깊은 추론. 복잡한 태스크용
코딩 성능
GLM-5.2는 코딩 특화 장기 태스크 (Long-horizon task)에서 GPT-5.5를 상회하는 벤치마크 결과를 기록하고 있습니다.
| 벤치마크 | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | 58.6 | — |
| FrontierSWE (Dominance) | 74.4% | 72.6% | 75.1% |
| MCP-Atlas | 77.0 | 75.3 | 77.8 |
| Intelligence Index v4.1 | 51 | — | — |
※ Intelligence Index v4.1 (Artificial Analysis)에서는 오픈 웨이트 모델로서 최고 점수인 51을 기록하며, DeepSeek V4 Pro (44) 및 MiniMax-M3 (44)를 앞질렀습니다.
1M 토큰의 컨텍스트 윈도우 (Context Window)를 통해, 대규모 코드베이스 전체를 한 번에 읽어 들이는 아키텍처 리뷰나 의존성 분석도 가능합니다.
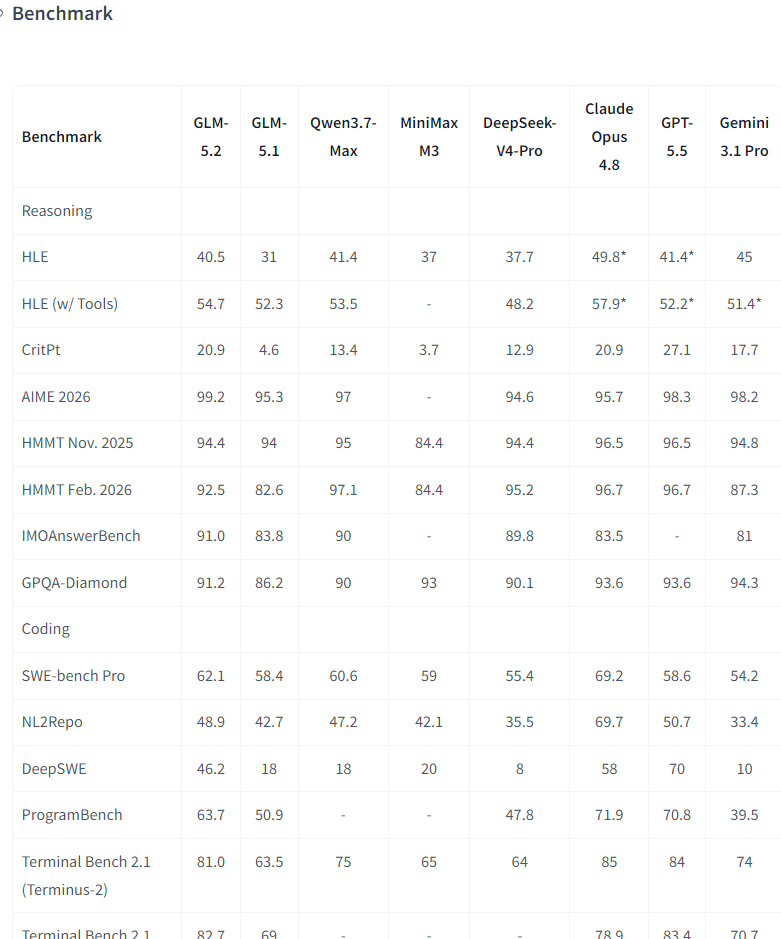
요금 비교
GLM-5.2 공식 요금 (2026년 6월 시점)
종량제 (Pay-as-you-go) API
| 토큰 종류 | 요금 |
|---|---|
| 입력 (일반) | $1.40 / 1M tokens |
| ... |
GLM Coding Plan (월간 구독)
| 플랜 | 월간 (분기 결제 환산) | 대응 모델 | 5시간당 프롬프트 상한 | 주간 프롬프트 상한 |
|---|---|---|---|---|
| Lite | 약 $18/월 | GLM-5.2, GLM-4.7, GLM-4.5-Air | 약 80 프롬프트 | 약 400 프롬프트 |
| Pro | 약 $30/월 | GLM-5.2, GLM-4.7, GLM-4.5-Air | 약 400 프롬프트 | 약 2,000 프롬프트 |
| Max | 약 $80/월 | GLM-5.2, GLM-4.7, GLM-4.5-Air | 약 1,600 프롬프트 | 약 8,000 프롬프트 |
⚠️ GLM-5.2는 피크 시간대 (UTC+8 14:00~18:00)에 3배 소비, 오프 피크 시간대에 2배 소비됩니다. 단, 2026년 9월 말까지는 오프 피크 시간대에 1배 소비되는 한정 특전이 적용되고 있습니다.
주요 모델과의 출력 비용 비교
| 모델 | 출력 1M tokens 당 |
|---|---|
| Claude Opus 4.8 | $75.00 |
| ... | GLM-5.2 |
| $4.40 | |
| DeepSeek V4-Pro | $3.48 |
GLM-5.2는 Claude Opus 4.8의 약 17분의 1, GPT-5.5의 약 7분의 1 수준의 비용입니다. 코딩 에이전트(Coding Agent)와 같이 출력 토큰이 많은 워크로드(Workload)일수록 비용 차이가 크게 나타납니다.
Sonnet 4.6의 약 1/3 정도의 비용으로 이 성능을 얻을 수 있다는 점은 매우 경제적입니다.
⚠️ 주의: Cursor에서의 Thinking Mode 제어
Cursor의 BYOK(Bring Your Own Key) 커스텀 모델 설정에서는 GLM-5.2의 Thinking Mode 강도(High / Max)를 명시적으로 지정할 수 있는 수단이 없습니다. API에서는 reasoning_effort 파라미터로 제어하지만, Cursor의 Custom Model UI는 이 파라미터를 전달하는 기능을 갖추고 있지 않아 기본 동작(일반 보완)으로 작동합니다.
- 보완(Completion) 자체는 문제없이 작동합니다.
- Thinking의 강도를 Max로 설정하여 사용하고 싶다면, Cline 등 OpenAI 호환 클라이언트가 적합합니다.
API 키 발급
- https://z.ai/model-api 에 접속하여 계정을 생성하거나 로그인
- GLM Coding Plan에서 구독 구매 (Lite 플랜은 약 $18/월~)
- 대시보드의 API Keys에서 「+ Add API Key」로 키 발급
⚠️ 중요: Coding Plan에서 Cursor를 사용하는 경우, General API(https://api.z.ai/api/paas/v4)가 아니라, **전용 Coding API(https://api.z.ai/api/coding/paas/v4)**를 사용해야 합니다.
Cursor에 GLM-5.2를 등록하는 절차
⚠️ 전제 조건: Cursor의 커스텀 모델 설정은 Cursor Pro 이상의 플랜에서만 이용 가능합니다.
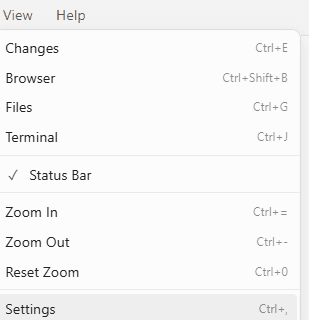
1. Cursor를 실행하고 설정 열기
View → Settings
2. 커스텀 모델 추가하기
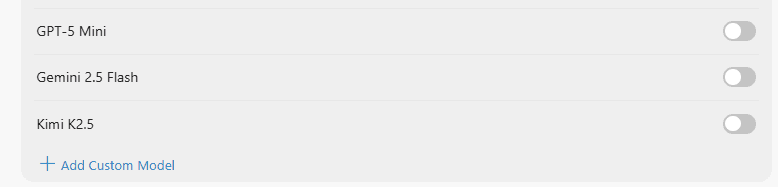
「+ Add Custom Model」을 클릭하여 다음과 같이 설정합니다.
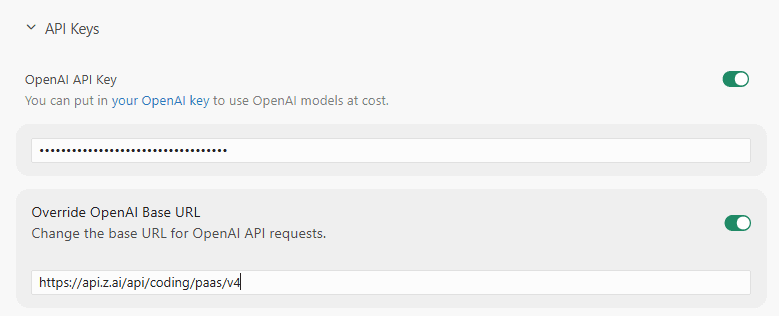
- Model Name:
GLM-5.2(반드시 대문자로 입력해야 합니다) - OpenAI API Key: Z.ai에서 발급한 API 키를 입력
- Override OpenAI Base URL:
https://api.z.ai/api/coding/paas/v4
⚠️ Cursor에서는 모델명을 대문자로 입력해야 합니다 (예: GLM-5.2). 소문자로 입력하면 모델이 인식되지 않을 수 있습니다.
3. Verify로 연결 확인
API 키 입력 후, 「Verify」 버튼을 클릭하여 연결을 확인합니다.
에러 코드 참고
| 코드 | 원인 |
|---|---|
| 402 | 잔액 부족 또는 구독 미가입 |
| ... | 에러가 발생하는 경우, 다른 모델(GPT 계열 등)의 체크를 해제하고 GLM만 남기면 해결될 수 있습니다. |
4. 모델을 선택하여 사용 시작
설정을 저장한 후, Cursor의 모델 셀렉터(Model Selector)에서 GLM-5.2를 선택하여 사용을 시작할 수 있습니다.
모델 활용 구분
| 유스케이스 | 권장 모델 | 이유 |
|---|---|---|
| 복잡한 리팩터링 · 설계 리뷰 | GLM-5.2 | SWE-bench Pro 62.1의 높은 추론 성능, 1M 토큰의 대규모 코드베이스 대응 |
| 인라인 보완 · 간단한 질문 | GLM-4.7 | 낮은 레이턴시(Latency) · 낮은 비용, 쿼터(Quota) 소비 1배 |
| 대량의 자동화 태스크 | GLM-4.7 | 쿼터 절약을 위해 일상적인 태스크는 GLM-4.7이 최적 |
💡 GLM Coding Plan에서는 GLM-5.2와 GLM-4.7을 모두 등록하여 구분해서 사용하는 것을 권장합니다. 복잡한 태스크에는 GLM-5.2를, 일상적인 태스크에는 GLM-4.7을 사용함으로써 쿼터를 효율적으로 활용할 수 있습니다.
요약
GLM-5.2는 오픈 웨이트 모델 (Open-weight model)로서 최고 수준의 코딩 성능을 보유하면서도, Claude Opus 4.8의 약 17분의 1 비용으로 이용할 수 있습니다. Cursor로의 BYOK (Bring Your Own Key) 연동 또한 OpenAI 호환 엔드포인트 (OpenAI-compatible endpoint)를 교체하는 것만으로 완료됩니다.
- Cursor Pro 플랜 필요 (커스텀 모델 설정에 필수)
- Non-Thinking 모드는 그대로 동작함
- Thinking 모드는 아직 미지원 (Feature Request 중)
- 비용 절감 효과는 출력 토큰 (Output token)이 많은 에이전트 계열 태스크에서 특히 큼
- GLM-4.7과 구분하여 사용함으로써 쿼터 (Quota)를 효율적으로 소비할 수 있음
코딩 비용을 낮추고 싶은 엔지니어에게 GLM-5.2 × Cursor의 BYOK 연동은 현시점에서도 유력한 선택지입니다.
참고 링크
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기