ByteDance, SwanVoice 출시
요약
ByteDance가 독백과 다중 화자 대화 합성이 가능한 SwanVoice를 출시했습니다. 이 모델은 flow-matching DiT를 활용해 대화 전반의 음향적 일관성을 유지하며, Tencent는 오디오-LLM 통합을 위한 Universal Audio Tokenizer를 공개했습니다.
핵심 포인트
- SwanVoice는 최대 4명의 화자가 참여하는 대화 합성 지원
- flow-matching DiT를 통한 음향적 일관성 유지
- 표현력이 풍부한 제로샷 음성 합성 기술 적용
- Tencent의 Universal Audio Tokenizer는 오디오 인지와 언어적 정렬 결합
ByteDance가 SwanVoice를 출시했습니다.
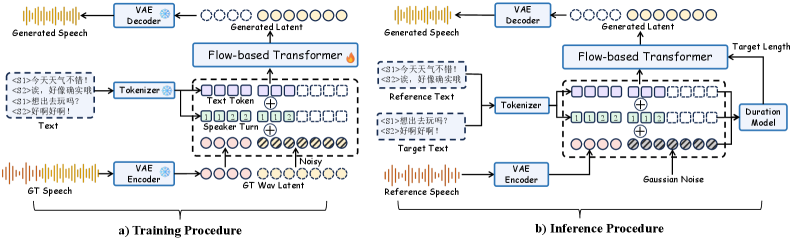
이 모델은 긴 형태의 독백 (monologue) 및 최대 4명의 화자가 참여하는 대화 (dialogue)를 합성합니다.
이 모델은 대화 차례 (turns) 전반에 걸쳐 음향적 일관성 (acoustic consistency)을 유지합니다.
화자 차례 조건화 (speaker-turn conditioning)를 갖춘 플로우 매칭 DiT (flow-matching DiT)를 사용합니다.
표현력이 풍부한 제로샷 음성 합성 (zero-shot speech synthesis)을 들어보세요.
SwanVoice는 독백과 다중 화자 대화를 모두 처리합니다.
프로젝트:
https://swanaigc.github.io/#/swanvoice
논문:
https://huggingface.co/papers/2605.30993
…
Tencent가 방금 Hugging Face에 Universal Audio Tokenizer를 출시했습니다.
매끄러운 Audio-LLM 통합을 위해 일반적인 오디오 인지 (audio perception)와 언어적 정렬 (linguistic alignment)을 독특하게 결합한 소형 단일 코드북 (single-codebook) 모델입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기