Box AI가 Deep Agents를 통해 기업용 콘텐츠 에이전트를 구축한 방법
요약
Box는 기업용 콘텐츠 에이전트인 Box Agent를 구축하기 위해 Deep Agents 프레임워크를 도입했습니다. 부모-자식 에이전트 구조를 통해 복잡한 의도를 분류하고, 다양한 LLM을 유연하게 사용할 수 있는 에이전트 중심 아키텍처를 구현했습니다.
핵심 포인트
- Deep Agents를 활용한 부모/자식 에이전트 아키텍처 구축
- OpenAI, Anthropic 등 다양한 LLM을 지원하는 모델 불가지론 확보
- RAG 기반 Knowledge Hubs를 통한 기업 규모의 데이터 분석 지원
- 에이전트 하네스를 통한 개발 및 반복 속도 3배 향상
Box는 100,000개 이상의 기업이 비정형 데이터 (unstructured data)를 저장, 보안 유지 및 관리하기 위해 신뢰하는 지능형 콘텐츠 관리 플랫폼입니다. Box AI의 일부인 Box Agent는 Deep Agents를 기반으로 구축되어, Box의 기존 보안 및 권한 모델을 준수하면서 기업의 콘텐츠 라이브러리를 검색하고, 수천 개의 문서에 걸친 조사 내용을 종합하며, 보고서와 분석 결과물을 생성합니다.
단일 파일 Q&A에서 기업 규모의 분석으로
Box Agent의 첫 번째 반복 버전은 사용자가 단일 문서 내에서 질문할 수 있도록 했습니다. 그 후, 팀은 사용자가 정의된 지식 소스 전체를 쿼리할 수 있는 RAG (Retrieval-Augmented Generation) 기반 레이어인 Knowledge Hubs를 도입했습니다.
Box의 수석 AI 아키텍트 (Principal AI Architect)인 Sesh Jalagam은 다음과 같이 설명했습니다. *"에이전트로 시작했을 때, 우리는 검색 문제를 해결하고 싶었습니다. 기업용 검색은 중복된 정보, 오래된 정보, 겉보기에는 비슷해 보이지만 기업마다 고유한 명칭 (nomenclature)을 사용하는 것들 때문에 매우 까다롭습니다." *
이러한 기능들은 가치가 있었지만, 사용자들은 점점 더 다양한 도메인에 걸쳐 복잡한 질문을 던지기 시작했습니다. 예를 들어, 바이오 과학 기업의 연구원들은 새로운 연구를 시작하기 전에 Box AI에게 기존 연구 결과들을 종합해 달라고 요청할 수 있습니다. 법무 팀은 지난 10년 동안 특정 금액을 초과하는 모든 계약서를 추출하여 리스크 루브릭 (risk rubric)에 따라 평가해 달라고 요청할 수도 있습니다. 더욱 풍부한 AI 네이티브 (AI-native) 경험을 위해, Box는 표준적인 Q&A를 넘어서는 에이전트 중심 아키텍처 (agentic architecture)가 필요했습니다.
제어, 모델 유연성 및 속도를 위한 Deep Agents 선택
Box는 에이전트 플랫폼을 구축하기 시작할 때 여러 프레임워크를 평가했습니다. 두 가지 요구 사항이 결정에 영향을 미쳤습니다.
완전한 모델 불가지론 (Model agnosticism). Box는 고객에게 OpenAI와 Anthropic부터 Google 등에 이르기까지 다양한 LLM (Large Language Model) 제공업체를 선택할 수 있는 옵션을 제공하며, 이러한 유연성은 플랫폼 수준에서 반드시 유지되어야 했습니다. 반복 속도 (Speed of iteration). 10만 명 이상의 기업 고객을 위해 Box Agent를 출시하고 개선하기 위해, Box 팀은 핵심 에이전트 인프라를 재구축하는 대신 기업 특화 문제에 엔지니어링 시간을 집중해야 했습니다.
Deep Agents는 이 두 가지를 모두 충족했습니다. 모델 추상화 계층 (Model abstraction layer)은 제공업체에 구애받지 않는 라우팅 (Routing)을 처리했고, 오픈 에이전트 하네스 (Open agent harness)는 반복 속도를 3배 높였습니다. "우리는 미래 지향적인 프레임워크 위에서 구축하면서도, 모든 구성 요소를 완전히 제어하기를 원했습니다," 라고 Jalagam은 말했습니다.
Deep Agent 아키텍처: 스스로 자식 에이전트를 생성하는 부모 에이전트
Box Agent의 아키텍처는 부모와 모든 자식이 모두 Deep Agents인 부모/자식 (Parent/child) 모델을 사용합니다. 부모(Global Agent라고 불림)는 요청을 받고, 의도 (Intent)를 분류하며, 이를 직접 처리할지 아니면 작업을 분산하기 위해 자식 에이전트를 생성할지를 결정합니다. 자식 에이전트는 부모에게 도구 (Tools)로 표현되므로, 부모가 키워드 검색을 수행하든 새로 생성된 하위 에이전트에게 위임하든 호출 인터페이스 (Invocation surface)를 균일하게 유지합니다.
이 설계는 검색 전용 에이전트, QA 에이전트, 작성 (Compose) 에이전트와 같이 하드코딩된 전문화된 하위 에이전트를 가졌던 이전 아키텍처에서 의도적으로 진화한 결과입니다. 이전 방식은 불필요한 지연 시간 (Latency)을 발생시켰습니다. "질문이 매우 간단하거나 검색이 매우 단순하다면, 부모 노드가 그냥 처리할 수 있습니다," 라고 Box의 AI 엔지니어링 리더인 Shubhro Roy는 말했습니다. "심지어 계획을 세울 필요조차 없습니다."
복잡한 작업의 경우, 동작 방식이 완전히 달라집니다. 예를 들어, 지난 10년 동안 특정 임계값을 초과하는 모든 계약서를 추출하고 이를 리스크 루브릭 (risk rubric)에 따라 평가하라는 요청을 받으면, Global Agent는 계획을 수립한 후 이를 확장(fan out)합니다. 하나의 하위 에이전트(child agent)는 관련 문서를 검색하고, 다른 하나는 병렬로 루브릭을 검색하며, 세 번째 에이전트는 앞의 두 작업이 완료되면 결과를 합성하고 분석합니다. 3개의 에이전트 모두(또는 작업 요구 사항에 따라 그 이상의 수의 에이전트)는 격리된 컨텍스트 윈도우 (context window) 내에서 실행되며, 미들웨어 (middleware) 레이어를 통해 결과를 보고합니다.
하위 에이전트들은 미리 정의된 것이 아니라 동적으로 생성되기 때문에, 시스템은 Box의 제품 팀이 명시적으로 설계하지 않은 작업들도 처리할 수 있습니다. Global Agent는 실행 시점 (runtime)에 어떤 하위 에이전트를 생성할지, 그리고 그들에게 어떤 도구 (tool)를 부여할지를 결정합니다.
부모 에이전트와 하위 에이전트 모두 BM25 키워드 검색, 벡터 검색 (vector search), 스프레드시트에 대한 구조화된 질의응답 (structured Q&A), 파일 작업 등을 포함하는 동일한 전체 도구 레지스트리 (tool registry)에 접근할 수 있습니다. Box는 요청마다 도구의 하위 집합을 동적으로 선택하려고 시도하는 대신, 사용 사례가 확장됨에 따라 모델이 그 어떤 정적 라우팅 로직 (static routing logic)보다 어떤 도구를 사용할지 더 잘 결정한다는 것을 발견했습니다.
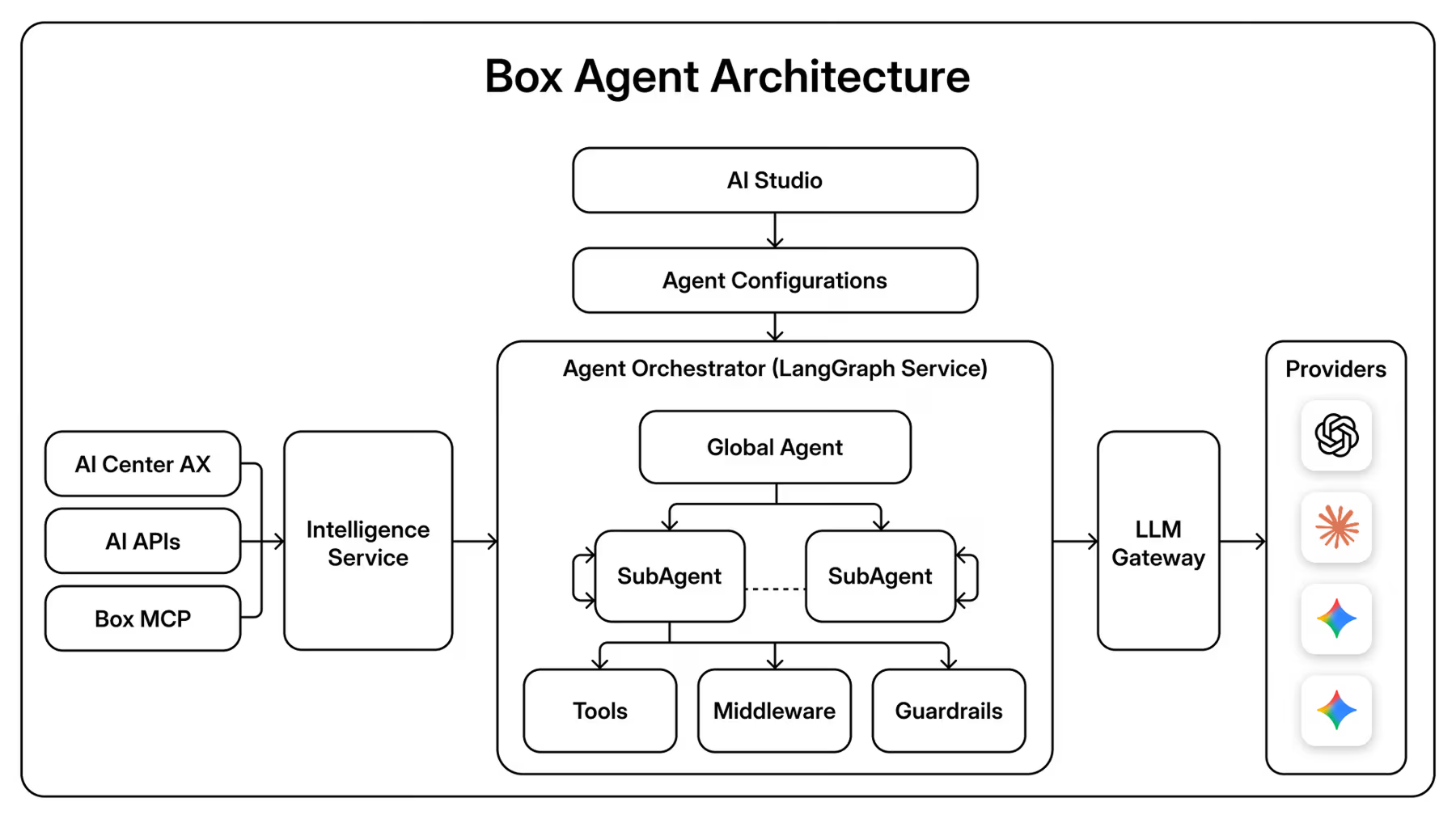
미들웨어 (Middleware): 인용 (Citations), 캐싱 (Caching), 그리고 컨텍스트 관리 (Context Management)
Box는 모델 및 도구 호출을 가로채는 Deep Agents 미들웨어를 사용합니다. 미들웨어를 사용하면 가드레일 (guardrails), 승인 (approvals), 동적 컨텍스트 (dynamic context) 및 기타 애플리케이션별 동작을 통해 에이전트 루프 (agent loop)를 맞춤 설정할 수 있습니다. Box Agent를 위한 미들웨어의 세 가지 기능은 다음과 같습니다:
인용 생성 (Citation generation). 복잡한 다중 문서 답변의 경우, 인용은 응답 스트리밍 (response streaming) 중에 병렬 프로세스로 실행됩니다. 스트리밍된 답변이 완료될 때쯤이면 인용을 첨부할 준비가 됩니다. 임베딩 기반 매칭 (Embedding-based matching)이 출처 귀속을 처리하며, 여러 소스에 걸쳐 인용이 적절히 분배되도록 하는 내장 로직이 포함되어 있습니다. "미들웨어로 이를 구현하는 장점은 답변 스트리밍과 인용 생성이 병렬로 이루어지기 때문에 사용자의 흐름을 절대 방해하지 않는다는 점입니다," 라고 Roy는 설명했습니다.
프롬프트 캐싱 (Prompt caching). 미들웨어는 다회차 대화 (multi-turn conversations)에 캐싱을 주입하여, 대화 기록이 누적됨에 따라 비용과 지연 시간 (latency)을 모두 줄여줍니다.
컨텍스트 관리 (Context management). 대화 기록이 170,000 토큰을 초과하면 미들웨어가 이를 자동으로 요약하여, 에이전트 로직의 변경 없이도 컨텍스트 오버플로 (context overflow)를 방지합니다.
미들웨어는 또한 부모 에이전트와 자식 에이전트 사이의 통신 채널 역할도 수행합니다. 검색을 완료한 자식 에이전트는 미들웨어를 통해 결과를 기록하며, 부모 및 다른 자식 에이전트들은 해당 결과를 읽고 실행할 수 있습니다. 이것이 단일 실행 내에서 에이전트 간에 중간 산출물 (intermediate artifacts)이 흐르는 방식입니다.
반복 속도: 몇 달에서 몇 주로
Deep Agents를 기반으로 구축함으로써 Box의 엔지니어링 속도 (engineering velocity)가 유의미하게 가속화되었습니다. "이전에는 Box AI를 완전히 바닥부터 구축했기 때문에 시장에 제품을 내놓기까지 더 많은 시간이 걸렸습니다," 라고 Jalagam은 강조했습니다. *"현재의 스택을 사용하면 팀은 몇 주 안에 새로운 에이전트를 출시할 수 있습니다."
이러한 가속화는 에이전트 플랫폼 자체 내에서도 나타납니다. 하드코딩된 특화된 서브 에이전트 (sub-agents)를 포함했던 첫 번째 에이전트 아키텍처는 개발 및 출시까지 약 3개월이 소요되었습니다. 그 뒤를 이은 재귀적 부모/자식 아키텍처는 4배 더 빠르게 출시되었습니다.
Box Agent의 조직 지식 확장
오늘날 Box Agent가 보유한 역량—기업 전반에 걸친 검색 (cross-enterprise search), 다중 문서 합성 (multi-document synthesis), 구조화된 보고서 생성 (structured report generation)—은 정규직 직원 수준의 조직 지식 (institutional knowledge)을 갖춘 미래형 에이전트를 위한 토대입니다. Jalagam은 "모든 상황이 어떻게 돌아가는지에 대해 10년 치의 이해도를 가진 직원을 상상해 보십시오"라고 말했습니다. 로드맵에는 에이전트 내의 더욱 풍부한 메모리 (memory) 및 지식 구성 (knowledge composition), 백그라운드에서 오프라인으로 실행되며 정보를 수집하고 드러내는 능력, 그리고 내부 팀 및 외부 시스템 모두와의 더 깊은 커뮤니케이션이 포함되어 있습니다.
*Box의 에이전트 아키텍처 (Agent Architecture)에 대해 더 알아보기: https://blog.box.com/how-box-built-its-ai-agent-langgraph *
기업용 콘텐츠를 기반으로 에이전트를 구축하시겠습니까? Deep Agents에 대해 더 알아보세요.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기