Auto-Evaluator의 기회
요약
LLM 기반의 문서 질문-답변(QA) 체인 품질을 자동으로 평가하기 위한 오픈 소스 도구인 'auto-evaluator'가 호스팅 앱과 API 형태로 출시되었습니다. 이 도구는 Anthropic과 OpenAI의 연구 방식을 결합하여 테스트 세트 생성부터 결과 채점까지 자동화하며, LangChain을 활용해 모듈식 구성이 가능합니다.
핵심 포인트
- QA 시스템의 환각 현상 및 품질 저하 문제를 해결하기 위한 자동 평가 워크스페이스 제공
- Anthropic의 평가 세트 생성 방식과 OpenAI의 모델 채점 방식을 결합한 구조
- LangChain의 추상화를 활용하여 모델, 리트리버, 청크 크기 등 다양한 구성 요소의 성능 비교 가능
- 데모 및 플레이그라운드를 통해 사용자가 직접 문서를 입력하고 QA 체인을 실험할 수 있는 환경 지원
- 현재 파일 전송 속도 개선 등 성능 최적화를 위한 개선 기회 존재
편집자 주: 이 글은 Lance Martin의 게스트 블로그 포스트입니다.
요약 (TL;DR)
최근 저희는 LLM(Large Language Model)의 질문-답변 체인을 채점하기 위한 auto-evaluator 도구를 오픈 소스로 공개했습니다. 이제 사용성을 확장하기 위해 오픈 소스이며 무료로 사용할 수 있는 호스팅 앱과 API를 출시합니다. 아래에서는 이를 더욱 개선하기 위한 몇 가지 기회에 대해 논의합니다.
배경 (Context)
문서 질문 답변 (Document Question-Answering)은 인기 있는 LLM 활용 사례입니다. LangChain은 LLM 구성 요소(예: 모델 및 리트리버 (retrievers))를 질문 답변을 지원하는 체인 (chains)으로 쉽게 조립할 수 있게 해줍니다. 즉, 입력 문서는 청크 (chunks)로 분할되어 리트리버에 저장되고, 사용자의 질문 (question)이 주어지면 관련 청크가 검색되어 답변 (answer)으로 합성하기 위해 LLM에 전달됩니다.
문제 (Problem)
QA 시스템의 품질은 상당히 다를 수 있습니다. 특정 파라미터 (parameter) 설정으로 인해 환각 (hallucination) 현상이 발생하거나 답변 품질이 저하되는 사례를 목격했습니다. 하지만 (1) 답변 품질을 평가하고, (2) 이 평가를 사용하여 개선된 QA 체인 설정(예: 청크 크기, 검색된 문서 수) 또는 구성 요소(예: 모델 또는 리트리버 선택)를 가이드하는 것은 항상 명확하지 않습니다.
앱 (App)
auto-evaluator는 이러한 한계를 해결하는 것을 목표로 합니다. 이 도구는 두 가지 분야의 작업에서 영감을 받았습니다: 1) Anthropic의 최근 연구는 모델이 작성한 평가 세트를 사용했으며, 2) OpenAI는 모델이 채점하는 평가를 보여주었습니다. 이 앱은 이 두 가지 아이디어를 하나의 워크스페이스 (workspace)로 결합하여, 주어진 입력 문서에 대한 QA 테스트 세트를 자동 생성하고 사용자가 지정한 QA 체인의 결과를 자동 채점합니다. LangChain의 추상화 (abstraction) 덕분에 테스트를 위한 모듈형 구성 요소로 QA를 쉽게 구성할 수 있습니다 (아래 색상으로 표시됨).
사용법 (Usage)
사용성을 확장하기 위해 이제 오픈 소스이며 무료로 사용할 수 있는 호스팅 앱과 API를 출시합니다. 앱은 두 가지 방식으로 사용할 수 있습니다 (자세한 내용은 README를 참조하세요):
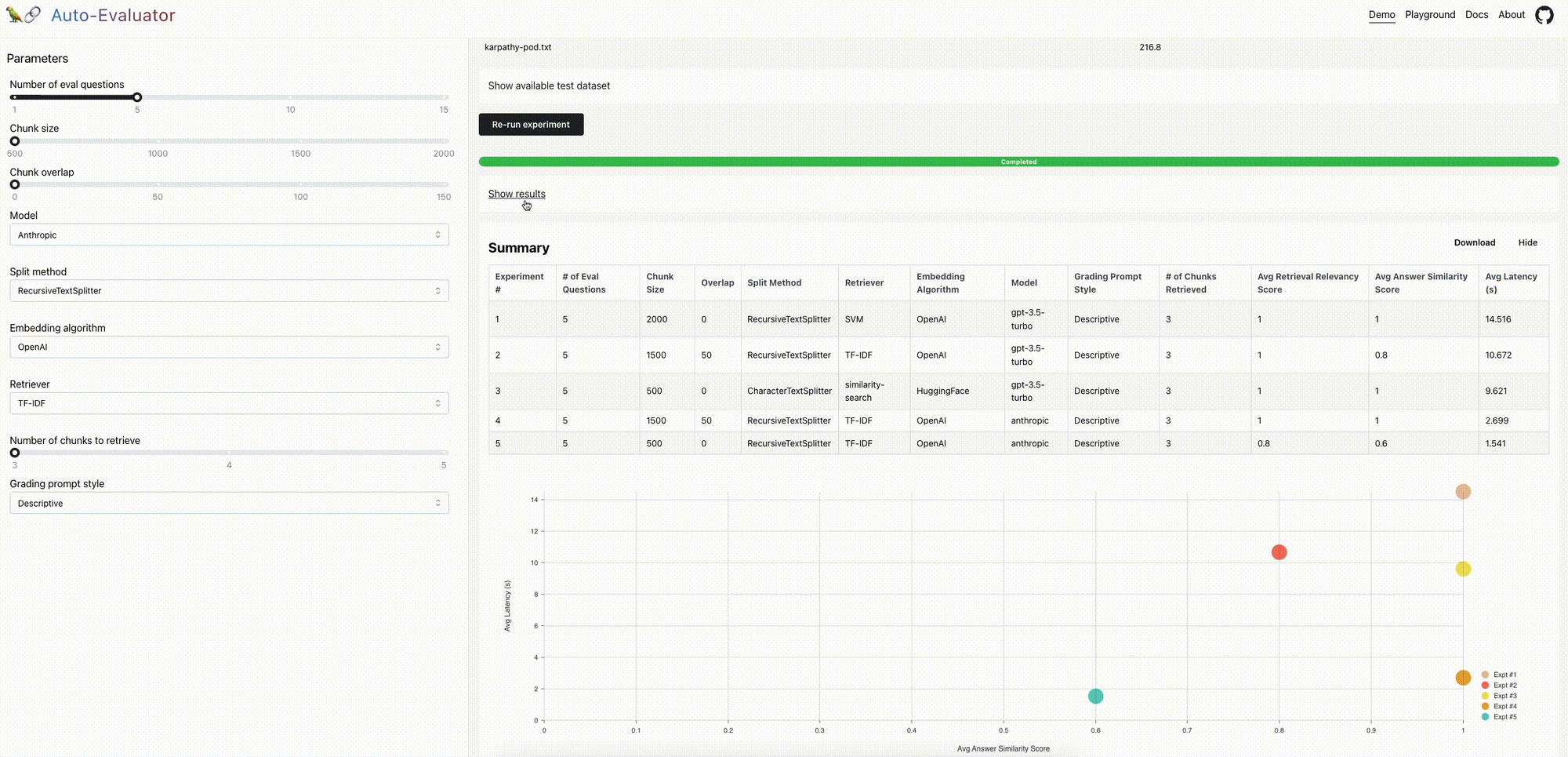
데모 (Demo): 저희는 문서(Andrej Karpathy가 출연한 Lex Fridman 팟캐스트의 스크립트)와 해당 팟캐스트에서 추출한 5개의 질문-답변 쌍을 미리 로드해 두었습니다. QA 체인을 구성하고 실험을 실행하여 상대적인 성능을 평가할 수 있습니다.
플레이그라운드 (Playground)
: nat.dev 플레이그라운드 (Playground)에서 영감을 받아, 사용자는 문서를 입력하여 다양한 QA 체인 (QA chain)을 평가할 수 있습니다. 선택적으로, 사용자는 해당 문서와 관련된 질문-답변 (question-answer) 쌍의 테스트 세트를 포함할 수 있습니다. 여기와 여기에서 예시를 확인하십시오.
개선 기회 (Opportunities)
파일 처리 (File handling)
클라이언트에서 백엔드 (back-end)로의 파일 전송이 느립니다. 파일 2개 (39MB)의 경우, 전송에 약 40초가 소요됩니다:
| 구분 | 운영 환경 (Prod) | 스테이징 (Stage) |
|---|---|---|
| OAI 임베딩 (OAI embedding) | 경과 시간 (Elapsed time) | 경과 시간 (Elapsed time) |
| 파일 전송 (Transfer file) | 37 초 | 0 초 |
| 파일 읽기 (Reading file) | 5 초 | 1 초 |
| 문서 분할 (Splitting docs) | 3 초 | 3 초 |
| LLM 생성 (Making LLM) | 1 초 | 1 초 |
| 리트리버 생성 (Make retriever) | 6 초 | 2 초 |
| 성공 (Success) | ✅ | ✅ |
이미지는 파일 크기를 부풀리므로, 클라이언트에서 전송하기 전에 제거될 수 있습니다:
| 구분 | 운영 환경 (Prod) | 운영 환경 (Prod) | 운영 환경 (Prod) | 운영 환경 (Prod) | 스테이징 (Stage) |
|---|---|---|---|---|---|
| 파일 크기/페이지 | 1.3 MB, 40 pg | 3.5 MB, 42 pg | 7.7 MB, 42 pg | 32 MB, 54 pg | |
| 경과 시간 (Elapsed time) | 경과 시간 (Elapsed time) | ||||
| 파일 전송 (Transfer file) | 1 초 | 3 초 | 5 초 | 35 초 | 1 초 |
| 파일 읽기 (Reading file) | 5 초 | 4 초 | 6 초 | 7 초 | 5 초 |
| 문서 분할 (Splitting docs) | 0 초 | 0 초 | 0 초 | 1 초 | 0 초 |
| LLM 생성 (Making LLM) | 1 초 | 1 초 | 1 초 | 1 초 | 1 초 |
| 리트리버 생성 (Make retriever) | 3 초 | 3 초 | 3 초 | 4 초 | 3 초 |
| 성공 (Success) | ✅ | ✅ | ✅ | ✅ | ✅ |
모델 작성 평가 (Model-written-evaluations)
Anthropic 및 기타 기업들은 모델 작성 평가 (model-written evaluations)에 관한 내용을 발표했습니다. 여기서 우리는 속도를 위해 매우 단순한 방식을 사용합니다. 즉, 입력 컨텍스트 (input context)에서 무작위로 선택하여 QA 쌍을 생성합니다. 자세한 내용은 당사의 블로그 포스트 여기에서 확인할 수 있습니다. 이를 상당히 개선할 기회가 있습니다 (예: 입력의 전체 컨텍스트를 반영한 질문 생성).
리트리버 (Retrievers)
LangChain의 리트리버 (Retriever) 추상화에는 문서 검색을 위한 여러 가지 접근 방식이 포함되어 있습니다. 벡터 데이터베이스 (VectorDBs, 예: FAISS, Chroma 등)의 임베딩 (Embeddings)에 대한 k-최근접 이웃 (k-Nearest Neighbor) 검색이 대중적인 방식이지만, 다른 대안들도 존재합니다. 예를 들어, Karpathy는 최근 SVM을 리트리버로 사용하는 것에 대해 논의했으며, TF-IDF와 같은 통계적 접근 방식도 고려할 수 있는 옵션입니다. Auto-evaluator를 사용하면 다양한 리트리버를 쉽게 추가하거나 테스트할 수 있습니다. 저희는 Kipply의 훌륭한 트랜스포머 분류 체계 (Transformer taxonomy)에서 추출한 15편의 논문으로 구성된 테스트 세트를 구축했습니다. 물론 개선될 여지가 있는 테스트 세트는 다음과 같습니다:
질문
답변
GPT-3는 어떤 데이터 코퍼스 (Corpus)로 학습되었나요?
GPT-3는 주로 필터링된 Common Crawl과 일부 도서, webtext 및 Wikipedia로 구성된 3,000억(300B) 토큰 데이터셋으로 학습되었습니다.
인컨텍스트 러닝 (In-context learning)이란 무엇인가요?
사전 학습 (Pre-training) 과정에서 습득한 광범위한 기술과 패턴 인식 능력은 추론 (Inference) 시점에 가중치 업데이트 없이 입력-출력 예시만 주어졌을 때 새로운 작업을 수행하는 데 사용될 수 있습니다. 이는 대규모 언어 모델 (Large Language Models, LMs)에서 나타나는 창발적 행동 (Emergent behavior)입니다.
LaTeX 수식에 대해 Galatica는 GPT-3보다 얼마나 더 나은가요?
LaTeX 수식에서 Galatica는 68.2%의 점수를 기록한 반면, 최신 GPT-3는 49.0%를 기록했습니다.
BLOOM 모델은 무엇으로 학습되었나요?
BLOOM은 46개의 자연어와 13개의 프로그래밍 언어를 아우르는 1.61테라바이트 분량의 498개 Hugging Face 데이터셋이 결합된 ROOTS 코퍼스 (Corpus)로 학습되었습니다.
Chinchilla 논문은 연산 최적화 학습 (Compute optimal training)을 위해 무엇이 중요하다고 주장하나요?
Chinchilla 논문은 연산 최적화 학습을 위해 모델 크기와 학습 토큰의 수가 동일하게 확장되어야 함을 발견했습니다. 즉, 모델 크기가 두 배가 될 때마다 학습 토큰의 수도 두 배가 되어야 합니다.
다음은 요약 결과입니다. 상세 결과는 여기에서 확인할 수 있습니다.
요약하자면, 이 특정 사례에서는 TF-IDF와 SVM 모두 k-NN과 대등하거나(실제로 조금 더 나은) 성능을 보입니다. 물론 이것이 항상 사실인 것은 아니지만, 핵심은 검색 (Retrieval) 단계에서 고려할 가치가 있는 많은 옵션이 있다는 점입니다.
모델 등급 평가 (Model-Graded Eval)
점수 산정 프롬프트 (Scoring prompts)
핵심 아이디어는 프롬프트를 사용하여 모델이 생성한 답변(및 검색된 문서)을 정답 (Ground Truth)과 비교하여 등급을 매기는 것입니다. 저희는 여러 프롬프트를 테스트했으며, 그 결과는 여기에서 확인할 수 있습니다. 각 프롬프트에 따른 결과(질문, 답변, 등급 근거)와 요약은 여기에서 확인할 수 있습니다:
| 프롬프트 | 답변 점수 (정답 비율) |
|---|---|
| Fast | 5 / 5 |
| Descriptive | 4 / 5 |
| Descriptive with bias | 5 / 5, 2 / 5 |
요약하자면, 답변 점수는 프롬프트에 따라 달라집니다 (예: OpenAI의 등급 산정이 가장 엄격함). 향후 연구는 모델 등급 평가 (Model-graded-evaluation)를 위한 프롬프트를 정교화하는 데 집중해야 합니다.
가변성 (Variability)
현재 앱은 평가자 (Grader)로 GPT-3.5-turbo를 사용하고 있지만, OpenAI와의 논의에 따르면 GPT4가 더 선호됩니다. 여기 한 가지 예시가 있습니다. 평가자가 이중 부정문에 혼동을 일으켜 동일한 입력 질문/답변에 대해 비결정론적 (Non-deterministic)인 출력을 생성하는 것으로 보입니다.
| 실험 (Experiment) | 답변 (Answer) | 등급 (Grade) | 근거 (Justification) |
|---|---|---|---|
| 1 | 돌출된 지붕 면적이 100제곱피트를 초과하지 않는 한, 도구 및 저장용 창고, 놀이집 또는 이와 유사한 용도로 사용되는 단층 독립 부속 건물이나 구조물에는 건축 허가가 필요하지 않습니다. | GRADE: Incorrect (오답) | JUSTIFICATION: 학생의 답변은 돌출된 지붕 면적이 100제곱피트 이하인 구조물에 대해 건축 허가가 필요하지 않다고 기술하고 있으나, 실제 정답은 100제곱피트를 초과하는 모든 구조물에 대해 허가가 필요하다고 명시하고 있으므로 오답입니다. |
| 2 | 돌출된 지붕 면적이 100제곱피트(9.29 m2)를 초과하지 않는 한, 도구 및 저장용 창고, 놀이집 및 이와 유사한 용도로 사용되는 단층 독립 부속 건물이나 구조물에는 건축 허가가 필요하지 않습니다. | GRADE: Correct (정답) |
정당화 (JUSTIFICATION): 학생의 답변은 100제곱피트 미만의 구조물에는 건축 허가가 필요하지 않다고 정확하게 기술하였으며, 이는 사실입니다.
결론
오픈 소스 저장소 (open source repo)에 기여하거나 무료로 호스팅되는 앱을 자유롭게 테스트해 보세요. 파일 처리, 프롬프트 (prompts) (예: QA 생성, 채점 또는 QA용), 모델 (models) (예: Hugging Face의 오픈 소스 모델 추가), 또는 리트리버 (retrievers)와 관련된 기여가 가장 영향력이 큰 분야 중 일부입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기