
Align Evals 소개: LLM 애플리케이션 평가 프로세스 간소화
요약
LangSmith가 LLM 평가자와 인간의 선호도를 일치시키는 새로운 기능인 'Align Evals'를 출시했습니다. 이 기능은 LLM-as-a-judge 평가 프로세스를 간소화하고, 평가 프롬프트 개선 및 정렬 점수 확인을 통해 고품질의 평가 환경을 구축하도록 돕습니다.
핵심 포인트
- LLM 평가자와 인간의 채점 결과 간 불일치 문제 해결
- 평가자 프롬프트 개선을 위한 플레이그라운드 인터페이스 제공
- 인간 채점 데이터와 LLM 점수의 나란한 비교 기능 지원
- 베이스라인 정렬 점수 저장을 통한 버전 간 비교 가능
평가(Evaluations)는 단일 프롬프트(Prompt)를 작업하든 복잡한 에이전트(Agent)를 작업하든, 애플리케이션을 개선하기 위한 핵심 기술입니다. 모델을 비교하거나, 로직을 업데이트하거나, 아키텍처를 반복적으로 개선할 때, 평가는 출력값의 점수를 매기고 변경 사항의 영향을 이해할 수 있는 신뢰할 수 있는 방법입니다.
하지만 팀들로부터 지속적으로 듣는 큰 과제 중 하나는 다음과 같습니다: "우리의 평가 점수가 우리 팀의 사람이 말할 것으로 예상되는 내용과 일치하지 않습니다." 이러한 불일치는 노이즈가 섞인 비교로 이어지며, 잘못된 신호를 쫓느라 시간을 낭비하게 만듭니다.
그렇기 때문에 우리는 평가자가 인간의 선호도와 더 잘 일치하도록 보정(Calibrate)할 수 있도록 돕는 LangSmith의 새로운 기능인 Align Evals를 소개합니다. 이 기능은 LLM-as-a-judge 평가자 구축에 관한 Eugene Yan의 기사에서 영감을 받았습니다.
이 기능은 오늘부터 모든 LangSmith Cloud 사용자에게 제공되며, 이번 주 후반에 LangSmith Self-Hosted에도 출시될 예정입니다. 시작하려면 우리의 비디오 워크스루(Video walkthrough)를 보거나 개발자 문서(Developer docs)를 읽어보세요.
고품질 LLM-as-a-judge 평가자를 만드는 것이 더 쉬워졌습니다
지금까지 평가자를 반복적으로 개선하는 과정에는 많은 추측이 수반되는 경우가 많았습니다. 평가자 동작의 트렌드나 불일치를 파악하기 어렵고, 평가자 프롬프트(Evaluator prompt)를 변경한 후에는 어떤 데이터 포인트가 점수 변화를 일으켰는지 또는 그 이유가 무엇인지 불분명할 수 있습니다.
이 새로운 LLM-as-a-Judge 정렬(Alignment) 기능을 통해 다음을 얻을 수 있습니다:
- 평가자 프롬프트를 반복적으로 개선하고 평가자의 "정렬 점수 (Alignment score)"를 확인할 수 있는 플레이그라운드(Playground)와 같은 인터페이스
- 인간이 채점한 데이터와 LLM이 생성한 점수의 나란한 비교(Side-by-side comparison), "정렬되지 않은 (Unaligned)" 사례를 식별하기 위한 정렬 기능
- 최신 변경 사항을 이전 버전의 프롬프트와 비교하기 위해 저장된 베이스라인 정렬 점수 (Saved baseline alignment score)
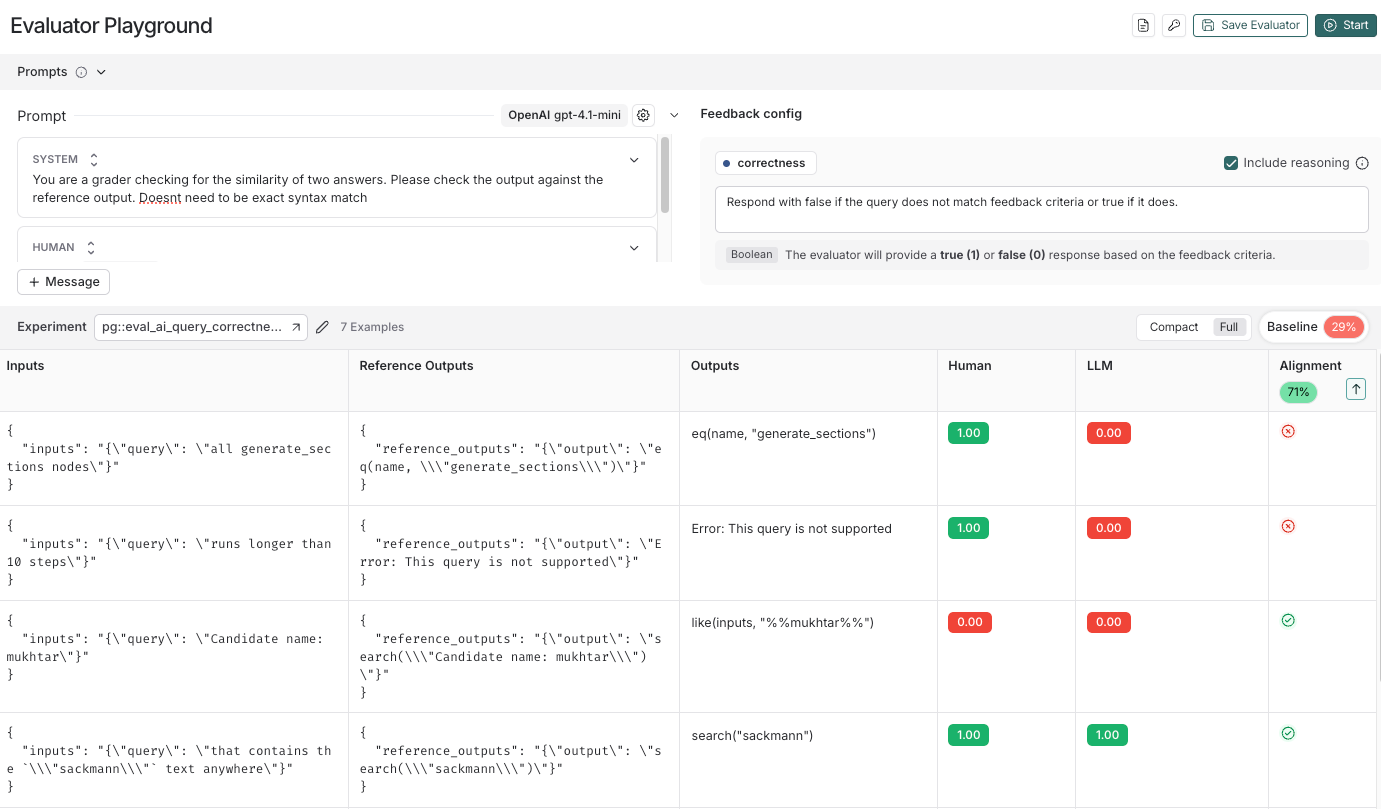
작동 방식
정렬 흐름(Alignment flow)이 작동하는 방식은 다음과 같습니다:
1. 평가 기준 선택
첫 번째 단계는 적절한 평가 기준 (evaluation criteria)을 식별하는 것입니다. 평가 기준에는 귀하의 애플리케이션이 잘 수행해야 하는 사항들이 포함되어야 합니다. 예를 들어, 채팅 앱을 구축하고 있다면 정확성 (correctness)이 중요하지만, 간결성 (conciseness) 또한 중요합니다. 요점을 전달하기까지 여러 단락이 소요되는 기술적으로 정확한 답변은 여전히 사용자들을 좌절시킬 수 있습니다.
2. 인간 검토를 위한 데이터 선택
귀하의 애플리케이션에서 대표적인 예시 세트를 만듭니다. 여기에는 좋은 예시와 나쁜 예시가 모두 포함되어야 합니다. 목표는 귀하의 애플리케이션이 실제로 생성할 출력값의 범위를 포괄하는 것입니다. 예를 들어, 고객 지원 어시스턴트가 질문에 답할 수 있는 새로운 제품을 추가하는 작업을 하고 있다면, 올바른 응답과 잘못된 응답을 모두 포함시키십시오.
3. 예상 점수로 데이터 채점
각 평가 기준에 대해, 각 예시에 점수를 수동으로 할당합니다. 이 점수들은 귀하의 "골든 세트 (golden set)"가 되며, 평가자 (evaluator)의 응답을 판단하는 벤치마크 (benchmark) 역할을 하게 됩니다.
4. 평가자 프롬프트를 생성하고 인간의 채점 결과와 대조하여 테스트
LLM 평가자를 위한 초기 프롬프트를 생성하고, 정렬 (alignment) 결과를 사용하여 반복 (iterate)합니다. 프롬프트의 각 버전마다, LLM의 점수가 귀하의 점수와 얼마나 잘 일치하는지 확인하기 위해 인간이 채점한 예시들과 대조하여 테스트합니다.
예를 들어, LLM이 특정 응답에 대해 지속적으로 높은 점수를 준다면, 더 명확한 부정적 기준 (negative criteria)을 추가해 보십시오. 평가자 점수를 개선하는 것은 반복적인 과정이어야 합니다. 프롬프트를 반복 개선하는 방법에 대한 모범 사례는 저희 문서에서 더 자세히 알아보십시오.
다음 단계는 무엇인가요?
이제 시작일 뿐입니다. 이것은 귀하가 더 나은 평가자를 구축할 수 있도록 돕기 위한 첫 번째 단계입니다. 앞으로 다음과 같은 기능들을 기대할 수 있습니다:
분석 (Analytics): 평가자의 성능이 시간이 지남에 따라 어떻게 진화하는지 추적할 수 있습니다.
자동 프롬프트 최적화 (Automatic prompt optimization): 저희가 귀하를 위해 프롬프트 변형을 자동으로 생성해 드립니다!
직접 시도해 보세요! 저희의 개발자 문서(developer documentation)를 확인하거나 비디오 튜토리얼(video tutorial)을 시청하여 시작할 수 있습니다. LangChain Community 포럼(forum)에 피드백을 남겨 귀하의 의견을 알려주세요.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기