
AI 모델 배포 완료… 그다음은 무엇인가요? 모니터링, 관측성(Observability) 및 AI 시스템이 조용히 실패하는 이유
요약
AI 모델 배포 후 발생하는 '조용한 실패'의 위험성을 경고합니다. 전통적인 소프트웨어와 달리 AI 시스템은 시스템 충돌 없이 성능 저하, 환각, 드리프트 현상이 발생하므로 모니터링과 관측성(Observability) 확보가 필수적입니다.
핵심 포인트
- AI 시스템은 전통적 소프트웨어와 달리 충돌 없이 성능이 서서히 저하됨
- 인프라 지표가 정상이어도 답변 품질이나 검색 정확도는 떨어질 수 있음
- 모델 드리프트, 환각, 지연 시간 증가 등 AI 특화 모니터링 필요
- 배포 이후의 관측성(Observability)과 워크플로우 추적이 핵심
AI 모델 배포 완료… 그다음은 무엇인가요?
모니터링, 관측성(Observability) 및 AI 시스템이 조용히 실패하는 이유
대부분의 팀은 배포가 결승선이라고 생각합니다.
모델이 작동합니다.
API가 응답합니다.
챗봇이 올바르게 답변합니다.
모두가 축하합니다.
그리고 나서…
운영(Production) 환경에 진입합니다.
갑자기:
- 사용자들이 답변이 "다르다"고 불평합니다
- 검색(Retrieval) 품질이 떨어집니다
- 지연 시간(Latency)이 증가합니다
- 비용이 예상치 못하게 급증합니다
- 환각(Hallucinations) 현상이 나타나기 시작합니다
- 에이전트 워크플로우(Agent workflows)가 이상하게 작동합니다
- 정확도가 조용히 감소합니다
하지만 대시보드는 이렇게 말합니다:
시스템 정상 ✅
인프라 장애 없음.
API 충돌 없음.
데이터베이스 중단 없음.
기술적으로는 모든 것이 괜찮아 보입니다.
하지만:
AI 시스템이 서서히 저하되고 있습니다.
이 순간 많은 팀은 불편한 사실을 깨닫습니다:
AI 시스템을 배포하는 것은 어려운 부분이 아닙니다.
배포 후에 어떤 일이 일어나는지 이해하는 것이 어려운 부분입니다.
그리고 바로 이 지점에서 모니터링(Monitoring), 관측성(Observability), 그리고 워크플로우 추적(Workflow tracing)과 같은 개념들이 중요해집니다.
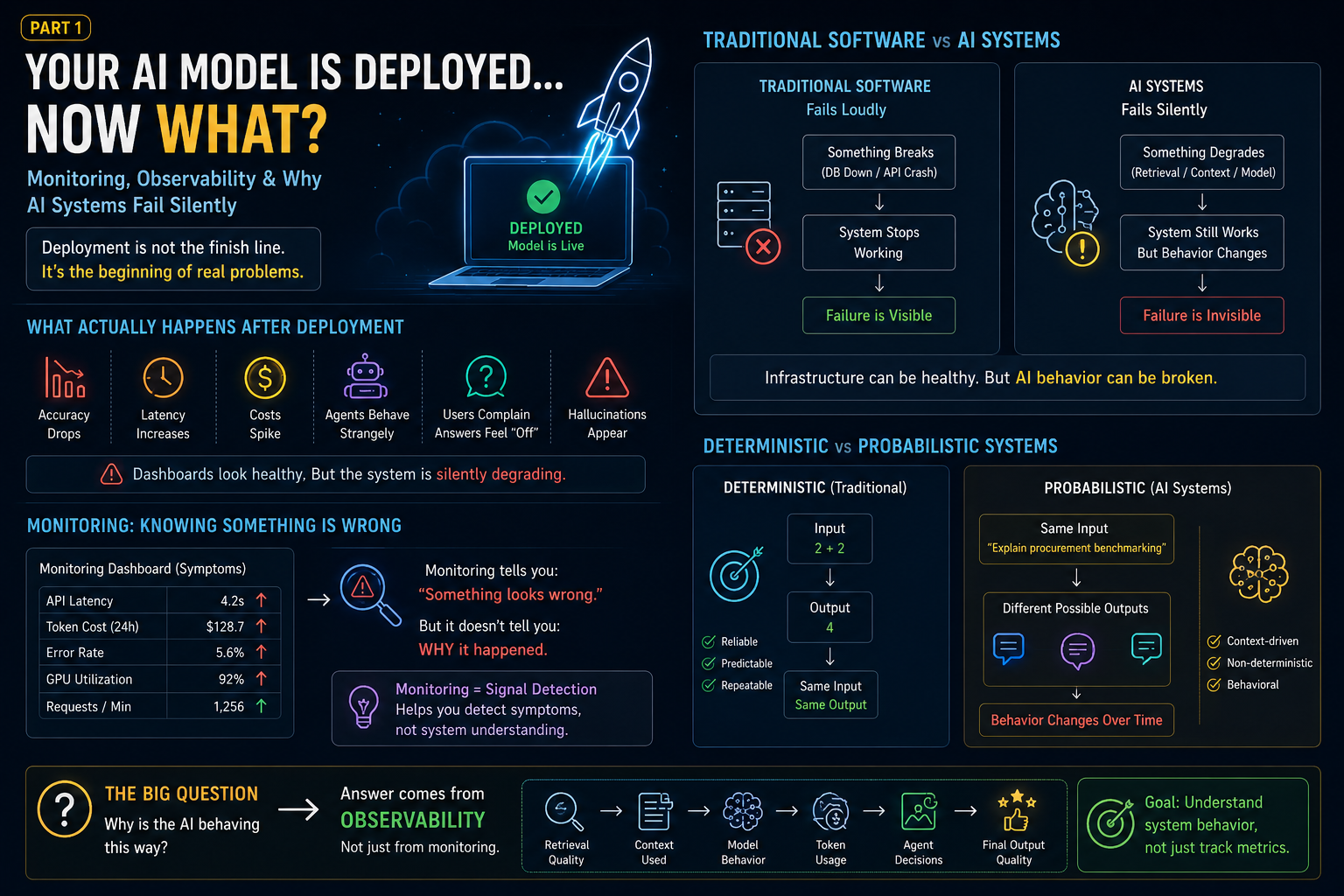
왜냐하면 전통적인 소프트웨어와 AI 시스템은 실패하는 방식이 매우 다르기 때문입니다.
전통적인 소프트웨어는 요란하게 실패합니다
전통적인 엔지니어링에서:
실패는 보통 명확합니다.
예시:
결제 API가 충돌합니다.
데이터베이스가 다운됩니다.
인증(Authentication)이 실패합니다.
시스템이 작동을 멈춥니다.
당신은 즉시 알게 됩니다:
무언가 고장 났다.
예시:
try:
process_payment()
except Exception:
return "Payment Failed"
실패가 눈에 보입니다.
...
CPU 사용량 높음
메모리 급증
API 실패
데이터베이스 타임아웃
서버 사용 불가
단순합니다.
문제가 발생했습니다.
무언가 고장 났다는 것을 압니다.
이제 엔지니어가 이를 수정합니다.
전통적인 모니터링은 이러한 세상을 위해 구축되었습니다.
하지만 AI 시스템은 다르게 작동합니다.
AI 시스템은 조용히 실패합니다
여기서부터 상황이 흥미로워집니다.
그리고 좌절스럽습니다.
왜냐하면 AI 시스템은 전통적인 소프트웨어처럼 실패하는 경우가 드물기 때문입니다.
시스템이 충돌(Crash)하는 대신:
서서히 드리프트(Drift)합니다.
예시:
어제:
당신의 금융 챗봇이 정확하게 답변했습니다.
오늘:
갑자기 불완전한 벤더 설명을 제공하기 시작합니다.
아무것도 충돌하지 않았습니다.
알람(Alert)도 울리지 않았습니다.
API 오류도 발생하지 않았습니다.
하지만:
무언가 변했습니다.
질문:
실제로 무엇이 실패했나요?
다음 중 무엇이었을까요?
- 검색 품질 (Retrieval quality)?
- 잘못된 문서 청킹 (Document chunking)?
- 컨텍스트 절단 (Context truncation)?
- 모델 드리프트 (Model drift)?
- 잘못된 프롬프트 업데이트 (Prompt update)?
- 벡터 데이터베이스 (Vector database) 문제?
- 에이전트 라우팅 (Agent routing) 문제?
- 도구 (Tool) 실패?
- 지연 시간 병목 현상 (Latency bottleneck)?
이제 디버깅(Debugging)은 훨씬 더 어려워집니다.
시스템이 여전히 작동하는 것처럼 보이기 때문입니다.
답변은 여전히 생성됩니다.
하지만 품질은 조용히 저하됩니다.
이것이 운영 환경(Production)에서 AI 시스템을 위험하게 만드는 요소입니다.
AI 시스템은 종종 다음과 같이 실패합니다:
조용하게.
그리고 조용한 실패는 비용이 많이 듭니다.
특히 엔터프라이즈 워크플로우(Enterprise workflows)에서 그렇습니다.
상상해 보세요:
매입채무(Accounts Payable) 자동화 시스템.
어제:
송장 추출 정확도:
text id="jlwm3"
...
```
오늘:
```
text id="’wini4"
...
```
아무도 즉시 알아차리지 못합니다.
송장 처리는 계속됩니다.
잘못된 필드가 추출됩니다.
불일치 탐지 기능이 약화됩니다.
재무 팀이 수동으로 개입합니다.
운영 비용이 증가합니다.
비즈니스 신뢰도가 하락합니다.
그리고 결국 누군가 질문합니다:
> “왜 AI가 갑자기 이상하게 행동하죠?”
이 지점에서 모니터링(Monitoring)만으로는 한계가 나타나기 시작합니다.
전통적인 모니터링은 오직 다음과 같이만 알려주기 때문입니다:
> 무언가 발생했다.
그것이 왜 발생했는지는 거의 설명해주지 못합니다.
그리고 이는 운영 환경의 AI 시스템에서 가장 큰 오해로 이어집니다.
사람들은 다음을 혼동합니다:
> 모니터링 (Monitoring)
과
> 관측성 (Observability)
을.
이 둘은 같은 것이 아닙니다.
근처에도 가지 못할 만큼 다릅니다.
---
## 모니터링: 무언가 잘못되었다는 것을 아는 것
모니터링은 한 가지 질문에 답합니다:
> 시스템이 건강한가?
대시보드 예시:
```
text id="jlwm5"
...
```
유용한가요?
네.
하지만 불완전합니다.
모니터링은 증상(Symptoms)을 감지하는 데 도움을 줍니다.
예시:
당신은 알고 있습니다:
```
text id="’wini6"
...
```
하지만:
여전히 알지 못합니다:
> 왜 그런지.
이것은 병원 모니터와 유사합니다.
의사는 다음과 같은 것을 봅니다:
```
text id="’wini7"
...
```
하지만 그것은 다음을 설명하지 못합니다:
> 근본 원인 (Root cause).
모니터링 (Monitoring)은 신호 탐지입니다.
시스템에 대한 이해가 아닙니다.
그리고 AI 시스템의 경우:
이것은 중대한 한계가 됩니다.
왜냐하면 AI 시스템은 확률적 (Probabilistic)이기 때문입니다.
결정론적 (Deterministic)이지 않습니다.
---
## 결정론적 시스템 (Deterministic Systems) vs 확률적 시스템 (Probabilistic Systems)
전통적인 소프트웨어:
입력 (Input):
```
text id="’wini8"
...
```
출력 (Output):
```
text id="’wini9"
...
```
매번 동일합니다.
신뢰할 수 있습니다.
예측 가능합니다.
AI 시스템은 어떨까요?
동일한 입력.
서로 다른 출력.
예시:
LLM (Large Language Model)에게 질문합니다:
> 조달 벤치마킹 (Procurement benchmarking)에 대해 설명해줘.
어느 날은:
완벽한 답변.
다음번에는:
약간 다른 설명.
때로는:
환각 (Hallucination)된 세부 사항.
때로는:
누락된 문맥 (Context).
때로는:
정확하지만 불완전함.
시스템은 여전히 작동합니다.
하지만 동작이 변합니다.
이것은 디버깅 (Debugging) 방식의 변화를 가져옵니다.
당신은 더 이상 다음을 디버깅하는 것이 아닙니다:
> 하드 실패 (Hard failures)
당신은 다음을 디버깅하고 있는 것입니다:
> 시스템 동작 (System behavior).
그리고 동작은 인프라 메트릭 (Infrastructure metrics)만으로는 모니터링할 수 없습니다.
이 지점에서 관측성 (Observability)이 필수적이 됩니다.
왜냐하면 관측성은 다음을 묻는 것이 아니기 때문입니다:
> “무언가 실패했는가?”
관측성은 다음을 묻는 것입니다:
> “왜 시스템이 이런 방식으로 동작했는가?”
그리고 이것이 모든 것을 바꿉니다.
>
# 제2부: 모니터링 vs 관측성, RAG 실패 및 전통적인 대시보드가 AI 시스템에서 실패하는 이유
이제 우리는 중요한 사실 하나를 알고 있습니다:
AI 시스템은 요란하게 실패하는 경우가 드뭅니다.
그들은 다음과 같이 실패합니다:
> 조용하게.
그리고 이것은 문제를 야기합니다.
왜냐하면 대부분의 팀은 여전히 확률적으로 동작하는 시스템을 디버깅하기 위해 전통적인 모니터링 접근 방식을 사용하고 있기 때문입니다.
이는 마치 CPU 그래프만을 사용하여 인간의 행동을 진단하려는 것과 같습니다.
때로는 작동할 수도 있습니다.
하지만 충분하지 않습니다.
그 이유를 이해해 봅시다.
---
## 모니터링은 무언가 잘못되었다는 것을 알려줍니다
관측성은 왜 그런지 이해하도록 도와줍니다
언뜻 보기에는:
두 개념이 비슷하게 들립니다.
하지만 이들은 서로 다른 문제를 해결합니다.
### 모니터링
모니터링은 다음과 같이 묻습니다:
> 시스템이 건강한가?
예시:
당신은 다음을 모니터링합니다:
```
text id="jlwm1"
...
```
대시보드는 다음과 같이 말합니다:
```
text id="’wini1"
...
```
좋습니다.
무언가 변했습니다.
하지만:
왜일까요?
단서가 없습니다.
모니터링 (Monitoring)은 반응적 (Reactive)입니다.
증상을 감지할 뿐입니다.
---
### 관측성 (Observability)
관측성 (Observability)은 다음과 같이 묻습니다:
> 시스템이 왜 이런 방식으로 동작했는가?
이 차이는 생성형 AI (GenAI) 시스템에서 매우 중요해집니다.
왜냐하면:
AI는 여전히 답변을 생성할 수 있기 때문입니다.
하지만 답변의 품질은 조용히 저하될 수 있습니다.
예시:
사용자가 질문합니다:
> 왜 Vendor X에 대한 결제가 지연되었나요?
어제:
시스템은 다음과 같이 답변했습니다:
```
text id="’wini2"
...
```
오늘:
시스템은 다음과 같이 응답합니다:
```
text id="’wini3"
...
```
그럴싸해 보입니다.
하지만 틀렸습니다.
질문:
무슨 일이 일어난 걸까요?
관측성 (Observability)을 통해 다음을 조사할 수 있습니다:
```
text id="’wini4"
...
```
이제 디버깅 (Debugging)이 가능해집니다.
추측하는 대신:
동작을 조사합니다.
그것이 관측성 (Observability)입니다.
---
## 전통적인 대시보드가 AI 시스템에서 실패하는 이유
전통적인 대시보드는 다음과 같은 용도로 설계되었습니다:
```
text id="’wini5"
...
```
즉:
다음 사항을 모니터링합니다:
```
text id="’wini6"
...
```
하지만 생성형 AI (GenAI) 시스템은 다르게 실패합니다.
예시:
당신의 RAG 챗봇을 상상해 보세요.
사용자가 질문합니다:
> 회사의 비용 환급 정책을 설명해 줘.
시스템이 잘못된 답변을 반환합니다.
대시보드는 다음과 같이 말합니다:
```
text id="’wini7"
...
```
모든 것이 완벽해 보입니다.
하지만 사용자 경험 (User experience)은 망가졌습니다.
왜일까요?
실패가 다음 단계에서 발생했기 때문입니다:
> 검색 계층 (Retrieval layer).
전통적인 모니터링 (Monitoring)은 이를 완전히 놓칩니다.
이것이 AI 시스템에서 가장 큰 사각지대 중 하나입니다.
인프라가 건강하다고 해서 AI가 건강한 것은 아닙니다.
---
## RAG 시스템은 기이한 방식으로 실패한다
실제 사례를 들어보겠습니다.
검색 증강 생성 (Retrieval-Augmented Generation, RAG) 시스템:
워크플로우 (Workflow):
```
text id="’wini8"
...
```
단순해 보입니다.
하지만 실패 지점은 도처에 널려 있습니다.
---
## 실패 유형 1: 잘못된 검색 (Wrong Retrieval)
사용자가 질문합니다:
> 공급업체 결제 조건을 보여줘.
검색기 (Retriever)가 다음을 반환합니다:
```
text id="’wini9"
...
```
기술적으로는:
검색 (Retrieval)은 성공했습니다.
하지만 관련성 (Relevance)은 실패했습니다.
전통적인 모니터링 (Monitoring):
```
text id="’wini10"
...
```
성공한 것처럼 보입니다.
현실은:
시스템이 실패했습니다.
관측성 (Observability)이 여기서 도움이 됩니다.
당신은 다음을 검사합니다:
```
text id="’wini11"
...
```
이제:
근본 원인 (root cause)을 찾아냅니다.
아마도:
* 잘못된 임베딩 (bad embeddings)
* 부실한 청킹 (poor chunking)
* 취약한 메타데이터 필터링 (weak metadata filtering)
* 잘못된 벡터 검색 (wrong vector search)
---
## 실패 유형 2: 컨텍스트 오염 (Context Pollution)
또 다른 숨겨진 문제입니다.
많은 팀이 다음과 같이 가정합니다:
> 더 많은 컨텍스트 = 더 나은 답변
그래서 그들은 다음과 같이 보냅니다:
```
text id="’wini12"
...
```
문제점:
중요한 정보가 파묻힙니다.
이를 다음과 같이 부릅니다:
> 컨텍스트 희석 (Context dilution)
예시:
사용자가 질문합니다:
> 송장 세금 금액이 얼마인가요?
LLM이 수신하는 내용:
```
text id="’wini13"
...
```
이제:
모델이 혼란에 빠집니다.
환각 (Hallucinations)이 증가합니다.
답변 품질이 저하됩니다.
하지만 인프라는요?
여전히 건강합니다.
다시 말하지만:
전통적인 모니터링은 이를 놓칩니다.
---
## 실패 유형 3: 조용한 환각 (Silent Hallucination)
이것은 위험합니다.
시스템은 자신감 있게 들립니다.
하지만 틀렸습니다.
예시:
AI가 말합니다:
> 공급업체 결제가 3월 10일에 승인되었습니다.
현실:
승인된 내역이 존재하지 않습니다.
왜 위험할까요?
이유는 다음과 같습니다:
LLM은 우아하게 실패합니다 (fail gracefully).
그들은 다음과 같이 말하지 않습니다:
```
text id="’wini14"
...
```
그들은 다음과 같은 것을 생성합니다:
> 믿을 법한 실수 (believable mistakes)
이것이 더 나쁩니다.
모니터링은 다음과 같이 봅니다:
```
text id="’wini15"
...
```
관측성 (Observability)은 다음과 같이 질문합니다:
```
text id="’wini16"
...
```
완전히 다른 사고방식입니다.
---
## 에이전트형 AI (Agentic AI)는 훨씬 더 조용히 실패합니다
이제 상황은 더 어려워집니다.
상상해 보세요:
멀티 에이전트 워크플로우 (Multi-agent workflow):
```
text id="’wini17"
...
```
사용자가 질문합니다:
> 왜 송장 불일치가 발생했나요?
응답이 좋지 않습니다.
질문:
어떤 에이전트가 실패했습니까?
아마도:
```
text id="’wini18"
...
```
또는:
```
text id="’wini19"
...
```
또는:
```
text id="’wini20"
...
```
또는:
```
text id="’wini21"
...
```
관측성 (observability) 없이는:
당신은 눈을 감고 디버깅하는 것입니다.
그리고 눈을 감은 디버깅은 비용이 많이 듭니다.
---
## 진짜 문제:
AI 시스템은 살아있는 시스템처럼 행동합니다
이것이 사고방식의 전환입니다.
전통적인 시스템:
```
text id="’wini22"
...
```
AI 시스템:
```
text id="’wini23"
...
```
당신은 다음을 디버깅하는 것이 아닙:
> 충돌 (crashes)
당신은 다음을 디버깅하고 있는 것입니다:
> 의사 결정 (decision-making)
그리고 의사 결정 (decision-making)에는 가시성 (visibility)이 필요합니다.
단순한 모니터링 (monitoring)만으로는 부족합니다.
당신에게는 다음이 필요합니다:
```
text id="’wini24"
...
```
이것이 바로 관측성 (observability)이 시작되는 지점입니다.
그리고 이는 자연스럽게 다음 질문을 불러일으킵니다:
> 우리는 실제로 이 모든 것을 어떻게 추적 (trace)할 수 있을까요?
우리는 어떻게 확인할 수 있을까요:
```
text id="’wini25"
...
```

# 파트 3: OpenTelemetry 쉽게 이해하기, 트레이스 (Traces), 스팬 (Spans) 및 AI 워크플로 (Workflow) 시각화
이제 우리는 중요한 사실 하나를 이해했습니다:
모니터링 (Monitoring)은 우리에게 다음과 같이 알려줍니다:
> 무언가 잘못되었습니다.
관측성 (Observability)은 우리에게 다음과 같이 알려줍니다:
> 왜 잘못되었는지 알려줍니다.
하지만 이는 실질적인 질문을 던지게 합니다:
엔지니어들은 실제로 복잡한 AI 시스템을 어떻게 관측할까요?
특히 다음과 같은 시스템의 경우 말입니다:
```
text id="jlwm1"
...
```
현대의 AI 시스템은 더 이상 다음과 같지 않기 때문입니다:
> 단일 API 호출 (Single API calls).
그것들은 워크플로 (workflows)입니다.
그리고 워크플로는 가시성 (visibility) 없이는 디버깅하기 어렵습니다.
이것이 바로 다음과 같은 상황에서:
> OpenTelemetry (OTel)
이 유용해지는 지점입니다.
---
## OpenTelemetry란 무엇인가?
먼저 위협적으로 느껴지는 이름부터 걷어내 봅시다.
OpenTelemetry는 단순히 다음과 같습니다:
> 시스템 동작을 관측하기 위한 표준화된 방법.
이것을 다음과 같이 생각하세요:
> 분산 시스템 (distributed systems)을 위한 CCTV.
이는 다음과 같은 질문에 답하는 데 도움을 줍니다:
```
text id="jlwm2"
...
```
눈을 감고 무작정 디버깅하는 대신,
당신은 가시성 (visibility)을 얻게 됩니다.
간단한 정의:
> OpenTelemetry는 시스템 전반에 걸친 요청 (request)의 전체 여정을 추적하는 것을 돕습니다.
특히 당신의 아키텍처 (architecture)가 다음과 같을 때 매우 유용합니다:
```
text id="’wini3"
...
```
트레이싱 (tracing)이 없다면:
모든 것이 블랙박스 (black box)가 됩니다.
트레이싱 (tracing)이 있다면:
당신은 다음을 볼 수 있습니다:
> 단계별로 어떤 일이 일어났는지.
---
## 전통적인 로그 (Logs)만으로는 부족한 이유
많은 엔지니어가 이렇게 말합니다:
> 우리는 이미 로그 (logs)를 가지고 있습니다.
예시:
```
python id="jlwm4"
...
```
문제는 무엇일까요?
로그는 고립된 이벤트 (isolated events)를 알려줍니다.
시스템의 흐름 (system flow)을 알려주지 않습니다.
예를 들어:
사용자가 말합니다:
> 시스템이 느린 것 같아요.
당신은 로그를 확인합니다:
```
text id="’wini5"
...
```
여전히 불분명합니다.
질문:
> 정확히 무엇이 느려진 것인가?
그것이 다음과 같았나요:
```
text id="’wini6"
...
```
로그만으로는 여기서 한계가 있습니다.
당신에게는 다음이 필요합니다:
> 실행 가시성 (execution visibility).
이 지점에서 트레이싱 (tracing)이 강력한 힘을 발휘합니다.
---
## AI 워크플로우를 병원처럼 생각해보세요
상상해 보십시오:
환자가 병원에 들어옵니다.
여정:
```
text id="’wini7"
...
```
이제 상상해 보십시오:
환자가 말합니다:
AI 자동 생성 콘텐츠
본 콘텐츠는 Dev.to AI tag의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기