
AI에 전적으로 의지하여 가계부 앱을 추가 개발하기: OCR 구현 ②
요약
가계부 앱 개발 과정에서 발생하는 OCR 인식 오류를 해결하기 위한 이미지 전처리 및 엔진 최적화 방법을 다룹니다. Tesseract의 한계를 극복하기 위해 OpenCV를 이용한 영수증 영역 검출과 PaddleOCR 도입 등 실무적인 개선 방안을 제시합니다.
핵심 포인트
- 배경 노이즈 제거를 위한 영수증 영역 검출 필수
- Tesseract 사용 시 LstmOnly 모드와 SingleBlock 모드 활용
- 일본어 영수증 인식에는 PaddleOCR이 더 강력한 대안
- 정밀도 향상을 위한 초해상도(Super Resolution) 기법 고려
지난번에는 가계부 앱의 설계를 진행했습니다 (AI가 했습니다).
지난번에는 OCR 구현을 시도했지만 제대로 동작하지 않았습니다.
이번에도 OCR 구현을 진행하겠습니다.
필요한 내용을 가져오지 못하고 기능하지 않음
개선책은?
취득된 문자열은 다음과 같습니다.
"は ち ( 日 )①⑤:③0\nッ No:0⑥③\n\nX ク イ ッ ク + ④0 錠 \\①。 958内\nL\n\nG。 Q ロ Q\n\nメ デ ィ ケ ー シ ョ ン プ ォ か を\n\nち 買 上 ( 税 抜 ) 加 算 額\n\nプホイン ト カ ー ド と\n\n \n"
원인은 상당히 명확합니다.
현재 OCR 결과를 보면 주로 다음과 같은 문제가 발생하고 있습니다.
| 문제 | 내용 |
|---|---|
| 이미지 전처리 부족 | 영수증 이외의 검은 배경을 대량으로 읽고 있음 |
| ... |
이것입니다.
「영수증만」 OCR 하고 있지 않음
현재 이미지는:
검은 배경 + 작은 영수증
입니다.
Tesseract는 배경 노이즈에 상당히 약하기 때문에,
먼저 「영수증 영역 검출」이 필요합니다.
원본 이미지
↓
영수증 윤곽 검출
...
이렇게 하면 정밀도가 대폭 개선됩니다.
다음으로 교체해 주세요.
private string PreprocessImage(string imagePath)
{
Mat src = Cv2.ImRead(imagePath);
...
이것이 중요합니다.
private string ExecuteTesseract(string imagePath)
{
using var engine = new TesseractEngine(
...
"jpn+eng"
영수증은:
No
mL
PMD
...
등 영문자와 숫자가 혼재되어 있습니다.
jpn
단독으로는 붕괴됩니다.
EngineMode.LstmOnly
이전 OCR 엔진보다 정밀도가 상당히 높습니다.
현재 이미지는:
세로가 긴 단일 영수증
이므로:
PageSegMode.SingleBlock
이 최적입니다.
정밀도를 더욱 높이는 경우.
private Mat DetectReceipt(Mat src)
{
Mat gray = new Mat();
...
이것을 가장 먼저 실행.
현재:
は ち ( 日 )①⑤:③0
개선 후:
2026年05月10日(日)15:30
정도까지는 개선이 가능합니다.
실운용에서는 다음을 추가합니다.
| 수법 | 효과 |
|---|---|
| 초해상도 (Super Resolution) | 작은 글자 개선 |
| ... |
Tesseract는 일본어 영수증 OCR에 약합니다.
실용 수준이라면:
쪽이 정밀도가 높습니다.
특히:
일본어
숫자
영수증
은 PaddleOCR이 상당히 강력합니다.
실운용이라면:
OpenCV
↓
PaddleOCR
...
이 상당히 강력합니다.
Tesseract 단독은,
「최소한으로 동작하는」 수준이라고 생각하는 것이 좋습니다.
실행해 보겠습니다.
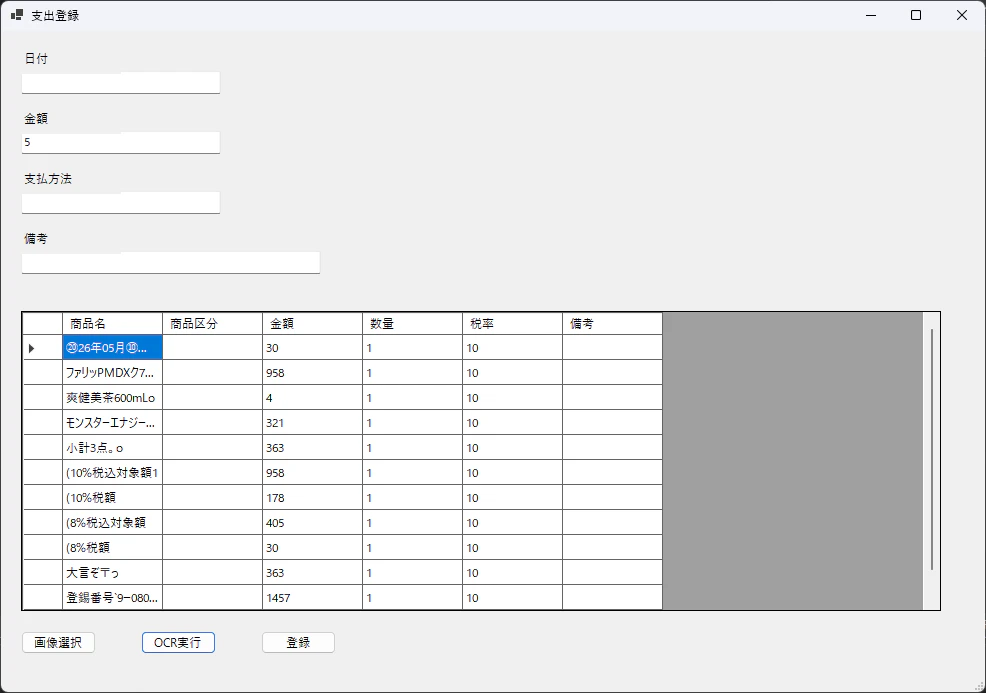
어떻게든 읽어 들였지만 여러 가지 문제가 있네요.
다음 회차에도 OCR 개선을 실시하겠습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기