AI에게 '사양대로'의 결과물을 만들게 하기 ── L2A-SCP를 V자 모델로 읽기
요약
L2A-SCP는 AI 에이전트가 생성하는 코드의 불확실성을 극복하고, 인간이 작성한 사양(SPEC)에 충실한 결과물을 도출하기 위한 프레임워크입니다. 확률적 변환기인 LLM의 특성을 고려하여 품질 최대화가 아닌 '품질 편향 방지'를 목표로 설계되었습니다.
핵심 포인트
- SPEC을 소스 코드처럼 취급하여 단계적으로 결과물을 생성하는 프로세스 제공
- LLM의 확률적 특성으로 인한 구현 편향(Biased Accumulation) 문제 해결 지향
- 품질 보증의 목표를 '품질 최대화'가 아닌 '품질 편향 방지'로 정식화
- 개인 개발자와 Claude Code의 로컬 동기화 환경에 최적화된 범용 프레임워크
에이전트에게 구현을 맡기면, diff가 발생하는 속도는 올라간다. 하지만 나오는 것은 '작동할 것 같은 코드'일 뿐, 사양대로의 소프트웨어라고는 단정할 수 없다.
**Layer2-Architect SPEC Compiling Pipeline (L2A-SCP)**가 노리는 최대의 유스케이스(Use Case)는 이 차이를 메우는 것이다. 인간이 SPEC을 작성한다. L2A-SCP는 그 SPEC이 결과물로 변환 가능한지를 판정하고, 가능하다면 UC(Use Case)·설계·테스트·구현·배포 계약으로 단계적으로 전개하여, SPEC에 충실한 결과물로 컴파일(Compile)한다. 이는 'AI에게 적당히 구현하게 하는' 이야기가 아니다. SPEC을 소스 코드처럼 취급하여, 그로부터 결과물을 단계적으로 생성하기 위한 개발 프로세스다.
다만, 여기서 일반적인 컴파일러와는 결정적으로 다른 문제가 발생한다. GCC나 Clang은 결정론적 변환기(Deterministic Converter)로, 동일한 입력으로부터 항상 동일한 출력이 나온다. 반면 LLM은 확률 분포 P(y|x)로부터 샘플링(Sampling)을 반환한다. 구현에서 사용하는 것은 그곳에서 뽑은 1개의 샘플일 뿐이며, 그것이 분포의 왼쪽 꼬리(나쁜 영역)에서 나올 수도 있고, 훈련 분포의 편향(Bias)으로 인해 여러 샘플이 한 방향으로 **편향 축적(Biased Accumulation)**될 수도 있다.
따라서 L2A-SCP가 해결하려는 문제는 'AI로부터 최고 품질의 출력을 끌어내는 것'이 아니다. 보다 근본적으로는, 확률적 변환기(Stochastic Converter)를 매개하더라도 SPEC에서 결과물로의 번역 충실성을 무너뜨리지 않는 것에 있다. 이를 위해 L2A-SCP는 품질 보증을 '품질 최대화'가 아닌 '품질 편향 방지'로 정식화한다.
출처: Layer2-Architect/SPEC-compiling-pipeline (Apache-2.0, 일본어판 ja/가 source of truth).
학술적으로 인용할 경우에는 Zenodo DOI 10.5281/zenodo.20773187를 사용한다 (버전 지정으로 인용할 경우에는 repo의 배지에서 해당 버전의 DOI를 참조).
이 기사의 사정거리 — 미리 선언해 둔다
이전 버전에 대한 가장 큰 지적은 "누구를 위한, 어디까지의 이야기인지 종반까지 알 수 없다"는 것이었다. 그래서 미리 범위를 정해둔다.
L2A-SCP는 소프트웨어 중심의 범용 프레임워크다. 특정 언어·특정 도메인에 의존하지 않는 기술로 작성되어 있으며, 구체적인 적용 사례는 익명화된 참조 프로젝트 APP (appendix/)에 정리되어 있다. 실기기·하드웨어 의존부나, ISO 26262 / IEC 61508과 같이 규격이 추적 가능성(Traceability) 결과물을 요구하는 세계로 그대로 가져가는 이야기가 아니다. 사정거리 밖의 부분은 별도의 사상(Mapping)이 필요하다.
-
**주요 시나리오는 '개발자 1명 + Claude Code의 로컬 동기화 환경'**이다 (
08-gates.md). 팀 개발이나, AI 이용이 내부 도구로 제한되는 현장으로 가져올 때는 게이트(Gate)의 담당자나 승인 플로우의 재해석이 필요하다. '개인 개발자에게 최적화되어 있다'는 것을 알고 읽으면 기대치가 맞을 것이다. -
V자 모델로서의 읽기 방식은 이 기사가 추가하는 관점이다. 사양서 본체에는 'V자', '폭포수(Waterfall)'라는 용어는 나오지 않는다. L2A-SCP의 구조를 기지의 발판 위에 올려 이해하기 쉽게 만들기 위한 보조선일 뿐이며, 사양의 정의가 아니다. 이 점은 솔직하게 구분해 둔다.
역으로 말하면, 위의 범위 안에서라면 L2A-SCP가 해결하고 있는 문제(확률적 변환기를 매개한 충실한 번역)는 보편적이다. 임베디드든 Web이든, AI에게 하류 생성을 맡기는 한 동일한 문제가 발생한다.
최대의 유스케이스 — SPEC을 결과물로 '컴파일'하기
L2A-SCP가 보증하려는 것은 '올바른 제품 아이디어를 선택하는 것'이 아니다. SPEC을 소스로 받아, 그것이 컴파일 가능한 수준으로 명확한지를 판정하고, 가능하다면 UC·설계·테스트·구현·배포 계약으로 단계적으로 전개하는 것이다.
GCC는 논리적으로 틀린 프로그램이라도 구문(Syntax)만 통과하면 충실하게 바이너리화한다. 컴파일러가 보증하는 것은 소스에 대한 번역의 충실성이지, 그 소스가 올바른 일을 하는가가 아니다. L2A-SCP도 같은 입장을 취한다. 만들어야 할 것이 올바른가(비즈니스적 타당성)는 인간의 책임으로 남기고, L2A-SCP는 'SPEC을 소스로 하여, 확률적 변환기에서도 충실하게 결과물로 번역해내는 것'에 책임을 진다.
다만 '올바름을 묻지 않는다'는 '무엇이든 받아들인다'는 뜻은 아니다.
| 묻는다 / 묻지 않는다 | 내용 | 담당 |
|---|---|---|
| 묻지 않는다 | SPEC이 기술하는 설계·요구가 올바른가 (만들어야 할 올바른 것인가) | 인간 |
| 묻는다 | SPEC이 컴파일(Compile) 가능한 정도로 명확·완비되어 있는가 (모호함·모순·결락이 없는가) | L2A-SCP (전단 루프 03a) |
모호하거나 불완비하여 번역 불가능한 SPEC은 QSET → SPP → FCR 과정을 통해 인간에게 되돌려 보내며, ACCEPTED에 도달하고 나서야 비로소 컴파일을 시작한다. garbage in의 책임은 작성자에게 있지만, "garbage인지 판별할 수 없을 정도로 모호한 입력"은 문전박대한다 —— 이 점이 일반적인 컴파일러보다 한 발짝 더 나아가 있는 부분이다.
이 글을 읽는 법 — 우선 V자 모델로 골격을 파악하기
L2A-SCP는 약어가 많다. QSET / SPP / FCR / TP / GAP / RBA / SEQA / RBD / SEQD / DD / TS / TC / SRC / AT / NFR / PAI / CTR / DLV.
이전 버전에서는 "분류표를 먼저 배치"하는 방식을 취했으나, 그럼에도 첫 독해는 무거웠다.
그래서 이번 개정판에서는, V자 모델을 약어의 수납 선반으로서 먼저 사용한다. L2A-SCP의 성과물은 결국 "왼쪽 = SPEC으로부터의 분해"와 "오른쪽 = 각 레벨에 대응하는 검증" 중 어느 한쪽으로 귀결된다. 따라서 약어도 "이것은 V의 왼쪽인가 오른쪽인가, 어느 레벨인가"로 기억하면, 개별 정의를 암기하지 않아도 본문을 따라갈 수 있다.
골격은 이것뿐이다. 왼쪽에서 분해하고, 바닥에서 구현하며, 오른쪽에서 각 레벨에 대응하는 검증을 쌓아 올려, 계약 적합성(Contract Compliance)이 확인되면 릴리스한다. 약어를 "어떤 계열인가"로 분류하면 다음과 같다.
| V자에서의 위치 | 분류 | 대표적인 약어 |
|---|---|---|
| 입구 (왼쪽 앞부분) | 입력 정규화 | QSET / SPP / FCR |
| ... | ||
| (개별 정의는 각 장에서 등장한다. 여기서는 "V의 어디에 위치하는가"만 파악하면 충분하다.) |
L2A-SCP를 V자 모델로 읽기
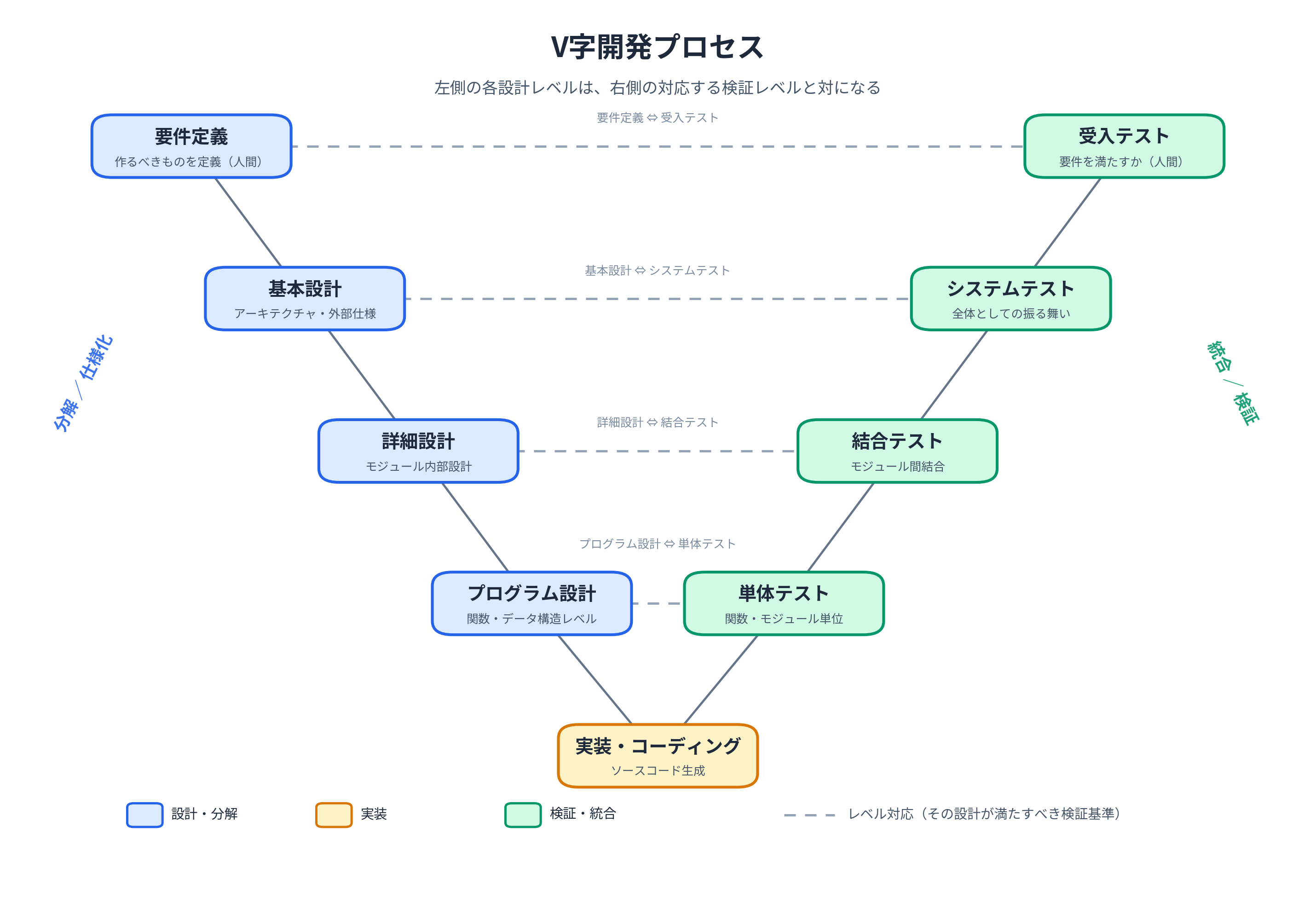
이 부분이 이번 개정판의 주안점이다. L2A-SCP의 파이프라인은 위에서 아래로 내려가는 일직선처럼 보이지만, 사실은 왼쪽의 각 추상 레벨이 오른쪽의 대응하는 검증과 쌍을 이루는 V자 구조로 되어 있다. 먼저 일반적인 V자를 확인하고, 그다음 L2A-SCP를 겹쳐본다.
일반적인 V자 개발
V자의 본질은 위 그림의 수평 점선에 있다. 요구사항 정의는 인수 테스트(Acceptance Test)와, 기본 설계는 시스템 테스트(System Test)와, 상세 설계는 통합 테스트(Integration Test)와, 프로그램 설계는 단위 테스트(Unit Test)와 쌍을 이룬다. 각 설계 레벨은 "자신이 충족해야 할 검증 기준"을 오른쪽에 가진다는 대응 관계야말로 V자의 내용이다.
L2A-SCP를 V자로 사상(Mapping)하기
L2A-SCP의 성과물을 동일한 구조에 얹으면 다음과 같다.
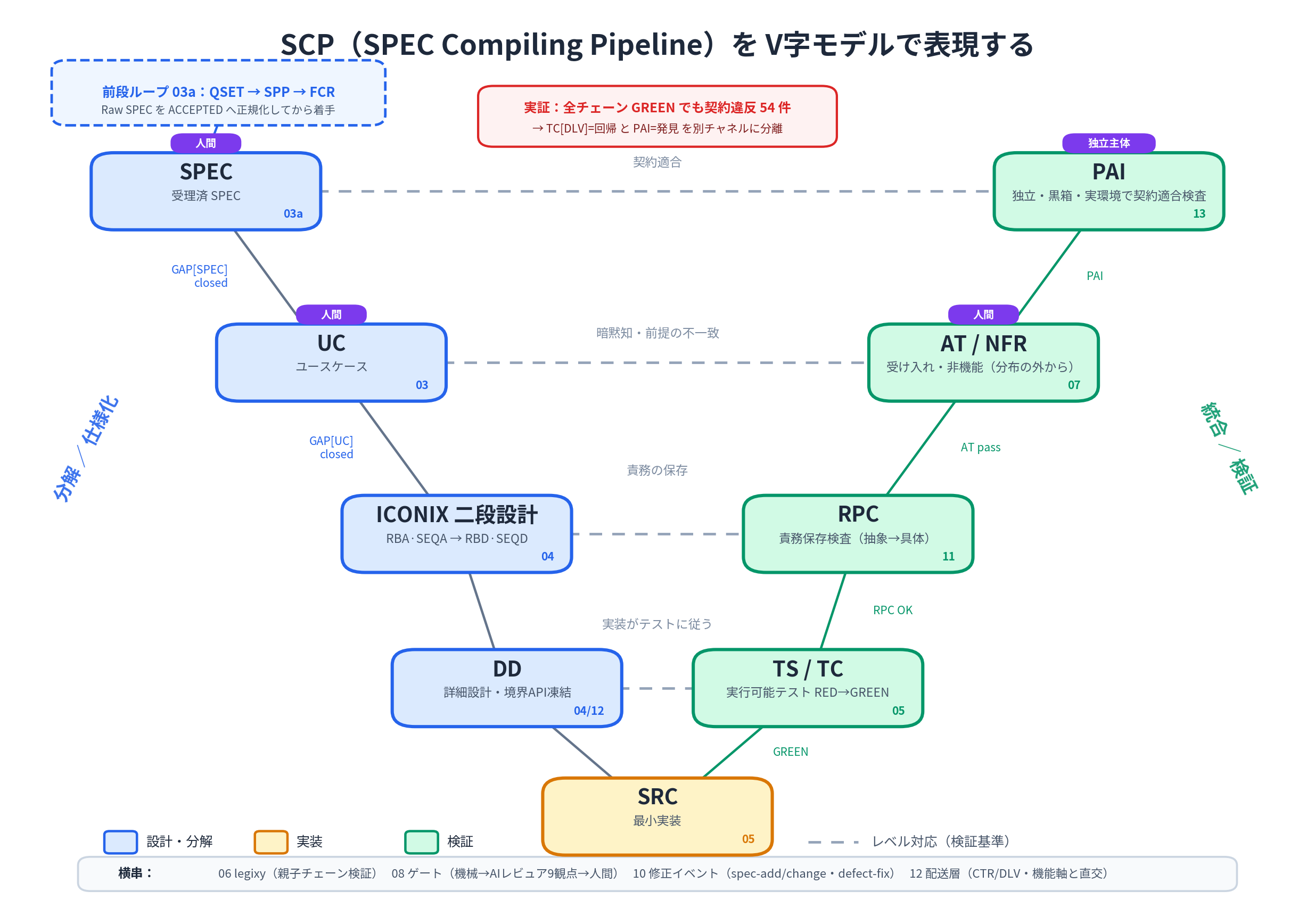
대응 쌍은 4개다. 모두 "해당 설계 레벨이 충족해야 할 검증"을 오른쪽에 배치하고 있다.
| 왼쪽 (분해) | ⇔ | 오른쪽 (검증) | 무엇을 지키는가 |
|---|---|---|---|
| SPEC (수리됨) | ⇔ | PAI (완성품 적합 검사) | 계약 적합성. 독립된 주체가 실환경·블랙박스(Black-box)로 검사 |
| UC (유스케이스) | ⇔ | AT / NFR (인수·비기능) | 암묵지·도메인 전제의 불일치를 분포 밖에서 포착 |
| ICONIX 2단 설계 (RBA·SEQA → RBD·SEQD) | ⇔ | RPC (책임 보존 검사) | 추상 → 구체로의 번역에서 책임이 누락되지 않았는가 |
| DD (상세 설계·경계 API 동결) | ⇔ | TS / TC (실행 가능 테스트) | 구현이 테스트를 따른다 (RED → GREEN) |
그리고 V자의 외곽에 L2A-SCP 고유의 발판이 붙는다.
- **전단 루프 03a (QSET → SPP → FCR)**는 V자가 시작되기 전 단계에 있다. Raw SPEC을
ACCEPTED로 정규화한 뒤 왼쪽 암(Arm)의 하강을 시작한다 (입력 분포를 좁힘). - 왼쪽 암의 하강에는 **진행 게이트(Progress Gate)**가 있다.
GAP[SPEC]이 클로즈(Close)될 때까지 UC 착수 금지,GAP[UC]가 클로즈될 때까지 RBA 착수 금지. - 오른쪽 암의 검증은 GREEN → RPC OK → AT → PAI 순으로, 검증 스코프가 넓어지는 방향으로 쌓아 올린다.
솔직한 단서 (사상의 한계)
그림을 깔끔하게 보여주기 위해 거짓말을 하지 않겠다. V자는 이해를 위한 보조선이지
V자(폭포수 모델 계열)는 각 레벨을 순차적으로 고착화해 나가는 엄격함을 대가로, 재작업 비용(rework cost)이 높다는 것이 약점으로 지적되어 왔다. "하류(downstream)까지 진행한 후에 상류(upstream)의 결함을 발견하면, 다시 만드는 비용이 너무 많이 든다" —— 그렇기에 현장은 애자일(Agile) 방식의 반복(iteration)으로 선회했다.
L2A-SCP의 입장은 이 지점을 반전시킨다. 하류 생성의 한계 비용을 AI가 없앤다면, V자 모델의 재작업 비용 문제는 전제가 무너진다. L2A-SCP의 수정 이벤트 흐름(10장)은 결함이 발견된 지점으로부터 하류를 **선택적으로 재생성(incremental reconstruction, 점진적 재구축)**한다. 즉, V자의 각 레벨 대응을 유지하면서도 루프 경계에서 애자일하게 회전시킬 수 있다. "재실행 가능한 V자"인 것이다.
이 부분은 사양서의 주장 그 자체라기보다, L2A-SCP의 구조로부터 도출할 수 있는 해석으로서 보충하고 있다. 실제로 10장의 이벤트 흐름은 "Phase E1~E5에서 순차적으로 운용 검증 중"이라고 명시되어 있으며, 사고 실험 단계를 포함하고 있다. 과신은 금물이다.
상세 흐름 (결과물이 어떤 순서로 생성되는가)
위의 V자는 구조를 나타낸 그림이다. 실제로 어떤 순서로 결과물이 생성되고, 어디서 게이트(gate)에 멈추는지를 한 장으로 정리하면 다음과 같다. 마름모는 진행을 멈추는 게이트, 점선은 횡단(cross-cutting) 메커니즘을 나타낸다.
범례: 위에서 아래로 가는 것이 정상 흐름. FCR
・GAP
・RPC
・GREEN
・PAI
의 각 마름모는 통과하지 못하면 앞으로 나아갈 수 없는 게이트이다. 08 게이트와 06 legixy는 전 공정에 영향을 미치는 횡단 메커니즘이므로 점선으로 표시했다. PAI에서 계약 위반이 발견되면 10 수정 이벤트를 경유하여 상류로 돌아가, 필요한 범위만 재생성한다.
SPEC 컴파일을 성립시키는 4가지 조건
V자의 좌우와 전단(pre-stage)·횡단을 설계 제약으로서 한 장으로 접으면 4가지 조건이 된다.
| 조건 | 무엇을 지키는가 | 주로 적용되는 장 | V자에서의 위치 |
|---|---|---|---|
| 입력을 컴파일 가능하게 함 | 모호한 SPEC을 하류로 흘려보내지 않음 | 03a 전단 루프 | V의 입구 |
| ... |
전 장을 횡단으로 지탱하는 것이 추적 가능성(traceability, 06 legixy) · 게이트(08) · 수정 이벤트(10) · 배포(12) 의 4가지 메커니즘이다.
왜 이렇게까지 무겁게 만드는가 —— 그 동기는 한 가지 사실이 보여준다. L2A-SCP에서는 전체 체인이 GREEN(테스트 총 통과)임에도 불구하고, 독립 검사에서 계약 위반이 54건 발견된 사례가 있다 (출처는 13장에서 후술). 기능 테스트의 GREEN은 계약 적합성을 의미하지 않는다. 그렇기에 TC[DLV](회귀)와 PAI(발견)를 역할이 다른 별개의 것으로 분리한다.
이하, 장 순서대로 살펴본다. 각 장은 "SPEC 컴파일의 어느 부분을 담당하는가 / 확률적 변환기(probabilistic transformer)에서 왜 필요한가 / repo에서는 어떻게 구현되는가"라는 세 가지 관점으로 읽는다.
00-philosophy — 왜 '최대화'를 그만두는가
담당 부분: L2A-SCP 전체의 제1원리. SPEC을 결과물로 충실히 컴파일하기 위해서는, 확률론적 변환기의 출력을 '최대화'하는 것이 아니라, 품질 편향(quality bias)을 방지하는 구조가 필요하다고 선언한다.
필요한 이유: 결정론적 컴파일러(deterministic compiler)라면 출력은 유일하므로 최대화만으로 충분했다. LLM은 분포(distribution)에서 추출하므로, 논점은 '평균적으로 좋은가'가 아니라 '나쁜 꼬리(bad tail)를 밟지 않는가 / 편향이 쌓이지 않는가'로 바뀐다.
repo에서는: 하위 원리로서 신뢰 경계의 상류 이동 · 관찰 가능화 · 다중 독립 검증 경로 · 분포 외(out-of-distribution)로부터의 관찰 · 편향 패턴의 사후 축적 · 인간 개입의 집중,의 6가지를 정의한다. 후속 장들은 반드시 이 중 하나에 대응된다.
01-overview / 02-typecodes — 어휘와 ID를 먼저 고정한다
담당 부분: 01이 4층 구조와 '관찰 가능화'의 전체상을, 02가 결과물의 타입 코드(typecode)와 ID 규칙을 담당한다.
필요한 이유: 편향을 탐지하려면 우선 무엇이 결과물이며, 누가 누구의 부모인가가 기계 판독 가능(machine-readable)해야 한다. 어휘가 모호하면 AI가 생성한 것을 추적하거나 검증할 수 없다.
repo에서는: 모든 결과물에 타입 코드와 부모 참조를 부여한다. 새로운 결과물 타입을 만들 때는 먼저 .legixy.toml을 업데이트해야 한다 (하드 룰 4). 이어서 docs/traceability/graph.toml에 [[nodes]]로 등록한다. 체인에 없는 타입을 마음대로 만들지 않는다. 보정 메모: 이전 버전은 설정 파일을 .trace-engine.toml이라고 기재했으나, 현행 리포지토리에서는 엔진이 legixy
로 재명명·재구축되었으며, 설정은 노드 등록이 .legixy.toml로 이행되었다. 하드 룰(Hard Rule) 4도 「docs/traceability/graph.toml보다 .legixy.toml 업데이트가 우선」으로 업데이트 완료됨.
포인트는, SPEC에 대한 TP/GAP이 UC보다 우선한다는 것이다. GAP[SPEC]이 open 상태인 동안에는 UC 착수 금지, GAP[UC]가 open 상태인 동안에는 RBA 착수 금지라는 순서가 하드 룰로 정해져 있다.
03a-frontend-pass — 입력 분포를 좁히는 「전단 루프」
역할: Raw SPEC을 직접 하류로 흘려보내지 않고, QSET → SPP → FCR 루프로 정규화하여, frontend_status = ACCEPTED에 도달하게 한 뒤에야 비로소 TP/UC 착수를 허용한다.
필요성: 조건 ① 그 자체. 입력 x의 품질을 높이면 분포 P(y|x)가 좁아진다. Raw SPEC을 그대로 흘려보내면, SPEC의 불완전함을 하류에서 임의로 메우게 되며, 그 메움이 편향(Bias)의 온상이 된다.
repo에서는: scripts/trace-check.sh가 「ACCEPTED에 도달하지 않았는데 TP를 착수하지 않았는가」를 기계적으로 검증한다 (하드 룰 9). 스킵할 경우 ADR(Architecture Decision Record)에 이유를 남겨야 한다.
03-spec-level-tdd — 출력의 편향을 「시각화」하기
역할: SPEC ⇄ TP ⇄ GAP 및 UC ⇄ TP ⇄ GAP 루프. TP(테스트 관점. 테스트 케이스가 아님)를 사양에 부딪혀, 결락을 GAP으로 기록한다.
필요성: 조건 ②. 테스트는 「있으면 좋은 장식」이 아니라, 생성물이 계약을 위반하지 않았음을 기계적으로 보여주는 계약이다. 관점을 부딪힘으로써, 보이지 않았던 출력의 편향이 GAP으로서 가시화된다.
repo에서는: GAP이 클로즈(Close)되지 않는 한 다음 페이즈로 진행할 수 없다 (하드 룰 2). 이 또한 trace-check.sh가 결정론적(Deterministic)으로 차단한다.
04-iconix-layer — 경로를 다중화하는 「ICONIX 이단화」
역할: 설계를 추상층과 구체층으로 나눈다. 추상 RBA/SEQA (도메인 어휘만) → 구체 RBD/SEQD (클래스 다이어그램 레벨·언어 독립적) → DD (언어 구조로 mapping).
필요성: 조건 ③. 동일한 설계를 어휘가 다른 두 단계로 작성하게 함으로써, 한쪽의 맹점을 다른 쪽이 구조적으로 보완하게 한다. 나아가 삼자 정합성 (UC ⇄ RBA ⇄ SEQA, UC ⇄ RBA ⇄ SPEC) 모두를 요구하여 독립적인 경로를 늘린다.
repo에서는: 레이어 오염 금지 (하드 룰 10). 함수명·구체 타입·Result<T,E>나 tokio::와 같은 언어 고유 요소는 DD에서만 작성할 수 있다. trace-check.sh의 [5/5]가 이를 grep 기반으로 검출한다.
05-test-and-impl — RED에서 GREEN으로, 구현이 뒤따라감
역할: TS (TP의 관점을 실행 가능한 테스트 사양으로 번역) → TC[RED] (실패하는 테스트) → SRC (최소 구현) → TC[GREEN]의 TDD 본체.
필요성: AI는 「테스트를 작성」할 수는 있어도 「테스트를 실행했다」는 상태가 되지는 않는다. 먼저 테스트를 Red로 고정하고 구현이 그에 맞추도록 함으로써, 생성물의 자유도를 계약 측면에서 구속한다.
repo에서는: 사양서와 테스트 코드는 구현 착수 후에 변경하지 않는다. 구현이 테스트에 맞춘다 (하드 룰 6). 테스트를 통과하지 못하는 구현은 머지(Merge)하지 않는다 (하드 룰 8). 수정이 필요한 경우 /defect-fix나 /spec-change와 같은 정식 이벤트(10장)를 경유해야 한다.
06-trace-engine — legixy가 「왜」를 유지함
역할: 트레이서빌리티(Traceability) 엔진 legixy (v0.4.0-alpha4 이후)의 운용. 모든 성과물의 부모-자식 체인을 legixy check --formal로 검증한다.
왜 필요한가: 판단의 대부분은 채팅에서 일어나지만, 채팅은 이력이 아니다. git은 what/when은 남기지만 why는 남기지 않는다. 추적 가능성(Traceability)은 편향 방지의 토대이며, 이것이 없으면 "어떤 생성물이 어떤 사양에서 유래했는가"가 사라진다.
repo에서는: 체인 내 성과물은 legixy (.legixy.toml + graph.toml)로, 체인 외부는 본문 metadata + trace-check.sh로 검증한다. 설계 판단은 ADR에 남긴다. .git/hooks/pre-commit에서 기계 검증을 결정론적(deterministic)으로 강제한다.
07-at-and-nfr — 분포의 바깥쪽에서 바라보기
담당 영역: AT(수락 테스트, Acceptance Test)와 NFR(비기능 요구사항, Non-Functional Requirements). AT는 사양 수준의 TDD(테스트 주도 개발)로는 원리적으로 탐지할 수 없는 영역——암묵지·도메인 관행·전제의 불일치——전용 독립 채널이다.
왜 필요한가: 조건 ④. AT는 종단 공정이 아니라, 확률 분포의 바깥쪽에서의 관찰이다. 사양 내부에서만 돌리고 있으면 포착할 수 없는 어긋남을 인간의 관찰이 최종 방어선으로서 잡아낸다.
repo에서는: AT를 하류의 단순한 마무리 작업으로 격하시키지 않는다(하드 룰 5). NFR은 성능·병행성·리소스·보안을 별도로 관리한다. 인간의 한정된 인지 자원은 이 관찰 기준과 입력 품질에 집중시킨다.
08-gates — 기계·AI·인간의 3층 게이트 (9개 관점 포함)
담당 영역: 페이즈 진행 게이트를 기계 검증 → AI 리뷰어 층 (9개 관점 + severity + VERDICT) → 인간 판단의 3층 구조로 확장한다.
왜 필요한가: 기존의 "기계 + 인간" 2층 구조에서는 인간이 개별 PR(Pull Request)을 계속해서 판정하느라 소모된다. 중간에 AI 리뷰어 층을 끼워 넣으면, 인간은 AI가 실수하는 패턴을 포착하여 가이드라인을 수정하는 human-on-the-loop로 전환될 수 있다.
repo에서는: AI 리뷰어는 1개 세션에서 다음의 9개 관점을 순차적으로 체크하며(병렬 sub-agent가 아니다. 이전 관점의 findings를 유지한 채 다음으로 진행하기 위함), 마지막에 <!-- VERDICT:APPROVE --> 또는 <!-- VERDICT:REQUEST_CHANGES -->를 출력한다.
| # | 태그 | 관점 | 주요 대상 |
|---|---|---|---|
| 1 | [Trace] | traceability 정합성 | Document ID · graph.toml · 부모 ID 인용 |
| 2 | [Frontend] | 전단 루프 완료 상태 | FCR.frontend_status · 스킵 ADR |
| 3 | [Spec-TDD] | 사양 수준 TDD 게이트 | red TP / open GAP의 잔존 |
| 4 | [Layer] | 레이어 오염 검사 | 추상 측/구체 측/DD의 어휘 혼입 |
| 5 | [Consistency] | 삼자 정합성 | UC ⇄ RBA ⇄ SEQA / UC ⇄ RBA ⇄ SPEC, RPC 통합 |
| 6 | [Coverage] | TP / 관점 지식 망라성 | 범용 관점 + 영역 특화 관점의 커버 |
| 7 | [Doc] | 문서 정합성 | 코드 변경에 대한 SPEC/DD/perspectives 추종 |
| 8 | [AI-Antipattern] | AI 특유의 함정 | 임시방편(filling in) · 추측 진행 · scope creep |
| 9 | [Recurrence] | 재발 방지 판단 | AT 실패의 승격 · 신규 관점 추가 · ADR화 |
기동 순서는 "토대 → 상류 게이트 → 구조 → 정합 → 망라 → 문서 → 함정 → 재발 방지"([Trace]→[Frontend]→[Spec-TDD]→[Layer]→[Consistency]→[Coverage]→[Doc]→[AI-Antipattern]→[Recurrence])이다. 전단의 findings를 후단이 참조할 수 있는 설계다.
중요한 것은 APPROVE 권한이 게이트(Gate)마다 다르다는 점이다. 상류(SPEC/UC/ADR/NFR)와 AT 통과(릴리스), ICONIX 추상 계층은 REQUEST_CHANGES만 가능하며 Approve는 반드시 인간이 수행해야 한다. 구체 계층(RBD/SEQD/DD)과 코드 레벨(TS/TC/SRC)은 AI Approve가 가능하지만(단, 경계 API 동결은 인간 필수), SPEC 변경·릴리스 판단·품질 기준 완화는 항상 AI Approve가 불가능하도록—인간 필수 메타 레벨 안전장치(Safety Valve)로 남겨둔다.
또한
[Consistency]
관점은 04장의 Adversary 역할(삼자 정합성 검증)을 모든 게이트로 일반화한 것이며, 11장의 RPC(책임 보존 검사, Responsibility Preservation Check)도 이 관점에 통합되어 있다. 관점이 너무 많아지는 것을 방지하기 위해, 새로운 패턴은 기존 9개 관점 중 하나로 분류한 뒤에 추가하도록 하는 규율을 따르고 있다.
09-compiler-lens — 프로세스를 다른 어휘로 읽어내는 렌즈
역할: 프로세스를 규정하는 것이 아니라 다른 어휘로 기술하는 렌즈 사양서. 전단 루프를 프론트엔드 패스(Frontend Pass)로 간주하고, L2A-SCP의 단계를 전통적인 컴파일러의 IR 계층에, 일상 운용을 인크리멘털 컴파일러(Incremental Compiler, Salsa / Roslyn 계열)에 대응시킨다.
필요성: 구현 절차는 전혀 바꾸지 않는다. 설계 판단의 참조 영역을 전환하는 관점을 추가할 뿐이다. 이 글의 'V자 렌즈'도 같은 성격의 보조선이며, 09장의 컴파일러 렌즈와 상보적으로 사용할 수 있다.
repo에서는: '멱등성(Idempotency)'을 전체 재생성의 멱등성과 그래프 조작의 멱등성으로 분리하여 재정의하는 등, 운용 어휘를 정리하는 보조 문서로 사용한다.
10-modification-events — 변경을 4가지 이벤트로 분류
역할: 기존 체인에 대한 변경을 **신규 생성 / 사양 추가(/spec-add) / 사양 변경(/spec-change) / 결함 수정(/defect-fix)**의 4가지 이벤트로 분류하여 공통 핵심 플로우로 다룬다.
필요성: '1변경·1이유'를 제도화한 것이다. 주변 맥락을 읽은 AI가 덤으로 format·rename·리팩토링을 섞어버리는 **스코프 폭발(Scope Explosion)**을 이벤트 타입으로 봉쇄한다. 이것이 '재실행 가능한 V자'를 성립시키는 재생성의 단위이기도 하다.
repo에서는: 공통 핵심은 trace --upstream → impact → 成果物参照 → 修正候補生成 (trace --upstream → impact → 산출물 참조 → 수정 후보 생성)이다. 수정 지점으로부터 하류를 **선택적으로 재생성(인크리멘털 재구축)**한다. 3사이클을 넘어도 수렴하지 않으면 설계 레벨의 재검토를 촉구하는 경고가 발생한다. 이벤트 플로우 자체는 사고 실험 단계의 사양이며, Phase E1~E5에서 순차적으로 운용 검증 중이라고 명시되어 있는 점도 정직하다.
11-responsibility-preservation-check — 번역의 불변 조건을 강제하는 RPC
역할: 추상 책임(RBA/SEQA) → 구체 책임(RBD/SEQD)의 보존율 검사. 이단계화 과정에서 발생할 수 있는 '번역 누락'을 검사 항목으로 고정한다.
필요성: 조건 ③의 보강. 다중 경로를 만들더라도 계층을 넘나드는 번역에서 책임이 누락되면 독립성이 무너진다. RPC는 lost / mutated / shifted / 미정당화된 invented를 탐지하여, 구조 번역의 불변 조건을 강제한다.
repo에서는: RPC-template.md에 따라 보존성을 기록 및 검사하며, AI 리뷰어의 [Consistency] 관점(추상→구체 경계)에 통합되어 있다. v1.0에서 추가된 비교적 최신 검사이다.
12-delivery-layer — 기능 축과 직교하는 '배송 축'
역할: 계약 서피스(Contract Surface, CLI/API/MCP)를 체인에 정착시키는 배송 계층. CTR(경계 계약·뿌리) / DLV(배송 설계) / multi-area / 계약 적합 게이트.
필요성: 권한·데이터·네트워크의 경계를 암묵적으로 두지 않도록 구조화한 것이다. 경계가 모호할수록 AI는 영역을 침범한다. V자의 기능 축과는 직교하는 '또 하나의 축'이다.
repo에서는: 경계 API의 계약은 DD 단계에서 동결하며, 동결 후의 변경은 다음 버전의 SPEC 개정으로 취급한다(하드 룰 7). TC[DLV]는 실제 바이너리 E2E + WARN-escalate 게이트를 통해 계약 적합성을 검사한다.
13-product-acceptance-inspection — 독립된 주체가 블랙박스(Black-box)로 완성품을 검사함
담당 영역: PAI (완성품 적합성 검사, Product Acceptance Inspection). 작성자와 독립된 주체가 완성품을 **실제 환경·블랙박스 (Black-box)**에서 계약 적합성을 검사한다.
필요성: 조건 ④의 최종 형태. 그리고 여기에 이 글에서 여러 번 언급했던 54건의 기원이 있다.
54건은 어디에서 왔는가 (기원)
이것은 사고 실험이 아니라, L2A-SCP의 트레이서빌리티 엔진 (Traceability Engine)인 legixy 자체가 완성품으로서 관측한 실적이다 (자기 도그푸딩 (Dogfooding)). "전 기능 체인 GREEN + trace-check PASS + 배송층 TC[DLV] pass"를 모두 충족했음에도 불구하고, 계약 위반이 54건 잔존해 있었다. 그것들을 포착한 것은 유일하게 작성자와 독립된 외부의 블랙박스 적합성 검사 (PAI)뿐이었다. 근본 원인은 defect-root-cause의 RC-1 —— 동결 계약 (Frozen Contract)의 적합성 테스트가 결과물로서 존재하지 않았다는 점이다. 즉, "테스트는 모두 그린(Green)이다"와 "계약에 적합하다"는 별개의 명제라는 주장의 경험적 근거가 된다.
TC[DLV] = 회귀 (Regression), PAI = 발견 (Discovery)로 역할을 나누어, AT (UX)와 PAI (계약/기능)는 상호 대체할 수 없는 채널로서 병행시킨다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기