46개 리포지토리에 걸친 코드베이스를 정적 분석으로 하나의 지식 그래프(Knowledge Graph)로 만든 이야기 (전편)
요약
46개 리포지토리에 분산된 복잡한 코드베이스를 정적 분석을 통해 하나의 지식 그래프(code-graph)로 통합한 사례를 다룹니다. AI의 컨텍스트 윈도우 한계와 할루시네이션 문제를 해결하기 위해 외부에서 관계성을 추출하는 접근 방식을 설명합니다.
핵심 포인트
- 46개 리포지토리의 복잡한 의존 관계를 정적 분석으로 통합
- AI의 컨텍스트 윈도우 및 할루시네이션 한계 극복을 위한 지식 그래프 구축
- 리포지토리 간 API, DB, Event 의존성 파악을 위한 경계 노드 추출
- 코드베이스 전체의 영향 범위 조사 및 변경 시 리스크 관리 목적
여러분 안녕하세요! 에어클로젯(airCloset)에서 CTO를 맡고 있는 츠지(辻)입니다.
이번에는 여러 서비스 합계 **46개 리포지토리(repository)**에 걸친 운영 시스템의 코드베이스를, 정적 분석(static analysis)을 통해 하나의 지식 그래프(knowledge graph)로 통합한 이야기에 대해 말씀드리고자 합니다.
사내에서는 code-graph라고 부르고 있으며, 올해 1월부터 3월에 걸쳐 구축했습니다.
기록해 두고 싶은 논점은 3가지가 있습니다.
- 왜 단순히 "코드를 읽게 하는 것"만으로는 부족했고, 리포지토리를 넘나드는 연결 관계까지 파악해야 했는가
- 46개 리포지토리에 흩어져 있는 다종다양한 프레임워크(jQuery / AngularJS / Express / NestJS / TypeORM / Redux Axios ...)의 경계를 어떻게 추출해 나갔는가
- 3개월간의 시행착오 결과, 무엇이 해결되었고 무엇이 해결되지 못했는가
본 기사는 전편으로, code-graph 자체의 구축과 고충, 그리고 남은 과제까지를 다룹니다. 후편에서는 code-graph를 기반으로 하되 다른 레이어에서 보강한 service-product-graph(SPG)에 대한 이야기를 다룰 예정입니다.
무엇을 위해 만들었는가
오랜 기간 쌓여온 운영 시스템의 코드베이스는 보통 다음과 같은 상태가 됩니다.
- 여러 서비스와 여러 팀이 다룸
- 각 시대의 프레임워크가 시대별로 혼재되어 있음
- API, DB, Event에 의한 리포지토리 간의 의존성이 1:1의 전후 관계가 아니라 복잡하게 얽혀 있음:
- 동일한 API를 여러 리포지토리에서 호출함 (= 호출 측이 여러 개인 n:1 관계)
- 동일한 DB 테이블에 대한 쓰기 / 읽기가 n:n으로 여러 리포지토리에 흩어져 있음
- Event는 발행 측만 봐서는 구독 측을 어디까지 망라하고 있는지, 애초에 추적조차 불가능함
이 코드베이스 전체에 대해 AI에게 "영향 범위를 봐줬으면 좋겠다", "여기을 바꾸면 무엇이 망가질지 조사해줬으면 좋겠다"라고 부탁하고 싶다는 것이 출발점이었습니다.
여기서 솔직하게 생각하면, "AI에게 모든 리포지토리의 코드를 통째로 넘겨서 분석하게 하면 되지 않을까"라는 생각이 듭니다.
하지만 그것은 두 가지 이유로 불가능합니다.
- 컨텍스트 윈도우 (Context Window): 46개 리포지토리 × 오랜 기간 쌓인 코드량을 AI에게 그대로 전달할 수 있는 크기가 아님
- 할루시네이션 (Hallucination): 설령 전달할 수 있다 하더라도, AI가 "전체를 읽고 관계성을 추출하는 것"은 추론 기반의 작업이기에 간과하거나 오류가 발생함. 운영 시스템의 영향 범위 조사용으로는 사용할 수 없음
그래서 먼저 생각해낸 것이 "외부에서 정적 분석으로 지식 그래프를 만든다"라는 접근 방식이었습니다. 이것이 code-graph의 출발점입니다.
규모: 46개 리포지토리
대상은 두 개의 graph로 나뉩니다.
- air-closet graph (37개 리포지토리): airCloset이나 Men's, WMS 등 여러 서비스를 횡단하는 graph
- mall graph (9개 리포지토리): airCloset Mall 계열
합계 46개 리포지토리입니다.
포인트는 이것이 "하나의 서비스에서"가 아니라 여러 서비스의 집합으로서 이 정도 규모가 되었다는 점입니다. 서비스 경계 그 자체를 넘나드는 의존 관계를 크로스 리포지토리의 edge로 보이게 만드는 것이, 이후에 나올 경계 노드 (boundary node) 이야기로 이어집니다.
왜 경계 노드가 중요한가
이 부분이 이 기사의 핵심입니다.
AI에게 코드를 이해시킬 때, 눈앞에 있는 코드나 그 옆에 있는 코드를 "읽게 하는 것"은 그리 어렵지 않습니다. grep으로 해당 파일을 열어서 읽게 하면 충분히 기능합니다.
다만 소규모 코드베이스라면 그것만으로도 충분하겠지만, 대규모 코드베이스에서 같은 일을 해도 앞서 언급한 컨텍스트 윈도우나 할루시네이션 문제가 발생합니다. 아마 이 글을 읽고 계신 많은 분도 공감하실 것입니다.
이를 개선하는 한 가지 방법으로서, 코드베이스를 정적 분석하여 지식 그래프로 변환하고 MCP를 통해 AI에 공급하는 수법을 취하고 있습니다.
그 첫 번째 단계로 수행한 것이 tree-sitter(소스 코드를 구문 트리로 파싱하는 OSS 라이브러리. 많은 언어를 지원하며, VS Code 등의 에디터 구문 강조에서도 사용됨)를 이용한 정적 분석이었습니다. 이 도구 자체는 매우 유용하므로 비슷한 일을 하고 싶은 분들에게 강력히 추천하지만, tree-sitter만으로는 해결할 수 없는 부분도 있습니다.
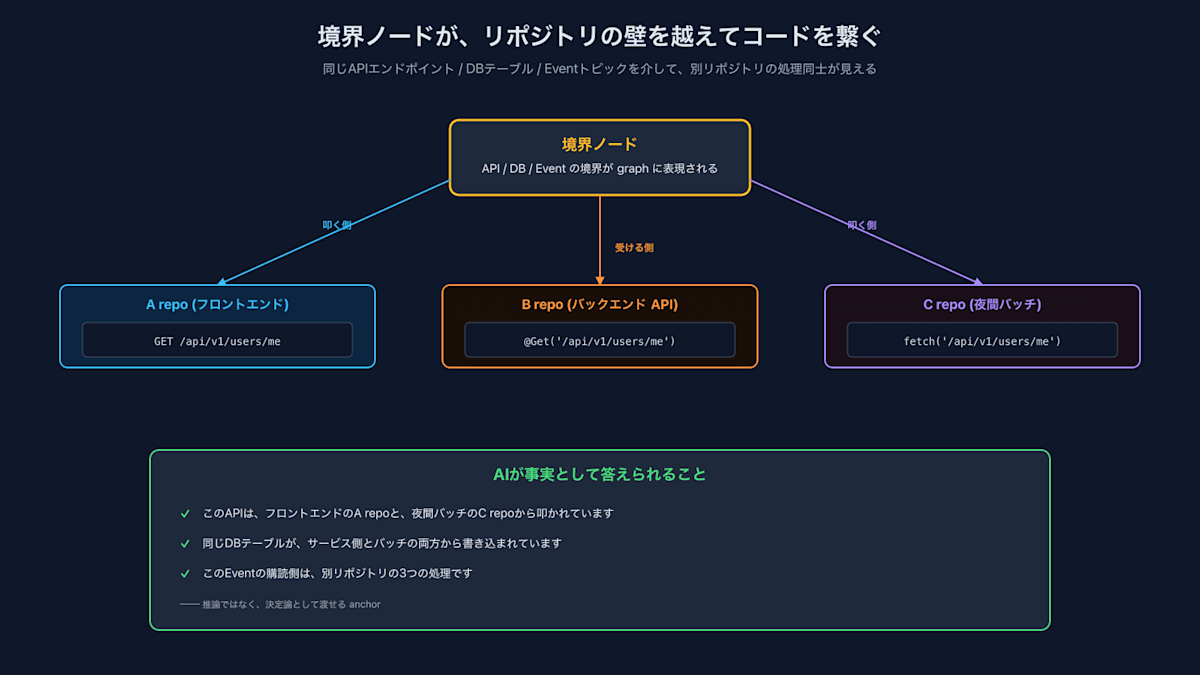
그것은 API나 데이터베이스 등의 경계를 넘나드는 관계의 추적입니다. tree-sitter는 프로그래밍 언어의 변수나 함수 등의 처리 관계를 분석하고 추출할 수는 있지만, 그러한 경계를 추출할 수는 없습니다.
하지만 실제로 사람도 AI도 막히기 쉬운 부분은, 바로 이러한 경계를 넘나드는 코드의 연결성입니다:
동일한 API를 호출하는 처리가 다른 리포지토리에도 있을 수 있음 - 프론트엔드 A repo와 야간 배치(Batch) C repo가 동일한 /api/v1/users/me를 호출하고 있을 가능성 - 한쪽 repo만 보고 있어서는 AI가 절대 알 수 없음
동일한 DB 테이블을 참조하는 코드가 배치(Batch)에 있을 수 있음 - 서비스 측의 처리를 수정하고 싶을 때, 다른 곳의 배치가 동일한 테이블을 읽고 쓸 가능성 - 영향 범위를 잘못 파악하면 데이터 불일치(Data Inconsistency)가 발생함
-
모르는 곳에서 다른 처리가 실행됨
요컨대, "경계 너머에 있는 코드"를 AI가 환각(Hallucination)을 일으키지 않고 파악하게 하는 것. 이것이 목적입니다.
경계 노드(Boundary Node)를 확보할 수 있다면, AI는 "이 API는 다른 ○○ repo에서도 호출되고 있습니다"라고 사실로서 대답할 수 있습니다. AI에게 추론하게 하는 것이 아니라, 사전에 해결된 사실로서 전달할 수 있는 것입니다 (추출 시에는 TypeScript Compiler나 Gemini를 통해 추론이 들어가지만, 그 결과는 그래프(Graph)에 확정값으로 저장되며, 후술할 경계 분석의 일일 cron을 통해 드리프트(Drift)를 다음 날 아침에 감지할 수 있는 상태로 만듭니다. AI가 소비하는 시점에는 검증된 사실만이 전달되는 형태가 됩니다).
AI는 "모르는 것"을 "모른다"고 답하기보다, 보이는 범위 내에서 어떻게든 답을 내놓으려는 경향이 있습니다. 여기서 발생하는 것이 사이런트 환각(Silent Hallucination)입니다. AI 자신도, 그것을 받아들이는 사람도 알아차리지 못하는 오답입니다. 경계 노드는 이를 물리적으로 차단하는 사실의 근거가 됩니다.
구축: tree-sitter 기반, 필요한 곳에서 TypeScript Compiler와 Gemini 병용
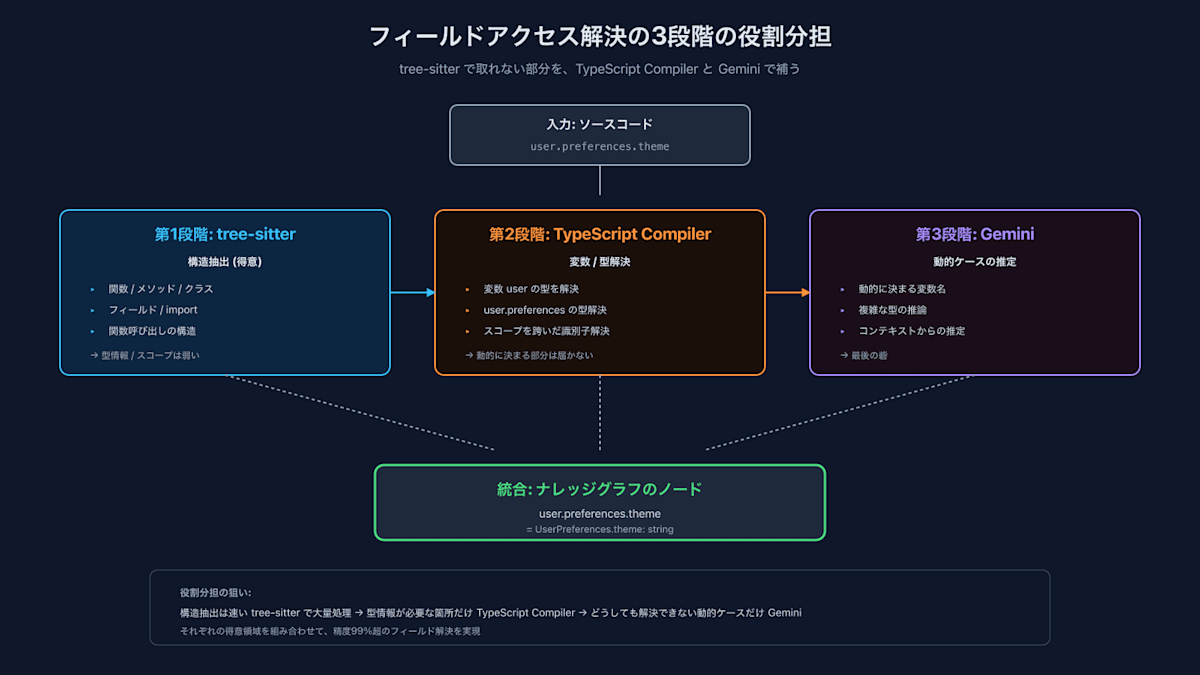
일반적인 코드(함수 호출 / 클래스 상속 / import 관계)는 tree-sitter로 비교적 쉽게 가져올 수 있습니다. AST를 따라 함수 / 메서드 / 클래스 / 필드를 노드로 만들고, 참조 관계를 에지(Edge)로 연결합니다. 이것은 묵묵히 수행하기만 하면 됩니다.
다만, tree-sitter는 구문 트리(Syntax Tree)를 만드는 데는 능숙하지만, 타입 정보나 스코프 분석(Scope Analysis)에는 약합니다. 필드 액세스(field access, user.preferences.theme와 같은 체이닝)를 정확하게 추적하려면, 변수 user가 어떤 타입으로 어떻게 정의되어 있는지를 해결해야 합니다. 이는 tree-sitter 단독으로는 도달할 수 없는 영역입니다.
그래서 필드 액세스 해결을 위해 TypeScript Compiler API와 Gemini를 병용하고 있습니다. tree-sitter로 구조를 추출 → TypeScript Compiler로 변수와 타입을 해결 → 그럼에도 해결되지 않는 동적인 케이스는 Gemini로 추정하는 방식으로 역할 분담을 하여 정밀도를 높이고 있습니다.
에지는 21종류로 정의되어 있습니다.
CALLS (함수 호출) / EXTENDS (상속) / IMPLEMENTS (interface 구현) 등 tree-sitter로 가져올 수 있는 기본적인 구조
CALLS_API(caller 측) /HANDLES_API(handler 측) ── API 경계EMITS_TO/WRITES_TO/READS_FROM── DB 경계- 등등
진정한 싸움은 경계 에지(CALLS_API / HANDLES_API / EMITS_TO / WRITES_TO / READS_FROM)를 확보하는 단계부터 시작됩니다.
경계 노드 추출과 접합의 고충: 1월~3월의 시행착오
일반적인 코드와 달리 경계(API 엔드포인트 / DB 테이블 / Event 토픽)는 프레임워크, 언어, 기술 영역, 라이브러리, 리포지토리, 작성자에 따라 작성 방식이 제각각입니다.
동일하게 "API 엔드포인트를 정의한다"는 의미의 처리라도, Express로 작성하느냐, NestJS의 @Get()을 사용하느냐...
데코레이터(Decorator)로 작성하느냐, Fastify의 route로 작성하느냐에 따라 AST(Abstract Syntax Tree) 형태가 완전히 달라집니다. 게다가 동일한 리포지토리 안에서도 여러 패턴이 혼재되어 있는 경우가 있습니다.
그리고 고생스러운 점은 추출만이 아닙니다. 추출한 경계(boundary)를 그래프(graph) 상에서 접합하는 것 또한 번거로운 작업입니다. 동일한 API 경로(path)나 DB 테이블 이름이라 하더라도,
- camelCase / snake_case / PascalCase 등의 명명 규칙(naming convention) 차이
- 슬래시(/)의 유무 (
/users/mevsusers/me) - 경계 이름 자체가 변수화되어 있는 케이스 (
${baseUrl}/users/me)
이 모든 것을 46개 리포지토리와 다양한 프레임워크 전체에 대해 찾아내야 했습니다.
실제로 당시의 git 히스토리를 살펴보면, 매주 새로운 파서(parser)나 디텍터(detector)가 추가되고, 노이즈 필터가 더해지며, 개념 정리가 이루어졌음을 알 수 있습니다. 여기에 1월부터 3월에 걸친 주요 커밋(commit)을 시계열로 나열해 보겠습니다 (커밋 프리픽스(commit prefix)는 초기에 graph-rag (= 지식 그래프(Knowledge Graph) + RAG로서 LLM에 공급하는 기반,이라는 발상의 스택 이름)로 시작하여, 2월 15일에 code-graph로 통일되었습니다).
1월: 시작, 그리고 tree-sitter만으로는 부족하다는 것을 깨닫다
- 2026-01-15─
feat(graph-rag): add TypeScript parser with tree-sitter
── 여기서부터 시작 - 2026-01-15─
feat(graph-rag): add graph builder with BigQuery storage
── BigQuery에 쓰는 방식으로 변경 - 2026-01-19─
feat(graph-rag): add TypeScript Compiler-based variable resolution for field extraction
── tree-sitter만으로는 변수의 타입 해결(type resolution)을 할 수 없다는 점이 드러나, TypeScript Compiler API도 병용하는 형태로 변경
2월: 다양한 프레임워크 대응과 노이즈와의 싸움
- 2026-02-02─
feat(graph-rag): add frontend parser for jQuery/Vanilla JS codebase
── jQuery / Vanilla JS 프론트엔드 코드 대응 - 2026-02-03─
feat(graph-rag): add AngularJS Page detection for frontend BFS
── AngularJS 페이지 탐지 (오래된 프레임워크이지만 여전히 현역으로 동작 중) - 2026-02-15─
refactor(code-graph): consolidate 18 MCP tools into 5 with deep subgraph traversal
── 18개로 불어났던 도구를 5개로 정리 (이 시점에code-graph라는 명칭으로 통일) - 2026-02-18─
fix(code-graph): reduce graph noise by filtering Type nodes, external lib CALLS, and Storybook files
── 노이즈 감소: Type 노드 / 외부 라이브러리의 CALLS / Storybook 파일 필터링 - 2026-02-19─
fix(code-graph): extract path aliases from tsconfig paths in addition to make-symlink+fix(code-graph): resolve @alias path imports for CommonJS symlink patterns
── path alias 해결의 고충: tsconfig paths와 make-symlink, 여기에 CommonJS의 symlink 패턴까지 총 3가지 메커니즘에 대응 - 2026-02-19─
feat(code-graph): add stop_at=boundary option to trace_connections
── 경계에서 정지하는 옵션 (스캔 범위의 명시적 제어 / 노드 폭발 대책) -
2026-02-21─feat(graph): add typeORM JOIN detection, NestJS decorator parsing, Fetcher API detection
──TypeORM의 JOIN / NestJS의 데코레이터 / Fetcher API 대응 -
2026-02-21─fix(graph): pass fullFileCode to Redux Axios variable resolver for scope-based extraction
──Redux Axios의 variable resolver 수정
3월: 개념 정리와 세밀한 정밀도 향상
2026-03-08─refactor(code-graph): rename __external__ to __boundary__
──개념 정리: 「외부 리소스」가 아니라 「경계 노드 (boundary node)」라는 명칭으로 통일 -
2026-03-16─refactor: remove db-dictionary from code-graph stack
── DB 스키마 사전 (테이블·컬럼 정의를 참조할 수 있는 레이어)을 별도의 graph로 독립시켜 발전 -
2026-03-24─fix(code-graph): infer table names from dynamic variable names
── 동적 변수명으로부터 테이블 이름 추정 -
2026-03-24─feat(code-graph): add orphan boundary node cleanup script
── 고립된 경계 노드의 클린업 스크립트
이 타임라인을 통해 알 수 있는 이야기
매주 새로운 프레임워크나 패턴에 대한 대응이 추가되고 있습니다. 「경계 노드를 가져오는」 작업은 결국 다양한 작성 방식 각각에 대해 parser를 추가해 나가는 작업입니다.
구체적으로 등장한 프레임워크 / 메커니즘만 나열해도 다음과 같습니다.
- tree-sitter (TypeScript / JavaScript / Go / Dart (Flutter))
- TypeScript Compiler (variable resolution)
- jQuery / Vanilla JS
- AngularJS
- Express / Koa / Fastify
- NestJS (데코레이터 parsing)
- TypeORM (DB의 JOIN 검출)
- Fetcher API
- Redux Axios (variable resolver)
- path alias의 3가지 방식 (tsconfig paths / make-symlink / CommonJS symlink)
단순히 「TypeScript / JavaScript / Go / Dart 등의 정적 분석」이라고 말하고 끝날 문제가 아닙니다. air-closet 계열의 코드베이스는 오랫동안 운영되어 온 운영 시스템의 집합체로, 각 시대의 프레임워크가 공존하고 있습니다. 각 시대의 「여기에 API 엔드포인트가 있다」, 「여기서 DB를 호출하고 있다」, 「여기서 Event를 구독하고 있다」라는 의미를 AST로부터 추출해 낼 필요가 있었습니다.
왜 그렇게까지 정밀도에 집착하는가
90%의 정밀도로는 전혀 쓸모가 없습니다.
예를 들어 「이 API를 호출하는 처리를 전부 뽑아줘」라는 용도에서 정밀도가 90%뿐이라면, 10%의 처리는 AI의 눈에 보이지 않습니다. 영향 범위를 조사하기 위해 code-graph를 사용하는 경우, 이 보이지 않는 10%가 사고를 일으킵니다.
게다가 graph를 따라가는 용도에서는 홉(hop)을 거듭할수록 정밀도가 거듭제곱으로 떨어집니다. 1홉에서 0.9라면, 2홉에서 0.81, 3홉에서 0.729, 5홉에서 약 0.59, 10홉에서 약 0.35 ── 몇 홉만 따라가도 결과는 절반 이하로 떨어집니다. 반면, 99%까지 끌어올리면 2홉에서 0.98, 5홉에서 0.95, 10홉에서도 약 0.90을 유지합니다. 실용성을 견딜 수 있느냐는 바로 이 한 자릿수의 차이로 결정됩니다.
새로운 경계 패턴이 발견될 때마다 독자적인 파서(Parser)를 추가로 작성하며, 경계 연결률을 99% 이상으로 유지하는 것을 목표로 해왔습니다. '전체 경계'라는 분모를 가질 수 없는 이상, 추출 망라율(Recall)을 직접 측정하는 것은 어렵기 때문에, 실제로 매일 측정할 수 있는 지표로는 'caller 측과 handler 측이 그래프(Graph) 상에서 제대로 연결되어 있는 비율' = 연결률을 사용하고 있습니다. 다음 섹션에서 그 모니터링 메커니즘에 대해 쓰겠습니다.
경계 분석의 운용 ── 지금도 매일 작동 중
지금까지 구축한 code-graph는 지금도 매일 작동하고 있습니다.
구체적으로는, 매일 JST 7:00에 경계 분석의 cron이 실행됩니다. 수행하는 작업은 다음과 같습니다:
- API 경계:
CALLS_API(caller 측)와HANDLES_API(handler 측)를 대응시켜, 리포지토리(Repository)를 넘나드는 연결률을 집계 - Event 경계:
EMITS_TO - DB 경계:
WRITES_TO와READS_FROM이 서로 다른 리포지토리에서 동일한 테이블을 참조하는 케이스를 집계 (= 리포지토리 간의 암묵적인 DB 의존성)
집계 결과를 매일 비교하여, 연결률이 이전 대비 5% 이상 저하되었다면 Grafana를 통해 알람을 보냅니다.
이는 "경계 노드를 가져오고 있다는 전제" 하에서 비로소 성립하는 운용입니다. "가져오고 있는 경계의 질" 그 자체를 일 단위로 모니터링하는 메타(Meta)적인 메커니즘으로 되어 있습니다. 연결률로 포착할 수 있는 종류의 드리프트(Drift) ── "파서(Parser)가 새로운 패턴에 대응하지 못해 경계의 일부가 보이지 않게 됨", "리포지토리 구성이 바뀌어 path alias를 해결할 수 없게 됨" ── 은 다음 날 아침에 바로 검지할 수 있는 상태가 됩니다. 반면 연결률로는 포착할 수 없는 드리프트(caller 측 파서의 리그레션(Regression)으로 인해 caller가 통째로 사라진 경우, handler는 남아 있는 다른 caller와 "연결되어" 있는 것처럼 보여서 사라진 caller는 조용히 누락됨)는 별도의 축으로, 리포지토리 / 패턴별 절대 노드 수를 일 단위로 비교하여 보완하고 있습니다.
그럼에도 남는 과제
여기까지 진행했음에도 불구하고, 몇 가지 근본적으로 해결되지 않는 과제가 남아 있습니다.
1. 시맨틱 검색(Semantic Search)이 불가능함 (입구의 문제)
검색 MCP 도구는 LIKE를 이용한 문자열 부분 일치 방식뿐입니다.
개발 중에 "지금 내가 보고 있는 함수의 연결 관계를 따라가고 싶다"와 같은 경우에는 해당 함수명이나 파일명으로 직접 검색할 수 있으므로 이 정도로도 문제가 없습니다.
문제가 되는 것은 실제 운영 중의 버그나 고객으로부터의 문의를 조사할 때입니다. 관련 코드의 파일명이나 함수명 따위는 처음에는 알 수 없습니다. "회원의 구독료 계산이 틀린 것 같다"라는 입력으로부터 관련 코드를 추적하고 싶을 때, 자연어 쿼리로 그래프를 검색할 수 없다면 애초에 입구를 찾을 수 없습니다.
"코드베이스 전체를 grep으로 검색하는 것이 아니라, graph RAG로 관련성을 추적할 수 있다"는 계획이었으나, 입구에서 grep을 하고 추론할 수밖에 없는 구조가 되어 있습니다.
2. 노드 폭발
tree-sitter로 AST를 그대로 그래프화하면, 내장 함수(builtin function)나 익명 함수, 내부 유틸리티(utility)까지 전부 노드가 됩니다. 실용적으로는 불필요한 "이 map 호출", "이 내부 helper"까지 전부 노드화되어 버립니다.
어느 기점 노드로부터 관련 노드를 따라가는 탐색을 수행하면, 불과 몇 홉(Hop) 만에 helper나 타입(Type), 프리미티브(Primitive)를 포함하며 노드 수가 폭발합니다. "관련성으로 좁히기" 위한 축이 그래프 구조 내에 존재하지 않습니다.
탐색을 경계 노드에서 멈추도록 하는 명시적인 제어로 운용상으로는 회피하고 있지만, 근본적인 대책은 아닙니다.
3. 함수의 내용은 결국 파일을 보지 않으면 알 수 없음
그래프를 통해 "여기에 무언가 있다", "여기서 다른 repo의 처리를 호출하고 있다"까지는 알 수 있습니다. 하지만 "이 함수가 구체적으로 무엇을 하고 있는가"는 결국 파일을 열어서 읽어보지 않으면 알 수 없습니다.
그래프 단독으로는 시간이 걸립니다. 나중에 만든 코드베이스 조사 도구에서는 그래프에서 후보 파일을 좁힌 뒤, Git Server MCP를 통해 실제 파일을 읽게 하는 방식으로 회피하고 있지만, 그래프 단독으로서의 해상도 한계는 그대로 남아 있습니다.
4. 새로운 경계 패턴이 나올 때마다 파서를 추가해야 하는 운용 부하
프레임워크 / 라이브러리가 새로 도입될 때마다, "해당 프레임워크에서는 경계를 이렇게 작성한다"는 것을 학습하고 파서를 추가로 작성해야 합니다.
이미 parser 디렉토리에는 10개 이상의 독자적인 detector / extractor가 나열되어 있습니다. 유지 및 확장 비용이 낮아질 기미는 보이지 않으며, 새로운 기술 스택이 코드베이스에 도입될 때마다 동일한 작업을 반복하게 됩니다.
보충: 다른 곳에서는 다른 판단 ── cortex 이야기
지금까지 code-graph에 대해 써왔지만, 보충 설명으로 저는 별도로 cortex라는 사내 AI 플랫폼을 처음부터 구축하고 있는 프로젝트를 가지고 있습니다 (현재 100개 이상의 앱이 포함된 하나의 모노레포 (monorepo)입니다).
그곳에서도 처음에는 code-graph와 동일한 접근 방식을 시도했으나, 빠른 단계에서 포기하고 어노테이션 기반의 지식 그래프 (annotation-based knowledge graph) 방식으로 전환했습니다.
- 제가 직접 구성하고 있는 모노레포이므로, 어노테이션을 일제히 부여한다는 전제를 둘 수 있음
- JSDoc 태그를 통해 코드 자체에 의도를 기록하고, 이를 그래프화하는 설계
- 위의 의도를 벡터화하여 노드에 저장함으로써 시맨틱 검색 (semantic search)이 가능하도록 함
이 "의도를 코드에 기록하여 그래프화한다"는 판단과 그 판단에 이르기까지의 시행착오는 별도의 연재에서 자세히 다루고 있습니다. 관심이 있다면: AI 하네스 연재 Part 2 (AI의 AI에 의한 AI를 위한 지식 그래프)
운영 시스템 측에는 어노테이션 기반 방식이 현실적이지 않음
그리고 이번에 code-graph에서 다루고 있는 운영 시스템 측에 동일한 접근 방식을 취할 수 있느냐고 묻는다면, 그것은 불가능합니다.
- 46개 리포지토리 전체에 어노테이션을 일제히 부여하는 것은 현실적이지 않음
- 오랜 기간 운영되어 온 운영 시스템, 여러 팀이 만지고 있음, 프레임워크도 제각각임
- "코드에 어노테이션을 넣는다"라는 전제가 성립하지 않음
따라서 code-graph (정적 분석 기반)를 베이스 (base)로 하되, 별도의 레이어에서 보강하는 방향으로 진화시키는 선택을 했습니다.
이 과제를 어떻게 해결하려고 하는지는 후편에서 별도로 설명하겠습니다.
계속됩니다
전편은 여기까지입니다. 후편에서는 위의 과제를 어떻게 극복하려고 하는지에 대해 쓸 예정입니다.
"버린" 것이 아니라 "진화시킨" 것이 진짜 스토리입니다.
긴 글 읽어주셔서 감사합니다.
제가 CTO를 맡고 있는 주식회사 에어클로젯(AirCloset)에서는 AI와 함께 새로운 개발 경험을 만들어 나갈 엔지니어를 모집하고 있습니다. 관심 있는 분은 꼭 엔지니어 채용 사이트 에어클로퀘스트(AirCloset Quest)를 확인해 주세요!
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기