
2,700 토큰에 48,000자: LLM이 텍스트를 이미지로 읽는 방식에 대하여
요약
텍스트 대신 이미지를 컨텍스트로 활용하여 LLM의 토큰 비용을 획기적으로 절감하는 pxpipe 프로젝트를 소개합니다. 동일한 정보를 이미지로 전달할 경우 텍스트 대비 토큰 사용량을 최대 89%까지 줄일 수 있는 메커니즘을 설명합니다.
핵심 포인트
- 텍스트 대신 이미지를 사용해 Claude Code 세션 비용을 $42.21에서 $4.51로 절감
- 멀티모달 모델은 픽셀 단위로 과금되므로 밀도 높은 텍스트를 이미지로 변환 시 유리
- 48,000자 텍스트를 2,700 이미지 토큰으로 압축하여 정보량 유지 및 비용 최적화
- 에이전트 및 롱 컨텍스트 파이프라인 운영 시 실질적인 비용 조절 수단 제공
2025년 12월 말, 저를 포함한 많은 이들은 pxpipe라는 작은 오픈 소스 프로젝트를 발견했습니다. 이 프로젝트는 마치 결제 오류처럼 들리는 주장과 함께 GitHub에서 트렌드가 되기 시작했습니다. 즉, 일반 텍스트로 처리했을 때 42.21달러가 들었던 동일한 Claude Code 세션이, 요청의 부피가 큰 부분들을 기기에서 나가기 전에 PNG 이미지로 변환했을 때는 4.51달러밖에 들지 않았다는 것입니다.
동일한 모델, 동일한 작업, 동일한 답변이었습니다. 유일한 차이점은 모델이 컨텍스트(Context)의 대부분을 토크나이저 (Tokenizer) 대신 눈으로 읽었다는 점입니다.
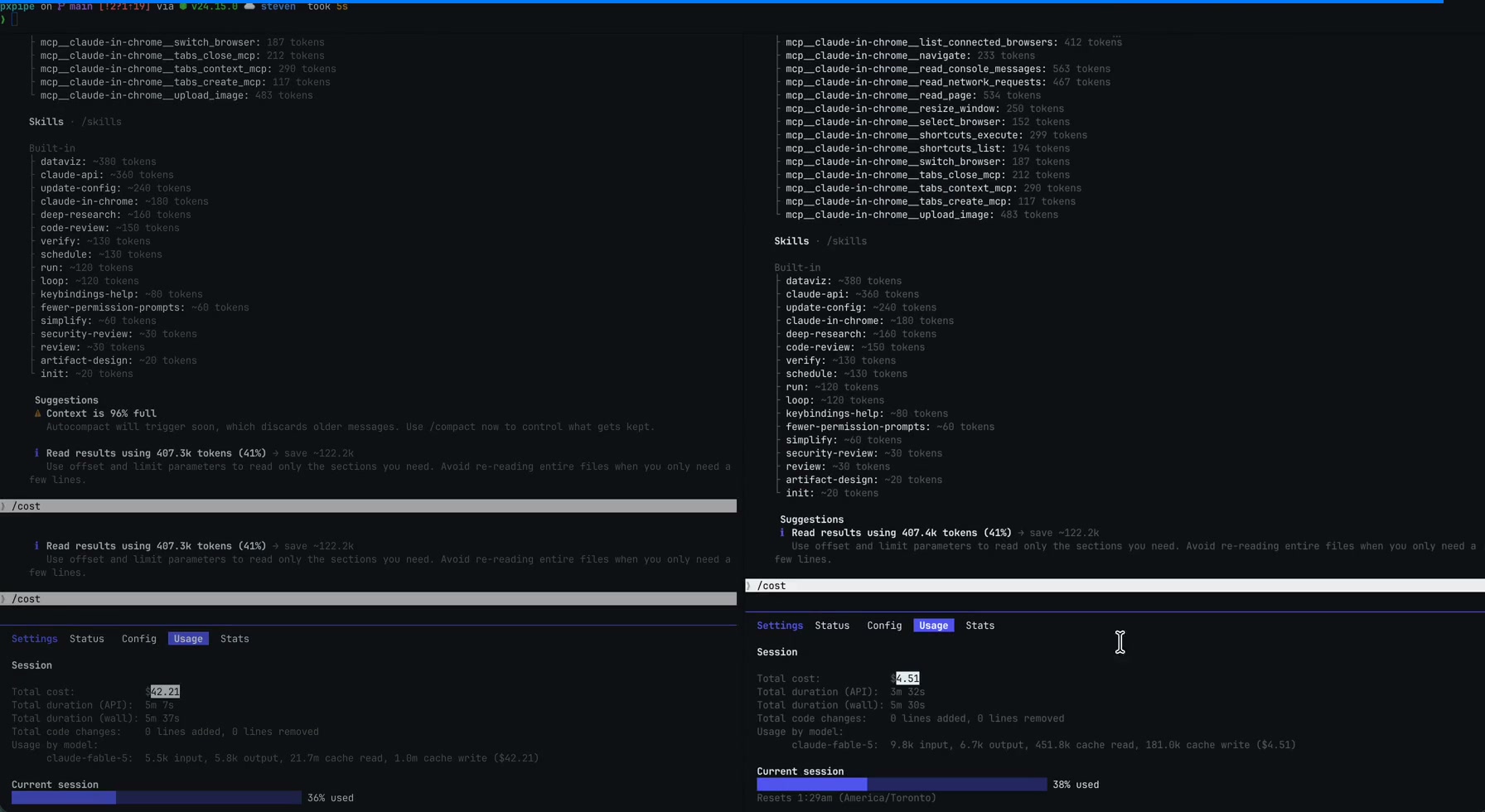
화제가 된 A/B 테스트: 동일한 세션, 텍스트로는 42.21달러 vs 이미지 컨텍스트로는 4.51달러. 출처: pxpipe 리포지토리 (MIT).
이 수치는 분석할 가치가 있습니다. 그 이면에 있는 메커니즘이 하나의 도구보다 더 크기 때문입니다. 이는 에이전트 (Agents)나 긴 컨텍스트 파이프라인 (Long-context pipelines)을 운영하는 모든 이들에게 실질적인 비용 조절 레버가 된다는 것을 설명해 줍니다. 또한, 대부분의 사람들이 아직 연결 짓지 못한 두 번째 질문과도 연결됩니다. AI 시스템이 실시간으로 당신의 웹사이트를 가져올 때, 그것은 실제로 무엇을 볼까요? 그 답은 점점 더 동일한 비전 채널 (Vision channel)과 관련이 깊어지고 있습니다.
메커니즘: 이미지는 문자가 아닌 픽셀로 과금됩니다
모든 멀티모달 모델 (Multimodal model)은 이미지의 크기에 따라 가격을 책정합니다. 1000x1000 픽셀 이미지는 그 안에 빈 흰색 공간이 있든 5,000단어의 밀도 높은 문서가 있든 동일한 수의 토큰 비용이 발생합니다. 토큰 측정기는 픽셀을 계산합니다. 그 위에 무엇이 그려져 있는지는 상관하지 않습니다.
반면, 텍스트는 문자 단위로 과금됩니다. 실제 Claude Code 트래픽을 보면, 코드, JSON, 로그와 같은 밀도 높은 콘텐츠는 텍스트 토큰당 대략 1자 정도로 계산됩니다. 동일한 콘텐츠를 빽빽하게 채워진 이미지로 렌더링하면 이미지 토큰당 약 3.1자 정도로 처리됩니다.
그 격차가 바로 핵심적인 기술입니다. pxpipe 문서의 원래 예시를 보면: 약 48,000자의 텍스트 블록(시스템 프롬프트 및 도구 문서 포함)은 텍스트로 처리할 경우 약 25,000 토큰이 소요됩니다. 이를 밀집된 PNG로 렌더링하면 약 2,700 이미지 토큰이 소요됩니다. 정보량은 동일하면서, 해당 블록에 대해 토큰 사용량을 89%나 줄인 것입니다. 간단합니다.

모델이 실제로 받는 데이터: 공백이 최소화(whitespace-minified)되고, 전체 행을 채우도록 재배열(reflowed)되었으며, 원래의 줄 바꿈 위치에 ↵ 표시가 삽입된 48,000자의 텍스트. 출처: pxpipe 리포지토리 (MIT).
비전 인코더 (vision encoder)가 이 페이지를 읽을 수 있도록 하기 위해, 텍스트는 세 가지 준비 단계를 거칩니다. 먼저 불필요한 공백을 제거합니다. 그다음, 이미지의 전체 행을 채우도록 줄을 재배열(reflow)하며, 약 1,928픽셀 너비의 열에서 줄 바꿈이 일어나도록 합니다. 마지막으로 원래의 줄 바꿈이 있던 곳에 작은 ↵ 표시를 삽입하여, 압축 후에도 구조가 유지되도록 합니다. 밀집된 페이지는 약 92,000자의 문자를 담을 수 있습니다.
왜 픽셀이 단어를 전달하는 데 있어 단어보다 뛰어난가
직관에 어긋나는 부분은 비용 문제가 아닙니다. 모델이 실제로 이를 매우 잘 읽을 수 있다는 점입니다.
Sean Goedecke는 왜 이러한 수학적 원리가 작동하는지에 대해 훌륭한 분석을 작성했습니다. 텍스트 토큰은 이산적인 선택(discrete choice)입니다. 약 50,000개의 항목으로 구성된 어휘 사전(vocabulary) 중 하나의 옵션을 선택하고, 이것이 임베딩 벡터 (embedding vector)로 매핑됩니다. 여러분도 아마 이 내용을 알고 계실 것입니다. 하지만 이미지 토큰에는 그러한 제약이 없다는 점은 아마 눈치채지 못했을 것입니다. 이미지 토큰은 임베딩 공간 내의 어떤 지점이든 차지할 수 있으며, 이는 단위당 훨씬 더 높은 표현력 (expressiveness)을 가짐을 의미합니다. DeepSeek의 연구는 이를 수치로 증명했습니다. 단 하나의 이미지 토큰으로부터 약 10개의 텍스트 토큰을 거의 완벽한 정확도로 복구할 수 있습니다. 저를 정말 놀라게 했던 것은 바로 이 정확도였습니다!
이 아이디어는 새로운 것이 아니며, 바로 그 점이 현재의 상황을 흥미롭게 만드는 요소 중 하나입니다. 저는 한 게시물에서 이를 보고 직접 시도해 보았으며, 그 이후로 계속 사용해 오고 있습니다. 사람들이 늘 그래왔듯, 수년 동안 멀티모달 (multimodal) 모델에 스크린샷을 붙여넣어 왔지만, 항상 제기되어 온 반대 의견은 동일했습니다. 비전 인코더 (vision encoders)가 작고 조밀한 글자를 읽기에 충분히 신뢰할 수 없었기 때문에, 제정신인 사람이라면 누구도 실제 서비스 환경의 컨텍스트 (context)를 비전 인코더를 통해 처리하도록 경로를 설정하지 않을 것이라는 점이었습니다. 2024년과 지금 사이에서 변한 것은 바로 인코더 (encoders)입니다.
DeepSeek가 광학 압축 (optical compression) 결과를 발표하고, pxpipe가 평가 (evals) 결과를 출시했을 때, 논의는 "이게 과연 작동할까"에서 "작동이 멈추는 정확한 비율은 이것이다"로 옮겨갔습니다. 이것이 바로 눈속임용 기술 (party trick)과 엔지니어링 옵션 (engineering option)의 차이입니다.
현재 주요 제공업체들이 실제로 이미지 토큰 (image tokens)을 계산하는 방식은 다음과 같습니다:
| 제공업체 | 이미지 가격 책정 방식 | 1000x1000 px 이미지 |
|---|---|---|
| Anthropic (Claude) | 28x28 픽셀 패치 (patches), 각 패치당 하나의 비주얼 토큰 (visual token): ⌈w/28⌉ x ⌈h/28⌉ | 1,296 토큰 |
| ... |
현재 Claude 모델 (Fable 5, Opus 4.7 및 4.8)에서 이미지는 긴 변이 최대 2,576 픽셀일 때 4,784 비주얼 토큰으로 제한됩니다. pxpipe의 렌더링 너비인 1,928 픽셀은 이 한계치 아래에 안정적으로 위치합니다. 이 중 어느 것도 우연이 아닙니다.
제공업체별 세부 사항
헤드라인 공식보다 세부 사항이 더 중요한 이유는, 각 제공업체가 그 안에 서로 다른 트레이드오프 (tradeoffs)를 숨기고 있기 때문입니다. 이 점이 삶을 흥미롭게 만드는 것이 아닐까요?
Anthropic의 이전 모델들은 긴 변을 1,568 픽셀, 비주얼 토큰을 1,568개로 제한했습니다. 이보다 큰 이미지는 처리되기 전에 다운스케일링 (downscaled)되었으며, 이는 비용과 해상도를 동시에 조용히 제한하는 결과를 초래했습니다. 오래된 글에서는 "토큰 = (너비 x 높이) / 750"이라는 기존의 근사치를 여전히 발견할 수 있을 것입니다. 패치 계산법 (patch math)이 이를 대체했습니다: 비주얼 토큰 하나당 28x28 픽셀이며, 각 축에 대해 올림 (ceiling-rounded) 처리합니다. 1000x1000 이미지의 경우 두 공식 모두 3% 이내의 오차를 보이는데, 이것이 오래된 규칙이 오랫동안 살아남았던 이유입니다.
OpenAI는 두 단계로 작동합니다. 먼저 이미지를 2048 픽셀 정사각형 안에 들어가도록 크기를 조정(scale)한 다음, 가장 짧은 변을 768 픽셀로 맞춥니다. 그 후에야 512 픽셀 타일링 (tiling)이 적용됩니다. "저세부 정보 (low detail)" 플래그를 사용하면 이 모든 과정을 건너뛰고 고정된 85 토큰을 사용하는데, 이는 텍스트를 읽는 데는 쓸모없지만 "이것이 고양이인가"를 판단하는 데는 충분합니다.
Google의 방식은 가장 단순합니다. 양쪽 변이 모두 384 픽셀 이하인 모든 이미지는 무조건 258 토큰입니다. 그 범위를 넘어서면, 768 픽셀 타일당 각각 258 토큰이 부과됩니다.
이에 따라 세 가지 결과가 뒤따릅니다. 첫째, 최적의 렌더링 크기는 제공자(provider)마다 다르기 때문에, Claude에 맞춰 조정된 파이프라인 (pipeline)은 Gemini에서 비용을 낭비하게 됩니다. 둘째, 업로드 전 크기 조정 (resizing) 여부는 사용자의 결정 사항이며, API가 대신 다운스케일링 (downscale)하게 두는 것보다 의식적으로 직접 조절하는 것이 더 낫습니다. 셋째, 이미지당 제한이 있기 때문에 매우 긴 문서는 하나의 거대한 페이지보다는 여러 개의 중간 밀도 페이지를 원하는 것이 좋습니다. pxpipe는 페이지당 약 92,000자를 담을 수 있으며, 콘텐츠가 넘치면 단순히 PNG 배열을 생성합니다.
![]()
한 장의 그림으로 보는 개념: 동일한 컨텍스트(context)를 텍스트로는 90 토큰, 이미지로는 50 토큰으로 처리. 출처: "Text or Pixels? It Takes Half" (arXiv 2510.18279), CC BY 4.0.
연구 결과가 말하는 것
2025년 10월에 발표된 두 편의 논문이 이 내용을 견고한 근거 위에 올려놓았습니다.
["Text or Pixels? It Takes Half"][https://arxiv.org/abs/2510.18279]는 GPT-4.1-mini와 Qwen2.5-VL-72B를 대상으로 이 아이디어를 체계적으로 테스트했습니다. 실험 설정은 정교했습니다: LaTeX로 조판된 300 DPI의 텍스트, 0.8의 채움 비율 (fill ratio)을 목표로 하는 적응형 폰트 크기 조정, 600x800에서 750x1000 픽셀 사이의 해상도를 사용했습니다. 긴 텍스트를 이미지로 렌더링했을 때, 정확도를 텍스트 전용 베이스라인 (baseline) 대비 3포인트 이내로 유지하면서도 약 2:1의 압축률 (디코더 토큰을 38%에서 58% 감소)을 달성했습니다. '건초더미 속 바늘 찾기 (needle-in-a-haystack)' 검색 작업에서 이미지 방식은 97%에서 99%의 점수를 기록했으며, CNN/DailyMail 요약 작업에서는 동일한 압축률에서 LLMLingua-2와 같은 전용 압축 베이스라인을 능가했습니다. 그리고 아무도 예상치 못한 보너스가 있었습니다: Qwen2.5-VL-72B에서 더 짧아진 디코더 시퀀스 덕분에 엔드투엔드 (end-to-end) 추론 속도가 25%에서 45% 더 빨라졌습니다. 동일한 트릭으로 더 저렴하고 더 빨라진 것입니다.
같은 달에 발표된 DeepSeek-OCR은 한 발 더 나아가 그 한계를 규명했습니다. 그들의 "컨텍스트 광학 압축 (contexts optical compression)" 연구에 따르면, 텍스트 토큰 대비 비전 토큰의 비율이 10배 미만으로 유지될 때 디코딩 정밀도 (decoding precision)가 97%로 유지됩니다. 압축률을 20배까지 밀어붙이면 정밀도는 약 60%로 떨어집니다. 이 두 지점 사이의 곡선이 이 기술 전체의 가격표인 셈입니다.
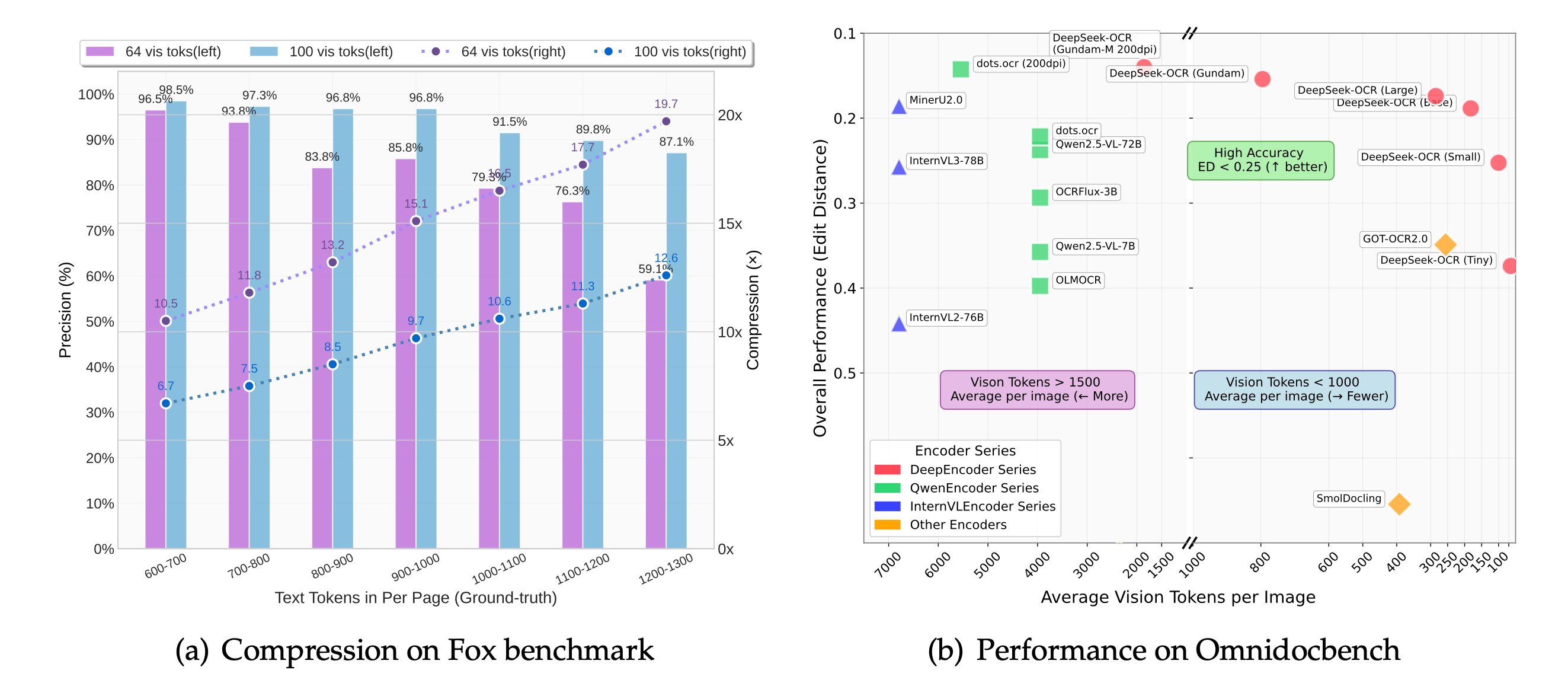
기술의 경계: 10배 미만의 압축에서는 정밀도가 97% 근처에서 유지되다가 그 이후 저하됩니다. OmniDocBench에서 페이지당 100개의 비전 토큰을 사용하는 방식은 256개를 사용하는 시스템을 능가했으며, 800개 미만으로는 6,000개 이상을 사용하는 시스템을 능가합니다. 출처: DeepSeek-OCR (arXiv 2510.18234), CC BY 4.0.
효율성 수치는 무시하기 어렵습니다. DeepSeek-OCR은 페이지당 100개의 비전 토큰으로 문서를 읽으며, 페이지당 256개를 사용하는 GOT-OCR2.0을 능가합니다. 800개 미만으로는 평균 6,000개 이상을 사용하는 MinerU2.0보다 뛰어난 성능을 보입니다. 실제 운영 환경에서 DeepSeek는 이를 활용하여 단일 A100-40G에서 하루 200,000페이지 이상의 LLM 학습 데이터를 생성합니다.
이 논문의 토론(discussion) 섹션에는 이 분야 전체를 통틀어 가장 공상과학(science-fiction)적인 아이디어가 포함되어 있습니다. 바로 광학 메모리(optical memory)입니다. 대화의 오래된 이력을 점진적으로 낮은 해상도의 이미지로 저장하여, 먼 과거의 문맥(context)이 인간의 기억처럼 말 그대로 희미해지도록 만드는 방식입니다. 이에 대한 자세한 내용은 마지막에 다루겠습니다.
프로덕션 파이프라인 내부
pxpipe는 자체적인 평가(evals)와 실패 사례를 공개하기 때문에 읽어볼 만한 가장 교육적인 구현체입니다. 이 시스템은 클라이언트와 Claude API 사이에서 로컬 프록시(local proxy)로 작동합니다. 요청은 세 가지 카테고리의 콘텐츠를 제외하고는 바이트 단위로 동일하게 전달되지만, 각 카테고리는 수익성 게이트(profitability gate) 뒤에 배치됩니다. 그 세 가지는 약 6,000자 이상의 밀도 높은 콘텐츠를 가진 도구 결과(tool results), 라이브 테일(live tail) 뒤에 있는 오래된 대화 턴(conversation turns), 그리고 정적인 시스템 프롬프트(system prompt) 및 도구 문서 덩어리(slab)입니다.
다른 무엇보다 중요한 두 가지 설계 규칙이 있습니다. 최근의 턴(turns)은 항상 텍스트로 유지됩니다. 그리고 정적 접두사(static prefix)는 건드리지 않고 보존되는데, 이는 프롬프트 캐싱(prompt caching)을 깨뜨릴 경우 비용 절감 효과가 사라지기 때문입니다.
해당 프로젝트의 자체 벤치마크 테이블에서 측정된 결과는 다음과 같습니다:
| 테스트 | 텍스트 베이스라인 (Text baseline) | 이미지 문맥 포함 (With imaged context) |
|---|---|---|
| 새로운 산술, Claude Fable 5 (n=100) | 100/100 | 100/100, 토큰 38% 감소 |
| ... |
마지막 행을 다시 한번 살펴보세요. 나중에 다시 이야기하겠습니다.
더 어려운 에이전트(agentic) 벤치마크인 SWE-bench Pro에서, 이미지 방식은 19개 작업 중 14개를 해결한 반면, 일반 텍스트 방식은 19개 중 15개를 해결했습니다. 하지만 이미지 방식은 요청 크기가 60% 더 작았으며, 19번의 실행 중 18번이 최종 판정에 동의했습니다. 이것이 어려운 작업에서 발생하는 트레이드오프(tradeoff)의 솔직한 모습입니다. 즉, 가장 어려운 문제에서는 약간의 정확도 비용(accuracy tax)을 지불하는 대신, 비용은 절반 이하로 줄이는 것입니다.
13,709개의 실제 요청 스냅샷을 대상으로 한 엔드 투 엔드(end to end) 결과, 비용은 100달러에서 약 41달러로 59% 감소했습니다. 압축이 집중적으로 적용된 트레이스(traces)는 70%에서 74% 더 저렴하게 실행되었습니다.
이에 따라 두 가지 운영 비용이 발생합니다. PNG를 인코딩하는 과정은 대규모 요청 시 지연 시간(latency)을 추가하며, 이는 파이프라인이 비용 효율성보다 지연 시간에 민감할 때 눈에 띄게 나타납니다. 또한 이 기술은 ASCII 및 Latin-1 콘텐츠에 대해 검증되었습니다. CJK(한중일) 텍스트도 작동하지만, 프로젝트에서는 이를 보수적으로 처리하여 압축률을 덜 공격적으로 적용합니다. 만약 사용자의 컨텍스트가 주로 중국어나 일본어로 구성되어 있다면, 압축률은 헤드라인에 나온 수치보다 낮을 것입니다.
컨텍스트를 이미지화하는 것이 이득이 될 때와 상황을 악화시킬 때
절감 효과만을 인용하는 이 기술에 대한 모든 글은 여러분에게 제대로 된 정보를 제공하지 못하고 있습니다. 주의하십시오, 이 방식은 손실 압축(lossy) 방식이며, 특정한 매우 까다로운 방식으로 실패합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Dev.to AI tag의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기