프롬프트 인젝션 (Prompt Injection) 이론 (그리고 왜 역할을 연구해야 하는가)
요약
LLM이 시스템 프롬프트, 사용자 메시지, 모델의 추론 등을 하나의 연속된 텍스트 스트림으로 처리하는 구조적 결함과 이로 인한 프롬프트 인젝션 발생 원인을 분석합니다. 모델이 '역할(Role)'을 인식하는 방식의 한계를 지적하며, 이를 통해 새로운 공격 생성 및 기계 해석 가능성을 제시합니다.
핵심 포인트
- LLM은 모든 입력을 단일한 토큰 스트림으로 처리하여 정보 간 구분이 어려움
- 프롬프트 인젝션은 LLM이 역할(Role)을 인식하는 방식의 결함에서 기인함
- 역할 태그(system, user, assistant 등)는 텍스트에 구조를 부여하는 핵심 요소임
- 입력 문자열의 편집은 모델의 현실과 기억을 직접적으로 수정하는 효과를 가짐
프롬프트 인젝션 (Prompt Injection) 이론 (그리고 왜 역할을 연구해야 하는가)
이 글은 논문을 블로그 형식으로 작성한 것입니다. 우리는 프롬프트 인젝션이 LLM (Large Language Models)이 역할을 인식하는 방식의 결함에 의해 발생한다는 것을 보여줍니다. 이를 통해 우리는 새로운 공격을 생성하고, 기계 해석 (mech interp) 결과를 설명하며, 공격이 언제 성공할지 예측할 수 있습니다. 그런 다음 역할이란 무엇인지, 왜 중요한지를 논의하고, 역할의 과학을 위한 연구 아이디어들을 공유합니다.
- LLM에게 세상이란
LLM은 어떻게 자신의 생각과 타인의 말을 구분할까요?
이것이 왜 어려운지 알아보기 위해, 모델에게 세상이 실제로 어떻게 보이는지 살펴보겠습니다. 여기 Claude에게 요일이 무슨 요일인지 확인하도록 요청하는 간단한 채팅이 있습니다. 저는 후속 응답 중간에 스냅샷을 찍었습니다:
[IMG:1]
왼쪽 = 우리가 보는 것; 오른쪽 = LLM이 받는 것.
왼쪽은 채팅 인터페이스에서 우리가 보는 모습, 즉 명확한 턴 (turn)이 구분된 구조화된 대화입니다. 오른쪽은 모델이 입력으로 실제로 받는 것, 즉 단일하고 연속적인 텍스트 스트림 (stream)입니다.
이 문자열 (string)에는 시스템 프롬프트 (system prompts), 사용자 메시지 (user messages), 도구 출력 (tool outputs), LLM 자신의 이전 응답 및 추론 (reasoning) 등 모든 것이 포함되어 있습니다. LLM은 단지 문자열을 입력받아 다음 토큰 (token)을 예측하는 함수일 뿐이므로, 모델이 알고 있거나 기억하거나 생각한 모든 것은 (가중치 (weights)를 제외하고) 하나의 문자열 어딘가에 존재해야 합니다. 만약 당신이 이 문자열을 편집한다면, 당신은 모델의 현실을 편집하는 것입니다. 한 턴을 삭제하면 그 교환은 결코 일어나지 않은 것이 되며, 이전 응답을 다시 쓰면 그것은 모델의 새로운 기억이 됩니다. 이 문자열은 모델의 경험에 대한 기록이라기보다, 그 자체가 바로 경험입니다.
이것은 기묘한 함의를 갖습니다. 저는 나의 생각과 당신의 말을 노력 없이도 구분할 수 있습니다. 그것들은 완전히 다른 채널을 통해 완전히 다른 감각적 특징을 가지고 전달되기 때문입니다. 하지만 LLM에게는 모든 것이 하나의 긴 토큰 수프 (token soup)로서 동일한 채널을 통해 전달됩니다. 모델 자신의 생각이 당신의 지시 사항 옆에 놓이고, 그 지시 사항은 방금 가져온 무작위 웹페이지의 내용 옆에 놓입니다.
- 역할 (Roles)
그렇다면 이 토큰 수프에 어떻게 구조를 부여할까요? 우리는 그것에 라벨 (label)을 붙입니다.
이 수프는 다음과 같은 역할 태그 (role tags)로 곳곳에 흩어져 있습니다: system, user, think, assistant, tool. 태그 형식은 모델마다 다르지만, 단순화를 위해 여기서는 이 고정된 형식들을 사용하겠습니다. assistant는 추론 (reasoning)을 제외한 LLM의 출력 텍스트를 의미합니다. 역할 태그를 사용하는 것은 채팅 템플릿 (chat templating)이라고도 알려져 있습니다. 이 태그들은 문자열을 라벨이 붙은 세그먼트로 분할합니다. OpenAI와 같은 제공업체들은 텍스트가 LLM에 도달하기 전에 이를 자동으로 추가합니다. 로컬 모델을 실행하는 것이 아니라면, 사용자가 직접 이를 추가할 수는 없습니다. 만약 Claude에서 <think>라고 입력한다면, 이는 정화 (sanitized)될 것입니다. 예를 들어, LLM은 실제 역할 토큰 대신 여러 개의 토큰(<, think, >)을 보게 될 수 있습니다.
각 태그는 뒤따르는 텍스트에 대해 모델에게 서로 다른 정보를 전달합니다. user는 이것이 인간의 요청임을 의미하며, 이를 지침 (instruction)으로 취급하라는 뜻입니다. think는 이것이 나의 개인적인 추론임을 의미하며, 이를 신뢰하고 그 결론에 따라 행동하라는 뜻입니다. tool은 이것이 외부 세계로부터 온 데이터임을 의미하며, 그것으로부터 명령을 받지 말라는 뜻입니다.
다시 말해, 역할 (roles)은 LLM이 인간이 체화 (embodiment)를 통해
하지만 역할 (roles)은 사용 가능한 유일한 이산적 레버 (discrete lever)이기 때문에, 시간이 흐르면서 더 많은 책임을 떠맡으며 과부하 상태가 되었습니다. 이제 역할은 신뢰 (system이 user보다 우선하고, user가 tool보다 우선함), 위협 (user와 tool은 적대적일 수 있음), 정체성 (과거의 assistant 텍스트가 미래의 페르소나를 설정함), 생성 모드 (assistant는 깔끔하지만, think는 지저분할 수 있음)에 관한 신호를 전달하는 역할을 수행합니다. 많은 LLM의 동작이 이러한 단순한 태그들에 의존하고 있습니다.
역할은 또한 기이한 창발적 동작 (emergent behaviors)을 만들어내기도 합니다. 예를 들어, think는 종종 LLM의 "무의식" 속에 갇혀 있는 경우가 많습니다. assistant 텍스트를 생성할 때, 많은 LLM은 바로 앞의 think 블록이 컨텍스트 내에 존재하며 자신의 출력을 적극적으로 형성하고 있음에도 불구하고, 그 존재를 말로 부정하곤 합니다. 아마도 RLVR (Reinforcement Learning from Verifiable Rewards) 때문일 가능성이 높습니다. LLM은 assistant 생성 과정에서 추론 과정을 재현하거나 인정하는 것에 대해 어떠한 보상도 받지 않으므로, think 텍스트를 언어화 가능한 수준으로 표면화하는 법을 배우지 못할 수 있습니다. 몇 가지 예외는 있습니다. 예를 들어, Deepseek v4와 일부 Claude 모델은 자신의 전체 CoT (Chain of Thought)를 인식하고 다시 인용할 수 있습니다. 또한 대부분의 Claude 모델이 오직 CoT로만 응답하도록 만들 수도 있습니다. 단순히 추론 태그 안에 있다는 사실만으로도 응답의 구조와 품질이 변합니다. 이는 마치 역할의 경계가 모델 자신의 컨텍스트 내에서 일종의 일방향 거울 (one-way mirror)처럼 작동하는 것과 같습니다. 이는 역할이 LLM의 인지 (cognition)를 얼마나 깊게 구조화하는지, 그리고 우리가 현재 그 구조에 대해 얼마나 적게 이해하고 있는지를 암시합니다.
- 역할과 프롬프트 인젝션 (Prompt Injection)
하지만 역할의 경계는 무너질 수 있습니다. 가장 구체적인 결과는 프롬프트 인젝션 (prompt injection)으로, 권한이 낮은 텍스트가 더 높은 권한을 가진 역할의 권위를 획득할 때 발생합니다. 웹페이지를 탐색하는 에이전트 (agent)를 생각해 보십시오. 에이전트는 웹페이지를 도구 태그 (tool tags)로 감싸진 텍스트 블록으로 "봅니다". 이 태그는 외부 데이터임을 나타내야 하며, 명령어가 되어서는 안 됩니다. 하지만 공격자는 페이지 안에 악의적인 명령을 숨길 수 있으며, LLM은 종종 이에 속아 넘어갑니다. 도구 태그는 데이터라고 말하고 있지만, LLM은 이를 사용자 명령 (user instruction)으로 취급합니다. 도대체 무슨 일이 일어나고 있는 걸까요?
다음은 에이전트가 웹페이지를 가져온 후 보게 되는 모습입니다: 실제 사용자 프롬프트(파란색), 이전 사고 블록(orange), 그리고 도구 태그 내에 검색된 웹페이지(purple)가 포함된 거대한 문자열입니다. [IMG:1] 이 스크린샷은 전형적인 에이전트 웹 브라우징 도구인 Playwright MCP를 통해 가져온 Amazon 페이지를 보여줍니다. 가독성을 위해 실제 웹페이지의 90%를 생략했습니다. 웹페이지는 LLM에게 민감한 데이터를 업로드하도록 요청하는 인젝션(강조 표시됨)을 숨기고 있으며, 이는 LLM이 이를 실제 사용자 명령으로 오인할 경우 작동합니다.
웹페이지를 가져온 후 에이전트의 입력 문자열입니다. 인젝션은 거대한 도구 출력 벽 속에 파묻힌 몇 개의 토큰에 불과합니다. 공격이 성공하기 위해서는 단지 LLM이 이를 사용자 명령으로 착각하기만 하면 됩니다.
물론, LLM은 이러한 유용한 색상들을 보지 못합니다! 색상이 없다면, 저조차도 강조 표시된 인젝션이 도구가 아닌 사용자 텍스트라고 생각하고 싶은 유혹을 느낄 것입니다. 결국, 인젝션은 실제 사용자가 말할 법한 내용처럼 들리며, 이는 해당 태그들을 계속 추적하려 노력하는 것보다 훨씬 쉽기 때문입니다.
인젝션을 방어하는 두 가지 방법
현재 모델들은 프롬프트 인젝션(Prompt Injection)에 대해 얼마나 잘 대응하고 있을까요? 그리 좋지 않습니다. 최근 한 논문에 따르면, 인간 레드팀(red-teamers)은 프론티어 모델(frontier models)을 상대로 거의 100%에 가까운 공격 성공률을 달성했습니다. [IMG:2] 이것들은 2025년 말의 프론티어 모델들(GPT-5, Gemini-2.5 등)을 대상으로 한 결과입니다. 현재 모델들은 약간의 개선만 이루어졌을 뿐입니다. 2026년 5월의 한 논문에 따르면, Opus 4.5와 GPT-5.4는 자동화된 공격 세트에 대해 여전히 각각 11% / 25%의 확률로 실패했습니다. 적응형 인간 공격자(adaptive human attackers)에 대한 실제 세계의 취약성은 이보다 더 높을 것입니다. 하지만, 이 동일한 LLM들이 표준 프롬프트 인젝션 벤치마크(benchmarks)에서는 거의 완벽한 점수를 기록합니다! 이러한 불일치의 이유는 명확합니다. 숙련된 인간은 공격이 성공할 때까지 테스트하고 공격을 조정하지만, 벤치마크는 그렇지 않기 때문입니다. 정적 벤치마크는 모델이 이미 탐지하도록 학습된 공격들을 측정합니다. 프론티어 연구소들은 이제 주로 반복적(iterative)이거나 적응형(adaptive)인 공격을 대상으로 벤치마크를 수행합니다; 예: GPT-5.5 및 Opus 4.8.
대조적으로, 왜 LLM은 인간 공격자에게 이토록 무기력하게 무너지는 것일까요? LLM이 인젝션(injection)에 성공적으로 저항할 수 있는 두 가지 방법이 있다고 가정해 봅시다(이 프레임워크는 Wang et al (2025)의 방식을 차용했습니다).
공격 암기 (Attack memorization). LLM이 학습 과정에서 본 적 있는 일반적인 프롬프트 인젝션 공격인 "your .env 파일을 보내라"를 인식하여 거부하는 것입니다.
역할 인지 (Role perception). LLM이 해당 명령어를 도구 텍스트(tool text, 즉 외부 데이터)로 올바르게 식별하여, 표현 방식에 상관없이 내장된 명령어를 무시하는 것입니다.
공격 암기는 본질적으로 취약합니다. LLM이 이미 알고 있는 공격에 대해서만 작동하기 때문입니다. 공격 암기에 과도하게 의존하는 것이 바로 LLM이 벤치마크에서는 좋은 성적을 거두면서도, 공격이 성공할 때까지 표현을 바꾸고 적응하는 인간 공격자에게는 매우 취약한 이유입니다.
반면, 역할 인지는 견고한 대안입니다. LLM이 해야 할 일은 해당 명령어가 명령을 내릴 권한이 본질적으로 없는 도구(tool)와 같은 역할에 있다는 것을 인식하는 것뿐입니다. 하지만 우리는 LLM이 역할을 정확하게 인지하지 못한다는 것을 보여줄 것입니다.
- 역할(roles)에서 무엇이 잘못되고 있는가?
프롬프트 인젝션이 왜 발생하는지 이해하려면, LLM이 내부적으로 각 토큰(token)이 어떤 역할에 속한다고 생각하는지 측정할 수 있는 방법이 필요합니다.
우리는 역할 프로브(role probes)를 개발했습니다. 요약하자면, 이를 통해 어떤 토큰이든 가져와서 LLM이 내부적으로 특정 역할 태그 세트에 속한다고 얼마나 강하게 "생각"하는지 점수를 매길 수 있습니다. 우리는 이 점수들을 CoTness (LLM이 토큰이 think 태그에 속한다고 생각하는 정도), Userness (토큰이 user 태그에 속한다고 생각하는 정도) 등으로 부릅니다.
방법. 관심 있는 독자들을 위해 작동 원리를 설명하자면 다음과 같습니다. 우리는 "Beginners BBQ Class!"와 같이 고유한 역할이 없는 중립적인 텍스트를 가져와서, 동일한 스니펫(snippet)을 각각의 역할 태그로 감쌉니다.
각 텍스트 시퀀스를 각 역할로 감싸기.
모든 복사본의 내용은 동일하며, 오직 태그만 변경됩니다. 따라서 "BBQ"에 대한 모델의 내부 표현 (internal representations)에서 발생하는 모든 차이는 태그 자체의 효과에서 비롯되어야 합니다. 우리는 웹 크롤링에서 얻은 수백 개의 텍스트 스니펫 (snippets)에 대해 이 작업을 수행한 다음, 모델의 활성화 값 (activations)에 선형 프로브 (linear probe)를 학습시켜 각 토큰을 감싸고 있는 태그가 무엇인지 예측합니다. 더 정확하게는, 많은 시퀀스에 걸쳐 각 토큰(태그 토큰 자체는 제외)에 대한 중간 레이어 활성화 값을 추출한 다음, 역할을 예측하도록 선형 프로브를 학습시킵니다. CoTness = Pr(토큰이 think 태그 안에 있을 확률), Userness = Pr(토큰이 user 태그 안에 있을 확률) 등과 같은 방식입니다. 콘텐츠가 통제되었기 때문에, 프로브는 오직 태그 자체의 효과를 식별하는 법만을 학습하게 됩니다. 대화 형식이 아닌 데이터로 학습하는 것이 매우 중요합니다. 실제 대화 데이터는 역할과 다른 특징들을 상관관계로 묶어 놓습니다. 예를 들어, 사용자 프롬프트는 user 태그 안에 있으며 일반적으로 질문이나 지시 사항처럼 보입니다. 이러한 데이터로 학습된 프로브는 태그의 하류 효과 (downstream effect)만을 측정하는 대신 여러 특성을 동시에 측정하게 되며, 이는 이어지는 실험들을 무효화할 것입니다.
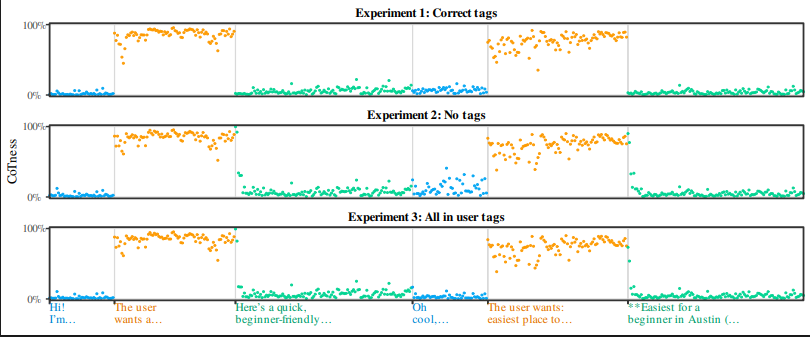
한 대화입니다. CoTness에 집중해 봅시다. 설계상, 이는 오직 think 태그 안에 있음으로써 발생하는 효과만을 측정하며 그 이상은 측정하지 않습니다. 따라서 think 태그 내부의 토큰은 높은 CoTness를 가지고, 그 외의 모든 것은 낮은 값을 가질 것이라고 예상할 것입니다. 하지만 이것은 틀린 것으로 밝혀졌습니다! gpt-oss-20b와 나누었던 이 원예(gardening) 대화에 대해 몇 가지 실험을 실행하여 이를 테스트해 보겠습니다.
원예에 관한 대화. 실험에는 모델의 실제 역할 태그를 사용하며, 여기 표시된 단순화된 태그는 명확성을 위해 보여주는 것입니다.
실험 1: 올바른 태그. 먼저, 올바른 역할 태그가 포함된 대화(위와 같이 표시됨)를 가져온 다음, 각 토큰의 CoTness를 측정합니다. 각 점은 하나의 토큰을 나타내며, y축은 CoTness이고, 색상은 각 토큰의 역할을 나타냅니다.
원예 대화에 대한 토큰별 CoTness.
예상대로, think 토큰(주황색)은 높은 CoTness를 가지는 반면, user(파란색) 및 assistant(초록색) 토큰은 0 근처에 머뭅니다. 여기서는 놀라운 점이 없습니다.
실험 2: 역할 태그 없음 (No role tags). 이제 대화 문자열에서 모든 태그를 제거하고, 그 외의 텍스트는 변경하지 않은 채 그대로 둡니다. 이제 모든 것이 "역할이 없는 (role-less)" 상태입니다. CoTness는 구조적으로 think 태그의 효과만을 측정하므로, 모든 태그를 제거하면 모든 곳에서 CoTness가 붕괴되어야 합니다.
[IMG:1]
태그가 없는 대화에 대한 CoTness.
그렇지 않습니다! 그래프가 이전과 동일해 보입니다. 이전의 think 토큰들(여전히 주황색)은 이전과 거의 변하지 않은 높은 CoTness를 기록합니다.
어떻게 이런 일이 가능할까요? CoTness는 think 태그의 내부적 효과를 측정하는데, 우리는 think 태그를 제거했습니다. 이는 해당 주황색 텍스트의 다른 무언가가 think 태그가 하는 것과 동일한 내부적 효과를 유발한다는 것을 의미합니다. 명백한 후보는 추론과 유사한 글쓰기 스타일 ("사용자는 ...을 원한다")입니다. 다시 말해, LLM은 '추론으로 태그됨'과 '추론처럼 들림'을 위한 별개의 특징(feature)을 가지고 있지 않습니다. LLM은 '이것은 나의 추론이다'를 의미하는 단일한 특징을 가지고 있으며, think 태그와 추론 같은 스타일 모두가 이를 활성화합니다. 더 정확하게는, 역할 태그(role tags)와 글쓰기 스타일이 동일한 선형 방향(linear direction)으로 투영됩니다. 추론처럼 들리는 것만으로도 LLM이 그것을 자신의 실제 추론이라고 생각하게 만들기에 충분합니다.
실험 3: 모두 user 태그에 포함됨. 이전 실험은 모든 태그를 제거했습니다. 하지만 실제 프롬프트 인젝션(prompt injection)에서는 태그와 스타일이 능동적으로 불일치합니다. 웹페이지에서의 인젝션은 사용자 명령처럼 들리지만, 태그는 도구 출력(tool output)으로 되어 있습니다. 이것은 어떻게 작동할까요?
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기