쿼리 구성 (Query Construction)
요약
자연어 사용자 인터페이스(LUI)를 통해 정형, 반정형, 비정형 데이터를 효과적으로 검색하기 위한 '쿼리 구성(Query Construction)'의 개념과 중요성을 다룹니다. 단순한 벡터 유사도 검색을 넘어, 데이터의 구조적 특성에 맞춰 자연어를 SQL이나 Graph 쿼리 등 적절한 구문으로 변환하는 전략을 설명합니다.
핵심 포인트
- 데이터 유형(정형, 반정형, 비정형)에 따라 쿼리 구성 시 고려해야 할 과제가 다름
- 정형 데이터는 스키마와 관계를 활용한 정밀한 연산이 필요함
- 비정형 데이터 검색 시에도 정형 메타데이터를 활용한 필터링이 중요함
- 쿼리 구성은 자연어 쿼리를 대상 데이터베이스의 특정 쿼리 언어로 변환하는 과정임
- 효과적인 검색을 위해서는 의미론적 검색과 구조적 필터링을 결합해야 함
주요 링크
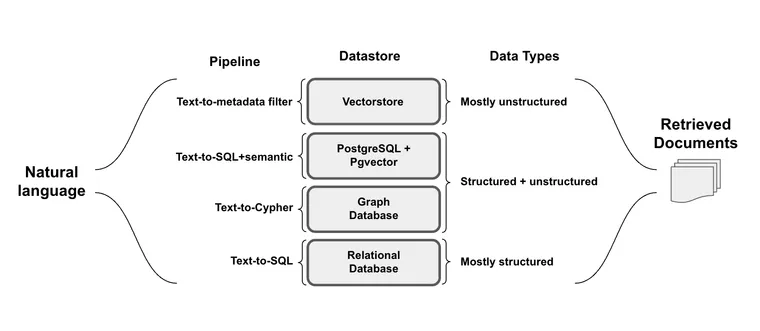
자연어(Natural Language)를 다양한 유형의 데이터(정형, 비정형, 반정형)와 원활하게 연결하는 것에 대한 관심이 매우 높습니다. 하지만, 새롭게 등장하는 이 "LUI" (언어 사용자 인터페이스, Language User Interface)는 각 데이터 유형별로 특정한 과제와 고려 사항을 가지고 있습니다.
정형 데이터 (Structured Data): 주로 SQL 또는 Graph 데이터베이스 내에 저장되며, 정형 데이터는 미리 정의된 스키마 (Schema)를 특징으로 하고 테이블이나 관계(Relation)로 조직되어 있어 정밀한 쿼리 연산에 적합합니다.
반정형 데이터 (Semi-structured Data): 반정형 데이터는 정형 요소(예: 문서 내의 테이블 또는 관계형 데이터베이스의 테이블)와 비정형 요소(예: 텍스트 또는 관계형 데이터베이스의 임베딩 (Embedding) 컬럼)가 혼합된 형태입니다.
비정형 데이터 (Unstructured Data): 일반적으로 벡터 데이터베이스 (Vector Database)에 저장되는 비정형 데이터는 미리 정의된 모델이 없는 정보로 구성되며, 필터링을 가능하게 하는 정형 메타데이터 (Metadata)가 동반되는 경우가 많습니다.
이러한 과제를 해결하기 위해, LLM (Large Language Models)은 각 데이터 유형에 맞는 특정 쿼리 구문 (Query Syntax)으로 자연어를 변환하는 과정인 **쿼리 구성 (Query Construction)**에 탁월한 능력을 갖추고 있습니다. 고급 검색 (Advanced Retrieval)에 관한 저희 블로그 시리즈의 세 번째 게시물인 이번 글에서는 **쿼리 구성 (Query Construction)**을 위한 다양한 전략을 다룰 예정입니다 (더 자세한 내용은 다중 표현 인덱싱 (Multi-Representation Indexing) 및 **쿼리 변환 (Query Transformation)**에 관한 저희 블로그 게시물을 참조하세요).
쿼리 구성 (Query Construction)이란 무엇인가?
전형적인 검색 증강 생성 (RAG, Retrieval Augmented Generation) 방식에서는 사용자 쿼리가 벡터 표현 (Vector Representation)으로 변환됩니다. 그런 다음 이 벡터를 소스 문서의 벡터 표현과 비교하여 가장 유사한 문서를 찾습니다. 이는 비정형 데이터에 대해서는 상당히 잘 작동하지만 (저희의 다중 표현 인덱싱 (Multi-Representation Indexing) 및 쿼리 변환 (Query Transformation) 블로그 게시물 참조), 정형 데이터의 경우는 어떨까요?
세상의 대부분 데이터는 어느 정도의 구조를 가지고 있습니다. 이러한 데이터의 상당 부분은 관계형 (예: SQL) 또는 그래프 (Graph) 데이터베이스에 존재합니다. 그리고 비정형 데이터조차도 종종 정형 메타데이터 (예: 저자, 장르, 발행 데이터 등)와 연관되어 있습니다.
💡
많은 사용자 쿼리는 임베딩 공간 (embedding space)에서 유사한 문서나 데이터를 찾는 것뿐만 아니라, 데이터에 내재되어 있고 사용자 쿼리에 표현된 구조를 활용할 때 가장 잘 답변될 수 있습니다.
예를 들어, 1980년도의 외계인에 관한 영화는 무엇인가라는 쿼리를 생각해 보십시오.
여기에는 의미론적 (semantically)으로 찾아보고 싶은 부분(외계인)이 있는 동시에, 정확한 (exact) 방식으로 찾아보고 싶은 구성 요소("year == 1980")도 존재합니다.
💡
쿼리 구성 (Query construction)이란 자연어 쿼리를 사용자가 상호작용하고 있는 데이터베이스의 쿼리 언어로 변환하는 것을 의미합니다.
아래에서는 쿼리 구성의 몇 가지 사례를 강조하고, 각 사례에 대한 관련 쿡북 (cookbooks), 템플릿 및 문서를 제공합니다.
예시 (Examples)
데이터 소스 (Data source)
참조 (References)
텍스트-메타데이터-필터 (Text-to-metadata-filter)
벡터 저장소 (Vectorstores)
텍스트-SQL (Text-to-SQL)
SQL DB
텍스트-SQL+ 의미론적 (Text-to-SQL+ Semantic)
PGVector를 지원하는 SQL DB
텍스트-Cypher (Text-to-Cypher)
그래프 데이터베이스 (Graph databases)
텍스트-메타데이터-필터 (Text-to-metadata-filter)
메타데이터 필터링 (metadata filtering) 기능이 갖춰진 벡터 저장소 (Vectorstores)를 사용하면, 임베딩된 비정형 문서들을 필터링하기 위한 구조화된 쿼리 (structured queries)를 실행할 수 있습니다. 셀프 쿼리 리트리버 (self-query retriever)는 몇 가지 단계를 거쳐 자연어 쿼리를 이러한 구조화된 쿼리로 변환할 수 있습니다.
데이터 소스 정의 (Data Source Definition): 셀프 쿼리 리트리버의 핵심은 관련 메타데이터 필드에 대한 명확한 사양에 기반합니다 (예: 노래 검색의 맥락에서는 아티스트, 길이, 장르 등이 될 수 있습니다).
사용자 쿼리 해석 (User Query Interpretation): 자연어 질문이 주어지면, 셀프 쿼리 리트리버는 (의미론적 검색을 위한) 쿼리와 메타데이터 필터링을 위한 필터를 분리합니다. 예를 들어, 3분 미만의 댄스 팝 장르이면서 테일러 스위프트 또는 케이티 페리의 십 대 로맨스에 관한 노래라는 쿼리는 필터와 쿼리로 분해됩니다.
논리 조건 추출 (Logical Condition Extraction): 필터 자체는 벡터 저장소에 정의된 비교 연산자 및 연산자로부터 만들어집니다 (예: '같음'을 의미하는 eq 또는 '작음'을 의미하는 lt 등).
보다 작음(lt).
구조화된 요청 형성 (Structured Request Formation): 마지막으로, 셀프 쿼리 리트리버 (self-query retriever)는 의미론적 검색어 (query)와 문서 검색 프로세스를 효율화하는 논리적 조건 (filter)을 분리하여 구조화된 요청을 조립합니다.
사용자의 질문을 입력받아 필요한 필터를 캡슐화한 StructuredQuery 객체를 반환하는 위 단계들을 실행하기 위한 체인 (chain)을 정의할 수 있습니다:
# 프롬프트 생성 및 출력 파싱
prompt = get_query_constructor_prompt(document_content_description, metadata_field_info)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
# 샘플 쿼리로 쿼리 생성기 호출
query_constructor.invoke({
"query": "Songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre"
})
구조화된 요청은 다음과 같은 형태가 됩니다:
{
"query": "teenager love",
"filter": "and(or(eq("artist", "Taylor Swift"), eq("artist", "Katy Perry")), lt("length", 180), eq("genre", "pop"))"
}
이러한 접근 방식은 벡터 데이터베이스 (vector databases)와 상호작용할 때 RAG 답변 품질을 크게 향상시킬 수 있습니다. 왜냐하면 사용자 질문에서 직접 추론된 논리적 필터 조건이 최종 답변 합성을 위해 LLM에 전달되는 텍스트 청크 (text chunks)를 제어하기 때문입니다.
더 읽어보기:
- Docs: Self-querying retriever
- Template: Self-query Supabase vector db
- Template: Self-query Elastic vector db
Text-to-SQL
데이터 연속체 (data continuum)의 반대편에서는, SQL / 관계형 데이터베이스 (relational databases)가 매우 구조화된 데이터의 중요한 소스입니다. 자연어를 SQL 요청으로 변환하는 데 상당한 노력이 집중되어 왔으며, 다음과 같은 몇 가지 주목할 만한 과제들이 있습니다:
환각 (Hallucination): LLM은 존재하지 않는 테이블이나 필드를 만들어내는 '환각 (Hallucination)' 현상을 일으키기 쉬우며, 이로 인해 유효하지 않은 쿼리를 생성할 수 있습니다. 이를 해결하기 위한 접근 방식은 LLM이 실제 데이터베이스 스키마 (Schema)와 일치하는 유효한 SQL을 생성하도록 현실에 기반(grounding)을 두어야 합니다.
사용자 오류 (User errors): Text-to-SQL 접근 방식은 유효하지 않은 쿼리를 초래할 수 있는 사용자의 철자 오류나 입력값의 기타 불규칙성에 대해 견고해야 (robust) 합니다.
이러한 과제들을 염두에 두고 몇 가지 기법들이 등장했습니다:
데이터베이스 설명 (Database Description): SQL 쿼리의 근거를 마련하기 위해, LLM에는 데이터베이스에 대한 정확한 설명이 제공되어야 합니다. 일반적인 Text-to-SQL 프롬프트 중 하나는 여러 논문에서 보고된 아이디어를 채택합니다. 즉, LLM에 각 테이블에 대한 CREATE TABLE 설명을 제공하여 컬럼 이름, 데이터 타입 등을 포함하게 하고, 그 뒤에 SELECT 문 형태의 예시 데이터 3행을 덧붙이는 방식입니다.
퓨샷 예시 (Few-shot examples): 질문과 쿼리가 매칭된 퓨샷 (Few-shot) 예시를 프롬프트에 입력하면 쿼리 생성 정확도를 높일 수 있습니다. 이는 에이전트가 질문을 바탕으로 쿼리를 어떻게 구축해야 하는지 안내할 수 있도록, 프롬프트에 표준적인 정적 예시를 단순히 추가함으로써 달성할 수 있습니다.
오류 처리 (Error Handling): 오류에 직면했을 때 데이터 분석가들은 포기하지 않고 반복 (iterate)합니다. 우리는 SQL 에이전트 (SQL agents)와 같은 도구를 사용하여 오류로부터 복구할 수 있습니다.
고유 명사의 철자 오류 찾기: 이름과 같은 고유 명사를 쿼리할 때, 사용자는 의도치 않게 잘못된 철자를 작성할 수 있습니다 (예: Franc Sinatra). 우리는 에이전트가 SQL 데이터베이스 내 관련 고유 명사의 올바른 철자를 저장하고 있는 벡터 스토어 (vectorstore)를 대상으로 고유 명사를 검색할 수 있도록 허용할 수 있습니다.
더 읽어보기:
- Docs: QA over structured data
- Blog: LLMs and SQL
- Blog: Incorporating domain specific knowledge in SQL-LLM solutions
Text-To-SQL+semantic
데이터 연속체 (data continuum)의 중간 단계에서는 혼합 유형 (mixed type, 구조화된 데이터 및 비구조화된 데이터) 데이터 저장 방식이 점점 더 흔해지고 있습니다. 관계형 데이터베이스 (relational databases)에 벡터 지원을 추가하는 것은 하이브리드 검색 (hybrid retrieval)을 지원하는 접근 방식의 핵심적인 동력입니다 (최근 AI Engineer summit의 영상을 여기서 확인하세요). 특히, PostgreSQL을 위한 오픈 소스 확장 기능인 pgvector는 SQL의 표현력과 시맨틱 검색 (semantic search)이 제공하는 미묘한 의미론적 이해를 결합합니다. Pgvector는 Pinecone과 같은 벡터 스토어 (vectorstores)와 비교했을 때 유리한 성능과 비용을 보고했습니다.
Pgvector를 사용하면 임베딩 (embeddings) 벡터 컬럼에 대해 유사도 검색 (similarity search, 예: 코사인 (cosine), L2 거리 (L2 distance), 내적 (inner product))을 실행할 수 있습니다. <-> 연산자를 사용합니다:
SELECT * FROM tracks ORDER BY "name_embedding" <-> {sadness_embedding}
위의 쿼리에서 LIMIT 3를 사용하여 상위 3개의 가장 슬픈 트랙을 가져올 수 있으며 (표준 kNN의 top_k 값과 유사함), 가장 슬픈 곡 하나와 왠지 모를 이유로 90번째 및 50번째 백분위수(percentile)를 선택하는 것과 같은 더 복잡한 연산도 가능합니다. 이는 두 가지 중요한 새로운 기능을 가능하게 합니다:
- 벡터 스토어로는 불가능한 시맨틱 검색 (semantic searches)을 수행할 수 있습니다.
- 시맨틱 연산자 (semantic operator)에 대한 지식을 통해 Text-to-SQL을 강화할 수 있습니다. 예를 들어, 텍스트-시맨틱 검색 (text-to-semantic searches, 예: 특정 감정을 전달하는 제목을 가진 노래 찾기)과 SQL 쿼리 (예: 장르별 필터링)를 가능하게 합니다.
앨범-곡 예시에 이어, 이 접근 방식을 사용하면 특정 감정과 일치하는 노래가 가장 많은 앨범을 찾거나 (표형 데이터 (tabular data)에 대한 필터 또는 카운트로 시맨틱 유사성을 사용), "lovely"라는 제목을 가진 앨범에서 슬픈 노래를 찾을 수 있습니다 (메타데이터 필터링을 사용하는 벡터 데이터베이스로는 불가능한, 두 개의 시맨틱 검색을 하나의 단일 쿼리로 결합).
더 읽어보기:
Text-to-Cypher
벡터 저장소(Vector stores)는 비정형 데이터(Unstructured data)를 손쉽게 처리하지만, 벡터 간의 관계를 이해하지는 못합니다. 반면 SQL 데이터베이스는 관계를 모델링할 수 있지만, 스키마(Schema) 변경이 중단적이고 비용이 많이 들 수 있습니다. 지식 그래프(Knowledge graphs)는 데이터 간의 관계를 모델링하고, 대대적인 개편 없이도 관계의 유형을 확장함으로써 이러한 과제들을 해결할 수 있습니다. 지식 그래프는 표 형식(Tabular form)으로 표현하기 어려운 다대다(Many-to-many) 관계나 계층 구조(Hierarchies)를 가진 데이터에 적합합니다.
관계형 데이터베이스가 흔히 SQL을 사용하는 것처럼, 그래프 데이터베이스는 패턴과 관계를 시각적인 방식으로 매칭하도록 설계된 Cypher라는 특정 쿼리 언어(Query language)를 자주 사용합니다. 이는 다음과 같은 ASCII 아트 형태의 구문을 기반으로 합니다:
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})
이 패턴은 Person이라는 레이블(Label)과
Tomaz라는 이름 속성(Name property)을 가진 노드(Node)가
Slovenia라는
국가(Country) 노드와 LIVES_IN 관계를 맺고 있음을 설명합니다. 위의 예시와 같이, Text-to-Cypher는 자연어를 Cypher 쿼리로 번역할 수 있습니다:
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)
유효한 Cypher를 생성하는 것은 복잡한 작업이 될 수 있으므로, cypher_llm으로서 GPT-4와 같이 성능이 뛰어난 LLM(Large Language Model)을 사용하는 것을 권장합니다. 위에서 보여준 것처럼, 그 후에는 자연어로 질문을 던질 수 있습니다.
cypher_chain.run(
"How many open tickets there are?"
)`
문서 보기
- 블로그: DevOps RAG 애플리케이션 구현을 위한 지식 그래프 사용법 (Using a Knowledge Graph to implement a DevOps RAG application)
- 블로그: Neo4j를 이용한 고급 RAG 전략 구현 (Implementing advanced RAG strategies with Neo4j)
- 문서: Neo4j DB QA 체인 (Neo4j DB QA chain)
결론 (Conclusion)
다양한 데이터 소스에 걸쳐 구조화된 데이터 (structured data)와 비구조화된 데이터 (unstructured data)를 원활하게 검색하는 것은 LLM (Large Language Models)의 잠재력을 끌어내는 데 매우 중요합니다. 우리는 다양한 유형의 데이터 저장소 (datastores)를 위해 등장한 네 가지 인기 있는 "자연어-to-구조화된 쿼리 (natural-language-to-structured query)" 파이프라인을 요약하고, 사용자가 시작할 수 있도록 템플릿과 쿡북 (cookbooks)을 제공합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기