
추출 벤치마킹 (Extraction Benchmarking)
요약
LangChain이 채팅 로그에서 구조화된 정보를 추출하는 LLM의 능력을 측정하기 위한 새로운 'Chat Extraction' 데이터셋을 공개했습니다. 이 데이터셋은 비구조화된 텍스트 분류 및 기계 판독 가능한 정보 생성 능력을 테스트하여 LLM 애플리케이션 개발의 실질적인 도전 과제를 다룹니다.
핵심 포인트
- 채팅 로그로부터 구조화된 통찰을 얻기 위한 새로운 벤치마크 데이터셋 공개
- 비구조화된 텍스트 분류 및 방해 정보 속 추론 능력 테스트 가능
- 분석 대시보드 구축 및 미세 조정 데이터 수집 파이프라인 활용 목적
- 데이터 모델 결정, 시드 생성, LLM 후보 답변 생성 및 수동 검토 과정을 통해 제작
2주 전, 저희는 LangChain 문서에 대한 Q&A 데이터셋과 함께 langchain-benchmarks 패키지를 출시했습니다. 오늘 저희는 채팅 로그로부터 올바른 구조화된 정보 (structured information)를 추론하는 LLM의 능력을 측정하는 새로운 추출 (extraction) 데이터셋을 공개합니다.
이 새로운 데이터셋은 비구조화된 텍스트 (unstructured text) 분류, 기계 판독 가능한 정보 (machine-readable information) 생성, 그리고 방해 정보가 포함된 상태에서 여러 작업을 추론 (reasoning)하는 것과 같이 LLM 애플리케이션 개발에서 흔히 발생하는 도전 과제들을 테스트할 수 있는 실질적인 환경을 제공합니다.
이 포스트의 나머지 부분에서는 저희가 이 데이터셋을 어떻게 만들었는지 설명하고 초기 벤치마크 결과를 공유하겠습니다. 여러분의 대화형 앱 개발에 이 내용이 유용하기를 바라며, 여러분의 피드백을 기다리겠습니다!
데이터셋 제작 동기
저희는 챗봇 상호작용으로부터 구조화된 통찰 (structured insights)을 얻어내는 것과 같은 실제 세계의 문제를 중심으로 데이터셋 스키마 (schema)를 설계하고자 했습니다.
이번 여름, 저희의 훌륭한 인턴인 Molly는 LangChain의 Python 문서에 대한 검색 증강 생성 (RAG, retrieval-augmented generation) 애플리케이션인 Chat LangChain (repo)을 개선하는 것을 도와주었습니다. 이것은 "검색 엔진을 갖춘 LLM"이므로, "에이전트 (agent)에 메모리를 어떻게 추가하나요?"와 같은 질문을 던지면 문서에서 찾을 수 있는 내용을 바탕으로 답변을 제공합니다.
이러한 프로젝트의 진정한 테스트는 배포 후에 시작되며, 사용자가 어떻게 사용하는지 관찰하고 이를 더욱 개선하기 시작할 때 이루어집니다. 일반적으로 사용자는 명시적인 피드백을 제공하지 않지만, 그들의 대화는 많은 것을 드러냅니다. 단순히 "로그를 LLM에 넣어서" 요약할 수도 있지만, 모니터링 및 분석을 위해 구조화된 콘텐츠를 추출함으로써 이점을 얻는 경우가 많습니다. 구조화된 값은 전통적인 소프트웨어에서 쉽게 사용될 수 있으므로, 이는 분석 대시보드를 구동하거나 미세 조정 (fine-tuning) 데이터 수집 파이프라인을 추진하는 데 도움이 될 수 있습니다.
Chat Extraction 데이터셋은 오늘날의 LLM들이 이러한 유형의 데이터로부터 관련 정보를 얼마나 잘 추출하고 분류할 수 있는지 테스트하도록 설계되었습니다. 다음 섹션에서는 저희가 데이터셋을 어떻게 생성했는지 설명하겠습니다. 결과만 확인하고 싶다면 아래의 요약 그래프를 참조하세요. 결과 분석을 위해 실험(experiments) 섹션으로 바로 이동하셔도 좋습니다.
데이터셋 생성 (Creating the Dataset)
데이터셋 생성의 주요 단계는 다음과 같습니다:
- 구조화된 출력 (structured output)을 나타낼 데이터 모델 결정
- Q&A 쌍을 통한 시드 (seed) 생성
- LLM을 사용하여 후보 답변 생성
- 어노테이션 큐 (annotation queue)에서 결과를 수동으로 검토하고, 필요한 경우 분류 체계 (taxonomy) 업데이트
LangChain은 초기 데이터를 부트스트랩 (bootstrap)할 수 있도록 돕는 합성 데이터셋 생성 (synthetic dataset generation) 유틸리티를 오랫동안 제공해 왔지만, 최종 버전은 적절한 품질을 보장하기 위해 항상 어느 정도의 인간 검토를 포함해야 합니다. 이것이 저희가 LangSmith에 데이터 어노테이션 큐를 추가한 이유이며, 여러분이 데이터 플라이휠 (data flywheel)을 구축할 수 있도록 도구를 지속적으로 개선해 나갈 것입니다.
초기 데이터셋을 확보하면, 레이블이 지정된 데이터를 시드 생성 모델 내의 퓨샷 예시 (few-shot examples)로 사용하여 인간이 검토할 데이터의 품질을 높일 수 있습니다. 이는 정답 (ground truth)을 업데이트할 때 필요한 작업량과 변경 사항을 줄이는 데 도움이 될 수 있습니다.
추출 스키마 (Extraction Schema)
저희는 이 작업이 다루기 쉬우면서도(tractable), 오늘날의 많은 일반적인 모델들에게는 여전히 도전 과제가 되기를 원했습니다. 저희는 연결된 이 Pydantic 모델을 사용하여 스키마를 정의했습니다. 추출된 값의 예시는 다음과 같습니다:
{
"GenerateTicket": {
"question": {
"toxicity": 0,
"sentiment": "Neutral",
"is_off_topic": false,
"question_category": "Function Calling",
"programming_language": "unknown"
},
"response": {
"response_type": "provide guidance",
"confidence_level": 5,
"followup_actions": [
"Check with API provider for function calling support."
]
},
"issue_summary": "Function Calling Format Validation"
}
}
}
추출된 출력 예시
이러한 값들 중 상당수는 실제 운영 중인 챗봇 (Chat bot)을 모니터링하는 데 유용할 수 있습니다. 우리는 모델의 역량 (Capacity)과 기능 (Functionality)을 더 효과적으로 구분하여 벤치마크 결과의 유용성을 높이기 위해 스키마 (Schema)를 몇 가지 방식으로 까다롭게 설계했습니다. 이 스키마의 도전 과제는 다음과 같습니다:
- 상당히 긴 몇 가지 열거형 (Enum) 값을 포함합니다. OpenAI의 함수 호출 (Function calling)/도구 사용 (Tool usage) API조차도 이를 생성할 때 불완전할 수 있습니다.
- 객체가 중첩 (Nested)되어 있습니다. 중첩은 LLM이 코드 (Code) 학습을 하지 않은 경우 일관성을 유지하기 어렵게 만들 수 있습니다.
- 각 중첩된 구성 요소의 값은 입력(응답 또는 질문)의 해당 섹션에서만 추론되도록 설계되었습니다.
- 분류 (Classification), 요약 (Summarization), 그리고 구조화된 출력 생성 (Structured output generation)을 하나의 작업에 결합했습니다.
"Attention is all you need"라면, 모델의 주의력 (Attention)을 분산시킴으로써, 이 다중 작업 목표 (Multi-task objective)는 LLM이 단 한 번의 생성으로 해결하기에 어려울 수 있습니다.
평가 (Evaluation)
이 벤치마크는 구조와 분류에 초점을 맞추고 있으므로, LLM-as-a-judge 지표를 사용할 필요가 없습니다. 대신, 우리는 커스텀 LangSmith 평가기 (Evaluators)를 작성했습니다 (코드 정의는 여기서 확인 가능합니다). 아래는 우리가 측정한 항목들입니다:
-
구조 검증 (Structure verification)
json_schema: 올바르면 1, 그렇지 않으면 0. 작업 스키마를 사용하여 각 모델의 파싱된 출력을 검증합니다. -
분류 작업 (Classification tasks)
question_category: 25개의 유효한 열거형 (Enum) 값에 대한 분류 정확도 (Classification accuracy).
off_topic_similarity: LLM이 질문을 주제에서 벗어난 것으로 간주했는지에 대한 이진 분류 (Binary classification) 정확도.
toxicity_similarity: 사용자 질문의 예측된 "독성 (Toxicity)" 수준의 정규화된 차이.
programming_language_similarity: 사용자의 질문이 참조하는 예측된 프로그래밍 언어의 분류 정확도. 대부분의 경우 이는 "unknown"입니다.
confidence_level_similarity: 응답의 예측된 "신뢰도 (Confidence)"와 레이블이 지정된 신뢰도 사이의 정규화된 유사도.
sentiment_similarity -
예측값과 레이블 사이의 정규화된 차이. 감성 (Sentiment)은 부정/중립/긍정의 경우 0/1/2로 점수가 매겨집니다.
-
전체 차이
json_edit_distance
: 이는 예측된 JSON과 레이블 JSON을 먼저 정규화(canonicalize)한 다음, 두 직렬화된 형태 사이의 Damerau-Levenshtein 문자열 거리 (string distance)를 계산하는 일종의 포괄적인 지표입니다.
실험 (Experiments)
이 데이터셋을 제작하면서, 우리는 몇 가지 질문에 답하고자 했습니다:
- 가장 인기 있는 폐쇄형 (closed-source) LLM들은 서로 어떻게 비교되는가?
- 기성 (off-the-shelf) 오픈 소스 LLM들은 폐쇄형 모델들과 비교했을 때 얼마나 잘 작동하는가?
- 단순한 프롬프팅 (prompting) 전략이 추출 성능을 향상시키는 데 얼마나 효과적인가?
- 유효한 레코드를 출력하도록 LLM의 문법 (grammar)을 제어할 경우, 개별 분류 지표에 미치는 영향은 얼마나 큰가?
우리는 다음과 같은 LLM들을 평가했습니다:
gpt-4-1106-preview
최근에 출시된 GPT-4의 롱 컨텍스트 (long-context), 증류 (distilled) 버전입니다.
claude-2
- Anthropic의 LLM입니다.
llama-v2-34b-code-instruct
- 지시어 데이터셋 (instruction dataset)으로 미세 조정 (fine-tuned)된 Code Llama 2의 34b 파라미터 변형 모델입니다.
llama-v2-chat-70b
- 채팅을 위해 미세 조정된 Llama 2의 70b 파라미터 변형 모델입니다.
yi-34b-200k-capybara
- Nous Research의 34b 파라미터 모델입니다.
실험 1: GPT vs. Claude
우리는 먼저 둘 다 폐쇄형 LLM인 Claude-2와 GPT-4를 비교했습니다. GPT-4의 경우, JSON 스키마 (schema)를 제공하여 내용을 채울 수 있게 해주는 도구 호출 (tool-calling) API를 사용했습니다. Anthropic은 아직 유사한 도구 호출 API를 출시하지 않았기 때문에, 스키마를 지정하는 두 가지 다른 방법을 테스트했습니다:
- JSON 스키마로 직접 지정.
- XSD (XML 스키마)로 지정.
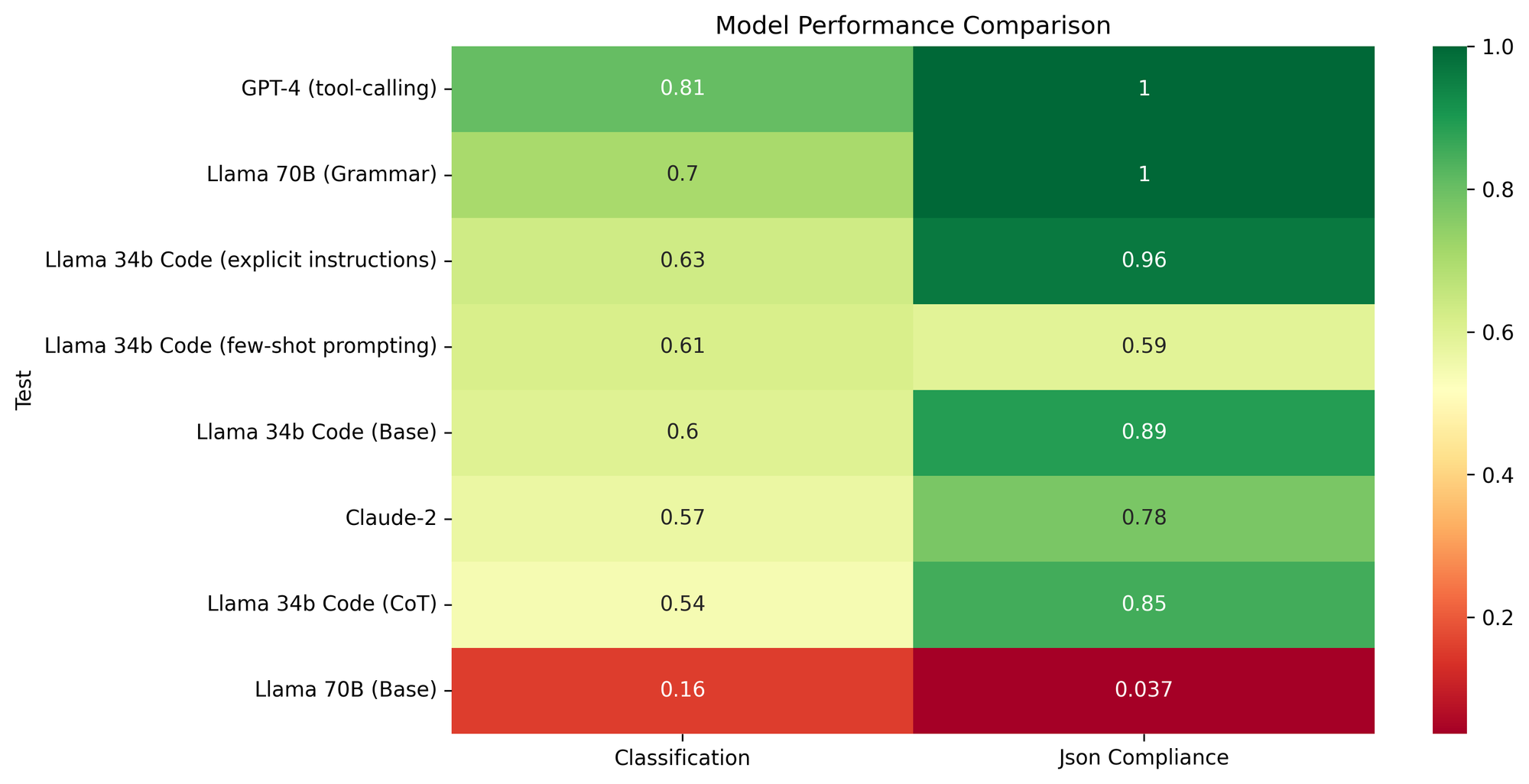
연결된 테스트에서 개별 예측값들을 나란히 검토할 수 있습니다. 또한 아래의 요약 그래프와 표도 확인할 수 있습니다:
GPT-4와 Claude 비교
| 테스트 (Test) | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|
| 0.97 | 0.39 | 0.52 | 0.00 | 0.52 | 0.37 | 0.91 | 1.0 | |
| 0.97 | 0.37 | 0.78 | 0.00 | 0.44 | 0.48 | 0.93 | 1.0 | |
| 0.94 | 0.28 |
1.00
0.89
0.59
0.56
1.00
0.0
예상대로 GPT-4가 거의 모든 지표에서 더 나은 성능을 보였으며, Claude의 경우 단 한 번의 시도(single shot)만으로는 원하는 스키마 (schema)를 완벽하게 출력하도록 만드는 데 실패했습니다. 흥미롭게도, JSON 스키마 (JSON schema)로 프롬프트를 작성한 Claude 모델이 동일한 정보를 XSD (XML schema)로 제공했을 때보다 약간 더 나은 성능을 보였는데, 이는 적어도 이번 사례에서는 스키마의 일관된 형식이 그리 중요하지 않음을 나타냅니다.
몇 가지 공통적인 스키마 이슈를 쉽게 확인할 수 있습니다. 예를 들어, 이번 실행과 저번 실행에서 모델은 후속 조치 (follow-up actions)를 적절히 태깅된 요소 (elements) 대신 불렛 포인트 리스트로 출력했으며, 이는 리스트 (list)가 아닌 문자열 (string)로 파싱되었습니다. 이에 대한 예시 이미지는 다음과 같습니다:

이러한 파싱 (parsing) 오류를 사례별로 수정할 수는 있지만, 예측 불가능성은 전반적인 개발 경험을 저해합니다. 파서 (parser) 및 기타 동작의 일관성이 떨어지기 때문에, 하나의 추출 체인 (extraction chain)을 다른 작업에 맞게 조정하는 데 더 많은 오버헤드 (overhead)가 발생합니다. 또한 XML 구문 (syntax)은 GPT 대비 Claude의 전체 토큰 (token) 사용량을 증가시킵니다.
0.41
0.30
0.43
0.04
0.30
0.15
0.04
0.30
0.00
0.93
0.41
0.89
0.89
0.44
0.07
0.59
1.00
모델 크기가 더 컸음에도 불구하고, Llama 2의 70B 변형 모델은 사전 학습(pretraining) 및 SFT 코퍼스에 포함된 코드 양이 적었기 때문에 JSON을 안정적으로 출력하지 못했습니다. Yi-34b가 이 면에서는 더 신뢰성이 높았지만, 여전히 필요한 스키마를 충족하는 경우는 37%에 불과했습니다. 또한 question_category 분류와 같은 가장 어려운 분류 작업에서도 성능이 더 좋았습니다.
34B Code Llama 2는 유효한 JSON을 출력할 수 있었고 다른 지표들에서도 준수한 성능을 보였기 때문에, 이후 프롬프트 실험의 기준선(baseline)으로 사용하기로 했습니다.
실험 3: 스키마 준수화를 위한 프롬프팅 (Prompting for Schema Compliance)
세 가지 오픈 모델 기준선 중에서 34B Code Llama 2 변형 모델이 가장 좋은 성능을 보였습니다. 이 때문에 우리는
- 추가적인 작업 특정 지침(task-specific instructions) 추가: 스키마(schema)에 이미 각 값에 대한 설명이 포함되어 있지만, 예를 들어 목록에서 유효한 열거형(Enum) 값을 신중하게 선택하라는 등의 추가 지침이 도움이 되는지 확인하고자 했습니다. 우리는 플레이그라운드(playground) 예시 몇 가지에서 이 접근 방식을 테스트했으며, 이것이 때때로 도움이 될 수 있음을 확인했습니다.
- 생각의 사슬 (Chain-of-thought, CoT): 모델에게 최종 출력을 생성하기 전에 스키마 구조에 대해 단계별로 생각하도록 요청합니다.
- 퓨샷 예시 (Few-shot examples): 명시적인 지침과 스키마 외에도 모델이 따를 수 있도록 예상되는 입출력 쌍을 직접 제작했습니다. 때때로 LLM은 (사람처럼) 지침을 따르는 것보다 몇 가지 예시를 보는 것을 통해 더 잘 학습합니다.
결과는 다음과 같습니다:
오픈 소스 모델(OSS Models)을 위한 프롬프트 전략 비교
| 테스트 (Test) | 프롬프트 (Prompt) | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|---|
| baseline | 0.93 | 0.41 | 0.89 | 0.89 | 0.44 | 0.07 | 0.59 | 1.00 | |
| instructions | 0.95 | 0.38 | 0.96 | 0.89 | 0.63 | 0.11 | 0.54 | 1.00 | |
| few-shot | 0.89 | 0.38 | 0.59 | 0.85 | 0.33 | 0.07 | 0.85 | 0.96 | |
| CoT | 0.97 | 0.42 |
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기