
【총집편】e-Stat을 계속 분석하며 깨달은, 데이터 분석에서 반드시 빠지게 되는 4가지 함정──도쿄 최하위, 나라의 수수께끼, 카가와의
요약
e-Stat 정부 통계 데이터를 분석하며 경험한 데이터 분석의 4가지 주요 함정을 소개합니다. 분모 무시, 이상치 폐기, 가짜 상관관계, 입도 오판의 위험성을 실제 사례를 통해 설명합니다.
핵심 포인트
- 분모(인구, 점포 수 등)를 고려하지 않으면 데이터 왜곡 발생
- 이상치(Outlier)는 오류가 아닌 중요한 분석 단서가 될 수 있음
- 단순 상관관계와 인과관계를 혼동하지 않도록 주의
- 데이터의 입도(Granularity)를 정확히 파악하여 분석해야 함
통계학 교과서에는 적혀 있다.
하지만 스스로 데이터를 분석해 보고 나서야 비로소 이해할 수 있는 것이 있다.
분모를 잊는 함정
이상치(Outlier)를 버리는 함정
가짜 상관관계(Spurious Correlation)를 믿는 함정
입도(Granularity)를 오판하는 함정
도쿄의 외식 지출을 분석했더니, 도쿄가 최하위가 되었다.
나라현은 회귀 분석(Regression Analysis)에서 크게 벗어났다.
카가와현은 범죄율의 이상치였다.
효고현은 인구 밀도와 범죄율의 관계를 깨뜨리고 있었다.
처음에는 모두 데이터의 오류라고 생각했다.
하지만 틀린 것은 데이터가 아니라 나였다.
최근 몇 달간, 나는 e-Stat(정부 통계 포털 사이트)을 사용하여 가계 조사, 국세 조사, 경찰청 통계 등을 횡단적으로 분석해 왔다.
다룬 항목은 수백 개.
상관관계의 조합은 10만 가지 이상.
하지만 되돌아보면, 가장 가치 있었던 것은 분석 결과 그 자체가 아니었다.
오히려,
「데이터 분석에는 누구나 반드시 빠지게 되는 함정이 있다」
라는 사실이었다.
이 기사에서는 실제 분석에서 마주한 실패·오해·발견을 되돌아보며, 데이터 분석에서 의식해야 할 4가지 함정을 소개한다.
- 데이터 분석에서 가장 재미있는 것은 이상치였다 ― 카가와와 효고의 범죄율을 추적하며 알게 된 것
- 「오사카는 치안이 나쁘다」를 검증했더니, 일본의 범죄 감소를 설명하는 것은 고령화였다
- 「도쿄 최하위」에서 시작했더니, 나라현의 "생활 여력"이 보였다 ~ 외식 문화도 독서 문화도 아닌, 주택비 이야기였다 ~
- 【대체 POS v2.0】정부 통계의 "남은 89%"를 파헤쳤더니, 일본의 소비는 7개 국가로 나뉘어 있었다
- 일본은 가난해졌는가? 가계 데이터로 검증했더니 "전혀 다른 결론"이 나왔다
처음에 분석한 것은 도도부현별 외식 지출이었다.
직관적으로는,
- 도쿄 → 압도적으로 강함
- 오사카 → 상위권
이라는 결과가 나올 것 같았다.
실제로 지출 총액만 보면 그랬다.
하지만 음식점 수로 보정하면 풍경이 완전히 바뀐다.
df["외식지출_보정"] = df["외식지출액"] / df["음식점수"]
그러자 도쿄는 최하위 클래스까지 추락했다.
이유는 단순하다. 도쿄는 음식점이 너무 많기 때문에 소비가 분산되어 있기 때문이다.
인구, 점포 수, 세대 수, 면적.

이러한 "분모"를 무시하면, 거대 도시는 무엇이든 강해 보인다.
분석 초보자뿐만 아니라 경험자도 빠지기 쉬운 함정이다.
우선 깨달아야 한다. 이야기는 그다음이다.
절대수가 아니라 인구당·점포당·세대당으로 봄으로써 비로소 비교가 가능해진다.
외식 지출을 보정한 후의 데이터를 보면 기묘한 현이 나타났다.
나라현이다.
외식 지출도 서적 지출도 이상할 정도로 높다.
회귀 분석을 해도 설명되지 않는다.
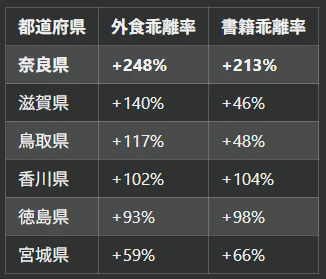
처음에는 노이즈(Noise)라고 생각했다.
하지만 조사할수록 흥미로워졌다.
- 오사카의 베드타운이기 때문인가
- 소득이 높기 때문인가
- 주야간 인구비의 영향인가
다양한 가설을 검증한 결과, 떠오른 것은 자가 보유율이었다.
나라현은 자가 보유율이 높고, 주택비 부담이 비교적 작다.
주택비라는 고정비가 가볍기 때문에 생활 여력이 생기고, 그 여력이 외식이나 취미로 향했을 가능성이 보였다.
만약 처음에
「이상치니까 제외하자」
라고 생각했다면, 이 발견에는 도달하지 못했을 것이다.
이상치는 쓰레기가 아니다. 이야기의 입구이다.
회귀 모델로 설명할 수 없는 잔차(Residual)에는 아직 보이지 않는 구조가 숨겨져 있는 경우가 있다.
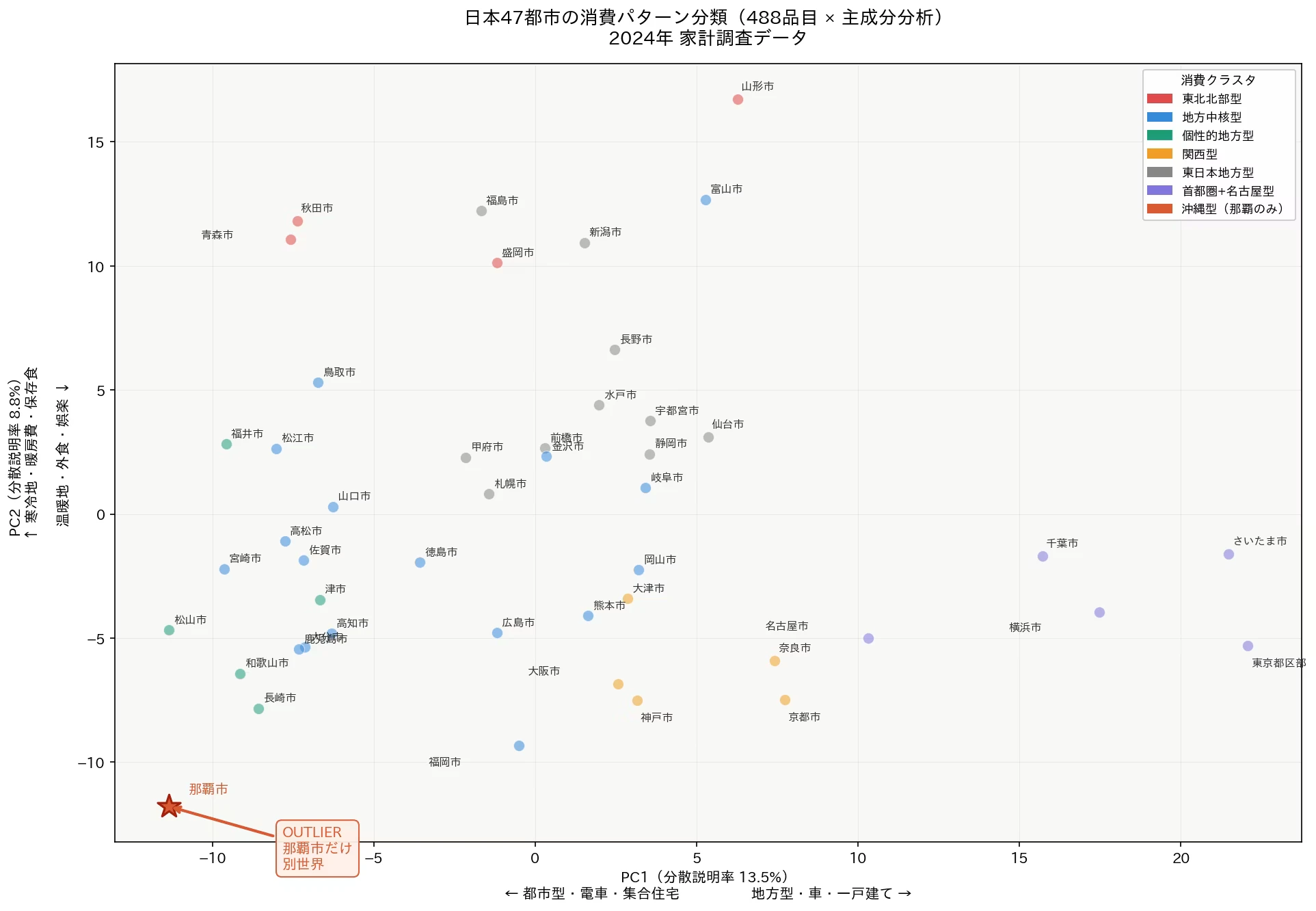
다음에 진행한 것은 가계 조사 488개 품목의 전수 탐색이었다.
조합 수는 118,828가지.
대량의 상관 분석을 실시하면 재미있는 결과가 차례차례 발견된다.
하지만 여기서 큰 문제가 있다.
대량으로 검정(Test)하면 가짜 상관관계가 대량 발생한다.
유의 수준(Significance level) 5%라면, 아무런 관계가 없어도 일정 수는 우연히 히트한다.
실제로 보정 전에는 수백 건의 "재미있어 보이는 상관관계"가 발견되었다.
하지만 보정 후에 남은 것은 그 일부뿐이었다.
만약 보정을 하지 않았다면, 나는 우연을 발견으로서 기사에 썼을지도 모른다.
그래서 FDR 보정(Benjamini-Hochberg 법)을 적용했다.
그러자 「유의미했던 상관관계」의 대부분이 사라졌다.
분석 결과는 줄어들었다.
하지만 신뢰성은 대폭 향상되었다.
그럼에도 보정 후에는 흥미로운 관계가 남았다.
예를 들어,
- 요거트 지출과 센베이(쌀과자) 지출의 상관관계
- 도시가스 지출과 가솔린 지출의 강한 부의 상관관계(Negative Correlation)
등이다.
이러한 결과는 일본의 지역 특성이나 생활 양식의 차이를 투영하고 있었다.

상관관계가 발견된 순간이 골(Goal)이 아니다.
대량 탐색에서는
「어떻게 우연을 배제했는가」
까지 설명할 수 있어야 비로소 분석이 된다.
원문 기사: 【대체POS v2.0】 정부 통계의 "남은 89%"를 파헤쳤더니, 일본의 소비는 7개의 국가로 나뉘어 있었다
마지막은 범죄 통계 분석이다.
"오사카는 치안이 나쁘다"라는 이미지를 검증하고 있었을 때, 일본 전체적으로 범죄 건수가 대폭 감소하고 있다는 사실을 알게 되었다.
하지만 여기서도 기묘한 현(県)이 나타났다.
단년 데이터(Single-year data)만 보면, 카가와현은 범죄율이 이상할 정도로 높게 보였다.
하지만 시계열(Time-series)로 추적해 보니, 특수 사기 적발로 인한 일시적인 스파이크(Spike)가 원인이었다.
점(Point)으로 보면 이상치(Outlier)이지만, 선(Line)으로 보면 설명이 가능하다.
전형적인 시계열의 함정이었다.
효고현은 인구 밀도에 비해 범죄율이 높게 보였다.
하지만 실제로는,
- 고베·한신 간의 도시 지역
- 타지마·탄바의 농촌 지역
이 같은 현(県) 안에 존재하고 있다.
평균을 내버리면 두 지역의 특징이 모두 사라져 버린다.
고베시만 보면 도시형 특징이 나타난다.
타지마 지방만 보면 농촌형 특징이 나타난다.
하지만 효고현으로서 평균을 내면, 그 양쪽이 섞여 버린다.
이처럼 집계 단위에 따라 결과가 달라지는 현상은 GIS(지리정보시스템) 분야에서 MAUP(가변 면적 단위 문제, Modifiable Areal Unit Problem)로 알려져 있다.
이것은 GIS 분야에서 알려진 MAUP(가변 면적 단위 문제)의 전형적인 사례였다.

데이터는 "어떤 단위로 보느냐"에 따라 얼굴을 바꾼다.
- 연 단위인가 월 단위인가
- 시구정촌(市区町村)인가 도도부현(都道府県)인가
- 전국인가 지역인가
입도(Granularity, 해상도)를 바꾸는 것만으로 결론은 크게 달라진다.
원문 기사: 「오사카는 치안이 나쁘다」를 검증했더니, 일본의 범죄 감소를 설명하는 것은 고령화였다

이번에 마주한 함정은 다음 4가지였다.
- 분모를 잊는 함정
- 이상치(Outlier)를 버리는 함정
- 가짜 상관관계(Spurious correlation)를 믿는 함정
- 입도(Granularity)를 오판하는 함정
모두 통계학 교과서에 실려 있는 내용이다.
하지만 실제로 직접 데이터를 다뤄보기 전까지는 그 무서움을 이해할 수 없었다.
돌이켜보면, 중요했던 것은 Python도 회귀 분석(Regression analysis)도 아니었다.
정말로 중요했던 것은,
"자신이 보고 싶은 것만 보지 않는 것"
이었다.
도쿄 최하위.
나라현의 돌출.
카가와현의 이상치.
효고현의 MAUP 문제.
모두 처음에는
"데이터가 틀린 것 아닌가?"
라고 생각했던 결과였다.
하지만 그 위화감을 계속 파헤친 끝에 비로소 발견이 있었다.
데이터 분석이란 가설을 증명하는 작업이 아니다.
자신의 직관이 왜 틀렸는지를 밝혀내는 작업이다.
e-Stat와 같은 오픈 데이터에는 아직 많은 발견이 잠들어 있다.
다음 "위화감"을 찾아내는 것은 이 글을 읽은 당신일지도 모른다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기