
에이전트 도구 사용 (Agent Tool Use) 벤치마킹
요약
LLM 에이전트의 핵심 역량인 도구 사용(Tool Use) 능력을 평가하기 위한 네 가지 새로운 벤치마크 환경을 소개합니다. 계획 수립, 함수 호출, 사전 학습된 편향 극복 능력을 테스트하며 다양한 모델의 성능 차이를 분석합니다.
핵심 포인트
- 에이전트의 도구 사용 능력을 측정하는 4가지 신규 테스트 환경 출시
- GPT-4는 관계형 데이터 작업에서 우수하나, 특정 수학 작업에서는 역스케일링 현상 발생
- Claude-2.1은 대부분의 작업에서 GPT-4와 유사한 성능을 보임
- Mistral 7b 등 오픈 소스 모델은 다중 함수 호출 구성에 어려움을 겪음
- 모델 배포 전 특정 행동 패턴에 대한 사전 검증의 중요성 강조
에이전트(Agents)는 LLM 애플리케이션의 핵심적인 "킬러" 앱이 될 수 있지만, 에이전트를 구축하고 평가하는 것은 어렵습니다. 함수 호출 (Function calling)은 효과적인 도구 사용을 위한 핵심 기술이지만, 함수 호출 성능을 측정할 수 있는 좋은 벤치마크가 많지 않습니다. 오늘 저희는 LLM이 작업을 완수하기 위해 도구를 효과적으로 사용하는 능력을 벤치마킹할 수 있는 네 가지 새로운 테스트 환경을 출시하게 되어 기쁩니다. 이를 통해 모든 사용자가 다양한 LLM 및 프롬프팅 (prompting) 전략을 테스트하여, 어떤 요소가 최상의 에이전트적 행동 (agentic behavior)을 가능하게 하는지 더 쉽게 확인할 수 있기를 바랍니다.
저희는 계획 / 작업 분해 (planning / task decomposition), 함수 호출 (function calling), 그리고 필요할 때 사전 학습된 편향 (pre-trained biases)을 무시할 수 있는 능력과 같이 일반적인 에이전트 워크플로우 (agentic workflows)의 전제 조건이라고 간주되는 역량들을 테스트하기 위해 이 작업들을 설계했습니다. 만약 LLM이 (명시적인 미세 조정 (fine-tuning) 없이) 이러한 유형의 작업을 해결할 수 없다면, "추론 (reasoning)"이 필요한 다른 워크플로우에서 신뢰성 있게 수행하고 일반화하는 데 어려움을 겪을 가능성이 높습니다. 저희의 연구 결과를 확인하고 싶은 분들을 위한 몇 가지 주요 요점은 다음과 같습니다:
💡
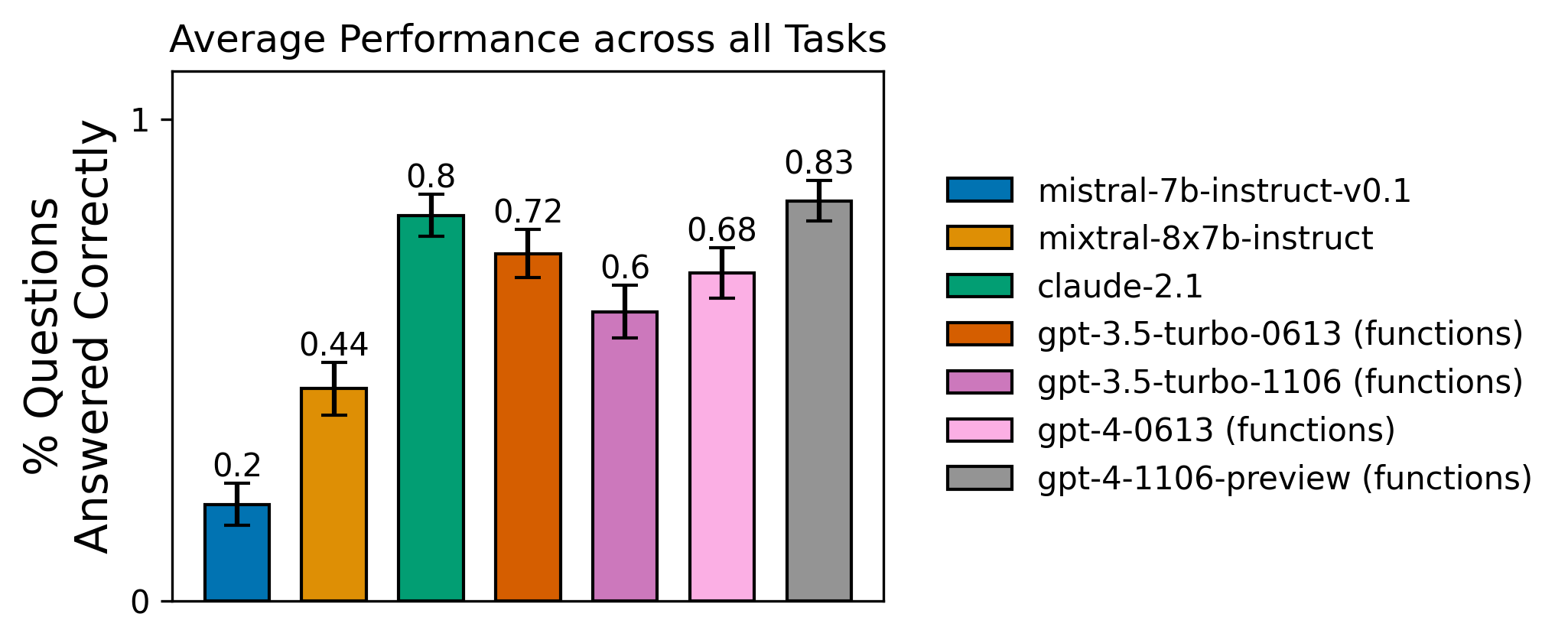
**주요 결과 - 모든 모델은 단순한 작업이라 할지라도 더 긴 궤적 (trajectories)에서는 실패할 수 있습니다. - GPT-4는 일반적인 사용 사례와 가장 유사한 관계형 데이터 (Relational Data) 작업에서 가장 높은 점수를 받았습니다. - GPT-4는 멀티버스 수학 (Multiverse Math) 작업에서 GPT-3.5보다 더 나쁜 성능을 보이는 것으로 보입니다. 이는 사전 학습된 편향이 역스케일링 (inverse scaling) 사례에서 성능을 저해했을 가능성이 있습니다. - Claude-2.1은 4개 작업 중 3개에서 GPT-4의 오차 범위 내에서 성능을 발휘하지만, 관계형 데이터 작업에서는 GPT-4에 뒤처지는 것으로 보입니다. - AnyScale의 Mistral 7b 미세 조정 변형 모델은 잘 형식이 갖춰진 도구 호출 (tool invocations)을 출력함에도 불구하고, 2개 이상의 호출을 안정적으로 구성하는 데 어려움을 겪습니다. 향후 오픈 소스 함수 호출 노력은 단일 호출의 정확성뿐만 아니라 함수 구성 (function composition)에도 집중해야 합니다. - 모델 품질 외에도 서비스 신뢰성이 중요합니다. 저희는 가장 인기 있는 모델 제공업체들로부터 빈번한 무작위 5xx 에러를 경험했습니다.
🦜
그래서 무엇이 중요한가요? (So what?)
- 모델의 지식이 초인적이라 할지라도, 수행하려는 작업이나 지식이 사전 학습 (pre-training) 데이터와 크게 다르다면 도움이 되지 않습니다. LLM을 배포하기 전에, 모델이 탁월한 성능을 발휘해야 하는 행동 패턴에 대해 선택한 LLM을 검증하십시오.
- 계획 수립 (Planning)은 LLM에게 여전히 어려운 과제입니다. 단순한 작업이라 할지라도 요구되는 단계 (steps)의 수가 늘어날수록 실패할 가능성이 높아집니다.
- 함수 호출 (Function calling)을 사용하면 100%의 스키마 (schema) 정확도를 얻기는 쉽지만, 그것만으로는 작업의 정확성 (task correctness)을 보장하기에 충분하지 않습니다. 만약 에이전트 사용을 위해 모델을 미세 조정 (fine-tuning)하고 있다면, 다단계 궤적 (multi-step trajectories) 데이터로 학습시키는 것이 필수적입니다.
이 포스트의 나머지 부분에서는 각 작업을 살펴보고 초기 벤치마크 결과를 전달하겠습니다.
실험 개요 (Experiment overview)
이번 릴리스에서는 4가지 도구 사용 (tool usage) 작업에 대해 7개 모델을 대상으로 한 실험 결과와 이를 재현할 수 있는 코드를 공유합니다.
- Typewriter (단일 도구): 단일 도구를 순차적으로 호출하여 단어를 타이핑합니다.
- Typewriter (26개 도구): 서로 다른 도구들을 순차적으로 호출하여 단어를 타이핑합니다.
- 관계형 데이터 (Relational Data): 세 개의 테이블에 있는 정보를 바탕으로 질문에 답합니다.
- Multiverse Math: 도구를 사용하여 수학 문제를 해결하며, 이때 기저에 깔린 수학 규칙은 약간 변경되어 있습니다.
저희는 이러한 작업들에 대해 네 가지 지표 (metrics)를 계산합니다:
- 정답 여부 (Correctness, 정답(ground truth)과 비교) - 이는 LLM을 판사(judge)로 사용합니다. 이 모든 질문에 대한 답변은 간결하고 상당히 이진적(binary)이기 때문에, 저희는 해당 판단이 저희의 결정과 일치한다는 것을 확인했습니다.
- 최종 상태의 정확성 (Correct final state (environment)) - 타자기(typewriter) 작업의 경우, 각 도구 호출(tool invocation)은 세계 상태(world state)를 업데이트합니다. 저희는 각 테스트 행의 끝에서 환경의 동등성(equivalence)을 직접 확인합니다.
- 중간 단계의 정확성 (Intermediate step correctness) - 각 데이터 포인트는 정답을 얻기 위한 최적의 함수 호출(function calls) 시퀀스를 가지고 있습니다. 저희는 함수 호출의 순서를 정답(ground truth)과 직접 비교하여 확인합니다.
- 예상 단계 대비 수행된 단계의 비율 (Ratio of steps taken to the expected steps) - 에이전트가 최적이지 않은 도구 세트를 선택하더라도 궁극적으로 정답을 반환할 수도 있습니다. 이 지표는 중간 단계의 정확성(intermediate step correctness)처럼 엄격하지는 않으면서도 불일치 사항을 반영할 것입니다.
저희는 폐쇄형 소스(closed source) 모델과 오픈 소스(open source) 모델을 모두 비교했습니다. 자세한 내용은 아래 섹션을 확장하여 확인하세요.
테스트된 모델들
오픈 소스 (Open Source):
- Mistral-7b-instruct-v0.1: Anyscale에서 함수 호출(function calling)을 위해 조정한 Mistral의 7B 파라미터 모델입니다.
- Mixtral-8x7b-instruct: Fireworks.ai에서 지시어 튜닝(instruction tuning)을 통해 조정한 Mistral의 7B 파라미터 전문가 혼합(mixture of experts) 모델입니다.
OpenAI - (도구 호출 에이전트 (Tool Calling Agent))
- GPT-3.5-0613
- GPT-3.5-1106-preview
- GPT-4-0613
- GPT-4-1106-preview
Anthropic
- XML 프롬프팅(XML prompting)과 자체 도구 사용자 라이브러리를 사용하는 Claude 2.1.
⌨ 타자기 (Typewriter) (단일 도구)
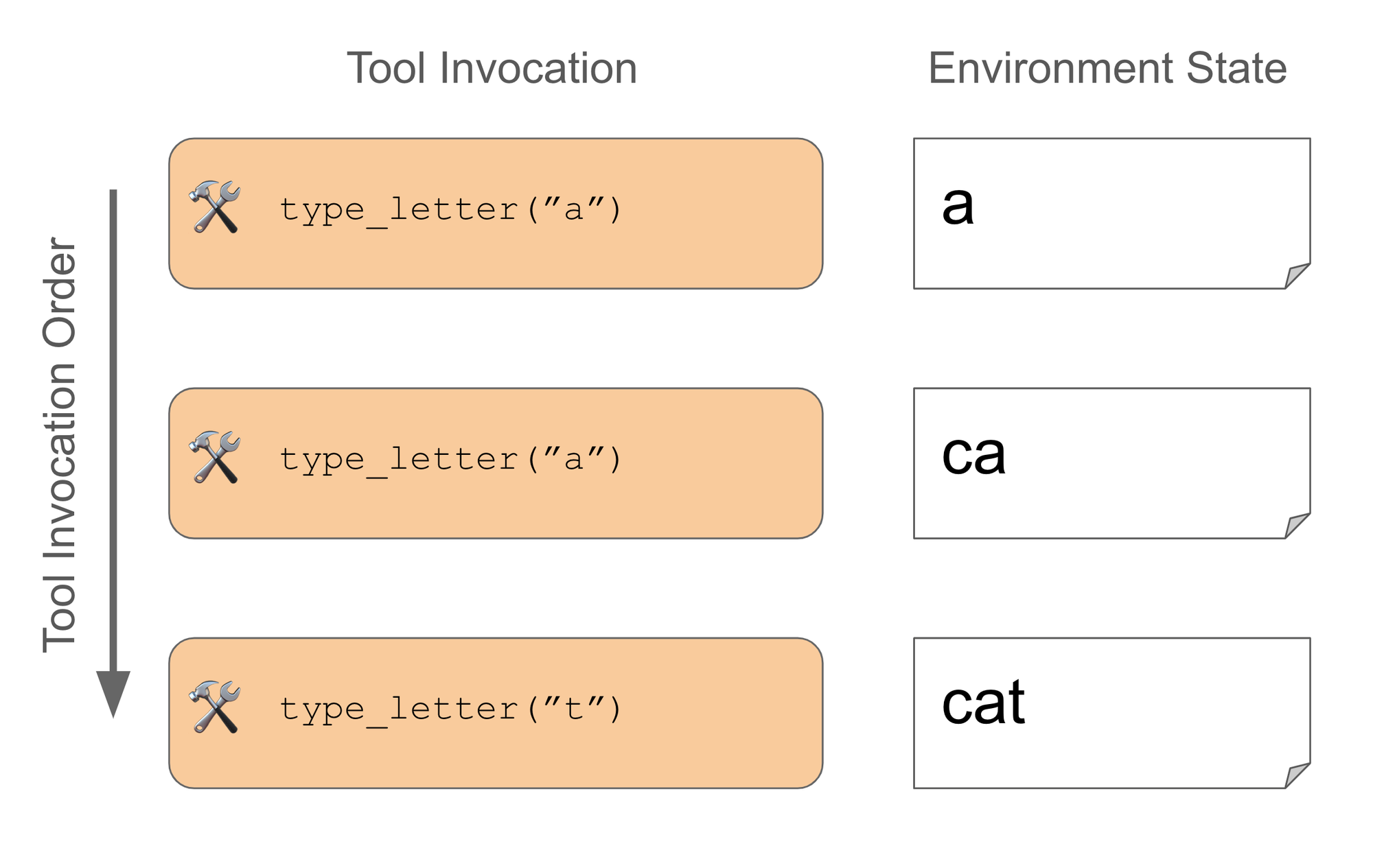
타자기 작업은 간단합니다: 에이전트는 주어진 단어를 "타이핑"한 다음 멈춰야 합니다. 단어는 쉬운 수준(a 또는 cat)부터 약간 더 어려운 수준(communication 및 keyboard)까지 다양합니다. 단일 도구 설정에서 모델에게는 문자를 입력으로 받는 단일 type_letter 도구가 주어집니다. 통과하기 위해서 에이전트가 해야 할 일은 올바른 순서로 각 글자에 대해 도구를 호출하는 것뿐입니다. 예를 들어, cat의 경우 에이전트는 다음과 같이 실행합니다:
전체 데이터셋은 이 링크에서 확인하실 수 있으며, 어떤 모습인지 파악하고 이 작업을 직접 실행하는 방법에 대한 자세한 문서는 참고해 주세요.
이처럼 간단한 작업에 성공하는 것은 어느 정도 기본 역량(table stakes)이며, gpt-4와 같이 도구 호출(tool-calling) 기능이 있는 대규모 모델이라면 아주 쉽게 해낼 것이라고 예상할 수 있습니다. 하지만 저희는 그렇지 않은 경우도 발견했습니다! 예를 들어, 에이전트가 단순히
이 작업의 데이터셋은 단일 도구 타자기(single-tool typewriter) 데이터셋과 동일한 테스트 입력 단어를 사용합니다. 이 링크에서 데이터셋을 확인하고, 이 벤치마크에서 본인의 에이전트를 실행하는 방법을 포함한 자세한 내용은 작업 문서를 통해 검토할 수 있습니다.
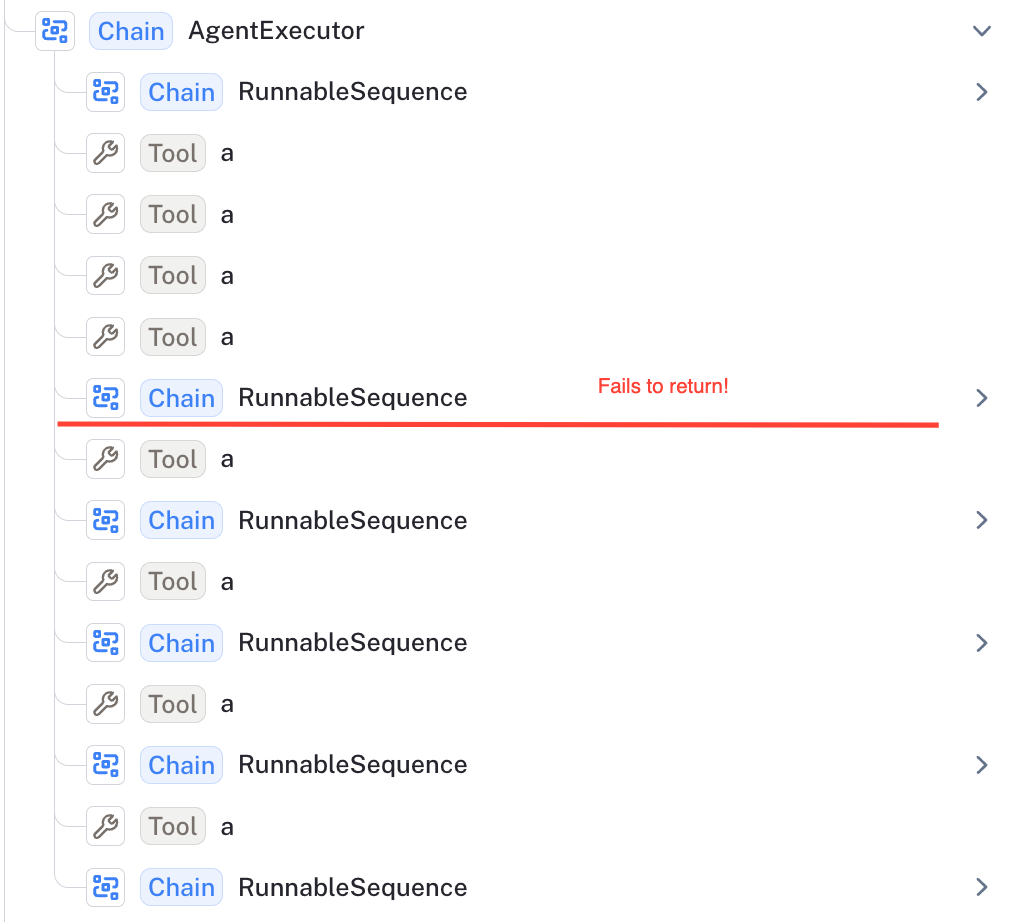
다시 한번 말씀드리지만, gpt-4와 같은 강력한 모델이라면 이 작업이 사소할 것이라고 예상하겠지만, 여러분의 예상은 다시 한번 틀렸음이 증명될 것입니다. 이 실행 사례를 예로 들어보겠습니다. "aaaa"를 입력하라는 요청을 받았을 때, 처음에는 네 개의 'a'를 입력하지만 그 후 멈추지 못하고, 작업이 완료되었다고 판단하기 전까지 'a'를 4번 더 입력합니다.
다음은 테스트된 에이전트들에 대한 이 작업의 결과입니다:
🕸️ 관계형 데이터 (Relational Data)
유능한 AI 어시스턴트는 객체와 그 관계에 대해 추론할 수 있어야 합니다. 현실 세계의 질문에 답하기 위해서는 대개 서로 다른 소스로부터 응답을 합성해야 하지만, LLM(Large Language Models)은 이러한 방식으로 "생각"하는 데 얼마나 신뢰할 수 있을까요?
관계형 데이터 작업에서 에이전트는 3개의 관계형 테이블(relational tables)에 포함된 데이터를 기반으로 질문에 답해야 합니다. 도구를 사용하기 위해 에이전트에게는 다음과 같은 지침이 주어집니다:
제공된 도구를 사용하여 사용자의 질문에 답하세요. 답을 추측하지 마세요. 사용자, 음식, 위치와 같은 엔티티(entities)는 이름과 ID를 모두 가지고 있으며, 이 둘은 서로 다르다는 점을 유념하세요.
에이전트는 사용할 수 있는 17개의 도구 세트를 사용하여 정답을 찾기 위해 이 테이블들을 쿼리(query)할 수 있습니다. 세 개의 테이블은 각각 사용자, 위치, 음식에 대한 정보를 포함하고 있습니다. 오늘 공개된 모든 합성 데이터셋(synthetic datasets) 중에서, 이 데이터셋은 실제 웹 애플리케이션에서의 도구 사용 방식과 가장 유사합니다.
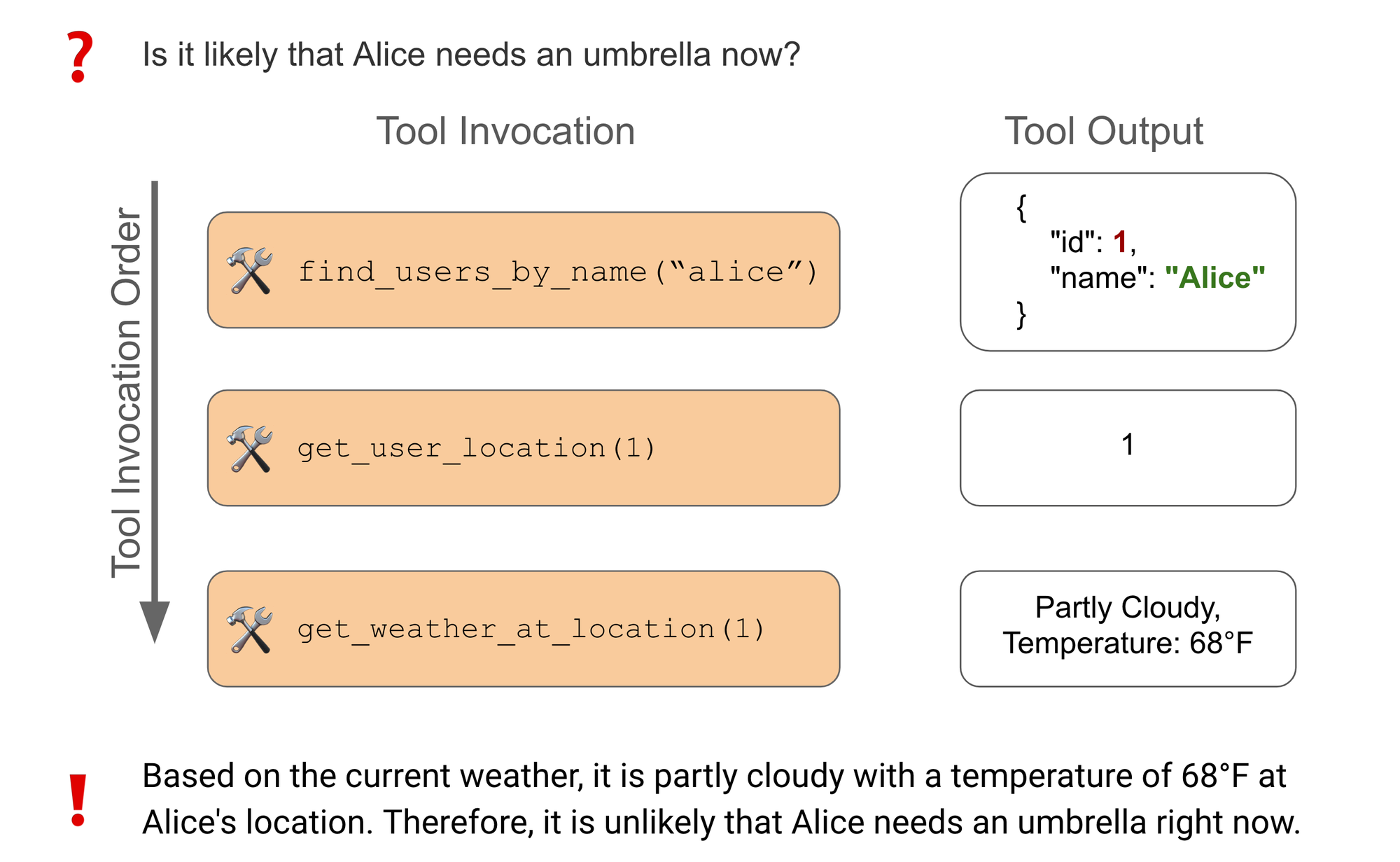
테이블의 데이터를 사용하면 "Alice에 대해 무엇을 알려줄 수 있나요?" 또는 "Alice가 지금 우산이 필요할 가능성이 있나요?"(아래 샘플 데이터 참조)와 같은 질문에 답할 수 있습니다.
다음은 후자의 질문에 대한 예시입니다:
이 예시에서 에이전트는 사용할 수 있는 17개의 도구 중 다음 3개의 도구를 선택합니다:
find_users_by_name(name)
→ 이름으로 사용자 검색. get_user_location(user_id)
→ 주어진 사용자의 선호 색상을 조회합니다. get_weather_at_location(location_id)
→ 주어진 위치의 날씨를 가져옵니다.
각 테이블의 처음 2개 레코드를 살펴보면, 이러한 함수 호출(function calls)이 반환할 결과를 확인할 수 있습니다:
Users
id
name
location
favorite_color
favorite_foods
1
Alice
1
red
[1, 2, 3]
21
Bob
2
orange
[4, 5, 6]
Locations
id
city
current_time
current_weather
1
New York
2023-11-14 10:30 AM
Partly Cloudy, Temperature: 68°F
2
Los Angeles
2023-11-14 7:45 AM
Sunny, Temperature: 75°F
Foods
id
name
calories
allergic_ingredients
1
Pizza
285
["Gluten", "Dairy"]
2
Chocolate
50
["Milk", "Soy"]
에이전트는 먼저 Alice의 사용자 ID를 검색한 다음, 해당 사용자 ID를 사용하여 현재 위치를 가져오고, 마지막으로 위치 ID를 사용하여 현재 날씨를 가져옵니다. Alice의 위치의 현재 날씨가 구름 조금(partly cloudy)이므로, 그녀에게 우산이 필요할 가능성은 낮습니다. 만약 에이전트가 이 단계 중 하나라도 건너뛴다면, 최종 답변을 정확하게 제공하는 데 필요한 정보가 부족하게 될 것입니다.
평가 데이터셋은 다양한 난이도의 질문 20개로 구성되어 있어, 에이전트가 각 함수가 서로에게 어떻게 의존하는지에 대해 얼마나 잘 추론할 수 있는지 테스트할 수 있습니다. 이 링크에서 데이터셋을 탐색할 수 있습니다. 아래 차트는 테스트된 에이전트들에 대한 이 작업의 결과를 공유합니다:
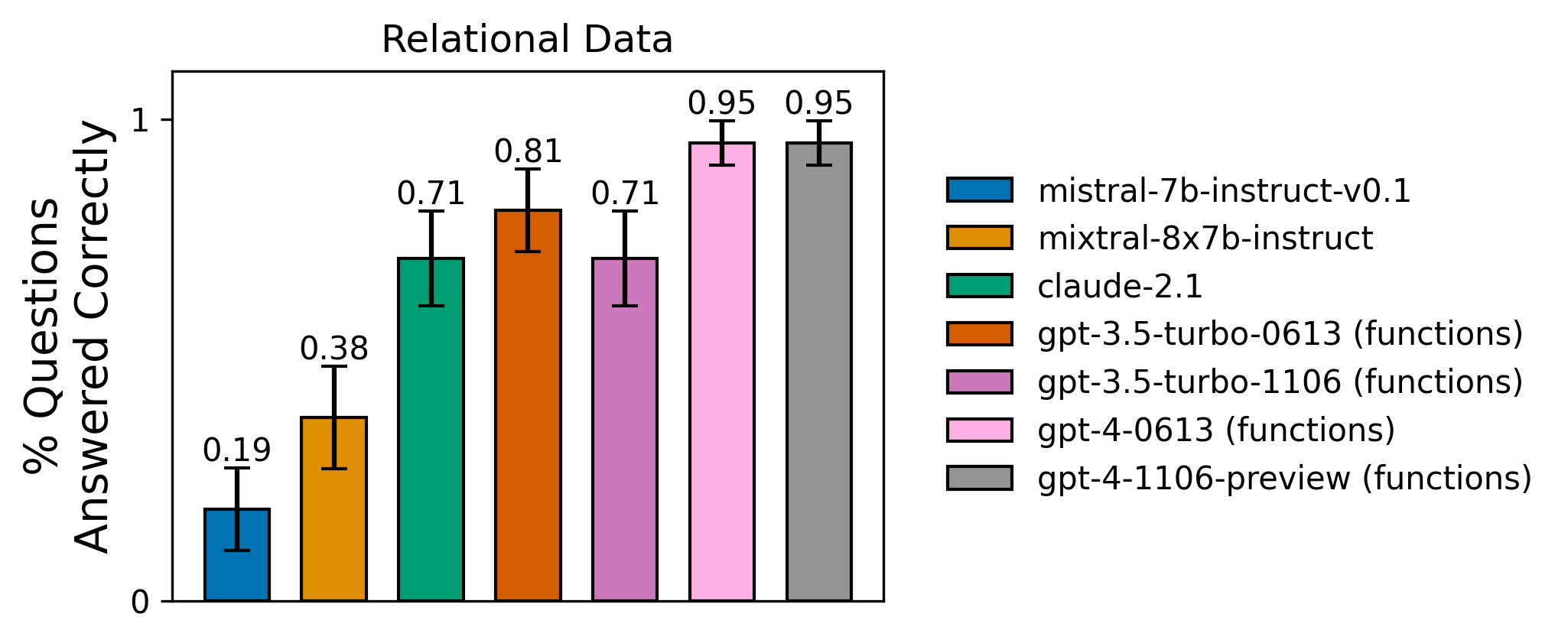
필요한 추론 능력 측면에서 처음 두 작업보다 다소 어렵음에도 불구하고, GPT-4는 이 작업에서 1개의 질문을 제외한 모든 질문에 올바르게 답하며 상당히 좋은 성능을 보여줍니다. 이 실패 사례를 살펴보겠습니다. 이 데이터 포인트에서 에이전트에게는 "Even의 친구인 Frank는 유제품(dairy) 알레르기가 있습니다. 그가 샐러드를 먹어도 될까요?"라는 프롬프트가 주어집니다.

이 경우, GPT-4는 get_users_by_name("Frank")에 대한 올바른 첫 번째 호출을 수행합니다.
. 도구는 "Frank the Cat"에 대한 정보를 반환합니다. 모델은 이것이 요청된 "frank"와 일치하지 않는다고 판단하여, 다시 "Even"에 대해 쿼리합니다. 직접적인 일치 항목이 없으므로, 에이전트는 "Even"이라는 이름의 사용자를 찾을 수 없다고 응답하며 포기합니다. "Frank the cat"에 대해 확신이 낮을 수는 있겠으나, 에이전트는 이를 가능한 일치 항목으로 고려하지도 않았고 최종 사용자 응답에서 이를 언급하지도 않았습니다. 이는 사용자가 에이전트의 자기 수정 (self-correct)을 도울 수 있는 효과적인 피드백을 제공할 수 없음을 의미합니다.
🌌 Multiverse Math
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기