에이전트 관측 가능성 (Agent Observability): 프로덕션 환경에서 LLM 에이전트를 모니터링하고 평가하는 방법
요약
LLM 에이전트는 비결정론적 특성과 무한한 자연어 입력 공간으로 인해 전통적인 소프트웨어와는 다른 관측 가능성(Observability) 전략이 필요합니다. 본 글은 에이전트의 다단계 추론, 도구 호출, 검색 작업을 모니터링하고 프로덕션 트레이스를 통해 품질을 평가하는 방법론을 다룹니다.
핵심 포인트
- 에이전트는 자연어 입력을 사용하므로 전통적인 소프트웨어와 달리 입력 공간이 무한하여 예측이 어렵습니다.
- 동일한 입력에 대해서도 비결정론적(non-deterministic)인 출력을 생성할 수 있어 품질 관리가 까다롭습니다.
- 단순한 오류율이나 응답 시간을 넘어 추론 체인, 도구 호출, 검색 작업에 대한 모니터링이 필수적입니다.
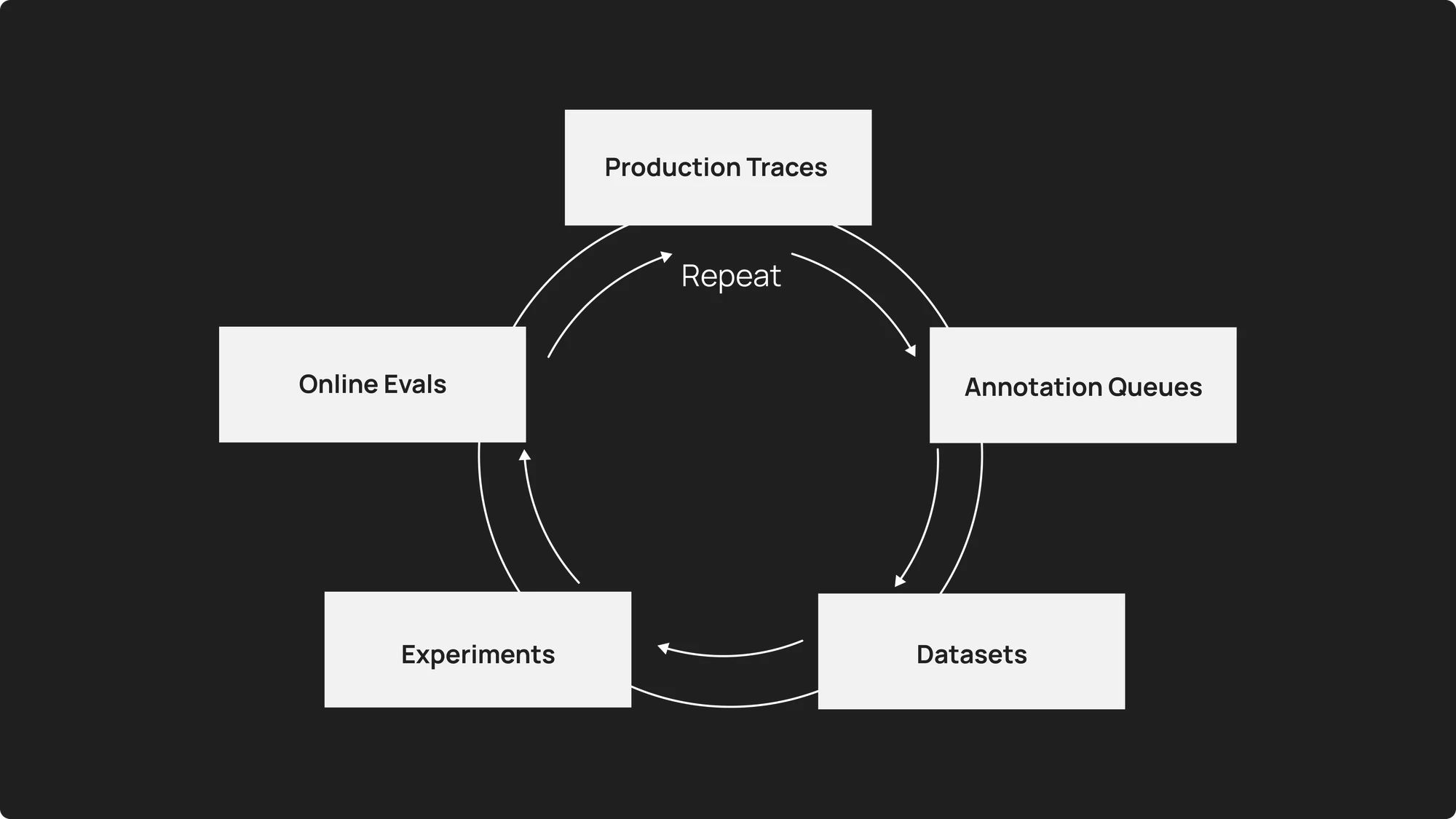
- 프로덕션 트레이스(production traces)는 에이전트의 지속적인 개선을 위한 핵심 토대가 됩니다.
핵심 요약 (Key Takeaways)
에이전트는 전통적인 소프트웨어처럼 모니터링할 수 없습니다. 입력값은 무한하며, 동작은 비결정론적 (non-deterministic)이고, 품질은 대화 그 자체에 존재합니다. 이 글에서는 무엇을 모니터링해야 하는지, 어떻게 평가를 확장할 수 있는지, 그리고 프로덕션 트레이스 (production traces)가 어떻게 지속적인 개선의 토대가 되는지를 설명합니다.
전통적인 소프트웨어를 프로덕션에 배포할 때는 무엇을 기대할 수 있는지 잘 알고 있습니다. 사용자는 버튼을 클릭하고, 양식을 채우며, 미리 정해진 경로를 따라 이동합니다. 테스트 스위트 (test suite)가 코드 경로의 80-90%를 커버할 수 있으며, 모니터링 도구는 오류율 (error rates), 응답 시간 (response times), 데이터베이스 쿼리 (database queries)와 같은 일반적인 요소들을 추적합니다. 무언가 고장 나면 스택 트레이스 (stack traces)와 로그 (logs)를 확인합니다.
에이전트는 다르게 작동합니다. 에이전트는 가능한 쿼리의 범위가 무한한 자연어 입력을 수용합니다. 에이전트는 프롬프트 (prompts)의 미세한 변화에 민감하고 동일한 입력에 대해 서로 다른 출력을 생성할 수 있는 거대 언어 모델 (Large Language Models, LLMs)에 의해 구동됩니다. 또한, 개발 단계에서 완전히 예측하기 어려운 다단계 추론 체인 (reasoning chains), 도구 호출 (tool calls), 검색 작업 (retrieval operations)을 통해 의사결정을 내립니다.
이는 에이전트를 위한 프로덕션 모니터링이 전통적인 관측 가능성 (observability)과는 다른 역량을 필요로 함을 의미합니다. 이 포스트에서는 왜 에이전트 관측 가능성이 독특한 과제를 안고 있는지, 무엇을 모니터링해야 하는지, 그리고 에이전트를 대규모로 배포하는 팀들로부터 무엇을 배웠는지 탐구해 보겠습니다.
에이전트가 전통적인 소프트웨어와 다른 이유
에이전트를 프로덕션에 배포하는 팀들과 협업하면서, 우리는 모니터링 접근 방식에 영향을 미치는 두 가지 주요 차이점을 관찰했습니다.
에이전트는 무한한 입력 공간을 가집니다
전통적인 소프트웨어는 유한하고 제한된 입력 공간을 가집니다. 사용자는 버튼, 드롭다운, 양식, 그리고 특정 형식을 가진 API 호출을 통해 상호작용합니다. 결제 흐름 (checkout flow)을 설계할 때, 여러분은 화면의 정확한 순서와 가능한 사용자 행동을 알고 있습니다. 실패 모드 (failure modes)를 열거할 수 있기 때문에 포괄적인 오류 처리가 가능합니다.
반면, 에이전트 (Agents)는 자연어 (natural language)를 주요 입력값으로 받아들입니다. 자연어에는 고정된 유효 입력 집합이 없습니다. 사용자는 동일한 요청을 수없이 다양한 방식으로 표현할 수 있습니다. 모호하거나 구체적일 수 있고, 격식을 차리거나 격식이 없을 수 있으며, 단일 메시지에 여러 의도 (intents)를 결합하거나 단일 요청을 여러 턴 (turns)에 걸쳐 나누어 전달할 수도 있습니다.
고객 지원 에이전트를 예로 들어보겠습니다. 전통적인 소프트웨어에서 사용자는 "주문 내역"으로 이동하여, 주문을 클릭하고, "환불 요청"을 클릭한 다음, 마지막으로 미리 정의된 옵션이 있는 양식을 작성할 것입니다. 이 경로는 고정되어 있으며 테스트가 가능합니다.
에이전트의 경우, 사용자는 다음과 같이 말할 수 있습니다:
- "주문을 반품하고 싶어요"
- "지난주에 산 신발 값을 돌려받도록 도와줄 수 있나요?"
- "받은 물건이 파손되었는데, 어떻게 해야 하나요?"
- "주문 번호 #12345 환불 부탁합니다"
각각은 동일한 근본적 의도를 나타내지만, 에이전트는 이러한 변형을 이해하고, 관련 정보를 추출하며, 적절한 행동을 결정해야 합니다.
이러한 무한한 입력 공간은 실제 사용자가 상호작용을 시작하기 전까지는 에이전트가 어떻게 사용될지 완전히 예측할 수 없음을 의미합니다.
LLM은 작은 변화에 견고하지 않습니다
두 번째 주요 차이점은 LLM이 프롬프트 민감도 (prompt sensitivity)와 비결정론적 (non-deterministic) 동작을 보인다는 것입니다. 입력의 아주 작은 변화만으로도 다른 출력이 나올 수 있으며, 동일한 입력이라도 때로는 다른 결과를 생성할 수 있습니다.
이러한 현상은 여러 가지 이유로 발생합니다. LLM은 생성 과정에서 확률적 샘플링 (probabilistic sampling)을 사용하며, 이는 분산 (variance)을 유발합니다. 가장 중요한 점은, LLM이 문구, 문맥 (context), 또는 지시 사항의 순서와 같은 미묘한 변화에 다르게 반응한다는 것입니다.
이러한 비결정론적 특성은 개발 단계에서 관찰한 동작이 프로덕션 (production) 환경에서 발생하는 상황과 일치하지 않을 수 있음을 의미합니다. 테스트에서 안정적으로 작동하던 프롬프트가 예상치 못한 엣지 케이스 (edge cases)에서 실패할 수 있습니다. 평가 (evaluation) 단계에서 도구 (tools)를 올바르게 사용하던 에이전트가, 문구가 약간 다른 사용자 질의에 대해서는 가끔 잘못된 도구를 선택할 수도 있습니다.
에이전트를 위한 프로덕션 모니터링은 다릅니다
전통적인 애플리케이션 성능 모니터링 (Application Performance Monitoring, APM) 도구는 지연 시간 (latency), 트래픽 (traffic), 에러 (errors), 포화도 (saturation)와 같은 지표에 집중합니다. 이들은 HTTP 요청, 데이터베이스 쿼리, 시스템 리소스를 추적합니다. 이러한 도구들은 가능한 코드 경로를 알고 있는 구조화되고 결정론적인 (deterministic) 시스템을 위해 설계되었습니다.
에이전트 관측 가능성 (Agent observability)은 시스템 주변의 지표뿐만 아니라, 입력값 (inputs)과 출력값 (outputs) 자체를 모니터링할 것을 요구합니다.
자연어 상호작용 모니터링
에이전트가 사용자와 대화를 나눌 때, 주요 신호는 대화 그 자체에 존재합니다. 다음과 같은 사항들을 캡처해야 합니다:
전체 프롬프트-응답 쌍 (Complete prompt-response pairs): 단순히 요청이 발생했다는 사실뿐만 아니라, 사용자가 무엇을 물었고 에이전트가 무엇이라고 응답했는지를 파악해야 합니다.
멀티턴 컨텍스트 (Multi-turn context): 에이전트는 종종 하나의 대화 과정으로서 여러 차례의 교환을 거치며 작동하므로, 관련된 상호작용들을 하나로 그룹화해야 합니다.
에이전트 궤적 및 중간 단계 (Agent trajectory and intermediate steps): 에이전트는 도구를 호출하고 옵션을 통해 추론하며 최종 출력에 도달하기 위해 다단계 경로를 거칠 수 있습니다. 최종 응답뿐만 아니라 궤적의 각 단계에 대한 가시성이 필요합니다.
이는 전통적인 로깅 (logging)과는 질적으로 다릅니다. 전통적인 웹 요청은 "POST /api/checkout 200 OK 342ms"와 같이 요약될 수 있습니다. 하지만 에이전트 상호작용은 잠재적으로 수십 단계에 이르는 자연어 대화이며, 그것이 잘 수행되었는지에 대한 질문은 상태 코드 (status code)만으로는 답할 수 없습니다.
대규모 환경에서의 인간 판단의 어려움
자연어 상호작용은 적절한 평가를 위해 종종 인간의 판단을 필요로 합니다. 이 응답이 도움이 되었는가? 에이전트가 사용자의 의도 (intent)를 이해했는가? 어조 (tone)가 적절했는가? 관련 정보를 제대로 검색했는가? 등의 문제입니다.
개발 단계에서는 이것이 관리 가능합니다. 트레이스 (traces)를 수동으로 검토하고, 프롬프트 (prompts)를 미세 조정하며, 반복 (iterate)하면 됩니다. 하지만 프로덕션 (production) 환경에서는 수천 또는 수백만 건의 상호작용을 처리해야 할 수도 있습니다. 사람이 시간당 50100개의 트레이스를 의미 있게 평가할 수 있다고 가정할 때, 하루에 1,000건의 요청이 들어온다면 전체를 수동으로 검토하는 데 매일 1020시간의 전담 인력이 필요합니다. 이는 중요한 질문을 던집니다. 수동 검토가 확장성 (scale)을 갖지 못할 때, 어떻게 프로덕션 데이터에 인간의 지능을 도입할 것인가?
우리는 상호 보완적인 두 가지 접근 방식이 효과적이라는 것을 발견했습니다.
구조화된 인간 검토를 위한 어노테이션 큐 (Annotation queues)
어노테이션 큐 (Annotation queues)는 인간의 검토를 최대한 효율적으로 만드는 데 도움을 줍니다. 검토자에게 프로덕션 로그를 직접 뒤지라고 요청하는 대신, 어노테이션 큐는 사전 정의된 루브릭 (rubric)과 함께 특정 실행 (runs)을 구조화된 형식으로 제시합니다.
효과적인 어노테이션 큐 시스템을 통해 다음과 같은 작업을 수행할 수 있습니다:
특정 트레이스를 검토 대상으로 라우팅 (Route specific traces for review): 모든 것을 검토하는 대신, 특정 하위 집합(부정적인 피드백이 있는 실행, 비용이 높은 상호작용, 또는 특정 시간대의 쿼리 등)을 큐로 보냅니다.
검토 기준 정의 (Define review criteria): 검토자가 무엇을 평가해야 하는지 정확히 알 수 있도록 루브릭을 설정합니다 (관련성, 정확성, 어조, 안전성).
팀 협업 활성화 (Enable team collaboration): 여러 검토자가 진행 상황 추적 및 역할 할당 기능을 갖춘 큐를 통해 작업할 수 있습니다.
피드백 루프 생성 (Create feedback loops): 검토된 데이터에 수정 사항을 어노테이션 (annotated)하여 평가 데이터셋 (evaluation datasets)에 추가할 수 있습니다.
어노테이션 큐는 새로운 실패 모드 (failure mode)를 이해하려고 하거나, 평가자 (evaluators)를 위한 학습 데이터를 구축하거나, 전문적인 쿼리에 대해 전문가의 도메인 피드백을 얻고자 할 때 특히 가치가 있습니다.
고려해야 할 트레이드오프 (Trade-offs): 어노테이션 큐는 전담 검토자의 시간이 필요하며 개선 주기 (improvement cycle)에 지연 (latency)을 초래할 수 있습니다. 우리는 모든 범위를 포괄하려고 시도하기보다 특정 고가치 트레이스에 집중할 때 가장 효과적이라는 것을 발견했습니다.
인간의 판단을 위한 프록시로서의 LLM (LLM as a proxy for human judgment)
두 번째 접근 방식은 인간의 판단을 확장하기 위해 LLM 자체를 사용하는 것입니다. LLM이 완벽한 평가자는 아닐지라도, 인간이 할 수 없는 규모로 다양한 품질 차원(quality dimensions)을 평가할 수 있습니다.
특히, 프로덕션 트래픽(production traffic) 전체 또는 샘플링된 일부에 대해 온라인 평가기(online evaluators)가 자동으로 실행되도록 구성할 수 있습니다. 이러한 평가기는 다음 사항들을 확인할 수 있습니다:
참조 없는 품질 지표 (Reference-free quality metrics): 정답(ground truth)이 필요하지 않은 일관성(coherence) 및 어조(tone)와 같은 속성
안전성 및 준수 (Safety and compliance): 응답에 민감한 정보가 포함되어 있는지, 정책을 위반하는지, 또는 유해한 동작을 보이는지 여부
형식 검증 (Format validation): 출력이 예상된 구조를 따르는지 또는 필수 요소를 포함하고 있는지 여부
주제 분류 (Topic classification): 사용자가 요청하는 요청의 카테고리가 무엇인지
LLM은 인간의 검토를 넘어서는 규모로 자연어를 평가할 수 있습니다. 인간은 수십 개의 트레이스(traces)를 검토할 수 있지만, LLM 평가기는 수천 개를 평가하여 잠재적인 문제를 표시하고 집계된 지표(aggregate metrics)를 제공할 수 있습니다.
하지만, LLM 기반 평가는 자체적인 비용과 제약 사항도 수반합니다:
지연 시간 (Latency): 평가기는 트레이스당 몇 초의 지연 시간을 추가할 수 있으며, 이는 비동기 배치 평가(async batch evaluation)에는 허용될 수 있지만 동기식 사용자 피드백(synchronous user feedback)에는 적합하지 않을 수 있습니다.
비용 (Cost): 모든 트레이스를 평가하면 추론 비용(inference costs)이 증가할 수 있으므로, 일반적으로 트래픽의 10-20%를 샘플링하는 것을 권장합니다.
정확도 (Accuracy): 기성(off-the-shelf) 평가기는 귀하의 특정 앱에서 의미하는 "좋음"을 반영하지 못할 수 있습니다. 귀하의 사용 사례에 맞춘 맞춤형 LLM-as-judge 평가기가 필요한 경우가 많지만, 이들이 인간의 판단과 일치하도록 보장하는 것 또한 어려울 수 있습니다. 저희는 팀들이 맞춤형 평가기를 대규모로 신뢰하기 전에 인간의 레이블(human labels)에 맞춰 보정(calibrated)되었는지 검증할 수 있도록 Align Evals를 구축했습니다.
평가 드리프트 (Evaluation drift): 프로덕션 트래픽이 변화함에 따라 평가기를 재조정하거나 교체해야 할 수도 있습니다.
이러한 이유로, 저희는 LLM 평가기에만 전적으로 의존하기보다는 자동화된 평가와 주기적인 인간 검토를 결합하는 것을 권장합니다.
프로덕션 에이전트 관측 가능성을 위한 도구들
에이전트를 위한 효과적인 프로덕션 관측 가능성 (Production Observability)을 구축하려면 특정한 기능 세트가 필요하며, 대부분의 범용 모니터링 도구들은 이러한 기능을 제공하도록 설계되지 않았습니다. 수십 개의 프로덕션 배포 사례에서 관찰한 패턴을 바탕으로, 저희는 다음과 같은 기능들을 LangSmith에 구축했습니다.
Insights Agent: 사용 및 오류 패턴 발견
프로덕션 환경에서 가장 어려운 측면 중 하나는 사용자들이 에이전트로 무엇을 하고 있는지 단순히 이해하는 것입니다.
팀들이 프로덕션 트레이스 (Traces)를 어떻게 사용하는지 분석했을 때, 저희는 무엇을 찾을지 사전에 지정하지 않고도 패턴을 자동으로 발견할 수 있는 방법이 필요하다는 것을 알게 되었습니다. 이를 바탕으로 유사한 트레이스를 그룹화하여 다음 사항들을 식별하는 자동화된 클러스터링 (Clustering) 시스템을 사용하는 Insights Agent를 구축하게 되었습니다.
사용 패턴 (Usage patterns): 사용자들이 요청하는 가장 일반적인 유형은 무엇인가? 그들이 사용하려는 기능이나 역량은 무엇인가?
오류 모드 (Error modes): 에이전트가 어디에서 실수를 하고 있는가? 잘못된 도구 선택 (Tool selection), 검색 실패 (Retrieval failures), 또는 사용자 의도 오해와 같은 공통적인 실패 패턴이 존재하는가?
엣지 케이스 (Edge cases): 여러분이 고려하지 못했던 예상치 못한 쿼리(Queries)를 사용자들이 보내고 있는가?
Insights Agent는 사용 패턴, 실패 모드 또는 도메인별 특정 사용자 정의 속성 (Custom attributes)에 따라 트레이스를 그룹화하도록 구성할 수 있습니다. 또한 분석 대상을 특정 하위 집합(시간 범위, 사용자 코호트, 기능 영역)으로 필터링할 수 있으며, 반복적인 분석을 위해 설정을 저장할 수도 있습니다.
예를 들어, 임베디드 코파일럿 (Embedded copilot)을 운영하는 회사의 제품 관리자(Product Manager)는 다음과 같이 질문할 수 있습니다: "사용자들이 우리 제품의 어떤 부분에서 코파일럿을 가장 자주 사용하려고 하는가?"
Insights Agent는 수천 개의 트레이스를 분석하고, 의도(Intent)별로 그룹화하여 상위 사용 카테고리를 제시할 수 있습니다.
품질 문제를 디버깅하는 엔지니어는 다음과 같이 질문할 수 있습니다: "내 에이전트가 어디에서 잘못된 도구를 선택하고 있는가?"
Insights Agent는 도구 선택 실패에서의 공통적인 패턴을 식별하고 대표적인 사례를 제공할 수 있습니다.
이러한 자동화된 패턴 발견은 방대한 양의 프로덕션 트레이스를 더 관리하기 쉽고 실행 가능한 정보로 만드는 데 도움을 줍니다.
온라인 평가 (Online Evaluations): 지속적인 품질 모니터링
앞서 인간의 판단을 확장하는 방법으로 온라인 평가 (Online Evaluations)를 언급했습니다. 이것이 실제로 어떻게 작동하는지 살펴보겠습니다.
온라인 평가를 사용하면 프로덕션 트레이스 (Production Traces)에서 자동으로 실행되는 평가자 (Evaluators)를 설정할 수 있습니다. 다음과 같은 사항을 구성할 수 있습니다:
어떤 트레이스를 평가할 것인가: 모든 트레이스, 샘플링된 비율 (통상적으로 10-20%), 또는 특정 필터링된 하위 집합
무엇을 평가할 것인가: 품질 지표 (Quality Metrics), 안전성 점검 (Safety Checks), 형식 검증 (Format Validation), 또는 사용자 정의 기준
언제 알림을 보낼 것인가: 지표가 저하될 때 알림을 트리거하는 임계값 (Thresholds)
온라인 평가는 전통적인 "테스트 (Testing)"를 넘어 여러 목적을 수행합니다:
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기