에이전트 개발 라이프사이클: AI 에이전트 구축, 테스트, 배포 및 모니터링 | LangChain
요약
성공적인 AI 에이전트 운영을 위한 구축, 테스트, 배포, 모니터링의 4단계 개발 라이프사이클을 소개합니다. 단순한 데모를 넘어 반복 가능하고 체계적인 시스템을 구축하는 방법론을 다룹니다.
핵심 포인트
- 에이전트 개발은 구축-테스트-배포-모니터링의 반복적 사이클이 필수적임
- 테스트는 프로덕션 배포 전 단계에서 반드시 선행되어야 함
- 다수의 에이전트 운영 시 비용 제어 및 도구 권한 관리 등 거버넌스가 중요함
- 에이전트 프레임워크와 런타임은 추상화와 실행 측면에서 서로 다른 역할을 수행함
모두가 에이전트를 출시하고 싶어 합니다.
최고의 조직들은 이를 반복적이고, 안전하며, 체계적으로 수행하는 방법을 파악했습니다. 그들은 조기에 출시하고, 실제 사용 사례로부터 배우며, 빠르게 반복(iterate)합니다. 그들은 에이전트를 일회성 데모나 고립된 프로젝트로 취급하지 않습니다.
대신, 그들은 실험을 출시, 학습, 그리고 시간이 지남에 따라 개선할 수 있는 반복 가능한 시스템으로 전환함으로써 추진력을 만들어내는 **에이전트 개발 라이프사이클 (agent development lifecycle)**을 구축했습니다.
이 라이프사이클은 네 가지 부분으로 구성됩니다:
Build (구축) → Test (테스트) → Deploy (배포) → Monitor (모니터링)
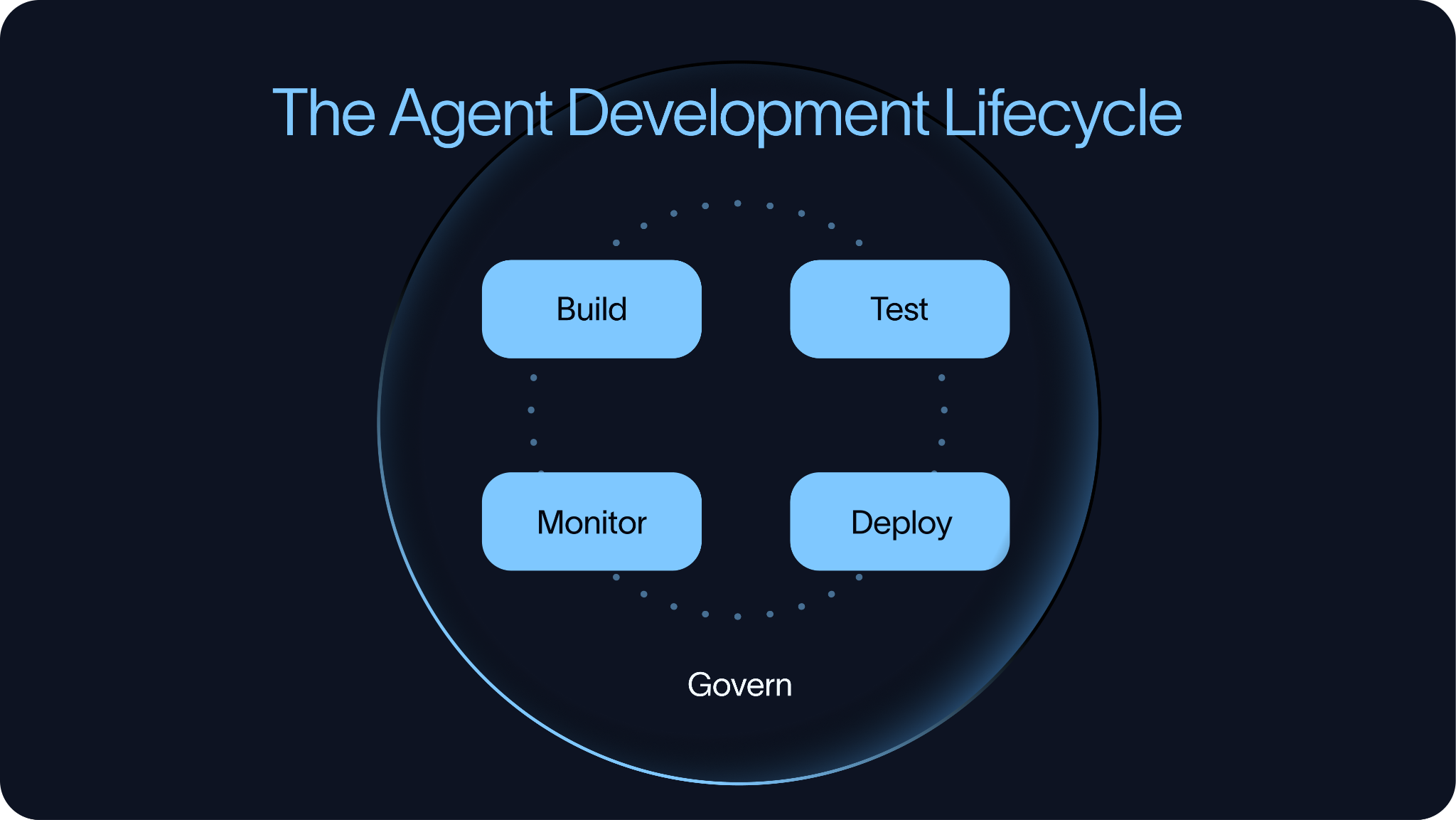
이 순서는 의도된 것입니다. 테스트는 에이전트가 프로덕션(production)에 도달한 후가 아니라, 도달하기 전에 시작되어야 합니다. 팀은 배포 전에 에이전트를 테스트해야 하고, 통제된 방식으로 배포해야 하며, 프로덕션에서 어떻게 동작하는지 모니터링해야 하고, 그러한 학습 내용을 다음 구축 및 평가 사이클로 다시 피드백해야 합니다.
단일 에이전트의 경우 이 프로세스는 가볍게 유지될 수 있습니다. 하지만 많은 에이전트에 걸쳐 적용될 때는 인프라 및 거버넌스(governance)의 과제가 됩니다. 팀은 비용을 제어하고, 도구 접근 권한을 관리하며, 도구 호출(tool calls)을 검사하고, 컨텍스트(context)를 재사용하며, 인간이 개입해야 하는 지점을 결정하기 위한 공유된 방식이 필요합니다.
에이전트가 한 번 작동하게 만드는 것과 에이전트를 반복 가능한 관행으로 구축하는 것의 차이는 올바른 개발 라이프사이클을 갖추고 있는지 여부에서 옵니다.
Build (구축)
구축 단계는 팀이 어떤 종류의 에이전트 시스템을 만들 것인지, 그리고 어떤 수준의 추상화(abstraction)를 사용할 것인지를 결정하는 단계입니다.
이 단계에는 매우 다양한 도구들이 있습니다. 어떤 도구들은 코드 우선(code-first) 방식인 반면, 어떤 것들은 노코드(no-code) 또는 로우코드(low-code) 방식입니다. 어떤 것들은 추상화에 집중하는 반면, 어떤 것들은 프롬프트(prompts), 도구(tools), 기술(skills), 상태(state)를 갖춘 작동 환경을 에이전트에게 제공하는 데 집중합니다.

코드 우선 측면에서 팀들은 종종 오픈 소스 프레임워크와 하네스(harnesses)를 찾습니다. LangChain 생태계에는 LangChain, LangGraph, 그리고 Deep Agents가 포함됩니다. LangChain 외부의 예로는 CrewAI와 Claude Agents SDK가 있습니다.
이러한 도구들은 스택의 서로 다른 계층에서 작동합니다.
**에이전트 프레임워크 (Agent frameworks)**는 주로 추상화 (abstractions)에 집중합니다. 이들은 개발자가 모델 호출 (model calls), 도구 (tools), 프롬프트 (prompts), 검색 (retrieval), 구조화된 출력 (structured outputs), 그리고 에이전트 루프 (agent loops)를 구성할 수 있도록 돕습니다. LangChain과 CrewAI가 이 범주의 예시입니다.
**에이전트 런타임 (Agent runtimes)**은 실행 (execution)에 집중합니다. 이들은 상태 (state), 제어 흐름 (control flow), 내구성 (durability), 그리고 인간의 개입 (human intervention)이 필요한 에이전트를 지원합니다. LangGraph는 LangChain 생태계에서 가장 명확한 예시입니다. LangGraph는 분기 (branch), 루프 (loop), 일시 중지 (pause), 재개 (resume), 그리고 시간이 지남에 따라 상태를 유지 (persist state)할 수 있는 에이전트 시스템을 구축하는 방법을 제공합니다.
**에이전트 하네스 (Agent harnesses)**는 수행 (doing)에 집중합니다. 이들은 에이전트가 더 오래 지속되는 작업 (longer-running tasks)을 수행하는 데 필요한 주변 구조를 제공합니다: 프롬프트 (prompts), 기술 (skills), MCP 서버 (MCP servers), 훅 (hooks), 미들웨어 (middleware), 그리고 때로는 파일 시스템 (filesystem) 등이 포함됩니다. Deep Agents와 Claude Agent SDK가 이 패턴의 예시입니다.
이러한 구분은 "에이전트를 구축한다"는 말이 서로 다른 의미를 가질 수 있기 때문에 중요합니다.
단순한 애플리케이션의 경우, 도구 호출 루프 (tool-calling loop)를 정의하는 것만으로 충분할 수 있습니다. 하지만 더 정교한 에이전트의 경우, 프롬프트를 작성하고, 기술을 정의하며, MCP 서버를 연결하고, 미들웨어를 구성하며, 에이전트가 시간이 지남에 따라 검색하거나 업데이트할 수 있는 컨텍스트 (context)를 설정하는 과정이 포함될 수 있습니다.
노코드 구축 (No-code building)
빌드 단계에는 노코드 (no-code) 및 로우코드 (low-code) 측면도 존재합니다. LangSmith Fleet, Claude Cowork, n8n과 같은 도구들은 더 많은 사람들이 에이전트 개발에 참여할 수 있게 해줍니다. 이는 필요한 워크플로우 (workflow)를 이해하는 사람이 항상 코드를 작성하는 사람은 아니기 때문에 중요합니다.
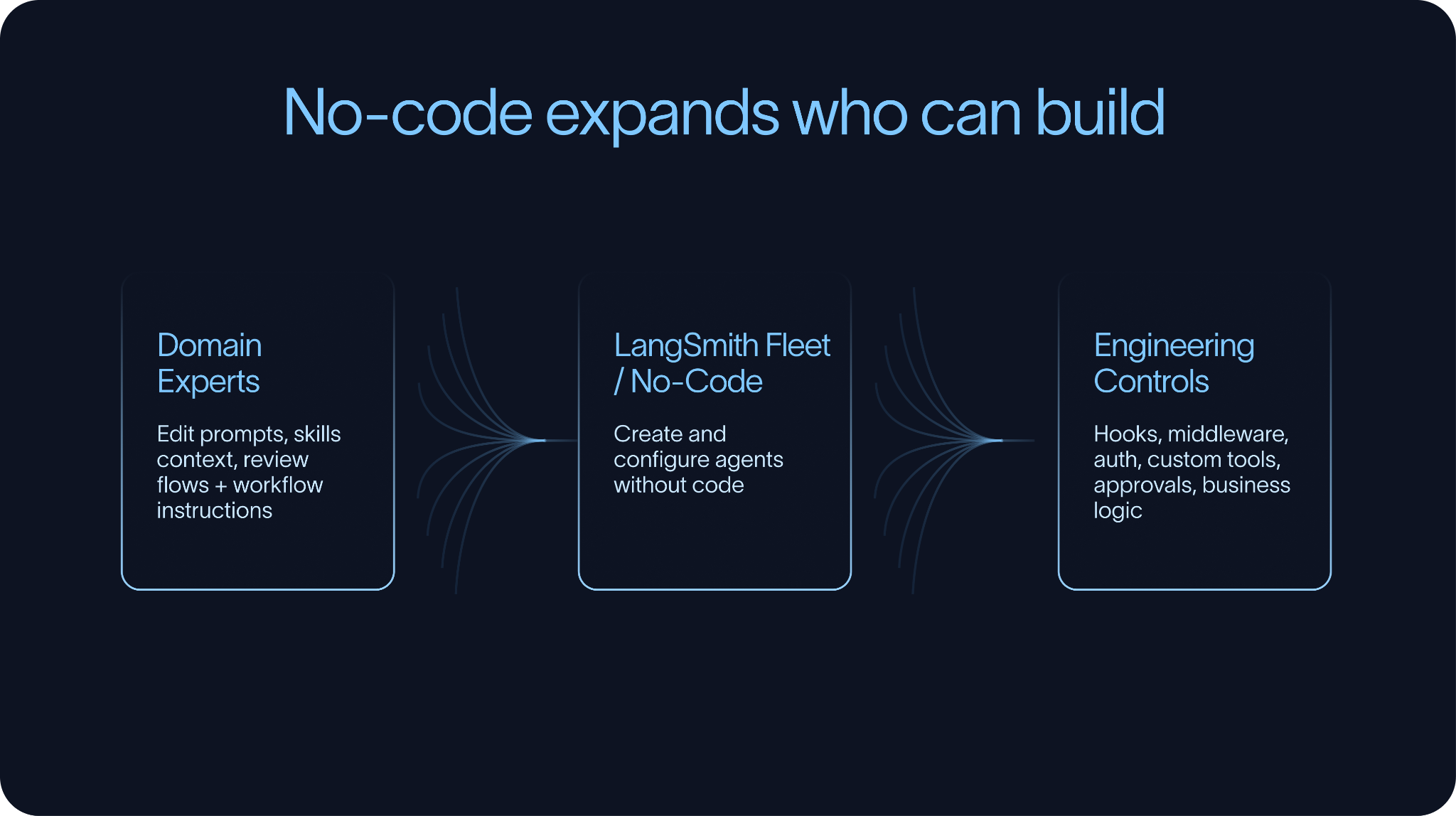
동시에, 노코드 도구가 엔지니어링 제어 (engineering control)의 필요성을 없애는 것은 아닙니다. 시스템이 복잡해짐에 따라, 팀들은 보통 코드에서 동작을 확장하거나 재정의 (override)할 수 있는 방법이 필요합니다. 여기서 훅 (hooks)과 미들웨어 (middleware)는 특히 중요한데, 이를 통해 팀은 모든 에이전트를 처음부터 다시 구축하지 않고도 도구 호출, 컨텍스트 처리, 승인 (approvals), 인증 (auth), 또는 비즈니스 규칙 주변에 커스텀 로직을 추가할 수 있기 때문입니다.
최고의 빌드 환경은 단순한 것은 단순하게, 복잡한 것은 가능하게 만듭니다. 이러한 환경은 도메인 전문가(domain experts)가 프롬프트(prompts), 스킬(skills), 컨텍스트(context)를 편집할 수 있게 하면서도, 엔지니어에게는 신뢰할 수 있고 테스트 가능하며 거버넌스(governed)가 적용되어야 하는 부분에 대한 제어권을 제공합니다.
테스트 (Test)
에이전트가 배포되기 전에, 팀은 에이전트가 실제로 준비되었는지 판단할 수 있는 방법이 필요합니다.
그것이 에이전트를 사용하기 전에 완벽한 평가 스위트(eval suite)를 구축해야 한다는 의미는 아닙니다. 실제로 그런 일은 거의 불가능합니다. 하지만 명백한 실패를 포착하고, 버전을 비교하며, 변경 사항을 맹목적으로 배포하는 것을 방지할 수 있을 만큼 충분한 평가(evals)를 갖추어야 한다는 의미입니다.
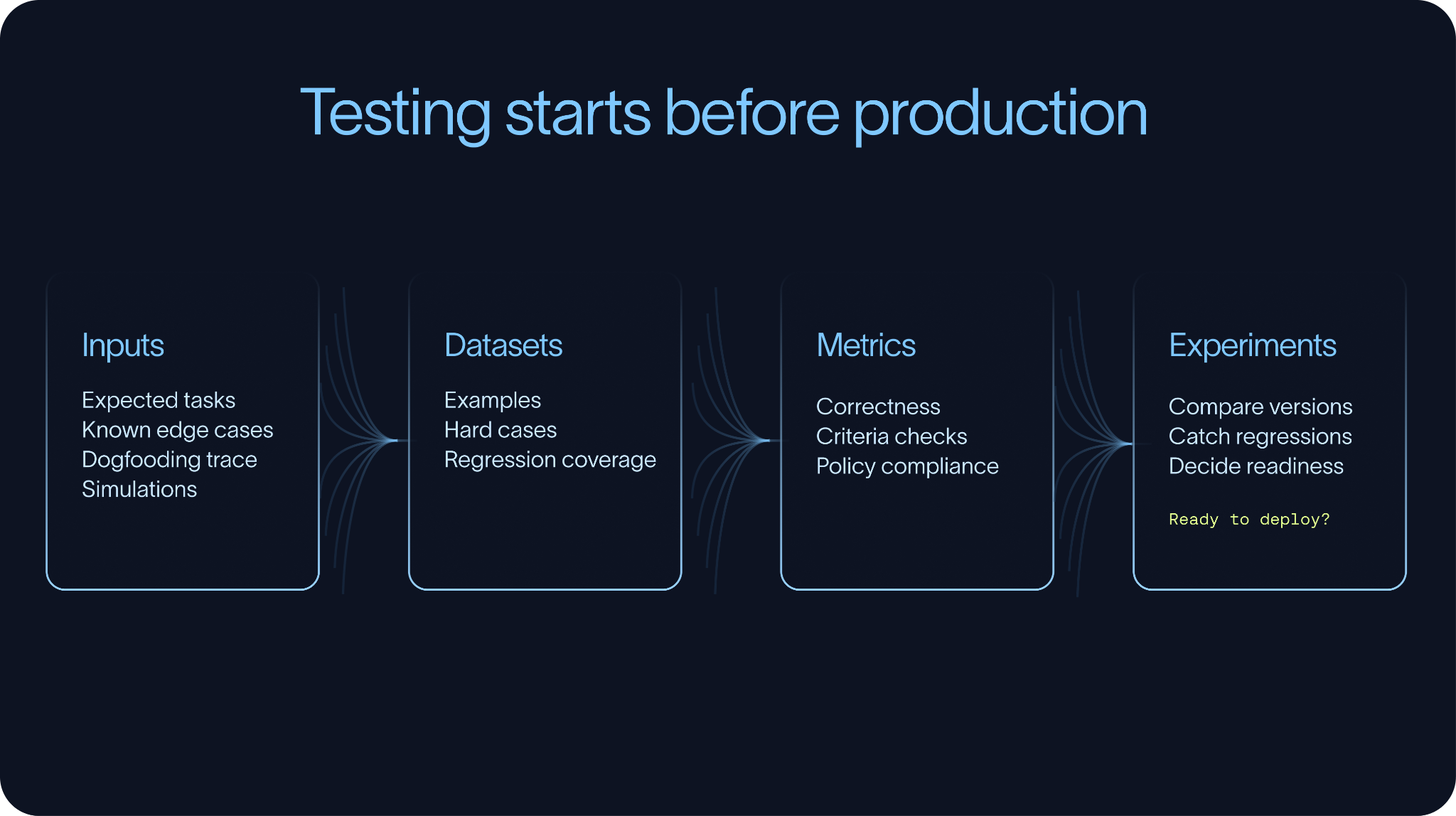
대부분의 평가 워크플로우(eval workflows)는 대표적인 작업들로 구성된 작은 데이터셋(dataset)으로 시작합니다. 몇 가지 예로는 예상되는 사용 사례(use cases), 수동 테스트, 도그푸딩(dogfooding), 지원 티켓(support tickets), 이전 트레이스(traces), 또는 알려진 엣지 케이스(edge cases) 등이 있습니다. 시간이 지나면서 프로덕션 트레이스(production traces)는 이러한 데이터셋을 훨씬 더 강력하게 만들지만, 테스트는 프로덕션 이전에 시작되어야 합니다.
데이터셋 및 지표 (Datasets and metrics)
데이터셋은 팀이 학습한 내용을 보존하는 방법입니다. 데이터셋이 없다면 프롬프트 변경, 모델 업그레이드, 또는 도구(tool) 업데이트 이후에 동일한 실패가 다시 나타나는 경향이 있습니다.
적절한 지표(metrics)는 작업에 따라 달라집니다.
어떤 경우에는 명확한 정답(ground truth)이 존재합니다. 에이전트가 올바른 값을 추출했나요? 올바른 라벨(label)을 선택했나요? 올바른 필드(field)를 업데이트했나요? 이러한 작업들은 정확성(correctness)을 직접 측정할 수 있습니다.
다른 경우에는 단일한 정답(ground truth)이 존재하지 않을 수도 있습니다. 에이전트는 응답을 작성하거나, 대화를 요약하거나, 에스컬레이션(escalate) 여부를 결정하거나, 여러 가지 유효한 경로를 가진 작업을 완료해야 할 수도 있습니다. 그런 경우 팀은 기준 기반 평가(criteria-based evaluation)에 더 많이 의존합니다. 질문은 응답이 근거에 기반했는지(grounded), 에이전트가 정책을 따랐는지, 명확한 설명을 요청했는지, 또는 불필요한 도구 호출(tool calls) 없이 효율적으로 작업을 완료했는지 등이 됩니다.
실험 (Experiments)
실험 (Experiments)은 데이터셋과 지표 (metrics)를 반복 (iteration) 과정에 연결하는 역할을 합니다. 실험을 통해 팀은 동일한 평가 세트 (evaluation set)를 바탕으로 프롬프트 (prompts), 모델 (models), 검색 전략 (retrieval strategies), 도구 스키마 (tool schemas), 그리고 오케스트레이션 패턴 (orchestration patterns)을 비교할 수 있습니다. 시간이 흐름에 따라, 이러한 실험들은 에이전트가 개선되고 있는지 아니면 퇴보하고 있는지를 보여줍니다.
목표는 첫날부터 완벽한 평가 스위트 (eval suite)를 만드는 것이 아닙니다. 유용한 평가 스위트로 시작하여 이를 지속적으로 개선해 나가는 것이 목표입니다. 가장 가치 있는 평가 데이터셋은 가장 어려운 사례들로부터 구축됩니다. 우선 개발 단계와 도그푸딩 (dogfooding)을 통해 구축하고, 이후에는 운영 (production) 환경에서 구축합니다.
시뮬레이션 (Simulations)
시뮬레이션은 테스트의 또 다른 중요한 부분입니다.
많은 에이전트는 멀티 턴 (multi-turn) 시스템입니다. 이들은 단순히 질문 하나에 답하는 것이 아니라, 대화를 나누고, 정보를 수집하며, 도구를 호출하고, 상태를 업데이트하며, 모호함으로부터 회복합니다. 이러한 에이전트들에게 싱글 턴 (single-turn) 평가만으로는 충분하지 않습니다. 팀은 멀티 턴 평가와 시뮬레이션된 엔드 투 엔드 (end-to-end) 상호작용이 필요합니다.
음성 에이전트가 명확한 예시이지만, 이 패턴은 더 광범위합니다. 일련의 턴 (sequence of turns)에 걸쳐 작동하는 모든 에이전트는 시뮬레이션이 필요할 수 있습니다. 고객 지원 에이전트는 화가 난 고객을 응대하고, 후속 질문을 던지며, 주문 상태를 확인하고, 에스컬레이션 (escalation)이 필요한지 결정해야 할 수도 있습니다. 코딩 에이전트는 저장소 (repository)를 검사하고, 변경 사항을 적용하며, 테스트를 실행하고, 피드백에 응답해야 할 수도 있습니다. 내부 운영 에이전트는 조치를 취하기 전에 누락된 정보를 수집해야 할 수도 있습니다.
훌륭한 테스트 관행은 팀이 단순한 느낌 (vibes)에 의존하지 않고 체계적으로 에이전트를 개선할 수 있도록 돕습니다. 테스트 관행은 기대되는 동작을 데이터셋으로, 데이터셋을 실험으로, 그리고 실험을 시스템의 더 나은 버전으로 전환합니다. 배포 후에는 모니터링 (monitoring)을 통해 이러한 평가를 더욱 강력하게 만드는 실제 사례들을 제공받게 됩니다.
배포 (Deploy)
에이전트가 구축되고 평가되면, 에이전트가 안정적으로 실행될 수 있는 환경이 필요합니다.
단순한 에이전트의 경우, 배포는 전통적인 애플리케이션을 배포하는 것과 유사할 수 있습니다. 하지만 많은 에이전트는 상태가 없는 (stateless) 서버 이상의 기능이 필요합니다. 에이전트는 더 긴 시간 동안 실행되며, 도구 (tools)를 호출하고, 인간의 입력을 기다리며, 파일을 작성하고, 중단으로부터 복구하며, 여러 상호작용 또는 작업에 걸쳐 상태 (state)를 유지해야 합니다.
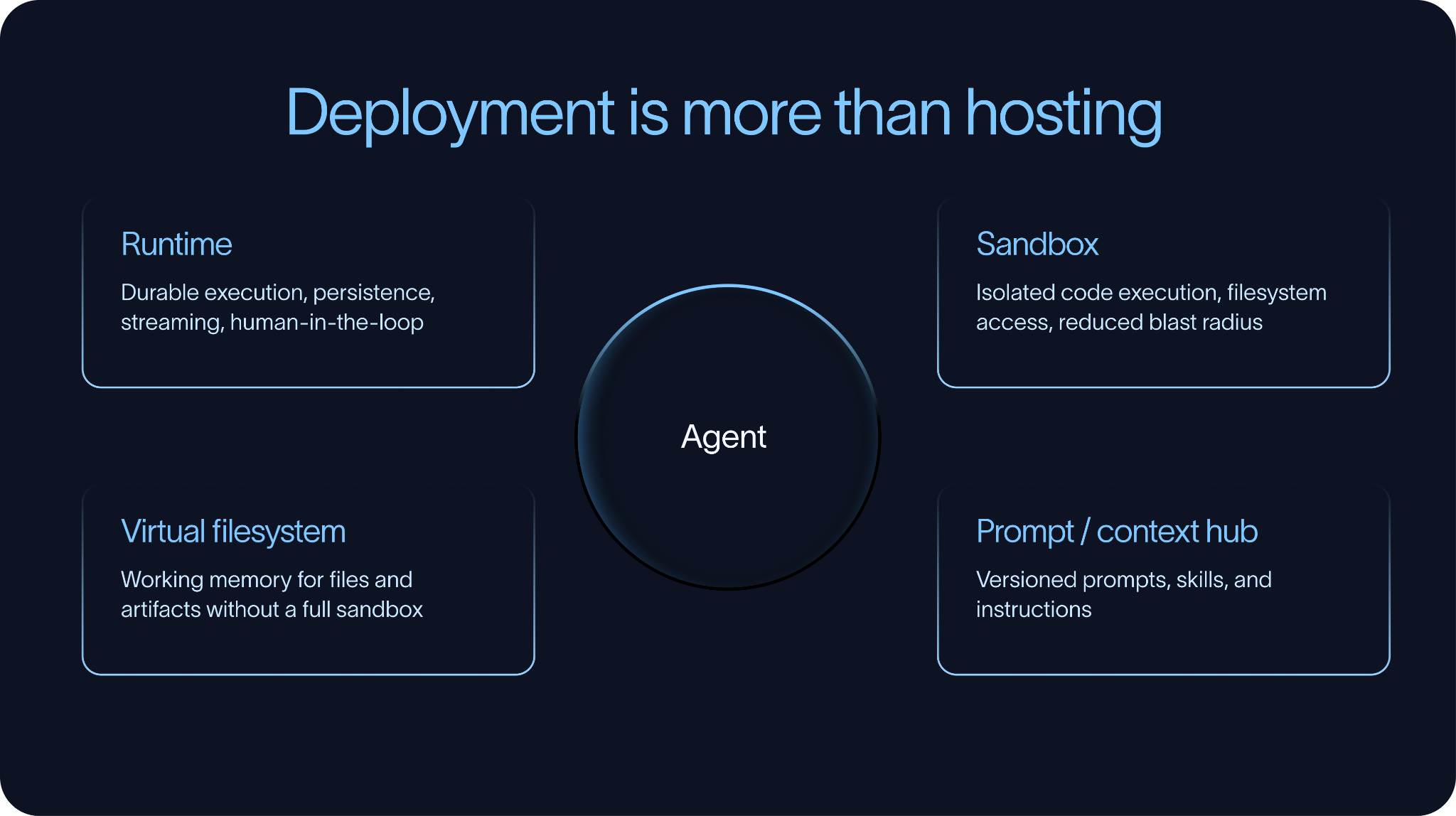
이것이 바로 런타임 (runtime)이 중요한 이유입니다.
프로덕션 에이전트 런타임은 일반적으로 내구성이 있는 실행 (durable execution) 및 인간 참여형 (human-in-the-loop) 패턴을 지원해야 합니다. 내구성이 있는 실행이란 에이전트가 진행 상황을 체크포인트 (checkpoint)로 저장하고, 무언가 실패했을 때 작업을 잃는 대신 재개할 수 있음을 의미합니다. 인간 참여형 (human-in-the-loop)이란 에이전트가 승인, 명확화 또는 검토가 필요할 때 일시 중지할 수 있음을 의미합니다.
이를 위한 기성 솔루션들이 있습니다. LangSmith Deployment는 Deep Agents 및 LangGraph 에이전트를 배포하고 관리하기 위한 인프라를 제공합니다. AWS AgentCore는 에이전트를 위한 관리형 런타임의 또 다른 예시입니다. 일부 팀은 특히 스택의 다른 곳에서 장기 실행 워크플로우 (long-running workflows)를 위해 이미 Temporal을 사용하고 있는 경우, Temporal과 같은 시스템 위에 자체적인 런타임을 구축하기도 합니다.
샌드박스 (Sandboxes)
많은 에이전트는 전용 실행 환경도 필요로 합니다.
에이전트는 점점 더 코드를 작성하고, 코드를 실행하며, 파일을 검사하고, 문서를 변환하거나, 파일 시스템과 상호작용해야 할 필요가 있습니다. 이러한 경우, 팀은 해당 작업이 어디에서 수행될지 결정해야 합니다. 샌드박스 (Sandboxes)는 일반적인 솔루션입니다. 샌드박스는 파일 시스템 접근 권한을 가진 격리된 실행 환경을 제공하는 동시에, 실수나 안전하지 않은 동작의 영향 범위 (blast radius)를 줄여줍니다.
예시로는 LangSmith Sandboxes, Daytona, E2B 등이 있습니다.
모든 에이전트가 완전한 샌드박스를 필요로 하는 것은 아닙니다. 어떤 경우에는 에이전트가 단순히 파일을 저장하고 검색할 장소만 있으면 됩니다. 가상 파일 시스템 (virtual filesystem)만으로도 충분할 수 있습니다. Deep Agents는 에이전트가 반드시 샌드박스 내부에서 임의의 코드를 실행하지 않고도 파일을 작업 메모리 (working memory)로 사용할 수 있게 함으로써 이 패턴을 지원합니다. 내부적으로 이 파일 시스템은 Postgres나 S3와 같은 시스템을 기반으로 할 수 있습니다.
컨텍스트 허브 (Context Hub)
배포에서 종종 간과되는 또 다른 부분은 프롬프트 (prompts)와 컨텍스트 (context)를 관리하는 것입니다.
에이전트의 가장 중요한 부분 중 일부는 전통적인 애플리케이션 코드 (application code)가 아닙니다. 프롬프트 (prompts), 검색 컨텍스트 (retrieval context), 기술 (skills), 그리고 작업 지침 (task instructions)은 애플리케이션 자체보다 더 자주 변경되어야 할 수도 있습니다. 또한 엔지니어가 아닌 사람들에 의해 편집되어야 할 수도 있습니다.
이는 프롬프트 또는 컨텍스트 허브 (prompt or context hub)의 필요성을 만듭니다. 즉, 에이전트의 비코드 (non-code) 부분을 저장, 버전 관리, 검토 및 업데이트할 수 있는 장소가 필요합니다. 이를 통해 팀은 전체 배포 (full deploy) 없이도 에이전트의 동작을 조정할 수 있으며, 도메인 전문가 (domain experts)가 자신이 가장 잘 이해하는 컨텍스트를 직접 관리할 수 있게 됩니다.
실제로 배포 (deployment)는 단순히 에이전트를 서버에 올리는 것만을 의미하지 않습니다. 그것은 에이전트가 실제 업무를 수행하는 데 필요한 런타임 (runtime), 실행 환경 (execution environment), 그리고 컨텍스트 관리 시스템 (context management systems)을 제공하는 것에 관한 것입니다.
모니터링 (Monitor)
에이전트가 배포되면, 팀은 에이전트가 프로덕션 (production) 환경에서 실제로 어떻게 동작하는지에 대한 가시성 (visibility)을 확보해야 합니다.
이 지점이 에이전트 모니터링이 전통적인 소프트웨어 모니터링과 다른 부분입니다. 지연 시간 (latency), 비용 (cost), 에러율 (error rates), 가동 시간 (uptime)과 같은 지표 (metrics)도 여전히 중요하지만, 이는 전체 그림의 일부일 뿐입니다. 에이전트는 기술적으로는 성공적인 응답을 반환하더라도 작업 자체에는 실패할 수 있습니다. 잘못된 도구 (tool)를 호출하거나, 잘못된 컨텍스트 (context)에 의존하거나, 필수 승인 단계를 건너뛰거나, 그럴듯해 보이지만 틀린 답변을 생성할 수도 있습니다.
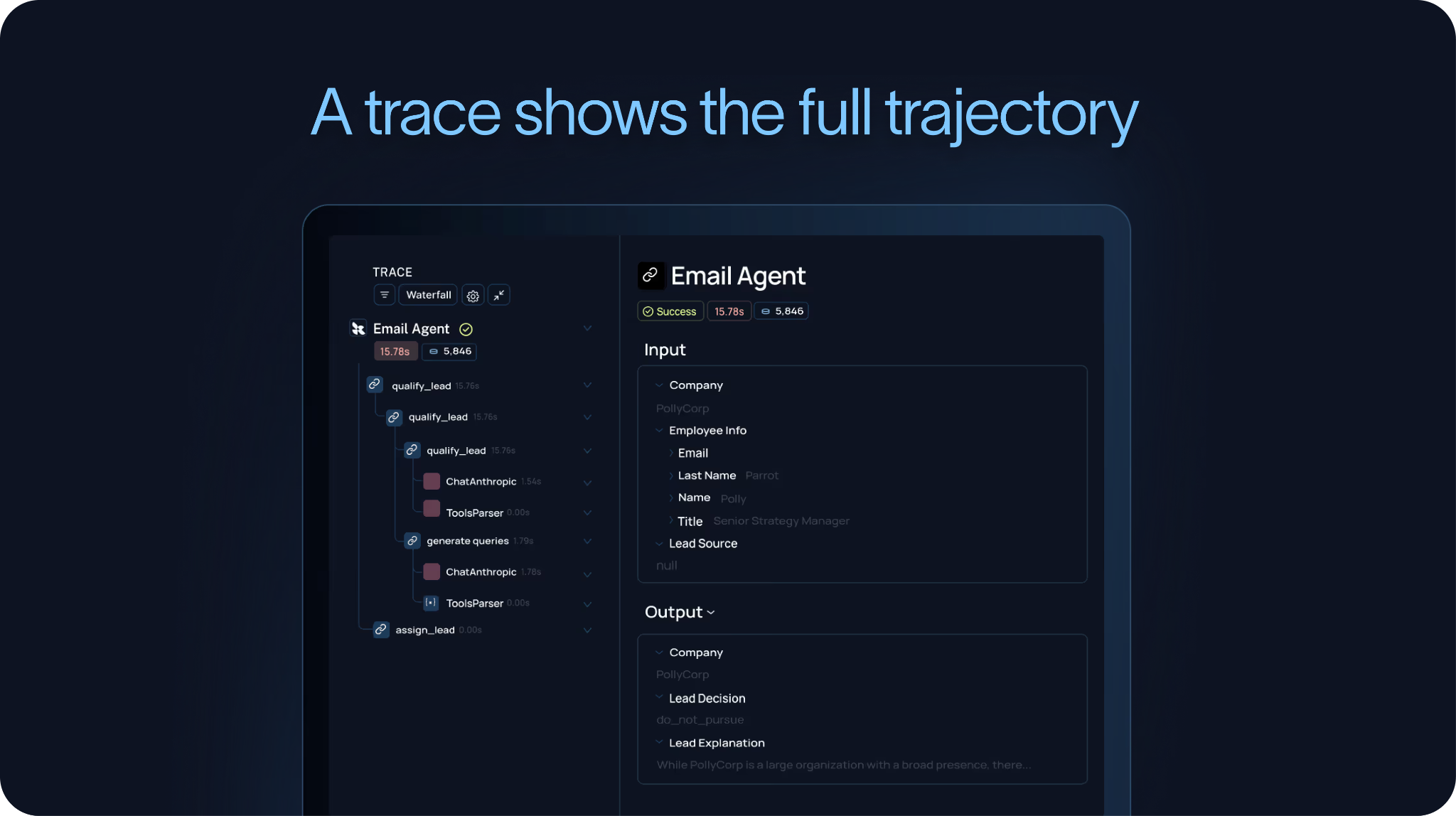
이러한 실패를 이해하기 위해 팀에는 트레이스 (traces)가 필요합니다.
A 트레이스 (trace)는 에이전트의 전체 궤적 (trajectory)을 캡처합니다: 에이전트가 받은 입력값 (inputs), 수행한 모델 호출 (model calls), 호출한 도구 (tools), 받은 출력값 (outputs), 그리고 최종적으로 생성한 응답 또는 작업 (action) 등이 포함됩니다. 이것이 에이전트가 실제로 무엇을 했는지 이해하는 데 필요한 상세 수준입니다.
이것이 바로 우리가 에이전트 관측성 (agent observability)이 에이전트 평가 (agent evaluation)를 뒷받침하며, 에이전트 개선 루프 (agent improvement loop)가 트레이스 (trace)에서 시작된다고 주장해 온 이유입니다. 궤적 (trajectory)을 볼 수 없다면, 동작을 안정적으로 디버깅 (debug)하거나 이러한 실패를 향후의 평가 (evals)로 전환할 수 없습니다.
시그널 (Signals)
모니터링에는 이러한 트레이스 (traces)로부터 시그널 (signals)을 수집하는 것도 포함되어야 합니다.
그러한 시그널 (signals) 중 일부는 LLM-as-judge 평가자 (evaluators)로부터 얻을 수 있습니다. 예를 들어, 평가자 (judge)는 에이전트 (agent)가 사용자의 질문에 답변했는지, 정책 (policy)을 준수했는지, 적절한 어조 (tone)를 사용했는지, 또는 작업을 완료했는지에 대해 점수를 매길 수 있습니다. 다른 시그널 (signals)은 더 간단할 수 있습니다. 정규 표현식 (regex)을 통해 필수 문구가 나타났는지, 금지된 도구 (tool)가 호출되었는지, 또는 알려진 실패 패턴 (failure pattern)이 발생했는지 포착할 수 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기