애플 컴퓨터(M 시리즈)로 로컬 대규모 언어 모델(LLM)을 실행하는 분들을 위한 주의사항!
요약
Apple Silicon 환경에서 로컬 LLM 추론 속도를 극대화하는 Rapid-MLX 도구를 소개합니다. Ollama 대비 2~4배 빠른 속도와 낮은 지연 시간을 제공하며, 다양한 모델 및 개발 도구와의 높은 호환성이 특징입니다.
핵심 포인트
- Ollama 대비 2~4배 빠른 추론 성능 제공
- 0.08초 수준의 매우 낮은 첫 번째 토큰 지연 시간
- Qwen, DeepSeek, Gemma 등 다양한 모델 지원
- OpenAI API 지원으로 Cursor, Claude Code 등과 연동 가능
애플 컴퓨터(M 시리즈)로 로컬 대규모 언어 모델(LLM)을 실행하는 분들을 위한 주의사항!
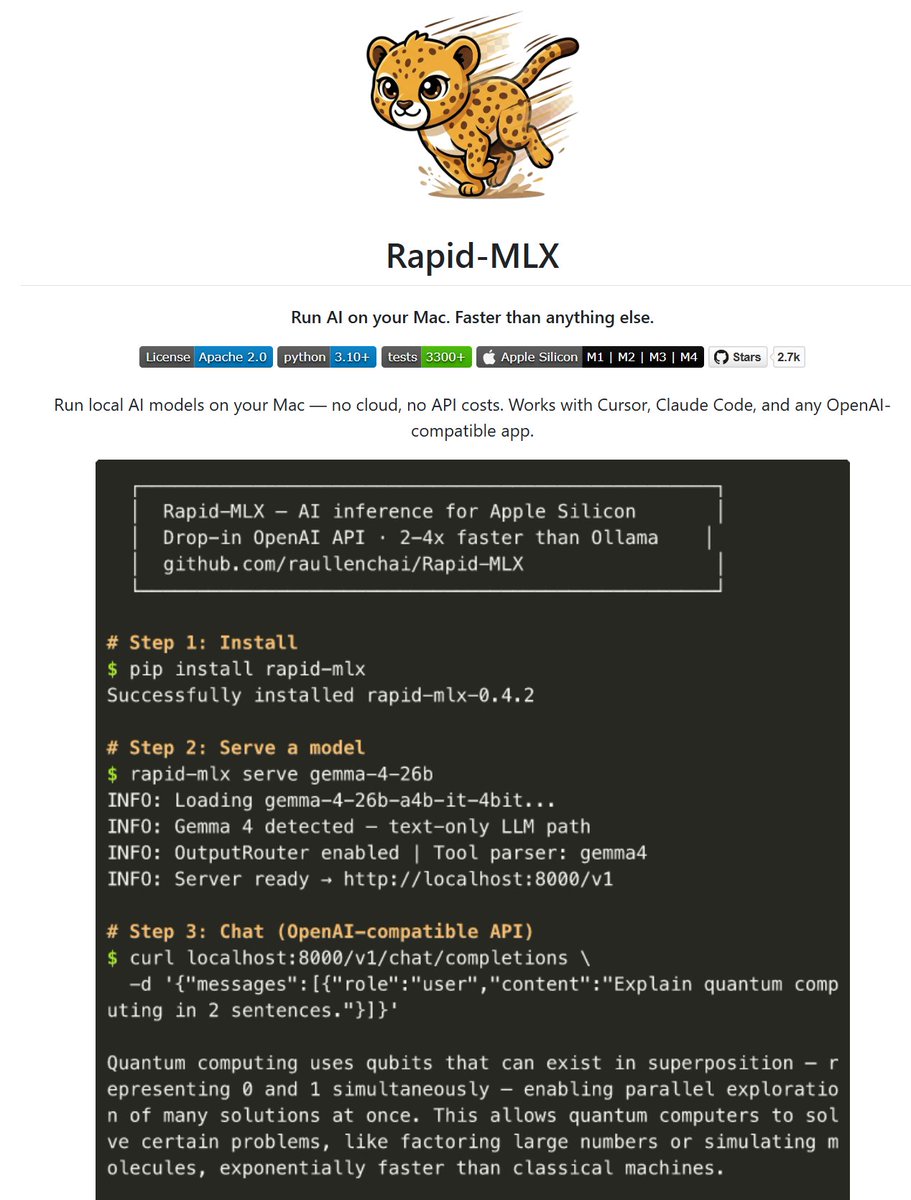
여러분이 아직 사용하지 않았을 수도 있는 강력한 도구가 있습니다 —— Rapid-MLX
Apple Silicon을 위해 특별히 제작된 로컬 LLM 추론 도구로, 실측 결과 Ollama보다 2~4배 더 빠릅니다!
핵심 장점:
- 극도로 낮은 첫 번째 토큰(First Token) 지연 시간: 다회차 대화 시 약 0.08초 정도만 소요되어 기다림이 거의 없습니다.
- 강력한 도구 호출(Tool Calling) 능력: 17종의 지능형 파서(Parser)가 내장되어 있어 Qwen, DeepSeek, Gemma 등의 모델에 자동 적응하며, 양자화(Quantization) 오류가 발생해도 자동으로 복구할 수 있습니다.
- 완벽한 호환성: OpenAI API를 네이티브로 지원하여 Cursor, Claude Code, Aider, LangChain 등의 도구와 직접적으로 원활하게 연결할 수 있습니다.
로컬 우선 + 멀티모달(Multimodal, 시각+오디오) 전폭 지원,
M 칩 아키텍처를 완전히 활용하여 경험이 정말 매끄럽습니다.
Mac에서 로컬 대규모 언어 모델을 쾌적하게 실행하고 싶은 분들에게 이 도구를 강력히 추천합니다!
https://github.com/raullenchai/Rapid-MLX
...
이미 MLX나 Ollama를 사용 중인 분들은 오셔서 비교 체험해 보세요~
여기에 궁극의 과학 학습 보물창고가 있습니다!
PhET는 학부모와 학생들에게 강력히 추천합니다.
이 웹사이트는 정말 놀랍습니다:
완전 무료 + 중국어 지원 + 브라우저에서 바로 플레이할 수 있는 100개 이상의 대화형 시뮬레이션 실험!
다루는 내용:
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huanusa (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기